Hadoop | 02架构简介
Posted Jxiepc
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop | 02架构简介相关的知识,希望对你有一定的参考价值。
文章目录
一、hadoop简介
Hadoop 是由Apache开发的分布式系统的基础架构,主要解决海量数据的存储和分析计算问题;
1.1 特性
高可靠性:
底层维护多个数据副本,若某个存储出现故障,也不会丢失数据;
高扩展性:
可动态扩张,在集群中分配任务数据;
高效性:
在MapReduce下,能够并行工作,提高处理速度;
高容错性:
能够自动将失败的任务重新分配;
若其中一台服务器宕机,则能够自动将任务分配给其他服务器运作;
二、HDFS架构
该架构是一个分布式文件系统;

NameNode:存储文件的元数据;【文件名、文件属性、文件的块列表、以及所在的DataNode】;DataNode:本地文件系统存储文件系统以及块数据的校验和;SNameNode:每隔一段时间就将NameNode的数据进行备份;
二、YARN 架构
Yet Another Resource Negotiator简称YARN ,另一种
资源协调者,是Hadoop的资源管理器;
在hadoop1.x版本中,没有该架构,直至2.x才出现;是由1.x中的MapReduce分离出来的;
ResourceManager(RM):管理整个集群资源;NodeManager(NM):管理节点服务器资源;ApplicationMaster(AM):管理单任务运行;Container:相当于独立的服务器,能够运行任务;
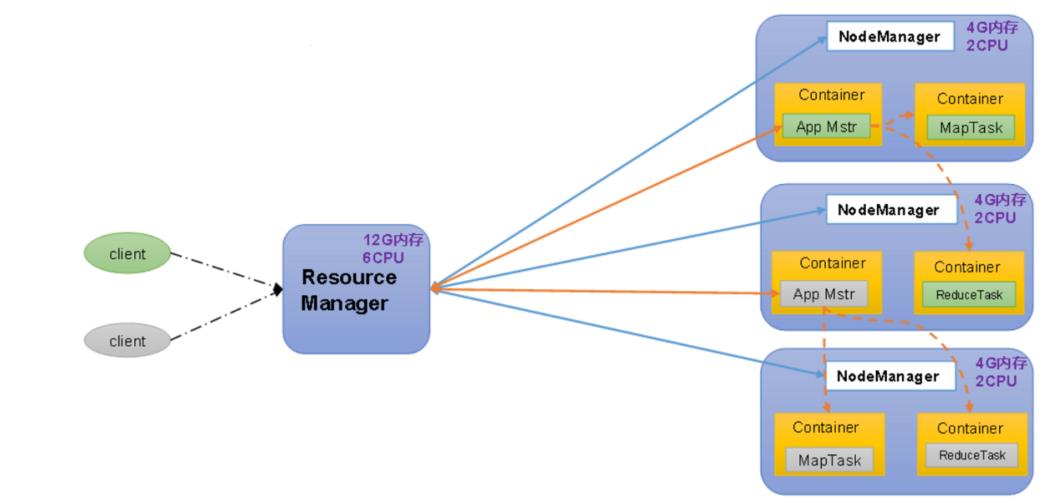
三、MapReduce架构
该过程分为两阶段:
- Map阶段并行处理输入数据;
- Reduce阶段对Map结果进行汇总;

