Keras使用LSTM时输入问题
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Keras使用LSTM时输入问题相关的知识,希望对你有一定的参考价值。
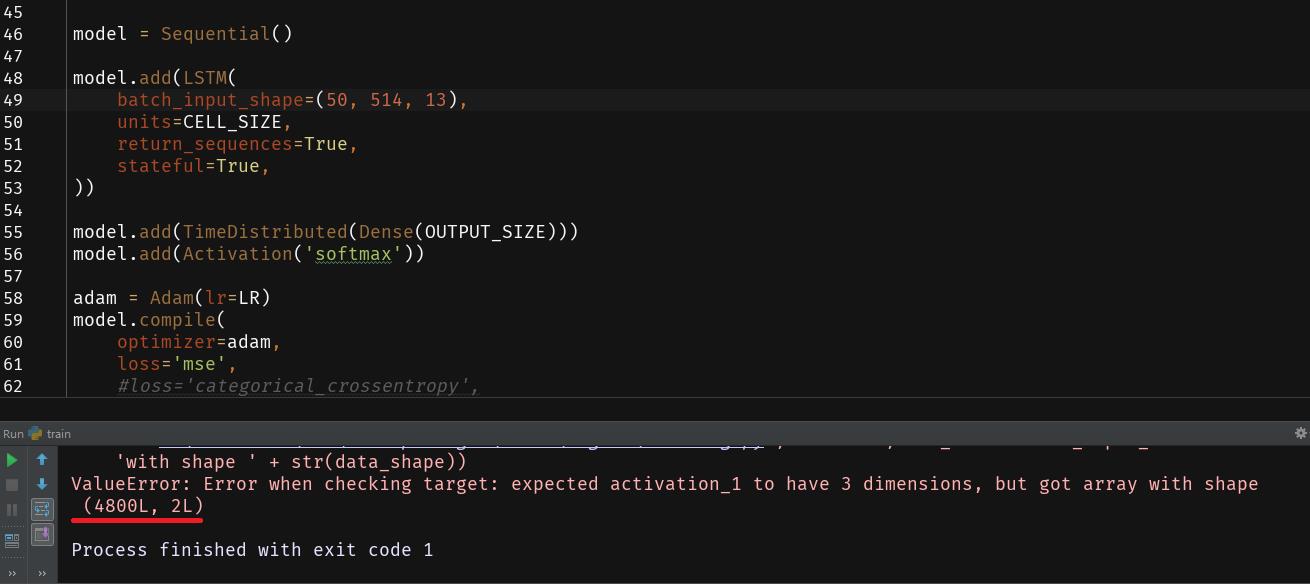
如图,fit输入的shape为(4800, 514, 13),为什么报错出来是这个shape了?
在 LSTM 网络的输入上使用 Masking 时,Keras(TensorFlow 后端)多 GPU 模型(4gpus)失败
【中文标题】在 LSTM 网络的输入上使用 Masking 时,Keras(TensorFlow 后端)多 GPU 模型(4gpus)失败【英文标题】:Keras(TensorFlow backend) multi-gpu model(4gpus) is failing when using Masking on input of LSTM network 【发布时间】:2020-01-03 18:02:31 【问题描述】:在 LSTM 中屏蔽输入层并尝试使用 TensorFlow 背景在 Keras 的 fi_genrator 的多 GPU 模型上运行会引发错误。
为 LSTM 创建了一个 fit_generator,代码在多 GPU 模型上成功运行(我看到所有 GPU 都在 watch -n0.5 nvidia-smi 上使用)。因为我的代码有 8 个时间戳,并且并非所有时间戳都始终可用。所以,我想对输入使用掩码。但是,当我屏蔽输入并运行代码时,会出现错误。
class quickdrawSequence(Sequence):
def __init__(self, batch_size=128,shuffle=True,total_combinations = total_combinations,listFils=listFiles):
self.batch_size = batch_size
self.shuffle = shuffle
self.total_combinations = total_combinations
self.listFiles=listFils
self.on_epoch_end()
def on_epoch_end(self):
#'Updates indexes after each epoch'
if self.shuffle == True:
np.random.shuffle(self.listFiles)
def __len__(self):
# number of batches for each epoch
return self.total_combinations//self.batch_size
def __getitem__(self, idx): # this idx comes from the call of genrator by fit_generator since we inherited sequence
#print("index from __getitem__ is : "+ str(idx))
curnt_batchFile = listFiles[idx]
#print(idx, curnt_batchFile)
x,y = self.__data_generation(curnt_batchFile)
return x, y
def __data_generation(self,curnt_batchFile):
curnt_batchFile_x = curnt_batchFile
curnt_batchFile_y = curnt_batchFile.replace("_x.npy","_y.npy")
x_val = np.load(curnt_batchFile_x)
y_val = np.load(curnt_batchFile_y)
return x_val,y_val
training_generator = quickdrawSequence(batch_size=Batch_size,shuffle=True,total_combinations = total_combinations,listFils=listFiles)
validation_generator = quickdrawSequence(batch_size=Batch_size,shuffle=True,total_combinations = total_combinations,listFils=listFiles)
with tf.device('/cpu:0'):
lstm_model = Sequential()
#lstm_model.add(LSTM(units=100,input_shape=(Time_Steps,Num_Features),return_sequences=True))
lstm_model.add(Masking(mask_value=-5,input_shape=(Time_Steps,Num_Features)))
lstm_model.add(LSTM(units=100,return_sequences=True))
lstm_model.add(Dropout(0.2))
lstm_model.add(LSTM(units=100, return_sequences=True))
#lstm_model.add(BatchNormalization())
lstm_model.add(Dropout(0.2))
lstm_model.add(TimeDistributed(Dense(25,activation='relu')))
lstm_model.add(TimeDistributed(Dense(1,activation='sigmoid')))
lstm_model.summary()
parallel_model = multi_gpu_model(lstm_model, gpus=4)
parallel_model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
parallel_model.fit_generator(
generator=training_generator,
steps_per_epoch=Bbatches_afterGpuDiv,
