好的架构是进化来的,不是设计来的
Posted m0_66404702
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了好的架构是进化来的,不是设计来的相关的知识,希望对你有一定的参考价值。
很多年前,读了子柳老师的《淘宝技术这十年》。这本书成为了我的架构启蒙书,书中的一句话像种子一样深埋在我的脑海里:“好的架构是进化来的,不是设计来的”。
2015 年,我加入神州专车订单研发团队,亲历了专车数据层「架构进化」的过程。这次工作经历对我而言非常有启发性,也让我经常感慨:“好的架构果然是一点点进化来的”。

1 单数据库架构
产品初期,技术团队的核心目标是:“快速实现产品需求,尽早对外提供服务”。
彼时的专车服务都连同一个 SQLServer 数据库,服务层已经按照业务领域做了一定程度的拆分。

这种架构非常简单,团队可以分开协作,效率也极高。随着专车订单量的不断增长,早晚高峰期,用户需要打车的时候,点击下单后经常无响应。
系统层面来看:
-
数据库瓶颈显现。频繁的磁盘操作导致数据库服务器 IO 消耗增加,同时多表关联,排序,分组,非索引字段条件查询也会让 cpu 飙升,最终都会导致数据库连接数激增;
-
网关大规模超时。在高并发场景下,大量请求直接操作数据库,数据库连接资源不够用,大量请求处于阻塞状态。
2 SQL 优化和读写分离
为了缓解主数据库的压力,很容易就想到的策略:SQL 优化。通过性能监控平台和 DBA 同学协作分析出业务慢 SQL ,整理出优化方案:
-
合理添加索引;
-
减少多表 JOIN 关联,通过程序组装,减少数据库读压力;
-
减少大事务,尽快释放数据库连接。
另外一个策略是:读写分离。
读写分离的基本原理是让主数据库处理事务性增、改、删操作( INSERT、UPDATE、DELETE),而从数据库处理 SELECT 查询操作。
专车架构团队提供的框架中,支持读写分离,于是数据层架构进化为如下图:

读写分离可以减少主库写压力,同时读从库可水平扩展。当然,读写分离依然有局限性:
-
读写分离可能面临主从延迟的问题,订单服务载客流程中对实时性要求较高,因为担心延迟问题,大量操作依然使用主库查询;
-
读写分离可以缓解读压力,但是写操作的压力随着业务爆发式的增长并没有很有效的缓解。
3 业务领域分库
虽然应用层面做了优化,数据层也做了读写分离,但主库的压力依然很大。接下来,大家不约而同的想到了业务领域分库,也就是:将数据库按业务领域拆分成不同的业务数据库,每个系统仅访问对应业务的数据库。

业务领域分库可以缓解核心订单库的性能压力,同时也减少系统间的相互影响,提升了系统整体稳定性。
随之而来的问题是:原来单一数据库时,简单的使用 JOIN 就可以满足需求,但拆分后的业务数据库在不同的实例上,就不能跨库使用 JOIN 了,因此需要对系统边界重新梳理,业务系统也需要重构 。
重构重点包含两个部分:
-
原来需要 JOIN 关联的查询修改成 RPC 调用,程序中组装数据 ;
-
业务表适当冗余字段,通过消息队列或者异构工具同步。
4 缓存和 MQ
专车服务中,订单服务是并发量和请求量最高,也是业务中最核心的服务。虽然通过业务领域分库,SQL 优化提升了不少系统性能,但订单数据库的写压力依然很大,系统的瓶颈依然很明显。
于是,订单服务引入了 缓存 和 MQ 。
乘客在用户端点击立即叫车,订单服务创建订单,首先保存到数据库后,然后将订单信息同步保存到缓存中。
在订单的载客生命周期里,订单的修改操作先修改缓存,然后发送消息到 MetaQ ,订单落盘服务消费消息,并判断订单信息是否正常(比如有无乱序),若订单数据无误,则存储到数据库中。

核心逻辑有两点:
-
缓存集群中存储最近七天订单详情信息,大量订单读请求直接从缓存获取;
-
在订单的载客生命周期里,写操作先修改缓存,通过消息队列异步落盘,这样消息队列可以起到消峰的作用,同样可以降低数据库的压力。
这次优化提升了订单服务的整体性能,也为后来订单服务库分库分表以及异构打下了坚实的基础。
5 从 SQLServer 到 mysql
业务依然在爆炸增长,每天几十万订单,订单表数据量很快将过亿,数据库天花板迟早会触及。
订单分库分表已成为技术团队的共识。业界很多分库分表方案都是基于 MySQL 数据库,专车技术管理层决定先将订单库整体先从 SQLServer 迁移到 MySQL 。
迁移之前,准备工作很重要 :
-
SQLServer 和 MySQL 两种数据库语法有一些差异,订单服务必须要适配 MySQL 语法。
-
订单 order_id 是主键自增,但在分布式场景中并不合适,需要将订单 id 调整为分布式模式。
当准备工作完成后,才开始迁移。
迁移过程分两部分:历史全量数据迁移 和 增量数据迁移。
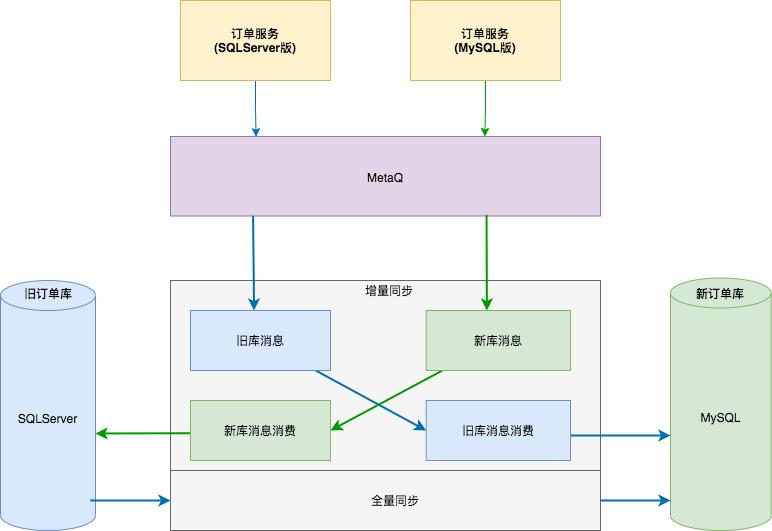
历史数据全量迁移主要是 DBA 同学通过工具将订单库同步到独立的 MySQL 数据库。
增量数据迁移:因为 SQLServer 无 binlog 日志概念,不能使用 maxwell 和 canal 等类似解决方案。订单团队重构了订单服务代码,每次订单写操作的时候,会发送一条 MQ 消息到 MetaQ 。为了确保迁移的可靠性,还需要将新库的数据同步到旧库,也就是需要做到双向同步 。
迁移流程:
-
首先订单服务(SQLServer 版)发送订单变更消息到 MetaQ ,此时并不开启「旧库消息消费」,让消息先堆积在 MetaQ 里;
-
然后开始迁移历史全量数据,当全量迁移完成后,再开启「旧库消息消费」,这样新订单库就可以和旧订单库数据保持同步了;
-
开启「新库消息消费」,然后部署订单服务( MySQL 版),此时订单服务有两个版本同时运行,检测数据无误后,逐步增加新订单服务流量,直到老订单服务完全下线。
6 自研分库分表组件
业界分库分表一般有 proxy 和 client 两种流派。
▍ proxy 模式

