利用MapReduce仿QQ音乐实现“今日推荐歌曲“系统
Posted MichaelIp
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了利用MapReduce仿QQ音乐实现“今日推荐歌曲“系统相关的知识,希望对你有一定的参考价值。
大数据无处不在,推荐系统无处不在。
QQ音乐的今日推荐歌曲;人人网的好友推荐;新浪微博的你可能感觉兴趣的人;优酷,土豆的电影推荐;豆瓣的图书推荐;大从点评的餐饮推荐;世纪佳缘的相亲推荐;天际网的职业推荐等都用到了大数据。
今天利用MapReduce简单写个仿QQ音乐的推荐系统,希望能给在座各位在工作中或面试中一点帮助!转载请注明出处:Michael孟良
今日推荐歌曲
原理:
通过历史对歌曲操作记录,计算得出每首歌相对其他歌曲同时出现在同一用户的次数,每件歌曲都有自己相对全部歌曲的同现列表,用户会对部分歌曲有过点击,收藏等实际操作,经过计算会得到用户对这部分歌曲的评分向量列表。
使用用户评分向量列表中的分值:
依次乘以每首歌同现列表中该分值的代表歌曲的同现值
求和便是该歌曲的推荐向量
具体算法:
推荐系统——协同过滤(Collaborative Filtering)算法
UserCF
基于用户的协同过滤,通过不同用户对歌曲的评分来评测用户之间的相似性,基于用户之间的相似性做出推荐。简单来讲就是:给用户推荐和他兴趣相似的其他用户喜欢的歌曲。
基于用户的协同过滤
基于用户的协同过滤
-ItemCF
基于item的协同过滤,通过用户对不同item的评分来评测item之间的相似性,基于item之间的相似性做出推荐。简单来讲就是:给用户推荐和他之前喜欢的歌曲相似的歌曲。
基于item的协同过滤
基于item的协同过滤
—Co-occurrence Matrix(同现矩阵)和User Preference Vector(用户评分向量)相乘得到的这个Recommended Vector(推荐向量)
—基于全量数据的统计,产生同现矩阵
1.体现歌曲间的关联性
2.每首歌都有自己对其他全部歌曲的关联性(每件歌曲的特征)
用户评分向量体现的是用户对一些歌曲的评分
任一歌曲需要:
1.用户评分向量乘以基于该歌曲的其他歌曲关联值
2.求和得出针对该歌曲的推荐向量
3.排序取TopN即可
公式
同现矩阵乘以用户评分
好了,逻辑知道了,怎么把它搬到代码中,我们一步一步来:
数据:
item_id,user_id,action,vtime
i161,u2625,click,2018/8/18 15:03
i161,u2626,click,2018/8/23 22:40
i161,u2627,click,2018/8/25 19:09
i161,u2628,click,2018/8/28 21:35
i161,u2629,click,2018/8/27 16:33
i161,u2630,click,2018/8/5 18:45
i161,u2631,click,2018/8/29 16:57
i161,u2632,click,2018/8/24 21:58
i161,u2633,click,2018/8/25 22:41
i161,u2634,click,2018/8/16 13:30
i161,u2635,click,2018/8/20 9:23
i161,u2636,click,2018/8/21 1:00
i161,u2637,click,2018/8/24 22:51
…
…
…
歌曲id:item_id
用户id:user_id
对歌曲操作:action
操作时间:vtime
代码:
启动类StartRun
public class StartRun
public static void main(String[] args)
Configuration config = new Configuration(true);
config.set("mapreduce.framework.name", "local");
config.set("mapreduce.app-submission.cross-platform", "true");
// config.set(“fs.defaultFS”, “hdfs://node1:8020”);
// config.set(“yarn.resourcemanager.hostname”, “node3”);
// 所有mr的输入和输出目录定义在map集合中
Map<String, String> paths = new HashMap<String, String>();
paths.put("Step1Input", "/user/root/m_log");
paths.put("Step1Output", "/data/itemcf/output/step1");
paths.put("Step2Input", paths.get("Step1Output"));
paths.put("Step2Output", "/data/itemcf/output/step2");
paths.put("Step3Input", paths.get("Step2Output"));
paths.put("Step3Output", "/data/itemcf/output/step3");
paths.put("Step4Input1", paths.get("Step2Output"));
paths.put("Step4Input2", paths.get("Step3Output"));
paths.put("Step4Output", "/data/itemcf/output/step4");
paths.put("Step5Input", paths.get("Step4Output"));
paths.put("Step5Output", "/data/itemcf/output/step5");
paths.put("Step6Input", paths.get("Step5Output"));
paths.put("Step6Output", "/data/itemcf/output/step6");
Step1.run(config, paths);
// Step2.run(config, paths);
// Step3.run(config, paths);
// Step4.run(config, paths);
// Step5.run(config, paths);
// Step6.run(config, paths);
public static Map<String, Integer> R = new HashMap<String, Integer>();
static
R.put("click", 1);
R.put("share", 2);
R.put("like", 3);
R.put("download", 4);
我们分为6步:
第一步:
public class Step1
public static boolean run(Configuration config, Map<String, String> paths)
try
FileSystem fs = FileSystem.get(config);
Job job = Job.getInstance(config);
job.setJobName("step1");
// config.set(“mapred.jar”, “D:\\MR\\item.jar”);
job.setJarByClass(Step1.class);
job.setMapperClass(Step1_Mapper.class);
job.setReducerClass(Step1_Reducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
