大数据技术与架构——大数据处理架构Hadoop(上)
Posted TUTOU程序猿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据技术与架构——大数据处理架构Hadoop(上)相关的知识,希望对你有一定的参考价值。
文章目录
1.Hadoop概述
1.1Hadoop简介
- Hadoop是Apache [ә’pætʃi]软件基金会旗下的一个开源分布式计算平台,
为用户提供了系统底层细节透明的分布式基础架构。

- Hadoop是基于Java语言开发的,具有很好的跨平台特性,并且可以部署在廉价的计算机集群中
- Hadoop可以支持多种编程语言,如C、C++、Java、Python

- Hadoop = HDFS(存)+MapReduce(算)

1.2Hadoop发展简史
- 创始人Doug Cutting

- Nutch 是一个开源Java实现的搜索引擎。它提供了我们运行自己的搜索引擎所需的全部工具。包括全文搜索和Web爬虫。
- 2003年,谷歌发布了分布式文件系统GFS(Google File System)
- 在2004年,Nutch项目也模仿GFS开发了自己的分布式文件系统NDFS(Nutch Distributed File System),也就是HDFS的前身
- 2004年,谷歌发布了分布式并行编程框架MapReduce
- 到了2006年2月,Nutch中的NDFS和MapReduce开始独立出
来,成为Lucene项目的一个子项目,称为Hadoop。 - 2008年1月,Hadoop正式成为Apache顶级项目。
- Hadoop成名史:2008年4月,Hadoop打破世界纪录,成为最快排序
1TB数据的系统,它采用一个由910个节点构成的集群进行运算,排序时
间只用了209秒。 - 在2009年5月,Hadoop更是把1TB数据排序时间缩短到62秒。Hadoop
从此名声大震,迅速发展成为大数据时代最具影响力的开源分布式开发平
台,并成为事实上的大数据处理标准。
1.3Hadoop的特性
Hadoop是一个能够对大量数据进行分布式处理的软件框架,并且是以一种可靠、高效、可伸缩的方式进行处理的,它具有以下几个方面的特性:
- 高可靠性
多台机器构成集群,部分机器发生故障,剩余机器可以继续对外提供服务。 - 高效性
成百上千台机器一起计算 - 高可扩展性
可以不断往集群中增加机器 - 高容错性
当数据被发送到一个单独的节点,该数据也被复制到集群的其他节点上,这意味着故障发生时,存在另一个副本可供使用。 - 成本低
Hadoop通过普通廉价的机器组成服务器集群来分发以及处理数据,以至于成本很低。 - 运行在Linux平台上
- 支持多种编程语言
1.4Hadoop的应用现状
- Hadoop凭借其突出的优势,已经在各个领域得到了广泛的应用,而互联网领域是其应用的主阵地.
- Facebook作为全球知名的社交网站,Facebook主要将Hadoop平台用于日志处理、推荐系统和数据仓库等方面.
- 国内采用Hadoop的公司主要有百度、淘宝、网易、华为、中国移动等,其中,淘宝的Hadoop集群比较大
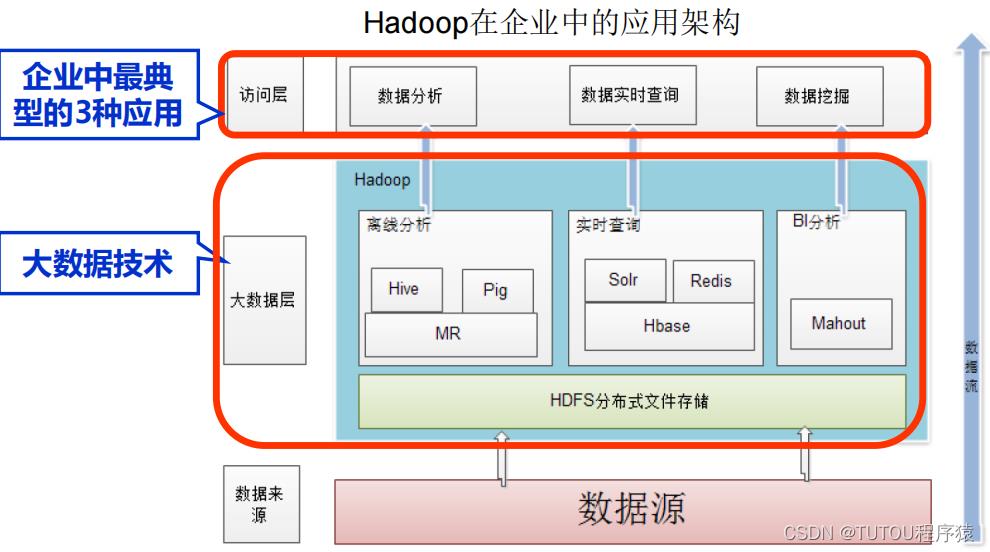
- Hadoop相关应用支撑上层的3种应用
- 不同的Hadoop组件实现不同的企业分析
- 最底层HDFS满足企业中大量数据存储的需求
- 存储后进行分析:
- 离线分析对数据进行批量处理,如MR(MapReduce)也可以用数据仓库产品Hive和Pig
- 实时查询用Hbase数据库
- 数据挖掘用Mahout
1.5 Apache Hadoop版本演变
- Apache Hadoop版本分为两代,我们将第一代Hadoop称为Hadoop 1.0,第二代Hadoop称为Hadoop 2.0
- 第一代Hadoop包含三个大版本,分别是0.20.x,0.21.x和0.22.x,其中,0.20.x最后演化成1.0.x,变成了稳定版,而0.21.x和0.22.x则增加了NameNode HA等新的重大特性
- 第二代Hadoop包含两个版本,分别是0.23.x和2.x,它们完全不同于Hadoop 1.0,是一套全新的架构
- Hadoop 1.0两大核心