代理层分片方案业界有 Mycat ,cobar 等 。
它的优点:应用零改动,和语言无关,可以通过连接共享减少连接数消耗。缺点:因为是代理层,存在额外的时延。
▍ client 模式

应用层分片方案业界有 sharding-jdbc ,TDDL 等。
它的优点:直连数据库,额外开销小,实现简单,轻量级中间件。缺点:无法减少连接数消耗,有一定的侵入性,多数只支持 Java 语言。
神州架构团队选择自研分库分表组件,采用了 client 模式 ,组件命名:SDDL。
订单服务需要引入是 SDDL 的 jar 包,在配置中心配置 数据源信息 ,sharding key ,路由规则 等,订单服务只需要配置一个 datasourceId 即可。
7 分库分表策略
7.1 乘客维度
专车订单数据库的查询主维度是:乘客,乘客端按乘客 user_id 和 订单 order_id 查询频率最高,我们选择 user_id 做为 sharding key ,相同用户的订单数据存储到同一个数据库中。
分库分表组件 SDDL 和阿里开源的数据库中间件 cobar 路由算法非常类似的。
为了便于思维扩展,先简单介绍下 cobar 的分片算法。
假设现在需要将订单表平均拆分到 4 个分库 shard0 ,shard1 ,shard2 ,shard3 。首先将 [0-1023] 平均分为 4 个区段:[0-255],[256-511],[512-767],[768-1023],然后对字符串(或子串,由用户自定义)做 hash, hash 结果对 1024 取模,最终得出的结果 slot 落入哪个区段,便路由到哪个分库。

cobar 的默认路由算法 ,可以和 雪花算法 天然融合在一起, 订单 order_id 使用雪花算法,我们可以将 slot 的值保存在 10 位工作机器 ID 里。

通过订单 order_id 可以反查出 slot , 就可以定位该用户的订单数据存储在哪个分区里。
Integer getWorkerId(Long orderId)
Long workerId = (orderId >> 12) & 0x03ff;
return workerId.intValue();
专车 SDDL 分片算法和 cobar 差异点在于:
-
cobar 支持最大分片数是 1024,而 SDDL 最大支持分库数 1024*8=8192,同样分四个订单库,每个分片的 slot 区间范围是 2048 ;

-
因为要支持 8192 个分片,雪花算法要做一点微调,雪花算法的 10 位工作机器修改成 13 位工作机器,时间戳也调整为:38 位时间戳(由某个时间点开始的毫秒数)。

7.2 司机维度
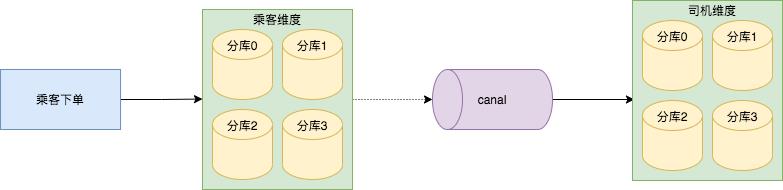
虽然解决了主维度乘客分库分表问题,但专车还有另外一个查询维度,在司机客户端,司机需要查询分配给他的订单信息。
我们已经按照乘客 user_id 作为 sharding key ,若按照司机 driver_id 查询订单的话,需要广播到每一个分库并聚合返回,基于此,技术团队选择将乘客维度的订单数据异构到以司机维度的数据库里。
司机维度的分库分表策略和乘客维度逻辑是一样的,只不过 sharding key 变成了司机 driver_id 。
异构神器 canal 解析乘客维度四个分库的 binlog ,通过 SDDL 写入到司机维度的四个分库里。