FileInputFormat.addInputPath(job, new Path(paths.get("Step1Input")));
Path outpath = new Path(paths.get("Step1Output"));
if (fs.exists(outpath))
fs.delete(outpath, true);
FileOutputFormat.setOutputPath(job, outpath);
boolean f = job.waitForCompletion(true);
return f;
catch (Exception e)
e.printStackTrace();
return false;
static class Step1_Mapper extends Mapper<LongWritable, Text, Text, NullWritable>
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException
if (key.get() != 0)
context.write(value, NullWritable.get());
static class Step1_Reducer extends Reducer<Text, IntWritable, Text, NullWritable>
@Override
protected void reduce(Text key, Iterable<IntWritable> i, Context context)
throws IOException, InterruptedException
context.write(key, NullWritable.get());
第一步去重,一进一出,没什么好说的。
第二步:
public class Step2
public static boolean run(Configuration config, Map<String, String> paths)
try
FileSystem fs = FileSystem.get(config);
Job job = Job.getInstance(config);
job.setJobName("step2");
job.setJarByClass(StartRun.class);
job.setMapperClass(Step2_Mapper.class);
job.setReducerClass(Step2_Reducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(paths.get("Step2Input")));
Path outpath = new Path(paths.get("Step2Output"));
if (fs.exists(outpath))
fs.delete(outpath, true);
FileOutputFormat.setOutputPath(job, outpath);
boolean f = job.waitForCompletion(true);
return f;
catch (Exception e)
e.printStackTrace();
return false;
static class Step2_Mapper extends Mapper<LongWritable, Text, Text, Text>
// 如果使用:用戶+歌曲的id,同时作为输出key,更好
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException
//i1,u2723,click,2014/9/14 9:31
String[] tokens = value.toString().split(",");
String item = tokens[0];
String user = tokens[1];
String action = tokens[2];
Text k = new Text(user);
Integer rv = StartRun.R.get(action);
// if(rv!=null)
Text v = new Text(item + ":" + rv.intValue());
//u2750 i160:1
context.write(k, v);
static class Step2_Reducer extends Reducer<Text, Text, Text, Text>
@Override
protected void reduce(Text key, Iterable<Text> i, Context context)
throws IOException, InterruptedException
Map<String, Integer> r = new HashMap<String, Integer>();
//迭代同一用户关注的歌曲的id
for (Text value : i)
//u2750 i160:1
String[] vs = value.toString().split(":");
String item = vs[0];
Integer action = Integer.parseInt(vs[1]);
action = ((Integer) (r.get(item) == null ? 0 : r.get(item))).intValue() + action;
r.put(item, action);
StringBuffer sb = new StringBuffer();
for (Entry<String, Integer> entry : r.entrySet())
sb.append(entry.getKey() + ":" + entry.getValue().intValue() + ",");
//u2756 i105:1,i79:1,i341:1,i319:1,i332:1,i160:1,i342:1,i94:1,
context.write(key, new Text(sb.toString()));
第二步,按用户分组,计算所有歌曲的id出现的组合列表,得到用户对歌曲的id的喜爱度得分矩阵。
运行结果:
第二步
第三步:
public class Step3
private final static Text K = new Text();
private final static IntWritable V = new IntWritable(1);
public static boolean run(Configuration config, Map<String, String> paths)
try
FileSystem fs = FileSystem.get(config);
Job job = Job.getInstance(config);
job.setJobName("step3");
job.setJarByClass(StartRun.class);
job.setMapperClass(Step3_Mapper.class);
job.setReducerClass(Step3_Reducer.class);
job.setCombinerClass(Step3_Reducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
FileInputFormat
.addInputPath(job, new Path(paths.get("Step3Input")));
Path outpath = new Path(paths.get("Step3Output"));
if (fs.exists(outpath))
fs.delete(outpath, true);
