ATC‘22顶会论文RunD:高密高并发的轻量级 Serverless 安全容器运行时
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ATC‘22顶会论文RunD:高密高并发的轻量级 Serverless 安全容器运行时相关的知识,希望对你有一定的参考价值。
编者按:目前的安全容器软件栈 — 包括 host 操作系统中的 cgroup、guest 操作系统和用于函数工作负载的容器 rootfs,都会导致低部署密度和在低并发能力。为此,RunD 作为一种轻量级安全容器运行时,提出了 host-to-guest 的全栈优化方案来解决上述问题。

摘要
在轻量级虚拟机(MicroVM)中托管单个容器的安全容器现在已经广泛应用于无服务器计算。由于其中的用户函数大多为细粒度抽象,因此为了提高资源利用率和用户体验,Serverless 需要支持高密度的容器部署和高并发的容器启动。我们的调查显示,目前的安全容器软件栈 — 包括 host 操作系统中的 cgroup、guest 操作系统和用于函数工作负载的容器 rootfs,都会导致低部署密度和在低并发能力。为此,RunD 作为一种轻量级安全容器运行时,提出了 host-to-guest 的全栈优化方案来解决上述问题。使用 RunD 运行时,可以做到在一秒钟内启动超过 200 个安全容器,并且可以在一个 384GB 内存的节点上部署超过 2500 个安全容器。
一、介绍
函数计算作为无服务器计算(或者服务器无感知计算,Serverless)中的主要实现,通过隔离开发人员提供的细粒度函数并弹性管理使用资源,做到了更精细化的按量付费和更高的数据中心资源利用率。随着云原生技术的发展和微服务架构的流行,应用被越来越多的拆分成更细粒度的函数并部署为 Serverless 模式。
但基于传统容器技术隔离的函数计算由于其较低的隔离性和安全性,已经逐步被替换成结合 MicroVM 和容器的安全容器技术为应用提供强隔离性和低延迟响应。安全容器通常会在一个普通的容器外额外嵌套一层轻量级的 microVM 中,如下图1 (a)所示。通过这种方式,用户可以基于现有的容器基础设施和生态系统构建 Serverless 服务。安全容器能够确保与 MicroVM 中的容器运行时兼容。Kata Containers 和 FireCracker 都提供了实现这种安全容器的实践经验。
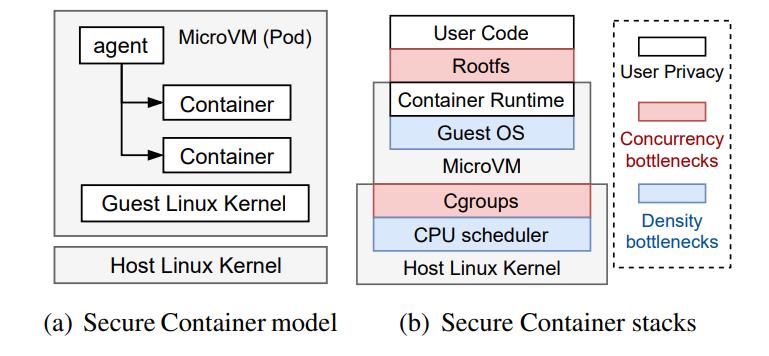
(图1/目前主流的安全容器模型,以及对应的软件栈架构)
在 Serverless 场景下,函数的轻量级和短期运行的特性使得高密度容器部署和高并发容器启动对于无服务器计算至关重要。例如,47% 的 Lambdas 在 AWS 上运行的最小内存规格是 128MB,在 Microsoft Azure 中,大约 90% 的应用程序的内存消耗从未超过 400MB。由于一个物理节点通常有很大的内存空间(如 384GB),它按理应该能够部署大量的容器设计。同时,大量的函数调用可能会在短时间内到达。但是,安全容器的额外开销大大降低了函数的部署密度和启动容器的并发性。
图1(b)显示了安全容器的软件栈层次结构。一般情况下,MicroVM 中的 guest 操作系统(GuestOS)和 host 上的资源调度都被转交给云提供商负责。rootfs 是一个文件系统,充当用户代码的执行环境。它是由 host 创建的,并传递给 microVM 中的容器运行时。在 host 端,cgroup 用于为安全容器分配资源,CPU 调度器负责管理资源分配。由此可见,安全容器的复杂层次结构必定会带来了复杂、高额的额外开销。
本文以 SOTA 的开源安全容器技术 Kata-containers 为出发点,通过深入分析从 host-to-guest 架构栈中的瓶颈点,提出了函数计算场景下安全容器高密高部署的 3 个关键观察和挑战:
- 容器的文件系统可以根据用户镜像只读和不需要持久化的特点进行定制;
- 客户机中的操作系统基础映像等可以在多个安全容器间共享和按需压缩以降低内存开销;
- 高并发创建 cgroup 会导致高同步时延,尤其在高密场景下带来的高调度开销。
为此我们提出了 RunD — 超轻量级安全容器运行时,通过全栈的 host-to-guest 解决方案以提供高密度部署和高并发能力的支持。RunD 通过引入读写分离的高效文件系统、预补丁和精简的 guest 内核以及一个全局可供维护的 lightweight cgroup 池以解决上述的三个高密高并发挑战。
根据我们的评估,RunD 启动到应用程序代码只需 88ms,并且每秒可以在一个节点上启动 200 个安全容器。在一个拥有 384GB 内存的节点上,可以使用 RunD 部署超过 2500 个安全容器。目前 RunD 已经作为 Alibaba 的 Serverless 容器运行时,服务超过 100 万个函数,每天调用近 40 亿次。在线统计数据表明,RunD 使得每个节点的最大部署密度已经超过 2000 个容器,并支持超过 200 个容器创建的快速端到端响应。
二、背景
通过以上介绍,我们了解了 RunD 。那么在本节中,我们将首先讨论当前安全容器的设计,以及为何需要引入 RunD 的需求。
2.1 安全容器模型
根据不同级别的安全/隔离需求,目前 Serverless 的生产环境中通常有两类主流的安全容器模型。图2(a)显示了”单虚拟机多容器“的安全容器模型。在该模型中,一个虚拟机(VM)承载着相同函数调用的容器,同一虚拟机中的容器共享虚拟机的 guest 操作系统。在这种情况下,对不同函数采用 VM 级别的隔离,但对同一函数的不同调用为 container 级别隔离。因为每个函数所创建和所需要的容器数量不同,该模型会导致潜在的内存碎片。虽然我们可以在运行时回收内存碎片,但这可能会严重影响函数性能,甚至在虚拟机内存热拔失败时导致程序崩溃。
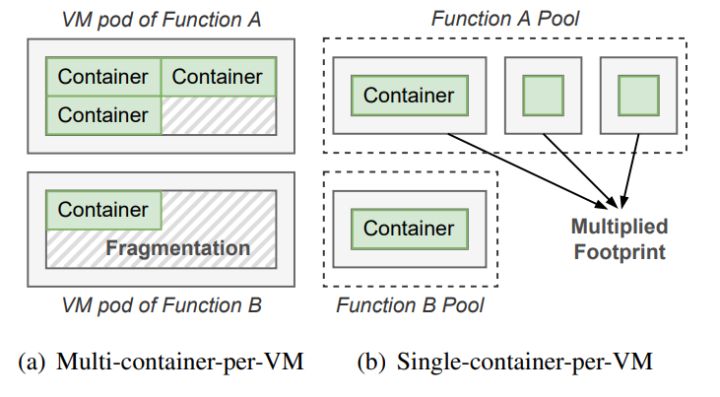
(图2/两种主流的安全容器模型隔离)
图2(b)显示了隔离每个函数调用的“单虚拟机单容器”的安全容器模型。目前的无服务器计算提供商主要使用这种安全容器模型。在此模型中,每个调用都在一个 microVM 中的容器中隔离并执行函数。这个模型没有引入内存碎片,但是虚拟机本身的内存开销很大。很明显,每个 microVM 都需要运行其专用的客户操作系统,从而增加了内存占用。安全容器依赖于硬件虚拟化和 VMM 的安全模型,通过系统调用检查显式地将 guest 内核视为不可信环境。在这种隔离和安全性的前提下,RunD 主要针对“单虚拟机单容器”的安全容器模型。
2.2 Serverless 场景下的需求
在 Serverless 场景下如果应用安全容器进行隔离,天然的细粒度隔离带来了新的复杂场景,我们需要满足一个硬性需求和两个衍生需求:
- 高速:无服务器计算的极致的自动扩展能力允许实例数量根据负载特性动态横向扩展,创建速度要快,E2E 启动时间达到百毫秒级。已有大部分工作致力于解决相关问题。但是还需要保证启动时延的鲁棒性,使得其不会明显受到运行时干扰,比如当前并发数和部署密度的影响。
- 高频:每天上百万的实例创建量,上亿次的函数调用,需要支撑每秒内容器的高并发创建。与此同时,新兴的互联网服务往往呈现波动的负载模式(如外卖软件在中午和晚上负载高,其他时间段负载低),并出现突发负载。当负载爆发时,需要创建大量的容器。虽然目前可以通过一些技术,如预热容器来缓解容器冷启动,但爆发性负载依旧会非常容易的击穿预热容器池。对于无服务器平台来说,支持高并发启动的能力至关重要。