这里大家可能有个疑问:虽然可以异构将订单同步到司机维度的分库里,毕竟有些许延迟,如何保证司机在司机端查询到最新的订单数据呢 ?
在缓存和 MQ 这一小节里提到:缓存集群中存储最近七天订单详情信息,大量订单读请求直接从缓存获取。订单服务会缓存司机和当前订单的映射,这样司机端的大量请求就可以直接缓存中获取,而司机端查询订单列表的频率没有那么高,异构复制延迟在 10 毫秒到 30 毫秒之间,在业务上是完全可以接受的。
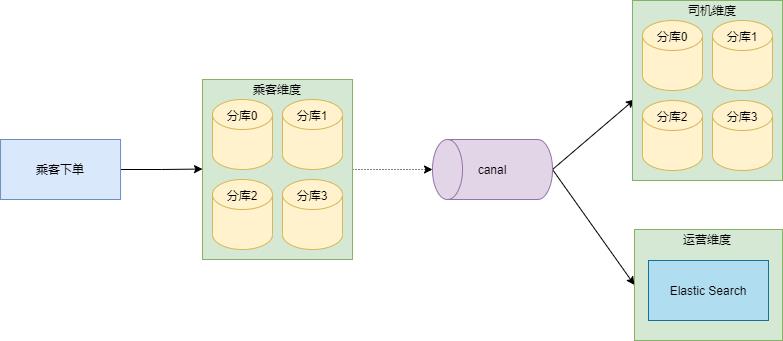
7.3 运营维度
专车管理后台,运营人员经常需要查询订单信息,查询条件会比较复杂,专车技术团队采用的做法是:订单数据落盘在乘客维度的订单分库之后,通过 canal 把数据同步到 Elastic Search。

7.4 小表广播
业务中有一些配置表,存储重要的配置,读多写少。在实际业务查询中,很多业务表会和配置表进行联合数据查询。但在数据库水平拆分后,配置表是无法拆分的。
小表广播的原理是:将小表的所有数据(包括增量更新)自动广播(即复制)到大表的机器上。这样,原来的分布式 JOIN 查询就变成单机本地查询,从而大大提高了效率。
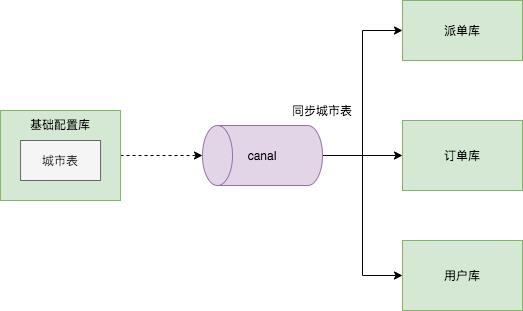
专车场景下,小表广播是非常实用的需求。比如:城市表是非常重要的配置表,数据量非常小,但订单服务,派单服务,用户服务都依赖这张表。
通过 canal 将基础配置数据库城市表同步到订单数据库,派单数据库,用户数据库。

8 平滑迁移
分库分表组件 SDDL 研发完成,并在生产环境得到一定程度的验证后,订单服务从单库 MySQL 模式迁移到分库分表模式条件已经成熟。
迁移思路其实和从 SQLServer 到 MySQL 非常类似。

整体迁移流程:
-
DBA 同学准备乘客维度的四个分库,司机维度的四个分库 ,每个分库都是最近某个时间点的全量数据;
-
八个分库都是全量数据,需要按照分库分表规则删除八个分库的冗余数据 ;
-
开启正向同步,旧订单数据按照分库分表策略落盘到乘客维度的分库,通过 canal 将乘客维度分库订单数据异构复制到司机维度的分库中;
-
开启反向同步,修改订单应用的数据源配置,重启订单服务,订单服务新创建的订单会落盘到乘客维度的分库,通过 canal 将乘客维度分库订单数据异构到全量订单库以及司机维度的数据库;
-
验证数据无误后,逐步更新订单服务的数据源配置,完成整体迁移。
9 数据交换平台
专车订单已完成分库分表,很多细节都值得复盘:
-
全量历史数据迁移需要 DBA 介入 ,技术团队没有成熟的工具或者产品轻松完成;
-
增量数据迁移通过 canal 来实现。随着专车业务的爆发增长,数据库镜像,实时索引构建,分库异构等需求越来越多,虽然 canal 非常优秀,但它还是有瑕疵,比如缺失任务控制台,数据源管理能力,任务级别的监控和报警,操作审计等功能。
面对这些问题,架构团队的目标是打造一个平台,满足各种异构数据源之间的实时增量同步和离线全量同步,支撑公司业务的快速发展。

