MapReduce课程设计——好友推荐功能
Posted 中發白白白
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MapReduce课程设计——好友推荐功能相关的知识,希望对你有一定的参考价值。
 1准备工作
1准备工作
1.1项目说明
- 互为推荐关系
- 非好友的两个人之间存在相同好友则互为推荐关系
- 朋友圈两个非好友的人,存在共同好友的人数越多,越值得推荐
- 存在一个共同好友,值为1;存在多个好友,值累加
1.2程序需求
1.2.1需求
- 程序要求,给每个推荐可能认识的人
- 虎威推荐关系值越高,越值得推荐
- 每个用户,推荐值越高的可能认识的人排在前面
1.2.2数据
- 数据使用空格进行分割
- 每行是一个用户以及其对应的好友
- 每行的第一列名字是用户的名字,后面的是其对应的好友
| 用户 | 好友 | |||
|---|---|---|---|---|
| xiaoming | laowang | renhua | linzhiling | |
| laowang | xiaoming | fengjie | ||
| renhua | xiaoming | ligang | fengjie | |
| linzhiling | xiaoming | ligang | fengjie | guomeimei |
| ligang | renhua | fengjie | linzhiling | |
| guomeimei | fengjie | linzhiling | ||
| fengjie | renhua | laowang | linzhiling | guomeimei |
1.3在本地创建文本文件(名字任意)

1.4创建testfriend目录并cd到此目录下
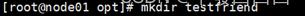
1.5将此文件直接拖进node01
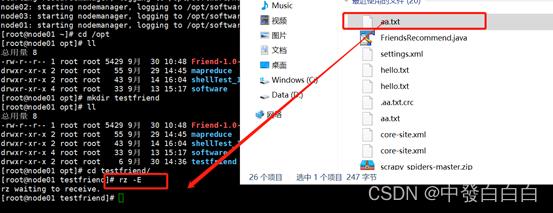
2项目实操
2.1在IDEA中导入依赖与插件
- 依赖
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.9.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>2.9.2</version>
<scope>provided</scope>
</dependency>
</dependencies>
- 插件
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<configuration>
<archive>
<manifest>
<mainClass>com.lee.friends.Friendscount</mainClass>
</manifest>
</archive>
</configuration>
</plugin>
</plugins>
</build>
2.2创建类
(1)创建friendsmapper
package com.lee.friends;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class friendsmapper extends Mapper<Object, Text, Text, IntWritable>
public void map(Object key, Text value, Context context) throws IOException, InterruptedException
String[] friends = value.toString().split(" ");
for(int i=0; i < friends.length; i++)
String self = friends[i];
for(int j=i+1; j < friends.length; j++)
if(i == 0)
// 直接好友
String directFriend = friends[j];
Text directFriendKey = new Text(sort(self, directFriend));
context.write(directFriendKey, new IntWritable(0));
else
// 可能是间接好友
String indirectFriend = friends[j];
Text indirectFriendKey = new Text(sort(self, indirectFriend));
context.write(indirectFriendKey, new IntWritable(1));
private String sort(String self, String directFriend)
//compareToIgnoreCase() 方法用于按字典顺序比较两个字符串,不考虑大小写
if(self.compareToIgnoreCase(directFriend) < 0)
return directFriend + " " + self;
return self + " " + directFriend;
(2)创建friendsreducer
package com.lee.friends;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class friendsreducer extends Reducer<Text, IntWritable, Text, IntWritable>
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException
int sum = 0;
boolean isDirectFriend = false;
for(IntWritable value : values)
if(value.get() == 0)
isDirectFriend = true;
break;
sum = sum + value.get();
if(!isDirectFriend)
context.write(key, new IntWritable(sum));
(3)创建friendscount
package com.lee.friends;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class Friendscount
public static void main(String[] args) throws Exception
//获取虚拟机配置信息
Configuration configuration = new Configuration();
//创建Job对象
Job job = Job.getInstance(configuration);
job.setJarByClass(Friendscount.class);
//Map端
job.setMapperClass(friendsmapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//combiner组件
// job.setCombinerClass(FriendsRecommendReduce.class);
//Reduce端
job.setReducerClass(friendsreducer.class);
//文件的输入路径
Path inputPath = new Path("/test/aa.txt");
FileInputFormat.addInputPath(job, inputPath);
//结果的输出路经
Path outputPath = new Path("/test/bb.txt");
//若路径存在则将其删除
if (outputPath.getFileSystem(configuration).exists(outputPath))
outputPath.getFileSystem(configuration).delete(outputPath);
FileOutputFormat.setOutputPath(job, outputPath);
System.exit(job.waitForCompletion(true) ? 0 : 1);
注意:在pom.xml中需要指出Friendscount类的具体路径,在类上按ctrl键可以跳转即可。
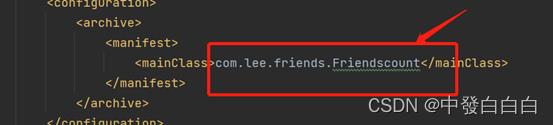
2.2 在父级pom.xml中,对于其余的module进行注释,方便下一步打包
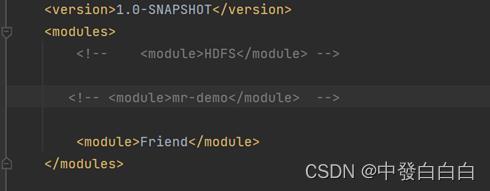
2.3找到侧面的maven并点击,找到package,对整个Friend项目进行打包
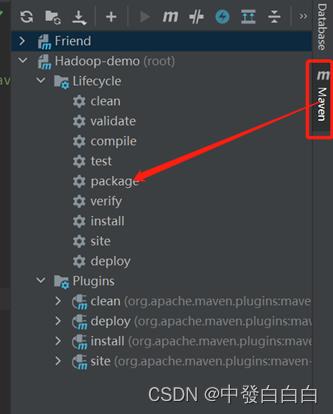
2.4表示完成(如图所示)
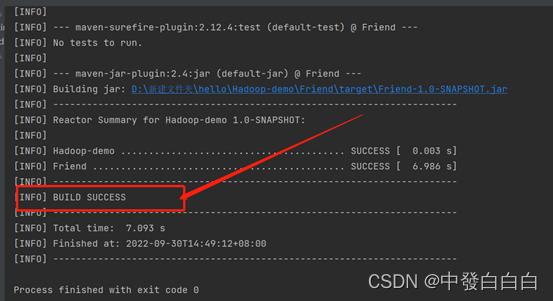
3结果与展示
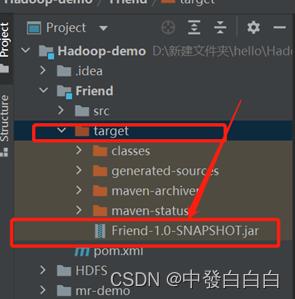
3.1在target目录下会生成一个项目jar包
3.2在xshell开启dfs和yarn