epochs=Epochs,
verbose=1,
validation_data=validation_generator,
validation_steps=2,
use_multiprocessing=True,
workers=8,
max_queue_size=8
)
output:
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
masking (Masking) (None, 8, 9) 0
_________________________________________________________________
lstm (LSTM) (None, 8, 100) 44000
_________________________________________________________________
dropout (Dropout) (None, 8, 100) 0
_________________________________________________________________
lstm_1 (LSTM) (None, 8, 100) 80400
_________________________________________________________________
dropout_1 (Dropout) (None, 8, 100) 0
_________________________________________________________________
time_distributed (TimeDistri (None, 8, 25) 2525
_________________________________________________________________
time_distributed_1 (TimeDist (None, 8, 1) 26
=================================================================
Total params: 126,951
Trainable params: 126,951
Non-trainable params: 0
_________________________________________________________________
Epoch 1/10
---------------------------------------------------------------------------
InvalidArgumentError Traceback (most recent call last)
<ipython-input-11-d4fa72c44cd9> in <module>()
40 use_multiprocessing=True,
41 workers=8,
---> 42 max_queue_size=8
43 )
/home/sa/anaconda/envs/tf112_cu9_py27_pycuda_2/lib/python2.7/site-packages/tensorflow/python/keras/engine/training.pyc in fit_generator(self, generator, steps_per_epoch, epochs, verbose, callbacks, validation_data, validation_steps, class_weight, max_queue_size, workers, use_multiprocessing, shuffle, initial_epoch)
2175 use_multiprocessing=use_multiprocessing,
2176 shuffle=shuffle,
-> 2177 initial_epoch=initial_epoch)
2178
2179 def evaluate_generator(self,
/home/sa/anaconda/envs/tf112_cu9_py27_pycuda_2/lib/python2.7/site-packages/tensorflow/python/keras/engine/training_generator.pyc in fit_generator(model, generator, steps_per_epoch, epochs, verbose, callbacks, validation_data, validation_steps, class_weight, max_queue_size, workers, use_multiprocessing, shuffle, initial_epoch)
174
175 outs = model.train_on_batch(
--> 176 x, y, sample_weight=sample_weight, class_weight=class_weight)
177
178 if not isinstance(outs, list):
/home/sa/anaconda/envs/tf112_cu9_py27_pycuda_2/lib/python2.7/site-packages/tensorflow/python/keras/engine/training.pyc in train_on_batch(self, x, y, sample_weight, class_weight)
1938
1939 self._make_train_function()
-> 1940 outputs = self.train_function(ins)
1941
1942 if len(outputs) == 1:
/home/sa/anaconda/envs/tf112_cu9_py27_pycuda_2/lib/python2.7/site-packages/tensorflow/python/keras/backend.pyc in __call__(self, inputs)
2945 raise TypeError('`inputs` should be a list or tuple.')