基于这个目标,架构团队自研了 dataLink 用于增量数据同步,深度定制了阿里开源的 dataX 用于全量数据同步。
10 写到最后
专车架构进化之路并非一帆风顺,也有波折和起伏,但一步一个脚印,专车的技术储备越来越深厚。
2017 年,瑞幸咖啡在神州优车集团内部孵化,专车的这些技术储备大大提升了瑞幸咖啡技术团队的研发效率,并支撑业务的快速发展。 比如瑞幸咖啡的订单数据库最开始规划的时候,就分别按照用户维度,门店维度各拆分了 8 个数据库实例,分库分表组件 SDDL 和 数据交换平台都起到了关键的作用 。
专车架构进化往事:好的架构是进化来的,不是设计来的
很多年前,读了子柳老师的《淘宝技术这十年》。这本书成为了我的架构启蒙书,书中的一句话像种子一样深埋在我的脑海里:“好的架构是进化来的,不是设计来的”。
2015年,我加入神州专车订单研发团队,亲历了专车数据层「架构进化」的过程。这次工作经历对我而言非常有启发性,也让我经常感慨:“好的架构果然是一点点进化来的”。
1 单数据库架构
产品初期,技术团队的核心目标是:“快速实现产品需求,尽早对外提供服务”。
彼时的专车服务都连同一个 SQLServer 数据库,服务层已经按照业务领域做了一定程度的拆分。
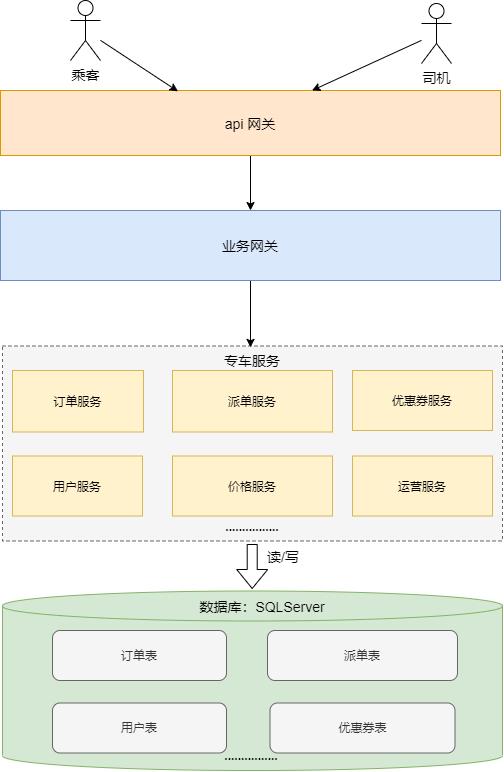
这种架构非常简单,团队可以分开协作,效率也极高。随着专车订单量的不断增长,早晚高峰期,用户需要打车的时候,点击下单后经常无响应。
系统层面来看:
- 数据库瓶颈显现。频繁的磁盘操作导致数据库服务器 IO 消耗增加,同时多表关联,排序,分组,非索引字段条件查询也会让 cpu 飙升,最终都会导致数据库连接数激增;
- 网关大规模超时。在高并发场景下,大量请求直接操作数据库,数据库连接资源不够用,大量请求处于阻塞状态。
2 SQL优化和读写分离
为了缓解主数据库的压力,很容易就想到的策略:SQL优化。通过性能监控平台和 DBA 同学协作分析出业务慢 SQL ,整理出优化方案:
- 合理添加索引;
- 减少多表 JOIN 关联,通过程序组装,减少数据库读压力;
- 减少大事务,尽快释放数据库连接。
另外一个策略是:读写分离。
读写分离的基本原理是让主数据库处理事务性增、改、删操作( INSERT、UPDATE、DELETE),而从数据库处理 SELECT 查询操作。
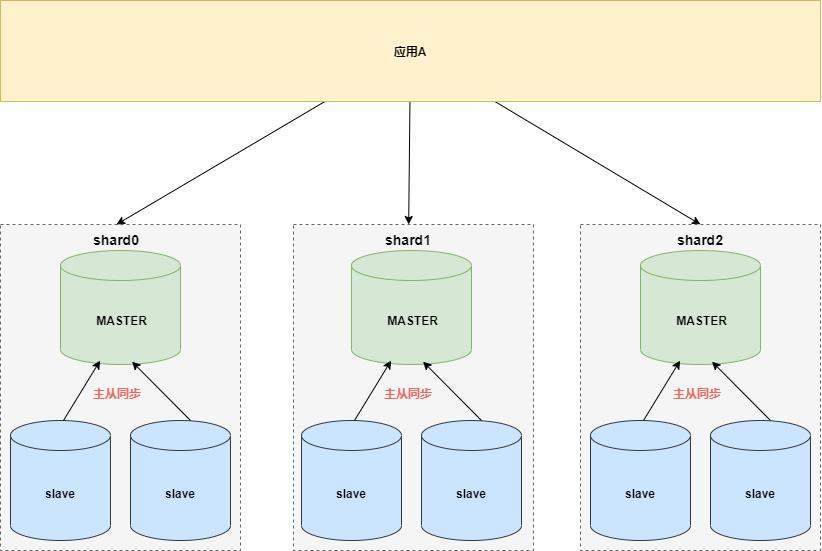