- 高密:大量容器共存于工作节点中,为保证极致弹性和资源利用率,需要考虑内存和 CPU 资源占用问题。如果一个安全容器没有任务隔离开销,拥有 256GB 内存的节点可以托管 8×256 = 2048 个容器。如果没有特别的优化,安全容器会明显降低无服务器计算中的部署密度。在相同的基础设施下,增加部署密度可以极大地提高资源利用率和多租户服务效率。
三、问题分析和见解
在本节中,我们将分析使用安全容器实现高并发启动和高密度部署的问题。
使用 Kata 容器作为安全容器运行时的代表来执行以下研究。
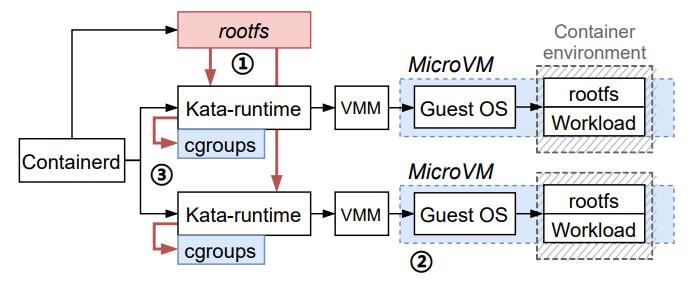
图3/并发启动Kata容器的步骤。并发瓶颈点在于创建rootfs(红色块步骤1)和创建cgroups(红色线步骤3)密度瓶颈点在于MicroVM的高额内存开销(蓝色块步骤2)和大量cgroups的调度维护开销(蓝色块步骤3)
图 3 显示了启动 Kata 容器的步骤。首先,containerd 并发地创建容器运行时 Kata-runtime 并准备 runc 容器的 rootfs。其次,hypervisor 加载 GuestOS 和准备好的 rootfs,在 microVM 中启动 runc 容器。第三,函数工作负载被下载到容器中,然后开始运行。
与启动传统容器相比,在启动安全容器时,我们有两个观察结果。
- 当并发启动 100 个或更多 Kata 容器时,在准备 Kata 运行时创建 rootfs 和 cgroup 会有明显的性能下降。这种降低导致启动容器的并发性较低。
- 当在一个 384GB 内存和 104 个核的节点上部署超过 1000 个 128MB 内存规格的 Kata 容器时,虚拟机的内存占用(guest内核和rootfs)已经占据了大部分内存空间。同时,容器的 I/O 性能也会严重下降。
图 3 还显示了我们发现的导致上述两个结果的三个瓶颈。一般来说,创建 rootfs 和 cgroup 的低效会导致低容器启动并发。较高的内存占用和调度开销导致较低的容器部署密度。我们将在下面的小节中分析各个瓶颈点。
3.1 容器的 rootfs 的高时空开销
在 kata-runtime 中,容器的 rootfs 主要可以选择 9pfs、devicemapper、virtio-fs 三种方案。9pfs 和 virtio-fs 属于文件级别的方案,devicemapper、属于块设备层方案。
为了选择合适的高并发场景下的容器rootfs方案,我们首先需要对比 9p、devicemapper 和 virtio-fs 方案之间的性能,主要分为 buffer I/O 和 direct I/O 在顺序读、顺序写、随机读、随机写和随机读写几个方面,关注 IOPS 和带宽数据。另外也测试了 runc 在 host 上使用 ext4+overlayfs 存储环境的数据作为对比。
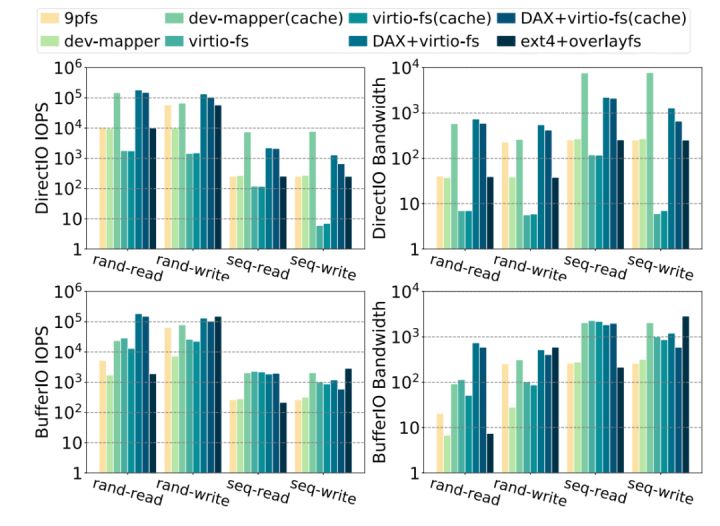
(图4/使用不同rootfs实现的随机和顺序读、写的IOPS和带宽性能)
对比上述三种方案,我们首先摒弃基于 9p 方案的高密高并发容器架构,原因是由于其 mmap 操作上 POSIX 语义兼容性问题和性能较差。然后,我们分别测试了基于 devicemapper 和 virtio-fs 的方案性能,并发现两种方案各自的问题:
- 在默认配置下(即writeback),devicemapper 的随机/顺序 写 性能较好。但是在高并发场景下创建、删除慢。在没有 I/O 压力情况下,创建一个device mapper thin-lv 需要 30-40ms 的时间,在大 I/O 压力下,创建时间可能会到秒级甚至 10s级,造成创建 snapshot 失败和容器创建失败。高密场景下内存开销高。devicemapper需要为每一个 microvm 准备 rootfs.img,但同时又不支持 host/guest 共享 volume 功能,于是 virtio-blk backend 读取 host上rootfs image 文件会产生这个文件的 host pagecache;在 guest 里再读取这个 block 设备内容时,在 guest 内部也会产生一次同样内容的pagecache,就形成了 double pagecache。