2946
-> 2947 session = get_session()
2948 feed_arrays = []
2949 array_vals = []
/home/sa/anaconda/envs/tf112_cu9_py27_pycuda_2/lib/python2.7/site-packages/tensorflow/python/keras/backend.pyc in get_session()
467 if not _MANUAL_VAR_INIT:
468 with session.graph.as_default():
--> 469 _initialize_variables(session)
470 return session
471
/home/sa/anaconda/envs/tf112_cu9_py27_pycuda_2/lib/python2.7/site-packages/tensorflow/python/keras/backend.pyc in _initialize_variables(session)
729 # marked as initialized.
730 is_initialized = session.run(
--> 731 [variables_module.is_variable_initialized(v) for v in candidate_vars])
732 uninitialized_vars = []
733 for flag, v in zip(is_initialized, candidate_vars):
/home/sa/anaconda/envs/tf112_cu9_py27_pycuda_2/lib/python2.7/site-packages/tensorflow/python/client/session.pyc in run(self, fetches, feed_dict, options, run_metadata)
927 try:
928 result = self._run(None, fetches, feed_dict, options_ptr,
--> 929 run_metadata_ptr)
930 if run_metadata:
931 proto_data = tf_session.TF_GetBuffer(run_metadata_ptr)
/home/sa/anaconda/envs/tf112_cu9_py27_pycuda_2/lib/python2.7/site-packages/tensorflow/python/client/session.pyc in _run(self, handle, fetches, feed_dict, options, run_metadata)
1150 if final_fetches or final_targets or (handle and feed_dict_tensor):
1151 results = self._do_run(handle, final_targets, final_fetches,
-> 1152 feed_dict_tensor, options, run_metadata)
1153 else:
1154 results = []
/home/sa/anaconda/envs/tf112_cu9_py27_pycuda_2/lib/python2.7/site-packages/tensorflow/python/client/session.pyc in _do_run(self, handle, target_list, fetch_list, feed_dict, options, run_metadata)
1326 if handle is None:
1327 return self._do_call(_run_fn, feeds, fetches, targets, options,
-> 1328 run_metadata)
1329 else:
1330 return self._do_call(_prun_fn, handle, feeds, fetches)
/home/sa/anaconda/envs/tf112_cu9_py27_pycuda_2/lib/python2.7/site-packages/tensorflow/python/client/session.pyc in _do_call(self, fn, *args)
1346 pass
1347 message = error_interpolation.interpolate(message, self._graph)
-> 1348 raise type(e)(node_def, op, message)
1349
1350 def _extend_graph(self):
InvalidArgumentError: Cannot assign a device for operation replica_0/sequential/lstm/transpose_1: Could not satisfy explicit device specification '/device:GPU:0' because no supported kernel for GPU devices is available.