FileOutputFormat.setOutputPath(job, outpath);
boolean f = job.waitForCompletion(true);
return f;
catch (Exception e)
e.printStackTrace();
return false;
// 第二个MR执行的结果--作为本次MR的输入 样本: u2837 i541:1,i331:1,i314:1,i125:1,
static class Step3_Mapper extends
Mapper<LongWritable, Text, Text, IntWritable>
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException
String[] tokens = value.toString().split("\\t");
String[] items = tokens[1].split(",");
//嵌套循环,每一个歌曲与其他歌曲组合输出一次,val的值为1
//WC的思维逻辑
for (int i = 0; i < items.length; i++)
String itemA = items[i].split(":")[0];
for (int j = 0; j < items.length; j++)
String itemB = items[j].split(":")[0];
K.set(itemA + ":" + itemB);
context.write(K, V);
static class Step3_Reducer extends
Reducer<Text, IntWritable, Text, IntWritable>
@Override
protected void reduce(Text key, Iterable<IntWritable> i, Context context)
throws IOException, InterruptedException
int sum = 0;
for (IntWritable v : i)
sum = sum + v.get();
V.set(sum);
context.write(key, V);
// 执行结果
// i100:i181 1
// i100:i184 2
第三步,对歌曲id组合列表进行计数,建立歌曲id的同现矩阵。
运行加过如下:
第三步
第四步:
public class Step4
public static boolean run(Configuration config, Map<String, String> paths)
try
FileSystem fs = FileSystem.get(config);
Job job = Job.getInstance(config);
job.setJobName(“step4”);
job.setJarByClass(StartRun.class);
job.setMapperClass(Step4_Mapper.class);
job.setReducerClass(Step4_Reducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
FileInputFormat.setInputPaths(job,
new Path[] new Path(paths.get("Step4Input1")),
new Path(paths.get("Step4Input2")) );
Path outpath = new Path(paths.get("Step4Output"));
if (fs.exists(outpath))
fs.delete(outpath, true);
FileOutputFormat.setOutputPath(job, outpath);
boolean f = job.waitForCompletion(true);
return f;
catch (Exception e)
e.printStackTrace();
return false;
static class Step4_Mapper extends Mapper<LongWritable, Text, Text, Text>
private String flag;// A同现矩阵 or B得分矩阵
// 每个maptask,初始化时调用一次
@Override
protected void setup(Context context) throws IOException,
InterruptedException
FileSplit split = (FileSplit) context.getInputSplit();
flag = split.getPath().getParent().getName();// 判断读的数据集
System.out.println(flag + "**********************");
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException
String[] tokens = Pattern.compile("[\\t,]").split(value.toString());
if (flag.equals("step3")) // 同现矩阵
// 样本: i100:i181 1
// i100:i184 2
String[] v1 = tokens[0].split(":");
String itemID1 = v1[0];
String itemID2 = v1[1];
String num = tokens[1];
Text k = new Text(itemID1);// 以前一个歌曲id为key 比如i100
Text v = new Text("A:" + itemID2 + "," + num);// A:i109,1
// 样本: i100 A:i181,1
context.write(k, v);
else if (flag.equals("step2")) // 用户对歌曲id喜爱得分矩阵
// 样本: u24 i64:1,i218:1,i185:1,
String userID = tokens[0];
for (int i = 1; i < tokens.length; i++)
String[] vector = tokens[i].split(":");
String itemID = vector[0];// 歌曲idid
String pref = vector[1];// 喜爱分数
Text k = new Text(itemID); // 以歌曲id为key 比如:i100
Text v = new Text("B:" + userID + "," + pref); // B:u401,2
// 样本: i64 B:u24,1
context.write(k, v);
static class Step4_Reducer extends Reducer<Text, Text, Text, Text>
@Override
protected void reduce(Text key, Iterable
throws IOException, InterruptedException
// A同现矩阵 or B得分矩阵
// 某一个歌曲id,针对它和其他所有歌曲id的同现次数,都在mapA集合中
Map<String, Integer> mapA = new HashMap<String, Integer>();
//和该歌曲id(key中的itemID)同现的其他歌曲id的同现集合//
//其他歌曲idID为map的key,同现数字为值