- virtio-fs 是专门为 KATA 场景设计的方案,有着良好的性能和完善的 POSIX 语义兼容性。virtio-fs 在使用 DAX 的情况下,dax+virtio-fs 各项随机/顺序读性能指标都很好,但是在高密高并发场景下写性能很差,同时 virtiofsd 承载容器读写的压力时,会造成 virtiofsd 在 host 上过高的 CPU 使用率。所以不适合大 I/O 压力场景,和大量小文件或者 metadata 操作的场景。
总结下来,我们可以得出这样的见解:在现有 kata 架构和存储方案下,任何单一存储方案不适用于高密高并发的场景。需要将容器 rootfs 的存储变为读写分离模式,其中:读方面,可以使用 dax+virtio-fs 方案能够在保证性能的前提下,共享 host/guest 之间 page cache,降低内存开销。写方面,应用现有基于device mapper的高开销方案需要降低可写层设备的创建时间,以及解决 double pagecache 的问题。基于 virtio-fs 的低性能方案需要演进至扩展到满足大 I/O 压力场景的前提,以及降低 host 上的 CPU 开销。因此现有方案都不适用,需要寻找替换方案。
3.2 单 MicroVM 的高内存空间开销
在高密下单个实例资源直接影响部署容器数量。高密部署下单个实例的除了提供给用户需要的内存规格大小以外,其他组件的资源占用往往是一个高额开销。firecracker 在发布时将内存占用减少到 5MB,但这个仅仅是 firecracker VMM 的占用,运行内核包括代码段、数据段等,以及内核管理内存的 struct page,启动的 rootfs 等内存资源,不能只从 VMM 的内存占用来评估实例的额外占用。比如,通过启动数个 AWS 128MB 的 lambda 函数实际的平均内存开销是 71MB,传统的 QEMU 带来的内存开销则更大,达到了 145MB。
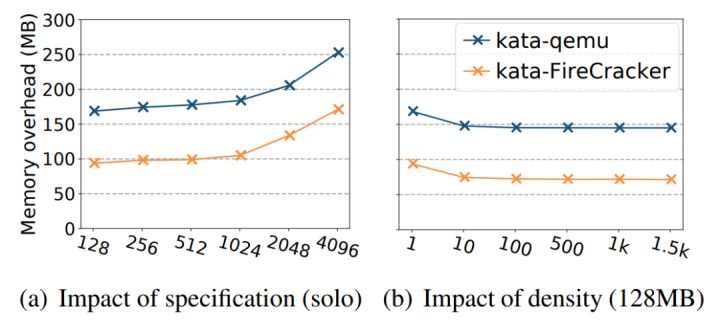
(图5/Kata安全容器使用不同hypervisor的平均内存开销)
目前 state-of-the-art 的方式是使用模版来解决 double page cache 以实现高密部署。一般情况下同一台物理机上每一个安全容器实例的 guest 内核都是相同的,模版利用 mmap 技术替代文件 IO 操作,将内核文件直接映射到 guest 内存中。这样,guest 内核就可以按需载入内存,并且其 text/rodata segment 可以在多个 kata 实例中共享,并且模板中没有被访问到的内容也不会被载入到物理内存中,安全容器实例的平均内存的消耗自然就会大大减少。
然而,由于操作系统内核中的自修改代码,模板技术并没有我们想象的那么高效。自修改代码技术在运行时按需修改指令,Linux 内核在很大程度上依赖于自修改代码来提高启动和运行时的性能,因此这样会导致有许多本应是只读的内存依旧被 guest 内核修改。我们从一个模板启动一个带有 CentOS 4.19 内核的虚拟机,来研究自修改代码的影响。当通过模版启动一个 128mb 实例后,发现17M(18432K)的 geust kernel 代码和只读数据,启动过程中实际只访问了不到 10M(10012K),但是在被访问的 10M 数据中居然有 7M(7928K)多的数据被修改了。这个例子表明,当使用 mmap 来减少内核映像文件的内存消耗时,自修改代码降低了共享效率。
因此,我们的第二个见解是由于 kernel 的自修改特性导致利用模版技术时,可供共享的内存数量有所减少。如果能解决利用模版时创建过程中 guest 内核启动时自修改代码,我们还能节省更多内存以覆盖大部分动态内存消耗。