Colocation Debug Info:
Colocation group had the following types and devices:
TensorArrayScatterV3: CPU XLA_CPU XLA_GPU
TensorArrayReadV3: CPU XLA_CPU XLA_GPU
Enter: GPU CPU XLA_CPU XLA_GPU
TensorArrayV3: CPU XLA_CPU XLA_GPU
Transpose: GPU CPU XLA_CPU XLA_GPU
Colocation members and user-requested devices:
replica_0/sequential/lstm/transpose_1 (Transpose) /device:GPU:0
replica_0/sequential/lstm/TensorArray_2 (TensorArrayV3)
replica_0/sequential/lstm/TensorArrayUnstack_1/TensorArrayScatter/TensorArrayScatterV3 (TensorArrayScatterV3) /device:GPU:0
replica_0/sequential/lstm/while/TensorArrayReadV3_1/Enter (Enter) /device:GPU:0
replica_0/sequential/lstm/while/TensorArrayReadV3_1 (TensorArrayReadV3) /device:GPU:0
Registered kernels:
device='XLA_CPU'; Tperm in [DT_INT32, DT_INT64]; T in [DT_FLOAT, DT_DOUBLE, DT_INT32, DT_UINT8, DT_INT8, DT_COMPLEX64, DT_INT64, DT_BOOL, DT_QINT8, DT_QUINT8, DT_QINT32, DT_HALF, DT_UINT32, DT_UINT64]
device='XLA_GPU'; Tperm in [DT_INT32, DT_INT64]; T in [DT_FLOAT, DT_DOUBLE, DT_INT32, DT_UINT8, DT_INT8, ..., DT_QINT32, DT_BFLOAT16, DT_HALF, DT_UINT32, DT_UINT64]
device='XLA_CPU_JIT'; Tperm in [DT_INT32, DT_INT64]; T in [DT_FLOAT, DT_DOUBLE, DT_INT32, DT_UINT8, DT_INT8, DT_COMPLEX64, DT_INT64, DT_BOOL, DT_QINT8, DT_QUINT8, DT_QINT32, DT_HALF, DT_UINT32, DT_UINT64]
device='XLA_GPU_JIT'; Tperm in [DT_INT32, DT_INT64]; T in [DT_FLOAT, DT_DOUBLE, DT_INT32, DT_UINT8, DT_INT8, ..., DT_QINT32, DT_BFLOAT16, DT_HALF, DT_UINT32, DT_UINT64]
device='GPU'; T in [DT_BOOL]
device='GPU'; T in [DT_COMPLEX128]
device='GPU'; T in [DT_COMPLEX64]
device='GPU'; T in [DT_DOUBLE]
device='GPU'; T in [DT_FLOAT]
device='GPU'; T in [DT_BFLOAT16]
device='GPU'; T in [DT_HALF]
device='GPU'; T in [DT_INT8]
device='GPU'; T in [DT_UINT8]
device='GPU'; T in [DT_INT16]
device='GPU'; T in [DT_UINT16]
device='GPU'; T in [DT_INT32]
device='GPU'; T in [DT_INT64]
device='CPU'; T in [DT_VARIANT]
device='CPU'; T in [DT_RESOURCE]
device='CPU'; T in [DT_STRING]
device='CPU'; T in [DT_BOOL]
device='CPU'; T in [DT_COMPLEX128]
device='CPU'; T in [DT_COMPLEX64]
device='CPU'; T in [DT_DOUBLE]
device='CPU'; T in [DT_FLOAT]
device='CPU'; T in [DT_BFLOAT16]
device='CPU'; T in [DT_HALF]
device='CPU'; T in [DT_INT8]
device='CPU'; T in [DT_UINT8]
device='CPU'; T in [DT_INT16]
device='CPU'; T in [DT_UINT16]
device='CPU'; T in [DT_INT32]
device='CPU'; T in [DT_INT64]
[[node replica_0/sequential/lstm/transpose_1 (defined at <ipython-input-11-d4fa72c44cd9>:29) = Transpose[T=DT_BOOL, Tperm=DT_INT32, _device="/device:GPU:0"](replica_0/sequential/lstm/ExpandDims, replica_0/sequential/lstm/transpose_1/perm)]]
Caused by op u'replica_0/sequential/lstm/transpose_1', defined at:
File "/home/sa/anaconda/envs/tf112_cu9_py27_pycuda_2/lib/python2.7/runpy.py", line 174, in _run_module_as_main
"__main__", fname, loader, pkg_name)
File "/home/sa/anaconda/envs/tf112_cu9_py27_pycuda_2/lib/python2.7/runpy.py", line 72, in _run_code
exec code in run_globals
File "/home/sa/anaconda/envs/tf112_cu9_py27_pycuda_2/lib/python2.7/site-packages/ipykernel_launcher.py", line 16, in <module>