- 包括两部分工作=数据处理+集群的资源管理(集群CPU、内存分配)
- 从Hadoop 1.0到Hadoop 2.0的变化

- 流计算的资源调度也是YARN负责
- 批处理计算搭建在YARN之上,由YARN进行资源调度

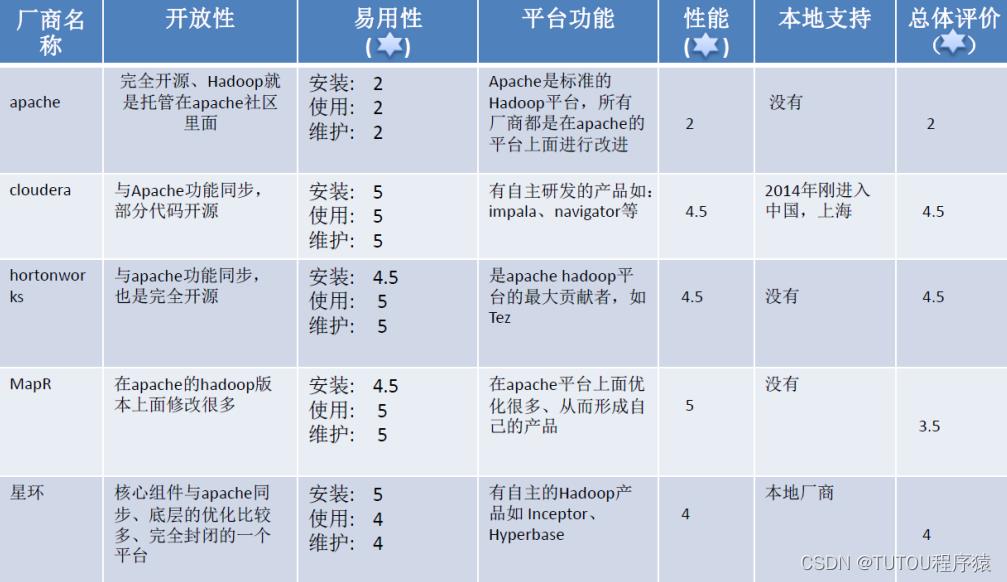
1.6 Hadoop各种版本(企业开发产品)
2.Hadoop项目结构
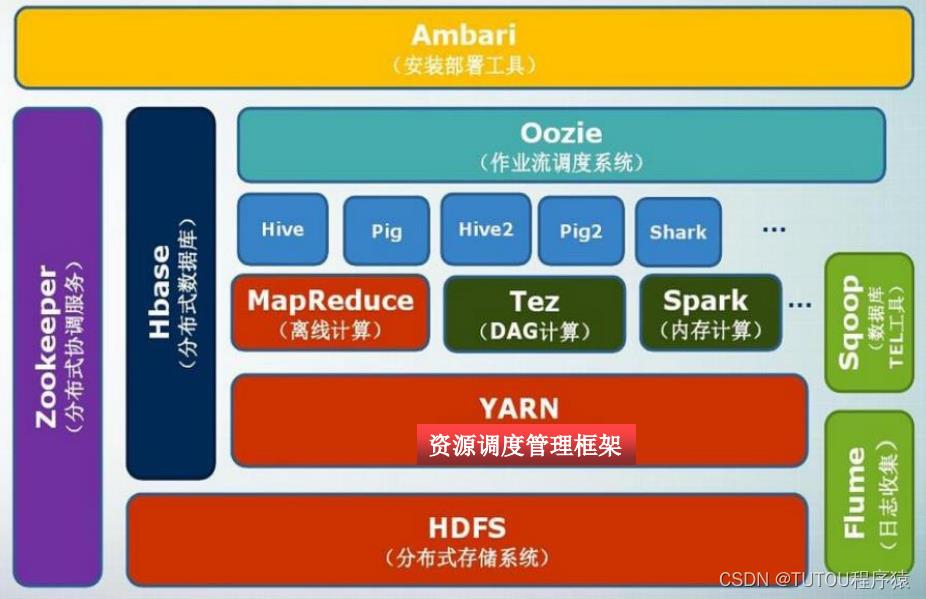
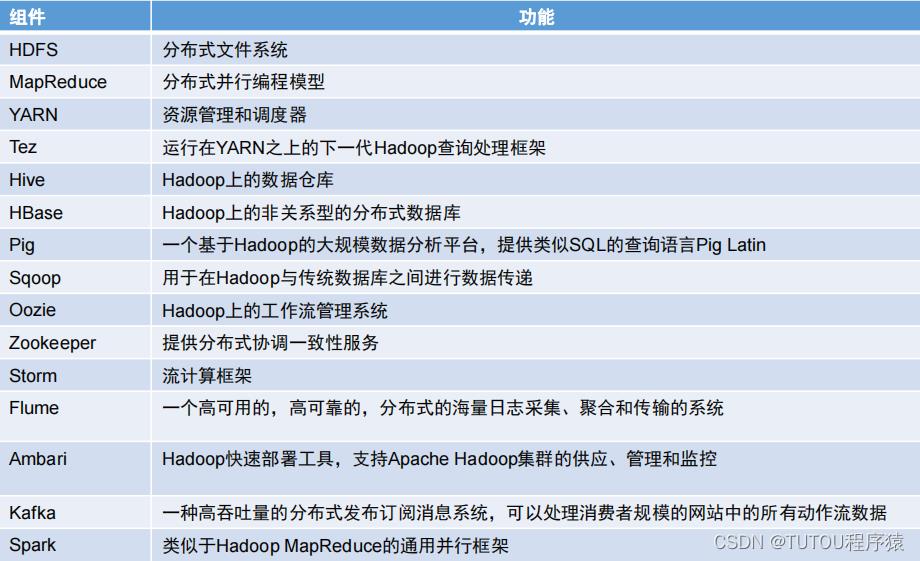
大数据技术原理与应用:第二讲大数据处理架构Hadoop
2.1 Hadoop概论
创始人:Doug Cutting
1.简介:
开源免费;
操作简单,极大降低使用的复杂性;
Hadoop是Java开发的;