3.3 cgroup 的高 CPU 时间开销
Cgroup 是为资源控制和流程抽象而设计的。在 Serverless 场景下,函数调用的频率显示出很大的变化。在这种情况下,平台会频繁创建并回收相应的安全容器。例如,在我们的无服务器平台中,在一秒钟内最多可以在一个物理节点上同时创建和回收 200 个容器。频繁地创建和回收对主机的 cgroup 机制提出了挑战。
当并发创建 2000 个容器时,我们测量 cgroup 操作的相关指标和性能图如图 6 所示。在实验中,我们使用不同数量的线程来执行 cgroup 操作。图6(a)显示了容器创建延迟的累积分布。单线程场景中, 容器启动时创建 cgroup 并初始化所用的耗时约为 1ms,在总创建的 cgroup 数量相同,多线程并行的场景下,低并发启动场景下能够获得少许性能提升。但在高并发场景下,与我们的直觉相反,尽管每个线程创建的 cgroup 变少了,但总耗时反而增加了,甚至不如单线程的连续操作的效果。
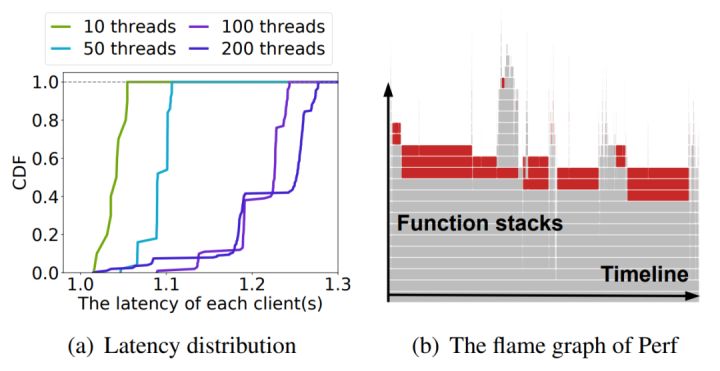
(图6/并发创建2000个容器时的cgroup性能)
其中的原因是:cgroup 实现非常复杂,涉及 10 多类资源控制(cgroup subsys),内核为了简化 cgroup 的设计引入了 cgroup_mutex ,css_set_lock、freezer_mutex、freezer_lock 等大锁,使得 cgroup 相关的操作都是串行化的;在高并发场景下,导致了整个创建链路上的串行执行会拖慢并发创建的效率,增加长尾延迟。图6(b)显示了同时使用 10 个线程创建 2000 个 cgroup 的火焰图。在图中,红色部分显示“互斥锁”被激活。当 mutex 中默认使用了 osq_lock 乐观锁优化,在 cgroup 抢不到锁的情况下会自旋一会儿,导致多线程场景大量消耗 CPU 资源,不能及时退出临界区,从而影响正在运行的函数实例。
除此之外,cgroup 机制是为通用业务场景设计的,设计之初并没有考虑到云原生场景会如此大规模的使用它们 。在一个上千容器共存的faas节点中,cgroup 总数轻松突破 1 万。在 CFS 调度器中,有遍历各自 cgroup subsys 所有对象的行为。在高密场景下,系统中 cgroup 数量很多时,导致调度器中的热点函数变为瓶颈,导致高 CPU 调度开销。(占整机的平均调度开销的 7.6%)
针对上述发现,我们的第三个见解是,Serverless 场景下 host 上的 cgroup 存在高密高并发的瓶颈,需要:
1)降低 cgroup 中由于 mutex 锁引入的“临界区”大小,最好是消除;
2)同时精简 cgroup 的功能,同时降低 cgroup 设计的复杂度。
四、RunD 设计和实现
上述分析揭示了在 host、MicroVM、guest 三层架构栈中实现高并发启动和高密度部署的瓶颈。为此,我们提出了 RunD,一个整体的安全容器解决方案,解决了跨容器的重复数据、每个虚拟机的高内存占用和 host 端 cgroup 的高开销问题。在本节中,我们首先展示 RunD 的总体设计,然后介绍每个组件的细节,以解决相应的问题。
4.1 总体架构及流程
在设计 RunD 时,我们得到了关于无服务器运行时的一个关键启示。在高密度和高并发的 Serverless 场景中,传统VM中微不足道的 host 端开销可能会造成放大效应,任何微不足道的优化都可以带来显著的好处。
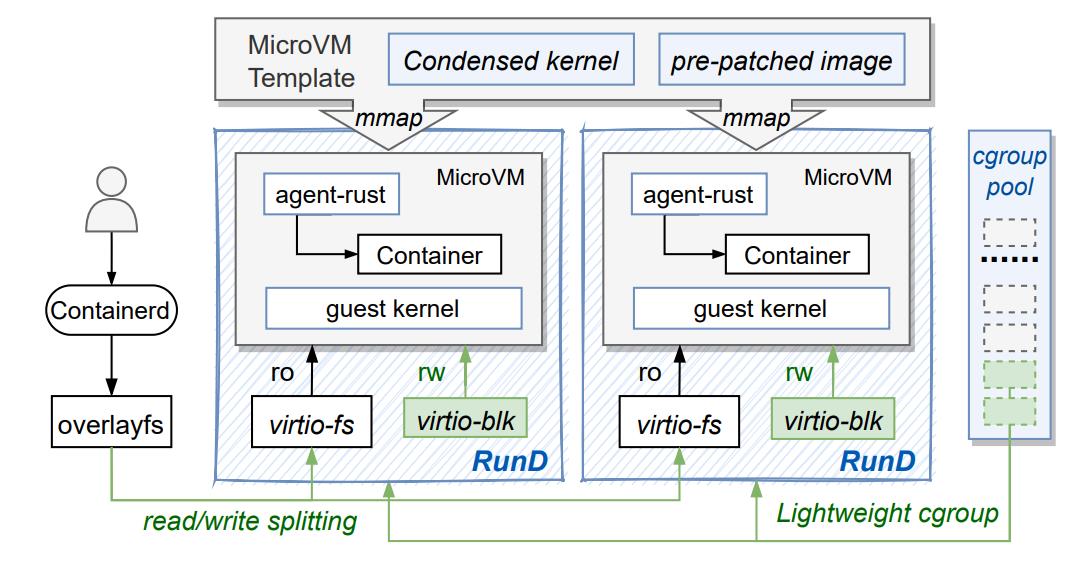
(图7/轻量级Serverless运行时RunD架构图)