专车架构团队提供的框架中,支持读写分离,于是数据层架构进化为如下图:
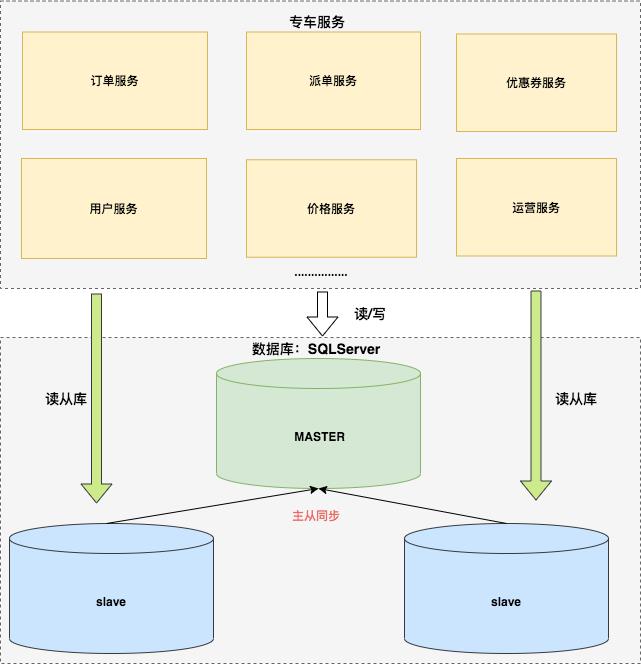
读写分离可以减少主库写压力,同时读从库可水平扩展。当然,读写分离依然有局限性:
- 读写分离可能面临主从延迟的问题,订单服务载客流程中对实时性要求较高,因为担心延迟问题,大量操作依然使用主库查询;
- 读写分离可以缓解读压力,但是写操作的压力随着业务爆发式的增长并没有很有效的缓解。
3 业务领域分库
虽然应用层面做了优化,数据层也做了读写分离,但主库的压力依然很大。接下来,大家不约而同的想到了业务领域分库,也就是:将数据库按业务领域拆分成不同的业务数据库,每个系统仅访问对应业务的数据库。
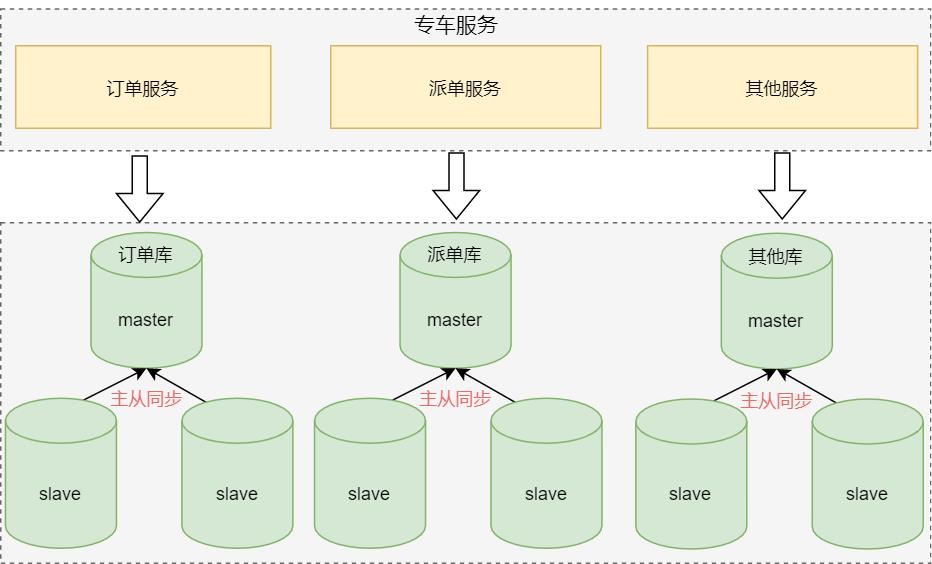
业务领域分库可以缓解核心订单库的性能压力,同时也减少系统间的相互影响,提升了系统整体稳定性。
随之而来的问题是:原来单一数据库时,简单的使用 JOIN 就可以满足需求,但拆分后的业务数据库在不同的实例上,就不能跨库使用 JOIN了,因此需要对系统边界重新梳理,业务系统也需要重构 。
重构重点包含两个部分:
- 原来需要 JOIN 关联的查询修改成 RPC 调用,程序中组装数据 ;
- 业务表适当冗余字段,通过消息队列或者异构工具同步。
4 缓存和MQ
专车服务中,订单服务是并发量和请求量最高,也是业务中最核心的服务。虽然通过业务领域分库,SQL 优化提升了不少系统性能,但订单数据库的写压力依然很大,系统的瓶颈依然很明显。
于是,订单服务引入了 缓存 和 MQ 。
乘客在用户端点击立即叫车,订单服务创建订单,首先保存到数据库后,然后将订单信息同步保存到缓存中。
在订单的载客生命周期里,订单的修改操作先修改缓存,然后发送消息到 MetaQ ,订单落盘服务消费消息,并判断订单信息是否正常(比如有无乱序),若订单数据无误,则存储到数据库中。
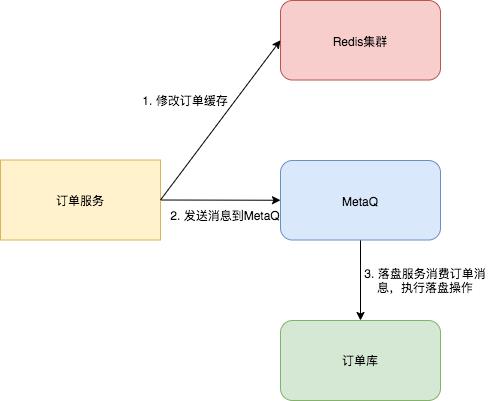
核心逻辑有两点:
- 缓存集群中存储最近七天订单详情信息,大量订单读请求直接从缓存获取;
- 在订单的载客生命周期里,写操作先修改缓存,通过消息队列异步落盘,这样消息队列可以起到消峰的作用,同样可以降低数据库的压力。
这次优化提升了订单服务的整体性能,也为后来订单服务库分库分表以及异构打下了坚实的基础。