app.launch_new_instance()
File "/home/sa/anaconda/envs/tf112_cu9_py27_pycuda_2/lib/python2.7/site-packages/traitlets/config/application.py", line 658, in launch_instance
app.start()
File "/home/sa/anaconda/envs/tf112_cu9_py27_pycuda_2/lib/python2.7/site-packages/ipykernel/kernelapp.py", line 499, in start
self.io_loop.start()
File "/home/sa/anaconda/envs/tf112_cu9_py27_pycuda_2/lib/python2.7/site-packages/tornado/ioloop.py", line 1017, in start
self._run_callback(self._callbacks.popleft())
File "/home/sa/anaconda/envs/tf112_cu9_py27_pycuda_2/lib/python2.7/site-packages/tornado/ioloop.py", line 758, in _run_callback
ret = callback()
File "/home/sa/anaconda/envs/tf112_cu9_py27_pycuda_2/lib/python2.7/site-packages/tornado/stack_context.py", line 300, in null_wrapper
return fn(*args, **kwargs)
File "/home/sa/anaconda/envs/tf112_cu9_py27_pycuda_2/lib/python2.7/site-packages/zmq/eventloop/zmqstream.py", line 542, in <lambda>
self.io_loop.add_callback(lambda : self._handle_events(self.socket, 0))
File "/home/sa/anaconda/envs/tf112_cu9_py27_pycuda_2/lib/python2.7/site-packages/zmq/eventloop/zmqstream.py", line 456, in _handle_events
self._handle_recv()
File "/home/sa/anaconda/envs/tf112_cu9_py27_pycuda_2/lib/python2.7/site-packages/zmq/eventloop/zmqstream.py", line 486, in _handle_recv
self._run_callback(callback, msg)
File "/home/sa/anaconda/envs/tf112_cu9_py27_pycuda_2/lib/python2.7/site-packages/zmq/eventloop/zmqstream.py", line 438, in _run_callback
callback(*args, **kwargs)
File "/home/sa/anaconda/envs/tf112_cu9_py27_pycuda_2/lib/python2.7/site-packages/tornado/stack_context.py", line 300, in null_wrapper
return fn(*args, **kwargs)
File "/home/sa/anaconda/envs/tf112_cu9_py27_pycuda_2/lib/python2.7/site-packages/ipykernel/kernelbase.py", line 283, in dispatcher
return self.dispatch_shell(stream, msg)
File "/home/sa/anaconda/envs/tf112_cu9_py27_pycuda_2/lib/python2.7/site-packages/ipykernel/kernelbase.py", line 233, in dispatch_shell
handler(stream, idents, msg)
File "/home/sa/anaconda/envs/tf112_cu9_py27_pycuda_2/lib/python2.7/site-packages/ipykernel/kernelbase.py", line 399, in execute_request
user_expressions, allow_stdin)
File "/home/sa/anaconda/envs/tf112_cu9_py27_pycuda_2/lib/python2.7/site-packages/ipykernel/ipkernel.py", line 208, in do_execute
res = shell.run_cell(code, store_history=store_history, silent=silent)
File "/home/sa/anaconda/envs/tf112_cu9_py27_pycuda_2/lib/python2.7/site-packages/ipykernel/zmqshell.py", line 537, in run_cell
return super(ZMQInteractiveShell, self).run_cell(*args, **kwargs)
File "/home/sa/anaconda/envs/tf112_cu9_py27_pycuda_2/lib/python2.7/site-packages/IPython/core/interactiveshell.py", line 2714, in run_cell
interactivity=interactivity, compiler=compiler, result=result)
File "/home/sa/anaconda/envs/tf112_cu9_py27_pycuda_2/lib/python2.7/site-packages/IPython/core/interactiveshell.py", line 2818, in run_ast_nodes
if self.run_code(code, result):
File "/home/sa/anaconda/envs/tf112_cu9_py27_pycuda_2/lib/python2.7/site-packages/IPython/core/interactiveshell.py", line 2878, in run_code