图7显示了 RunD 设计并总结了 host-to-guest 的全栈解决方案。RunD 运行时通过 virtio-fs 提供只读层,使用 built-in storage 为 virtio-blk 创建一个非持久的读写层,并使用 overlayfs 将前者和后者挂载为最终的容器 rootfs,从而进行读/写分离。RunD 利用集成了精简内核的 microVM 模板,并采用预处理的镜像创建一个新的 microVM,进一步分摊了不同的 microVM 的开销。在创建安全容器时,RunD 从cgroup 池绑定一个轻量级的 cgroup 进行资源管理。
基于上述优化,当使用 RunD 作为安全容器运行时,安全容器将按照以下步骤启动:
第一步:一旦 containerd 接收到用户调用,它将请求转发给 RunD 运行时。
第二步:RunD 为虚拟机 hypervisor 准备 runc 容器的 rootfs。rootfs 被分为只读层和可写层。
第三步:hypervisor 使用 microVM 模板创建所需的沙箱,并通过 overlayfs 将 rootfs 挂载到沙箱中。
最后一个轻量级的 cgroup 从 cgroup 池中被重命名,然后绑定到沙箱上,管理资源使用。
4.2 高效 rootfs 读写分离
我们分析了容器 rootfs 中的高密高并发场景下各种方案的优点与缺点。microvm 中container rootfs 所面临的根本问题,其实都是数据持久化需求所带来的问题。传统存储需求和场景需要非常高的稳定性和数据一致性,也就是在任何情况下都不能丢数据,但数据持久化在函数计算这个场景下完全是不需要的,我们需要的只是一个临时存储,host 节点宕机重启我们只需要重新初始化并拉起新的容器,之前的数据都不再需要了。所以,我们完全可以放下这个负担,并且充分利用好不需要持久化的临时存储这个特性。
为此我们把容器镜像分成只读和可写两层,那么 containerd 的 snapshotter 应该只负责提供镜像的只读内容,可写层资源应该属于具有临时存储特性的 sandbox,把容器创建和可写层设备创建解耦开来。为了让可写层设备后端文件和 sandbox 也就是 rund 的生命周期绑定到一起,并且尽可能避免 double pagecache 的问题,我们使用了 xfs 文件系统的 reflink 功能实现可写层文件的 CoW,同时利用了open-but-unlinked 文件的特性,在创建sandbox的时候只需要做一次 reflink copy,打开文件之后 rund unlink 文件,不需要做其他生命周期管理了,实现了 sandbox 退出后文件会自动删除。我们引入了的架构如下图 8 所示:
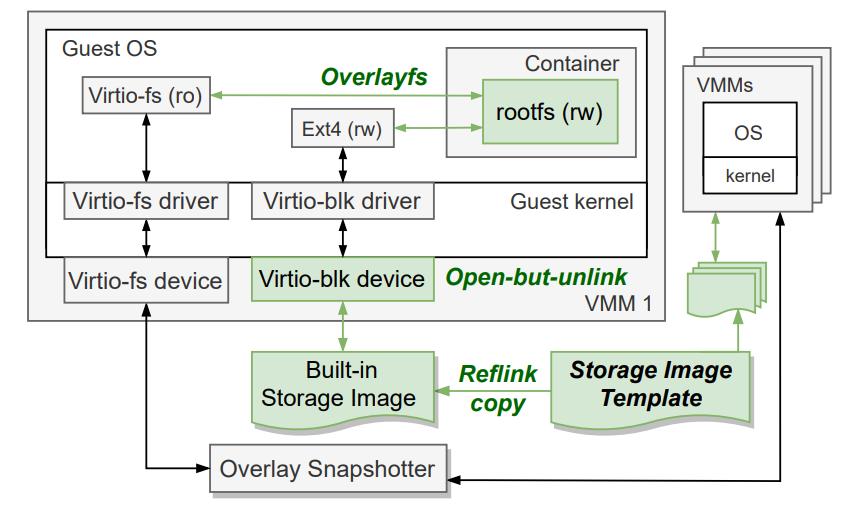
(图8/容器rootfs的读写分离实现)
- 使用 overlay snapshotter,创建容器镜像 rootfs,并通过 virtiofs 透传给 VM,作为容器 rootfs 的只读层。
- 将把 reflink copy 后的文件作为 virtio-blk 设备的后端,将 reflink copy 后的可写层文件作为 block 设备内置在 microvm 中作为临时存储,作为容器 rootfs 的可写层。
- 在 VM 内使用 overlayfs,virtiofs 作为 lower layer,reflink 文件的挂载点作为upper layer,挂载成 overlayfs,作为容器最终的 rootfs。
通过 reflink 方式实现可写层文件的 CoW,并且由于是本质上是 block 设备的方案,在读写性能上和 devicemapper 基本持平。与传统基于块设备的 rootfs 实现方式对比,在 200 容器并发创建的场景下,reflink 方式的磁盘使用率显著下降 (60% (4500 iops, 100MB/s) -> 20% (1500 iops, 8MB/s)),创建可写层设备的平均时间从 207ms 下降到了 0.2ms,足足下降了 4 个数量级!