5 从 SQLServer 到 MySQL
业务依然在爆炸增长,每天几十万订单,订单表数据量很快将过亿,数据库天花板迟早会触及。
订单分库分表已成为技术团队的共识。业界很多分库分表方案都是基于 MySQL 数据库,专车技术管理层决定先将订单库整体先从 SQLServer 迁移到 MySQL 。
迁移之前,准备工作很重要 :
- SQLServer 和 MySQL 两种数据库语法有一些差异,订单服务必须要适配 MySQL 语法。
- 订单 order_id 是主键自增,但在分布式场景中并不合适,需要将订单 id 调整为分布式模式。
当准备工作完成后,才开始迁移。
迁移过程分两部分:历史全量数据迁移 和 增量数据迁移。
历史数据全量迁移主要是 DBA 同学通过工具将订单库同步到独立的 MySQL 数据库。
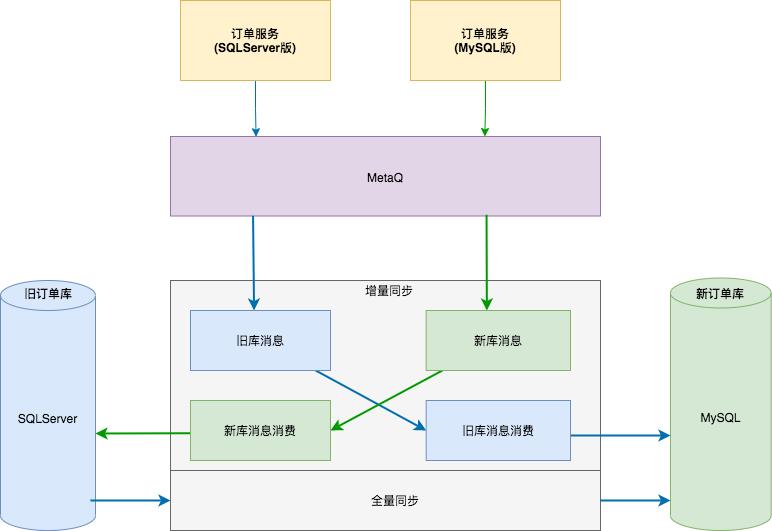
增量数据迁移:因为 SQLServer 无 binlog 日志概念,不能使用 maxwell 和 canal 等类似解决方案。订单团队重构了订单服务代码,每次订单写操作的时候,会发送一条 MQ 消息到 MetaQ 。为了确保迁移的可靠性,还需要将新库的数据同步到旧库,也就是需要做到双向同步 。
迁移流程:
- 首先订单服务(SQLServer版)发送订单变更消息到 MetaQ ,此时并不开启「旧库消息消费」,让消息先堆积在 MetaQ 里;
- 然后开始迁移历史全量数据,当全量迁移完成后,再开启「旧库消息消费」,这样新订单库就可以和旧订单库数据保持同步了;
- 开启「新库消息消费」,然后部署订单服务( MySQL 版),此时订单服务有两个版本同时运行,检测数据无误后,逐步增加新订单服务流量,直到老订单服务完全下线。
6 自研分库分表组件
业界分库分表一般有 proxy 和 client 两种流派。
▍ proxy模式
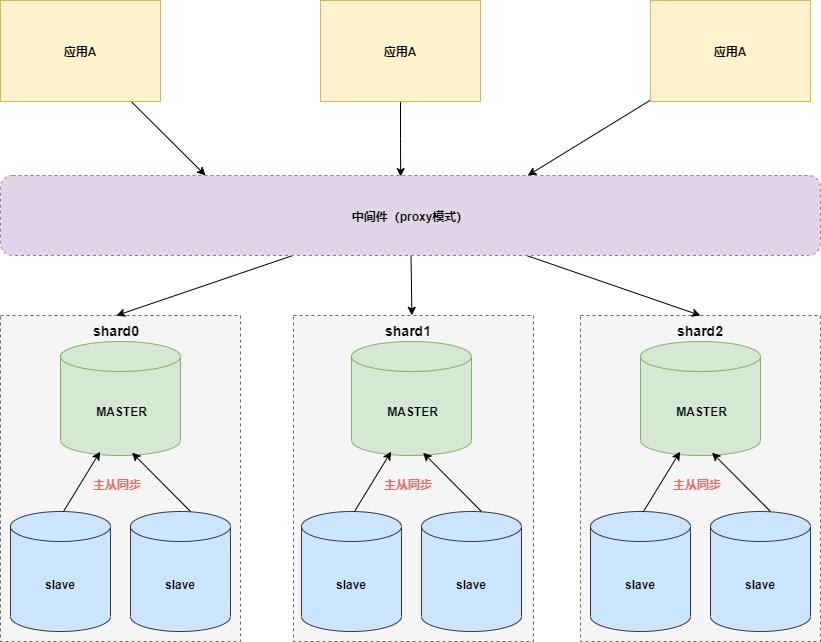
代理层分片方案业界有 Mycat ,cobar 等 。
它的优点:应用零改动,和语言无关,可以通过连接共享减少连接数消耗。缺点:因为是代理层,存在额外的时延。
▍ client模式
应用层分片方案业界有 sharding-jdbc ,TDDL 等。
它的优点:直连数据库,额外开销小,实现简单,轻量级中间件。缺点:无法减少连接数消耗,有一定的侵入性,多数只支持Java语言。