在Hadoop上开发应用支持多种编程语言、不限于Java;
Hadoop两大核心:HDFS+MapReduce
HDFS:海量数据存储
MapReduce:海量数据的处理
2.起源:
原本是文本搜索库,模仿谷歌的搜索引擎;
融入了谷歌相关技术:分布式文件系统GFS;分布式并行编程框架MapReduce;
3.成名史:数据排序 的傲人成绩
4.特性:
1.高可靠性
2.高效性
3高可扩展性
4.高容错性
5.低成本
6.运行在Linux平台上
7.支持多种编程语言
5.应用现状:
例如:Facebook
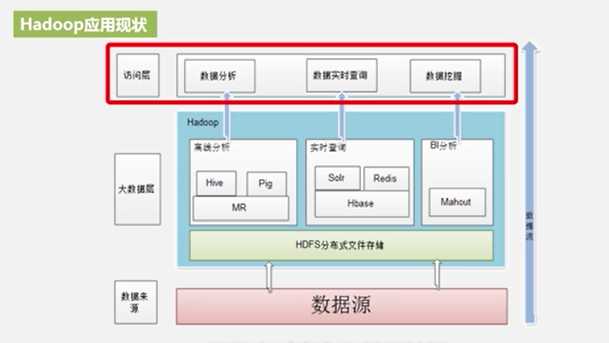
2.2 Hadoop项目结构
以上是关于大数据技术与架构——大数据处理架构Hadoop(上)的主要内容,如果未能解决你的问题,请参考以下文章