4.3 内核精简和代码自修改补丁
在 Serverless 的场景下,guest 内核中的许多功能是不必要且占用内存的,因此我们可以在编译的时候关闭这些选项。精简 guest 内核时,我们服从以下原则:
- 尽量降低内存消耗
- 不损失 faas 场景需要的功能
- 基本不影响运行时性能
通过 case by case 的精简,使得内存开销下降了约 16MB,内核文件体积下降了约4MB。我们首先将精简过的 kernel 和上节介绍的 container rootfs 存储应用在模板技术中,然后再解决从模版启动容器后内核自修改的问题。
我们发现内核代码段的自修改只存在于启动时,在启动后,这些代码段将不再会被修改,并且同一物理机中的所有 rund 实例一般都使用同一内核,它们初始化过程是完全相同的,因此它们修改后的代码段也是相同的。于是,我们便可以预先生成一个自修改代码段后的内核文件(pre-patched kernel image),并且使用其替换原来的内核文件,这样,我们就能够尽可能多地在不同安全容器的实例间共享内核文件了。为了适配这种模式,我们也对内核进行了少量 hack 工作,修复了一些使用 pre-patched kernel image 时可能导致 kernel panic 的问题。
使用模版技术不仅可以降低单个实力的内存占用实现高密部署,还非常适合应用于安全容器的高并发场景。因为它可以在某个特定时刻对一个已经启动的安全容器创建快照,并将其作为其它安全容器的启动模板,这样我们就可以通过这个模板快速拉起多个安全容器。本质就是将每个安全容器启动过程中的相同步骤的结果进行记录,然后直接跳过相同步骤,直接基于该中间结果启动安全容器。
4.4 轻量级 cgroup 和池化
在之前的小节中我们分析了在 host 中 cgroup 成为了容器在高密高并发下的瓶颈之一,自然的想法就是减少 cgroup 的数量和相关操作。我们的进一步研究揭示了两个方面的优化机会:
- cgroup 的创建和销毁比较耗时(临界区很大),且不能并行化。但是cgroup 重命名是一个非常轻量化的操作,且不涉及全局锁。
- Serverless 高密场景下,所需要的 cgroup subsys 的层次结构是确定的,同时一个单机上所能创建的最大函数实例数量是可以预先定义的。
为此,我们使用轻量级 cgroup (lightweight cgroup)管理每个 RunD 实例。如图 9 所示,我们使 mount cgroup 时将所有的 cgroup subsys (cpu, cpuacct, cpuset, blkio, memory, freezer))聚合到一个 lightweight cgroup 上,这帮助 RunD 减少容器启动时冗余的 cgroup 操作,显著减少了cgroup 和系统调用的总数。
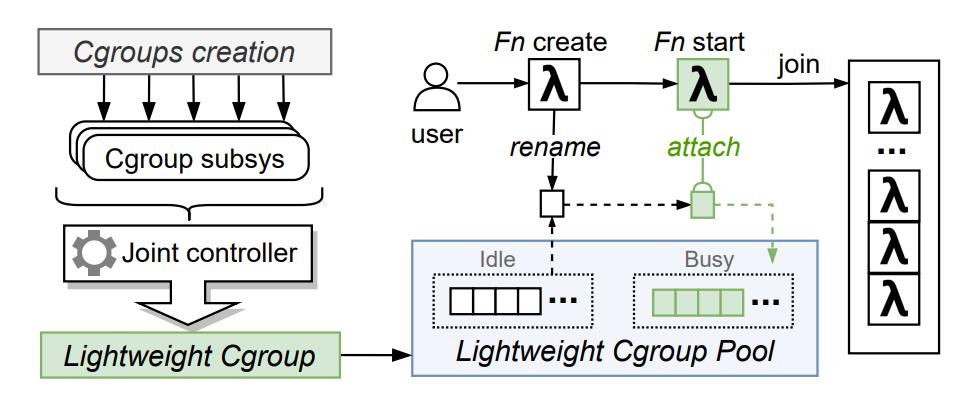
(图9/轻量级cgroup和池化设计)