神州架构团队选择自研分库分表组件,采用了 client 模式 ,组件命名:SDDL。
订单服务需要引入是 SDDL 的 jar 包,在配置中心配置 数据源信息 ,sharding key ,路由规则 等,订单服务只需要配置一个 datasourceId 即可。
7 分库分表策略
7.1 乘客维度
专车订单数据库的查询主维度是:乘客,乘客端按乘客 user_id 和 订单 order_id 查询频率最高,我们选择 user_id 做为 sharding key ,相同用户的订单数据存储到同一个数据库中。
分库分表组件 SDDL 和阿里开源的数据库中间件 cobar 路由算法非常类似的。
为了便于思维扩展,先简单介绍下 cobar 的分片算法。
假设现在需要将订单表平均拆分到4个分库 shard0 ,shard1 ,shard2 ,shard3 。首先将 [0-1023] 平均分为4个区段:[0-255],[256-511],[512-767],[768-1023],然后对字符串(或子串,由用户自定义)做 hash, hash 结果对1024取模,最终得出的结果 slot 落入哪个区段,便路由到哪个分库。
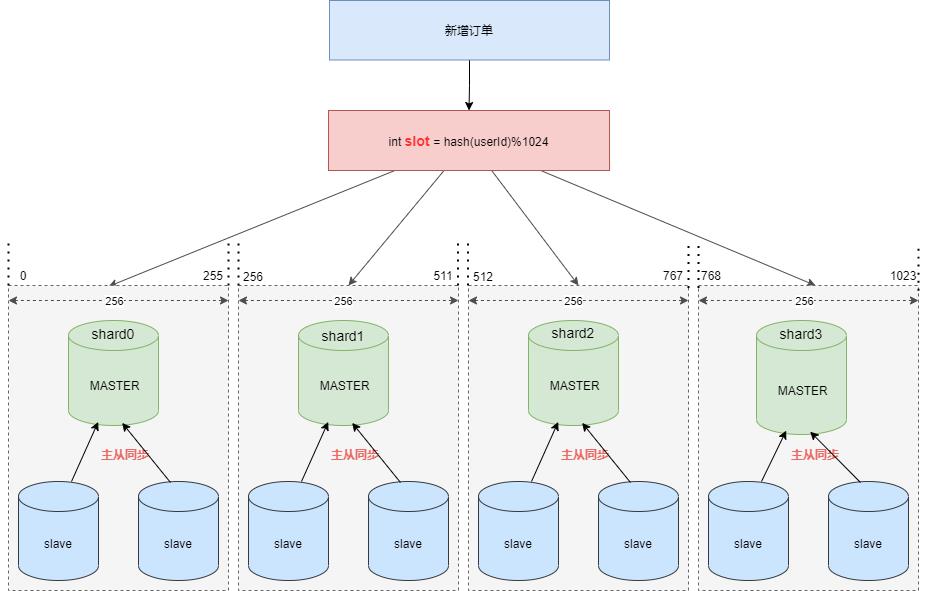
cobar 的默认路由算法 ,可以和 雪花算法 天然融合在一起, 订单 order_id 使用雪花算法,我们可以将 slot 的值保存在 10位工作机器ID 里。
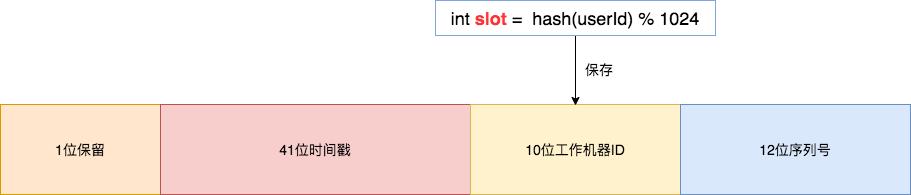
通过订单 order_id 可以反查出 slot , 就可以定位该用户的订单数据存储在哪个分区里。
Integer getWorkerId(Long orderId)
Long workerId = (orderId >> 12) & 0x03ff;
return workerId.intValue();
专车 SDDL 分片算法和 cobar 差异点在于:
- cobar 支持最大分片数是1024,而 SDDL 最大支持分库数1024*8=8192,同样分四个订单库,每个分片的 slot 区间范围是2048 ;
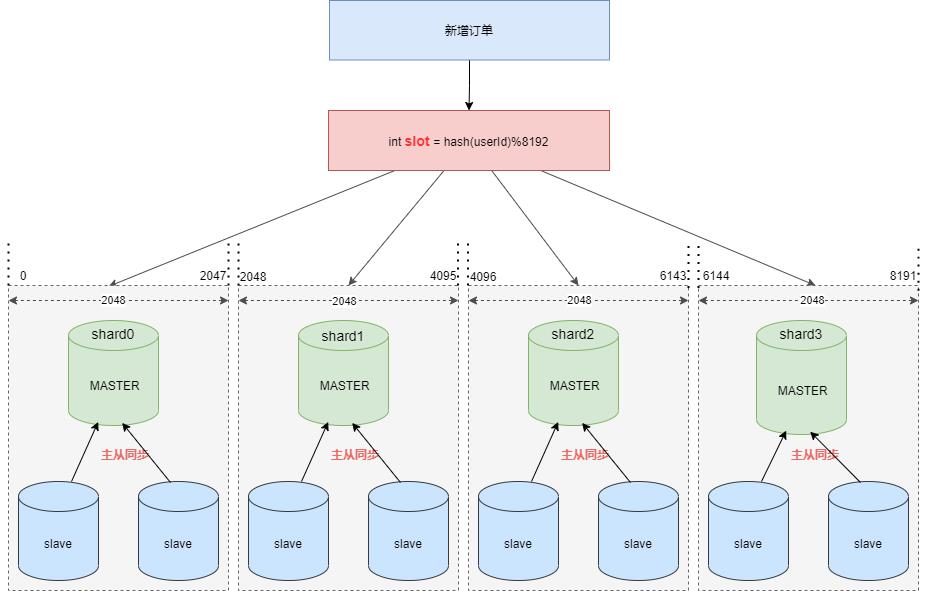
- 因为要支持8192个分片,雪花算法要做一点微调,雪花算法的10位工作机器修改成13位工作机器,时间戳也调整为:38位时间戳(由某个时间点开始的毫秒数)。