3.3查看根目录下的路径

3.4上传aa.txt文件到test目录

3.5访问http://node01:50070(如图所示)
3.6把jar包直接拖入到Xshell中
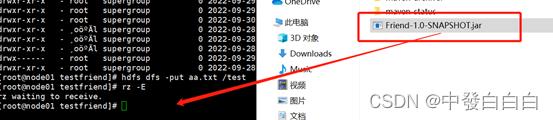
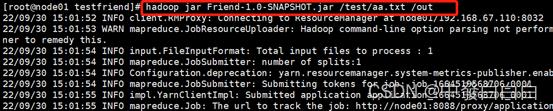
3.7输入hadoop jar Friend-1.0-SNAPSHOT.jar /test/aa.txt /out命令运行jar包
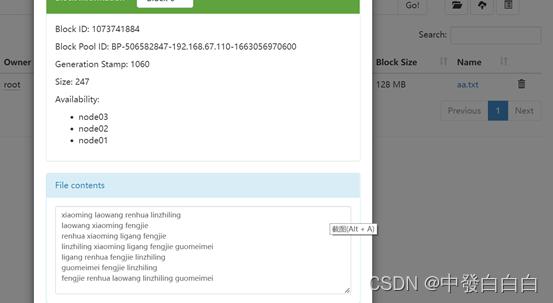
3.8在生成的bb.txt文件中查看part-r-00000文件,即可查看最终结果,(如下图所示)

以上是关于MapReduce课程设计——好友推荐功能的主要内容,如果未能解决你的问题,请参考以下文章
第3节 mapreduce高级:23课程大纲&共同好友求取步骤二