同时我们维护一个 cgroup 资源池,将所有初始创建的 cgroup 标记为空闲;通过一个 mutex 保护空闲链表,创建一个函数实例时,从空闲链表中获取 cgroup,并标记为使用;当容器启动时将线程 attach 到对应分配的 cgroup 即可。当销毁一个函数计算实例时,只需要 kill 对应的实例进程,不需要删除 cgroup;将 cgroup 还会资源池,标记为空闲。需要注意的是 cgroup 资源池管理涉及同步和互斥问题,必须要保证这个临界区很小,否则不能达到提高并行度的效果。
Lightweight cgroup 池去除了cgroup 的创建和初始化操作,同时利用cgroup rename 机制为新的实例分配 cgroup,极大的缩小了临界区,提高并行性。通过这一简单思想,cgroup 操作耗时大幅度降低,创建速度提升了 15 倍,达到了近 94% 的性能优化。
五、性能测试
5.1 并发度指标测试
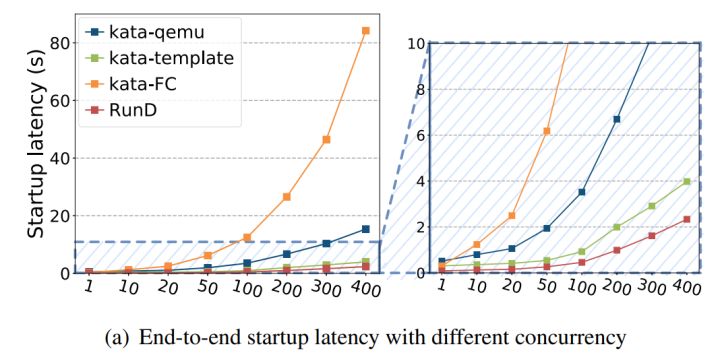
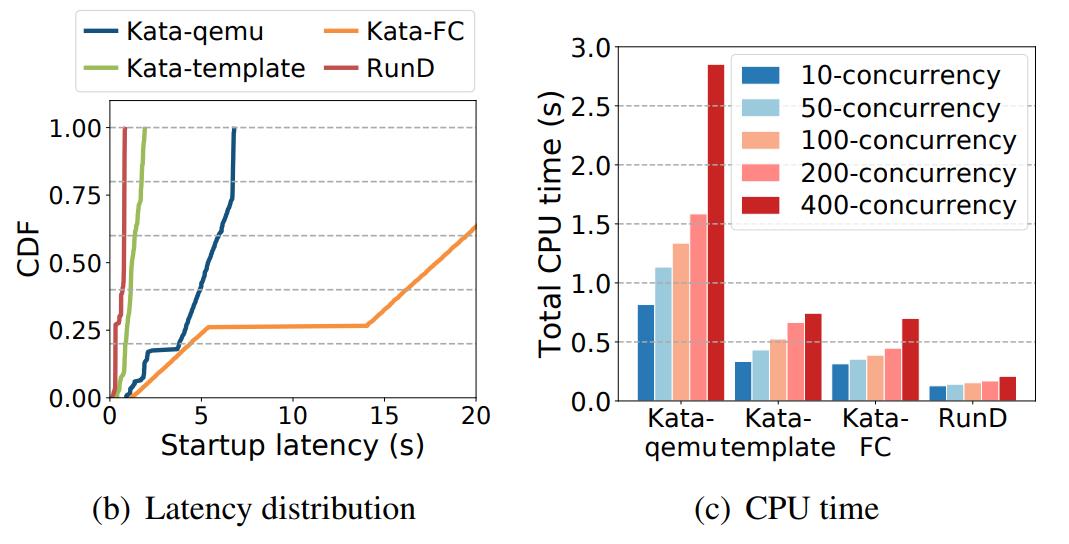
(图10/高并发创建场景下端到端时延、分布、和CPU开销)
并发性能总结:RunD 能够在 88ms 内启动一个单独沙盒,并具备在 1 秒内同时启动 200 个沙箱的并发能力,与现有技术相比,具有最小的延迟波动和 CPU 开销。
5.2 单实例开销和部署密度测试

(图11/不同运行时的沙箱内存开销(100密度下))
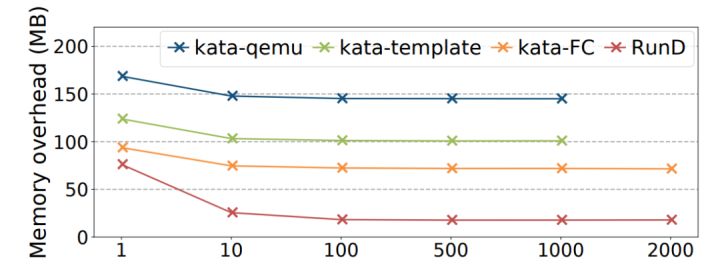
(图12/不同密度下的平均内存摊销(缺失点表示已达到最大部署密度))
高密部署总结:RunD 支持在内存为 384GB 的节点上部署超过 2500 个 128MB 内存规格的沙盒。且每个沙盒的平均内存占用小于 20MB。
5.3 部署密度对并发度的影响测试
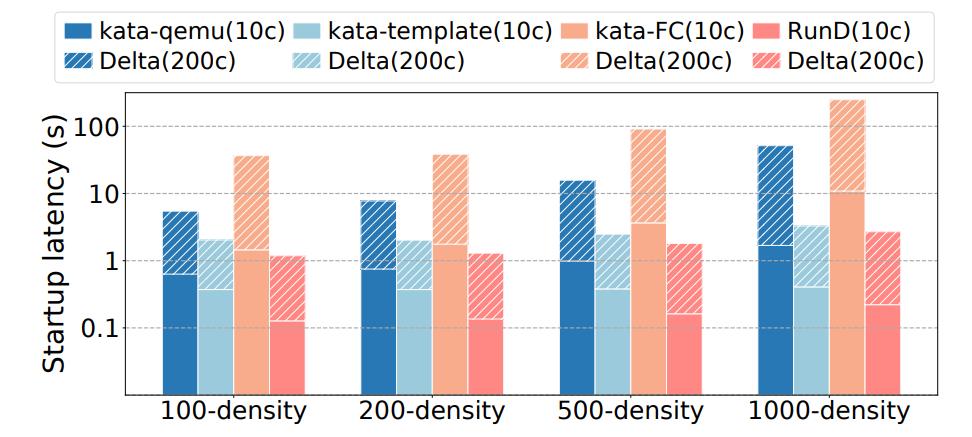
(图13/在不同密度下的并发性能(10c/200c表示10并发/200并发,Delta代表更高密度带来的开销增量))
高密下高并发能力总结:在高密度部署下,RunD 在支持高并发创建方面表现出了更好的性能和稳定性。
总结
根据实验评估,RunD 可以在 88 毫秒内启动,并且在 104 核 384GB 内存的单节点上每秒启动超过 200 个安全容器,高密部署超过 2500 个函数实例。RunD 作为阿里云的 Serverless 运行时已经部署上线,每天为超过 100 万个函数和近 40 亿的调用提供服务,并积极推进 Kata 社区 3.0 架构的演变。
本文为阿里云原创内容,未经允许不得转载。
以上是关于ATC‘22顶会论文RunD:高密高并发的轻量级 Serverless 安全容器运行时的主要内容,如果未能解决你的问题,请参考以下文章
阿里云飞天论文获国际架构顶会 ATC 2021最佳论文:全球仅三篇