7.2 司机维度
虽然解决了主维度乘客分库分表问题,但专车还有另外一个查询维度,在司机客户端,司机需要查询分配给他的订单信息。
我们已经按照乘客 user_id 作为 sharding key ,若按照司机 driver_id 查询订单的话,需要广播到每一个分库并聚合返回,基于此,技术团队选择将乘客维度的订单数据异构到以司机维度的数据库里。
司机维度的分库分表策略和乘客维度逻辑是一样的,只不过 sharding key 变成了司机 driver_id 。
异构神器 canal 解析乘客维度四个分库的 binlog ,通过 SDDL 写入到司机维度的四个分库里。
这里大家可能有个疑问:虽然可以异构将订单同步到司机维度的分库里,毕竟有些许延迟,如何保证司机在司机端查询到最新的订单数据呢 ?
在缓存和MQ这一小节里提到:缓存集群中存储最近七天订单详情信息,大量订单读请求直接从缓存获取。订单服务会缓存司机和当前订单的映射,这样司机端的大量请求就可以直接缓存中获取,而司机端查询订单列表的频率没有那么高,异构复制延迟在10毫秒到30毫秒之间,在业务上是完全可以接受的。
7.3 运营维度
专车管理后台,运营人员经常需要查询订单信息,查询条件会比较复杂,专车技术团队采用的做法是:订单数据落盘在乘客维度的订单分库之后,通过 canal 把数据同步到Elastic Search。
7.4 小表广播
业务中有一些配置表,存储重要的配置,读多写少。在实际业务查询中,很多业务表会和配置表进行联合数据查询。但在数据库水平拆分后,配置表是无法拆分的。
小表广播的原理是:将小表的所有数据(包括增量更新)自动广播(即复制)到大表的机器上。这样,原来的分布式 JOIN 查询就变成单机本地查询,从而大大提高了效率。
专车场景下,小表广播是非常实用的需求。比如:城市表是非常重要的配置表,数据量非常小,但订单服务,派单服务,用户服务都依赖这张表。
通过 canal 将基础配置数据库城市表同步到订单数据库,派单数据库,用户数据库。
8 平滑迁移
分库分表组件 SDDL 研发完成,并在生产环境得到一定程度的验证后,订单服务从单库 MySQL 模式迁移到分库分表模式条件已经成熟。
迁移思路其实和从 SQLServer 到 MySQL 非常类似。
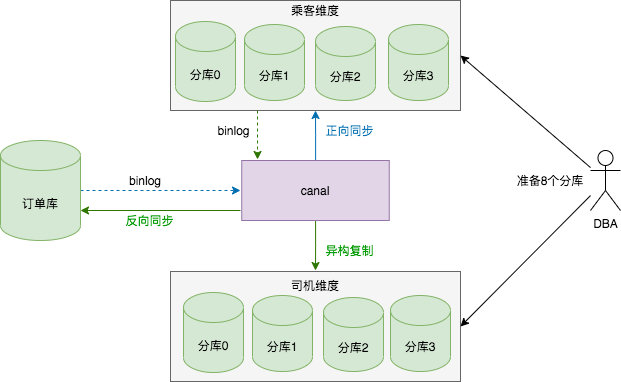
整体迁移流程:
- DBA 同学准备乘客维度的四个分库,司机维度的四个分库 ,每个分库都是最近某个时间点的全量数据;
- 八个分库都是全量数据,需要按照分库分表规则删除八个分库的冗余数据 ;
- 开启正向同步,旧订单数据按照分库分表策略落盘到乘客维度的分库,通过 canal 将乘客维度分库订单数据异构复制到司机维度的分库中;
- 开启反向同步,修改订单应用的数据源配置,重启订单服务,订单服务新创建的订单会落盘到乘客维度的分库,通过 canal 将乘客维度分库订单数据异构到全量订单库以及司机维度的数据库;
- 验证数据无误后,逐步更新订单服务的数据源配置,完成整体迁移。
9 数据交换平台
专车订单已完成分库分表 , 很多细节都值得复盘:
- 全量历史数据迁移需要 DBA 介入 ,技术团队没有成熟的工具或者产品轻松完成;
- 增量数据迁移通过 canal 来实现。随着专车业务的爆发增长,数据库镜像,实时索引构建,分库异构等需求越来越多,虽然canal 非常优秀,但它还是有瑕疵,比如缺失任务控制台,数据源管理能力,任务级别的监控和报警,操作审计等功能。
面对这些问题,架构团队的目标是打造一个平台,满足各种异构数据源之间的实时增量同步和离线全量同步,支撑公司业务的快速发展。
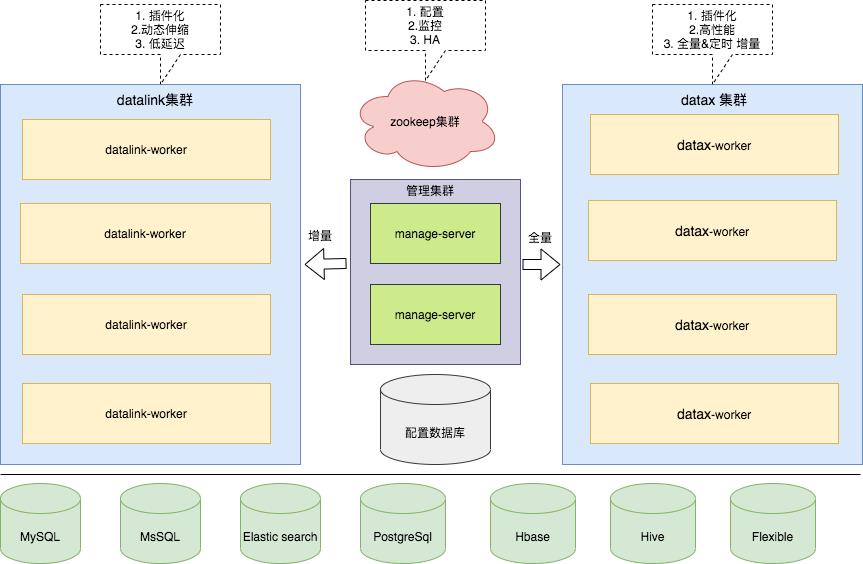
基于这个目标,架构团队自研了 dataLink 用于增量数据同步,深度定制了阿里开源的 dataX 用于全量数据同步。
10 写到最后
专车架构进化之路并非一帆风顺,也有波折和起伏,但一步一个脚印,专车的技术储备越来越深厚。
2017年,瑞幸咖啡在神州优车集团内部孵化,专车的这些技术储备大大提升了瑞幸咖啡技术团队的研发效率,并支撑业务的快速发展。 比如瑞幸咖啡的订单数据库最开始规划的时候,就分别按照用户维度,门店维度各拆分了8个数据库实例,分库分表组件 SDDL 和 数据交换平台都起到了关键的作用 。
好了,这篇文字就写到这里了。 我们下期见。
如果我的文章对你有所帮助,还请帮忙点赞、在看、转发一下,你的支持会激励我输出更高质量的文章,非常感谢!

以上是关于好的架构是进化来的,不是设计来的的主要内容,如果未能解决你的问题,请参考以下文章