exec(code_obj, self.user_global_ns, self.user_ns)
File "<ipython-input-11-d4fa72c44cd9>", line 29, in <module>
parallel_model = multi_gpu_model(lstm_model, gpus=4)
File "/home/sa/anaconda/envs/tf112_cu9_py27_pycuda_2/lib/python2.7/site-packages/tensorflow/python/keras/utils/multi_gpu_utils.py", line 239, in multi_gpu_model
outputs = model(inputs)
File "/home/sa/anaconda/envs/tf112_cu9_py27_pycuda_2/lib/python2.7/site-packages/tensorflow/python/keras/engine/base_layer.py", line 757, in __call__
outputs = self.call(inputs, *args, **kwargs)
File "/home/sa/anaconda/envs/tf112_cu9_py27_pycuda_2/lib/python2.7/site-packages/tensorflow/python/keras/engine/sequential.py", line 229, in call
return super(Sequential, self).call(inputs, training=training, mask=mask)
File "/home/sa/anaconda/envs/tf112_cu9_py27_pycuda_2/lib/python2.7/site-packages/tensorflow/python/keras/engine/network.py", line 845, in call
mask=masks)
File "/home/sa/anaconda/envs/tf112_cu9_py27_pycuda_2/lib/python2.7/site-packages/tensorflow/python/keras/engine/network.py", line 1031, in _run_internal_graph
output_tensors = layer.call(computed_tensor, **kwargs)
File "/home/sa/anaconda/envs/tf112_cu9_py27_pycuda_2/lib/python2.7/site-packages/tensorflow/python/keras/layers/recurrent.py", line 2237, in call
inputs, mask=mask, training=training, initial_state=initial_state)
File "/home/sa/anaconda/envs/tf112_cu9_py27_pycuda_2/lib/python2.7/site-packages/tensorflow/python/keras/layers/recurrent.py", line 750, in call
input_length=timesteps)
File "/home/sa/anaconda/envs/tf112_cu9_py27_pycuda_2/lib/python2.7/site-packages/tensorflow/python/keras/backend.py", line 3119, in rnn
mask = array_ops.transpose(mask, axes)
File "/home/sa/anaconda/envs/tf112_cu9_py27_pycuda_2/lib/python2.7/site-packages/tensorflow/python/ops/array_ops.py", line 1420, in transpose
ret = transpose_fn(a, perm, name=name)
File "/home/sa/anaconda/envs/tf112_cu9_py27_pycuda_2/lib/python2.7/site-packages/tensorflow/python/ops/gen_array_ops.py", line 8927, in transpose
"Transpose", x=x, perm=perm, name=name)
File "/home/sa/anaconda/envs/tf112_cu9_py27_pycuda_2/lib/python2.7/site-packages/tensorflow/python/framework/op_def_library.py", line 787, in _apply_op_helper
op_def=op_def)
File "/home/sa/anaconda/envs/tf112_cu9_py27_pycuda_2/lib/python2.7/site-packages/tensorflow/python/util/deprecation.py", line 488, in new_func
return func(*args, **kwargs)
File "/home/sa/anaconda/envs/tf112_cu9_py27_pycuda_2/lib/python2.7/site-packages/tensorflow/python/framework/ops.py", line 3274, in create_op
op_def=op_def)
File "/home/sa/anaconda/envs/tf112_cu9_py27_pycuda_2/lib/python2.7/site-packages/tensorflow/python/framework/ops.py", line 1770, in __init__
self._traceback = tf_stack.extract_stack()
InvalidArgumentError (see above for traceback): Cannot assign a device for operation replica_0/sequential/lstm/transpose_1: Could not satisfy explicit device specification '/device:GPU:0' because no supported kernel for GPU devices is available.