Map<String, Integer> mapB = new HashMap<String, Integer>();
//该歌曲id(key中的itemID),所有用户的推荐权重分数
for (Text line : values)
String val = line.toString();
if (val.startsWith("A:")) // 表示歌曲id同现数字// 样本: i100 A:i181,1
String[] kv = Pattern.compile("[\\t,]").split(val.substring(2));
try
mapA.put(kv[0], Integer.parseInt(kv[1]));//mapA:"i181" -> "1"
catch (Exception e)
e.printStackTrace();
else if (val.startsWith("B:")) // 样本: i64 B:u24,1
String[] kv = Pattern.compile("[\\t,]").split(
val.substring(2));
try
mapB.put(kv[0], Integer.parseInt(kv[1]));//mapB:"u24" -> "1"
catch (Exception e)
e.printStackTrace();
double result = 0;
//同现矩阵A
Iterator<String> iter = mapA.keySet().iterator();
//MR原语特征,这里只有一种歌曲的同现列表
while (iter.hasNext())
String mapk = iter.next();// itemID
int num = mapA.get(mapk).intValue();
Iterator<String> iterb = mapB.keySet().iterator();
//MR原语特征,这里是所有用户的同一歌曲的评分,迭代之
while (iterb.hasNext()) //迭代用户名
String mapkb = iterb.next();// userID
int pref = mapB.get(mapkb).intValue();
//注意这里的计算思维理解:
//针对A歌曲
//使用用户对A歌曲的分值
//逐一乘以与A歌曲有同现的歌曲的次数
//但是计算推荐向量的时候需要的是A歌曲同现的歌曲,用同现次数乘以各自的分值
result = num * pref;// 矩阵乘法相乘计算
//Text k = new Text(mapkb);
//Text v = new Text(mapk + "," + result);
//结果样本: u2723 i9,8.0
//context.write(k, v);
Text k = new Text(mapkb+","+mapk);
Text v = new Text( key.toString() + "," + result);
//key:101
// 结果样本: u3,101 101,4.0 *
// 结果样本: u3,102 101,4.0
// 结果样本: u3,103 101,4.0
//key:102
// 结果样本: u3,101 102,4.0 *
// 结果样本: u3,102 102,4.0
// 结果样本: u3,103 102,4.0
context.write(k, v);
第四步比较飘
把同现矩阵和得分矩阵相乘
利用MR原语特征,按歌曲分组
这样相同歌曲的同现列表和所有用户对该歌曲的评分进到一个reduce中
这一步也可以理解为,之前逻辑我们是打横计算的,现在我们先打竖把所有参数计算好,把整个矩阵填好,第五步再打横的一条数据一条数据技术出来:
先把整个矩阵的数计算出来
运算结果:
第四步结果
第五步:
public class Step5
private final static Text K = new Text();
private final static Text V = new Text();
public static boolean run(Configuration config, Map<String, String> paths)
try
FileSystem fs = FileSystem.get(config);
Job job = Job.getInstance(config);
job.setJobName("step5");
job.setJarByClass(StartRun.class);
job.setMapperClass(Step5_Mapper.class);
job.setReducerClass(Step5_Reducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
FileInputFormat
.addInputPath(job, new Path(paths.get("Step5Input")));
Path outpath = new Path(paths.get("Step5Output"));
if (fs.exists(outpath))
fs.delete(outpath, true);
FileOutputFormat.setOutputPath(job, outpath);
boolean f = job.waitForCompletion(true);
return f;
catch (Exception e)
e.printStackTrace();
return false;
static class Step5_Mapper extends Mapper<LongWritable, Text, Text, Text>
/**
* 原封不动输出
*/
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException
// 样本: u2723:101 i9,8.0
String[] tokens = Pattern.compile("[\\t]").split(value.toString());
Text k = new Text(tokens[0]);// 用户为key
Text v = new Text(tokens[1] );
context.write(k, v);
static class Step5_Reducer extends Reducer<Text, Text, Text, Text>
@Override
protected void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException
Map<String, Double> map = new HashMap<String, Double>();// 结果
Double score = 0.0;
for (Text line : values) // i9,4.0
String[] tokens = line.toString().split(",");
// String itemID = tokens[0];
score += Double.parseDouble(tokens[1]);
String[] tmp = StringUtils.split(key.toString(),',');
key.set(tmp[0]);
Text v = new Text(tmp[1]+","+String.valueOf(score));
context.write(key, v);
// 样本: u13 i9,5.0
把相乘之后的矩阵相加获得结果矩阵
还是按用户分组,将该用户所有歌曲的推荐向量求和
运行结果:
第五步结果
第六步:
public class Step6
private final static Text K = new Text();