四、HDFS、YARN、MapReduce三者关系

hadoop2 环境的搭建(自动HA)
zookeeper:hadoop112、hadoop113、hadoop114
namenode:hadoop110和hadoop111
datanode:hadoop112、hadoop113、hadoop114
journalnode:hadoop110、hadoop111、hadoop112
resourcemanager:hadoop110
nodemanager:hadoop112、hadoop113、hadoop114
1、搭建zk集群,并启动
1.1、搭建zookeeper
1.1.1、在hadoop112上解压缩,重命名为zookeeper,把conf/zoo_sample.cfg重命名为zoo.cfg
1.1.2、修改文件conf/zoo.cfg
dataDir=/usr/zookeeper/data
增加以下内容
server.112=hadoop112:2888:3888
server.113=hadoop113:2888:3888
server.114=hadoop114:2888:3888
1.1.3、创建目录mkdir zookeeper/data
1.1.4、写入节点id:echo 112 > zookeeper/data/myid
1.1.5、复制zookeeper文件夹到hadoop113和hadoop114上
scp /usr/zookeeper/ hadoop113:/usr/
scp /usr/zookeeper/ hadoop114:/usr/
在hadoop113上执行 echo 113 > zookeeper/data/myid
在hadoop114上执行 echo 114 > zookeeper/data/myid
1.2、启动
在hadoop112、hadoop113、hadoop114上分别执行:
bin/zkServer.sh start
1.3、验证
执行命令:
bin/zkCli.sh
进入后执行ls /
2、配置文件(hadoop-env.sh、core-site.xml hdfs-site.xml yarn-site.xml mapred-site.xml)
2.1、hadoop-env.sh
export JAVA_HOME=/usr/jdk
上面是我本机的路径,需要改成真实的jdk路径
export JAVA_HOME=JDK的路径
2.2、core-site.xml
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://cluster1</value> </property> <!-- 设置默认的HDFS路径,有多个HDFS集群同时工作时,默认值在这里指定 --> <property> <name>hadoop.tmp.dir</name> <value>/usr/hadoop/tmp</value> </property> <!-- 设置NameNode DataNode JournalNode等存放数据的公共目录,也可以单独指定 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop112:2181,hadoop113:2181,hadoop114:2181</value>
</property>
<!-- 指定zookeeper集群 -->
</configuration>
2.3、hdfs-site.xml
<configuration> <property> <name>dfs.replication</name> <value>2</value> </property> <!-- 集群中文件的副本数 --> <property> <name>dfs.nameservices</name> <value>cluster1</value> </property> <!-- 使用federation时,这里填写所有集群的别名,用逗号分隔 --> <property> <name>dfs.ha.namenodes.cluster1</name> <value>hadoop110,hadoop111</value> </property> <!-- 配置集群的NameNode几点,这里是NameNode 的别名,需要对每个NameNode再进行详细的配置--> <property> <name>dfs.namenode.rpc-address.cluster1.hadoop110</name> <value>hadoop110:9000</value> </property> <!-- 配置NameNode的RPC地址 --> <property> <name>dfs.namenode.http-address.cluster1.hadoop110</name> <value>hadoop110:50070</value> </property> <!-- 配置NameNode的HTTP地址 --> <property> <name>dfs.namenode.rpc-address.cluster1.hadoop111</name> <value>hadoop111:9000</value> </property> <property> <name>dfs.namenode.http-address.cluster1.hadoop111</name> <value>hadoop111:50070</value> </property> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://hadoop110:8485;hadoop111:8485;hadoop112:8485/cluster1</value> </property> <!-- 指定集群(cluster1)的两个NameNode共享edits文件目录时使用的JournalNode集群信息 --> <property> <name>dfs.ha.automatic-failover.enabled.cluster1</name> <value>true</value> </property> <!-- 指定集群(cluster1)是否启动自动故障恢复,即当NameNode出故障事,是否自动切换到另一台NameNode --> <property> <name>dfs.client.failover.proxy.provider.cluster1</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyPrivider</value> </property> <!-- 指定集群(cluster1)出故障时,哪个实现类负责执行故障切换 --> <property> <name>dfs.journalnode.edits.dir</name> <value>/usr/hadoop/tmp/journal</value> </property> <!-- 指定JournalNode集群在对NameNode的目录进行共享时,自己存储数据的磁盘路径 --> <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <!-- 一旦需要NameNode切换,使用ssh方式进行切换 --> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/root/.ssh/id_rsa</value> </property> </configuration>
2.4、yarn-site.xml
<configuration> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop110</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
2.5、mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
2.6、slaves
hadoop112
hadoop113
hadoop114
2.7、同步修改的配置文件
3、格式化zookeeper集群
在hadoop110上执行
hadoop/bin/hdfs zkfc -formatZK
4、启动journalnode集群
在hadoop110、hadoop111、hadoop112上分别执行:
sbin/hadoop-daemon.sh start journalnode
扩展
停止journalnode
sbin/hadoop-daemon.sh stop journalnode
5、格式化namenode、启动namenode
在hadoop110或者hadoop111上执行:
bin/hdfs namenode -format
sbin/hadoop-daemon.sh start namenode
在hadoop111上执行
bin/hdfs namenode -bootstrapStandby
sbin/hadoop-daemon.sh start namenode
*hadoop111的格式化,操作是关键是是把hadoop110上面的tmp/dfs下的fsimage和edit拷贝过去
6、启动datanode
sbin/hadoop-daemons.sh start datanode
7、启动ZKFC
在NameNode节点上执行(hadoop110或hadoop111)执行:
hadoop/sbin/hadoop-daemon.sh start zkfc
8、启动resourcemanager和nodemanager
在hadoop110或者hadoop111上执行
sbin/yarn-daemon.sh start resourcemanager sbin/yarn-daemons.sh start nodemanager
或者
sbin/start-yarn.sh start resourcemanager
总结:
自动切换比手动切换多的操作:
1、在core-site.xml配置zookeeper集群,在hdfs-site.xml中设置允许自动切换
2、操作上,格式化zookeeper,执行命令bin/hdfs zkfc -formatZK, 启动zk,执行命令sbin/hadoop-daemon.sh start zkfc
以上是关于Hadoop | 02架构简介的主要内容,如果未能解决你的问题,请参考以下文章