Colocation Debug Info:
Colocation group had the following types and devices:
TensorArrayScatterV3: CPU XLA_CPU XLA_GPU
TensorArrayReadV3: CPU XLA_CPU XLA_GPU
Enter: GPU CPU XLA_CPU XLA_GPU
TensorArrayV3: CPU XLA_CPU XLA_GPU
Transpose: GPU CPU XLA_CPU XLA_GPU
Colocation members and user-requested devices:
replica_0/sequential/lstm/transpose_1 (Transpose) /device:GPU:0
replica_0/sequential/lstm/TensorArray_2 (TensorArrayV3)
replica_0/sequential/lstm/TensorArrayUnstack_1/TensorArrayScatter/TensorArrayScatterV3 (TensorArrayScatterV3) /device:GPU:0
replica_0/sequential/lstm/while/TensorArrayReadV3_1/Enter (Enter) /device:GPU:0
replica_0/sequential/lstm/while/TensorArrayReadV3_1 (TensorArrayReadV3) /device:GPU:0
Registered kernels:
device='XLA_CPU'; Tperm in [DT_INT32, DT_INT64]; T in [DT_FLOAT, DT_DOUBLE, DT_INT32, DT_UINT8, DT_INT8, DT_COMPLEX64, DT_INT64, DT_BOOL, DT_QINT8, DT_QUINT8, DT_QINT32, DT_HALF, DT_UINT32, DT_UINT64]
device='XLA_GPU'; Tperm in [DT_INT32, DT_INT64]; T in [DT_FLOAT, DT_DOUBLE, DT_INT32, DT_UINT8, DT_INT8, ..., DT_QINT32, DT_BFLOAT16, DT_HALF, DT_UINT32, DT_UINT64]
device='XLA_CPU_JIT'; Tperm in [DT_INT32, DT_INT64]; T in [DT_FLOAT, DT_DOUBLE, DT_INT32, DT_UINT8, DT_INT8, DT_COMPLEX64, DT_INT64, DT_BOOL, DT_QINT8, DT_QUINT8, DT_QINT32, DT_HALF, DT_UINT32, DT_UINT64]
device='XLA_GPU_JIT'; Tperm in [DT_INT32, DT_INT64]; T in [DT_FLOAT, DT_DOUBLE, DT_INT32, DT_UINT8, DT_INT8, ..., DT_QINT32, DT_BFLOAT16, DT_HALF, DT_UINT32, DT_UINT64]
device='GPU'; T in [DT_BOOL]
device='GPU'; T in [DT_COMPLEX128]
device='GPU'; T in [DT_COMPLEX64]
device='GPU'; T in [DT_DOUBLE]
device='GPU'; T in [DT_FLOAT]
device='GPU'; T in [DT_BFLOAT16]
device='GPU'; T in [DT_HALF]
device='GPU'; T in [DT_INT8]
device='GPU'; T in [DT_UINT8]
device='GPU'; T in [DT_INT16]
device='GPU'; T in [DT_UINT16]
device='GPU'; T in [DT_INT32]
device='GPU'; T in [DT_INT64]
device='CPU'; T in [DT_VARIANT]
device='CPU'; T in [DT_RESOURCE]
device='CPU'; T in [DT_STRING]
device='CPU'; T in [DT_BOOL]
device='CPU'; T in [DT_COMPLEX128]
device='CPU'; T in [DT_COMPLEX64]
device='CPU'; T in [DT_DOUBLE]
device='CPU'; T in [DT_FLOAT]
device='CPU'; T in [DT_BFLOAT16]
device='CPU'; T in [DT_HALF]
device='CPU'; T in [DT_INT8]
device='CPU'; T in [DT_UINT8]
device='CPU'; T in [DT_INT16]
device='CPU'; T in [DT_UINT16]
device='CPU'; T in [DT_INT32]
device='CPU'; T in [DT_INT64]
[[node replica_0/sequential/lstm/transpose_1 (defined at <ipython-input-11-d4fa72c44cd9>:29) = Transpose[T=DT_BOOL, Tperm=DT_INT32, _device="/device:GPU:0"](replica_0/sequential/lstm/ExpandDims, replica_0/sequential/lstm/transpose_1/perm)]]
【问题讨论】:
【参考方案1】:在阅读了一些文档后,我意识到上述错误试图说明什么。它说一个操作没有 gpu 实现。如果我们将soft_placement设置为True,这些没有gpu实现的操作会被TF放到cpu上。
// 是否允许软放置。如果 allow_soft_placement 为真, // 一个 op 将被放置在 CPU 上,如果 // 1. OP 没有 GPU 实现 // 要么 // 2. 没有已知或注册的 GPU 设备 // 要么 // 3. 需要与来自 CPU 的 reftype 输入共同定位。
所以在上面的代码中添加,config.allow_soft_placement = True
它有效。
【讨论】:
以上是关于Keras使用LSTM时输入问题的主要内容,如果未能解决你的问题,请参考以下文章