private final static Text V = new Text();
public static boolean run(Configuration config, Map<String, String> paths)
try
FileSystem fs = FileSystem.get(config);
Job job = Job.getInstance(config);
job.setJobName("step6");
job.setJarByClass(StartRun.class);
job.setMapperClass(Step6_Mapper.class);
job.setReducerClass(Step6_Reducer.class);
job.setSortComparatorClass(NumSort.class);
job.setGroupingComparatorClass(UserGroup.class);
job.setMapOutputKeyClass(PairWritable.class);
job.setMapOutputValueClass(Text.class);
FileInputFormat
.addInputPath(job, new Path(paths.get("Step6Input")));
Path outpath = new Path(paths.get("Step6Output"));
if (fs.exists(outpath))
fs.delete(outpath, true);
FileOutputFormat.setOutputPath(job, outpath);
boolean f = job.waitForCompletion(true);
return f;
catch (Exception e)
e.printStackTrace();
return false;
static class Step6_Mapper extends
Mapper<LongWritable, Text, PairWritable, Text>
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException
String[] tokens = Pattern.compile("[\\t,]").split(value.toString());
String u = tokens[0];
String item = tokens[1];
String num = tokens[2];
PairWritable k = new PairWritable();
k.setUid(u);
k.setNum(Double.parseDouble(num));
V.set(item + ":" + num);
context.write(k, V);
static class Step6_Reducer extends Reducer<PairWritable, Text, Text, Text>
@Override
protected void reduce(PairWritable key, Iterable<Text> values,
Context context) throws IOException, InterruptedException
int i = 0;
StringBuffer sb = new StringBuffer();
for (Text v : values)
if (i == 10)
break;
sb.append(v.toString() + ",");
i++;
K.set(key.getUid());
V.set(sb.toString());
context.write(K, V);
static class PairWritable implements WritableComparable<PairWritable>
private String uid;
private double num;
@Override
public void write(DataOutput out) throws IOException
out.writeUTF(uid);
out.writeDouble(num);
@Override
public void readFields(DataInput in) throws IOException
this.uid = in.readUTF();
this.num = in.readDouble();
@Override
public int compareTo(PairWritable o)
int r = this.uid.compareTo(o.getUid());
if (r == 0)
return Double.compare(this.num, o.getNum());
return r;
public String getUid()
return uid;
public void setUid(String uid)
this.uid = uid;
public double getNum()
return num;
public void setNum(double num)
this.num = num;
static class NumSort extends WritableComparator
public NumSort()
super(PairWritable.class, true);
@Override
public int compare(WritableComparable a, WritableComparable b)
PairWritable o1 = (PairWritable) a;
PairWritable o2 = (PairWritable) b;
int r = o1.getUid().compareTo(o2.getUid());
if (r == 0)
return -Double.compare(o1.getNum(), o2.getNum());
return r;
static class UserGroup extends WritableComparator
public UserGroup()
super(PairWritable.class, true);
@Override
public int compare(WritableComparable a, WritableComparable b)
PairWritable o1 = (PairWritable) a;
PairWritable o2 = (PairWritable) b;
return o1.getUid().compareTo(o2.getUid());
第六步,按照推荐得分降序排序,每个用户列出10个推荐歌曲。
运行结果:
最终结果
最终结果,key作为用户id,value为推荐分数由高到低的歌曲ID。
后语:
1.第四步可能有点绕,看代码可能看不懂,如果是这样子的话我建议你拿支笔,在纸上写写那张表的计算过程,找找其中规律,就发现,妙啊!
2.用户的action操作评分是我暂时乱写的,具体要看你公司业务需要,设计具体操作的分值。
2.生产中肯定不会这么简单,例如要考虑一开始用户没数据时个推荐什么歌曲;推荐歌曲里不应该有已收藏的歌曲,但收藏这个操作的分值不能低,所以要去到下一步的过滤。。。具体怎么优化欢迎大家留言~
代码下载地址:https://github.com/MichaelYipInGitHub/RecommendDemo




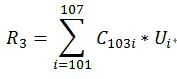
以上是关于利用MapReduce仿QQ音乐实现“今日推荐歌曲“系统的主要内容,如果未能解决你的问题,请参考以下文章