修改Hive运⾏⽇志的存放位置
Posted kalani呀
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了修改Hive运⾏⽇志的存放位置相关的知识,希望对你有一定的参考价值。
默认情况下,Hive的运⾏⽇志存放在/tmp/root/hive.log ⽬录下(root是当前⽤户登录 ⽤户名)。 修改hive的⽇志存放到/export/servers/hive/logs⽬录下。 1. cd /export/server/hive/conf/,找到下面的文件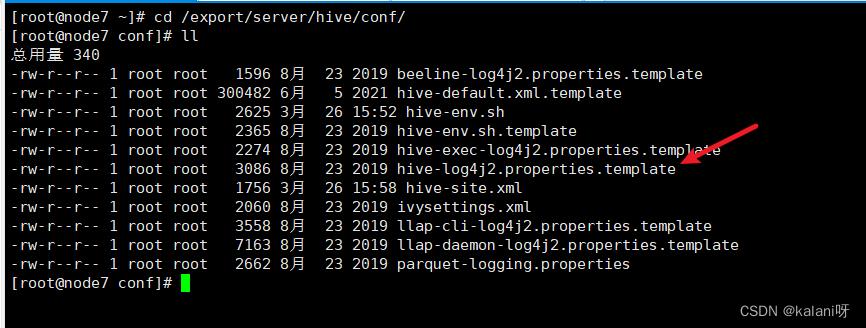
修改/export/server/hive/conf/hive-log4j2.properties.template ⽂件名称为hive-log4j2.properties
cp /export/server/hive/conf/hive-log4j2.properties.template hive-log4j2.properties
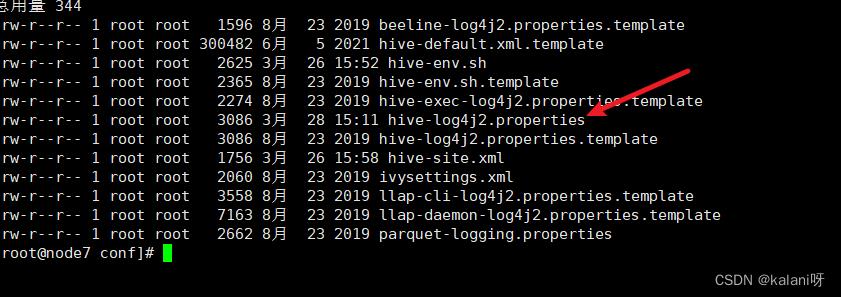
2.在 hive-log4j2.properties ⽂件中修改 log 存放位置
vi hive-log4j2.properties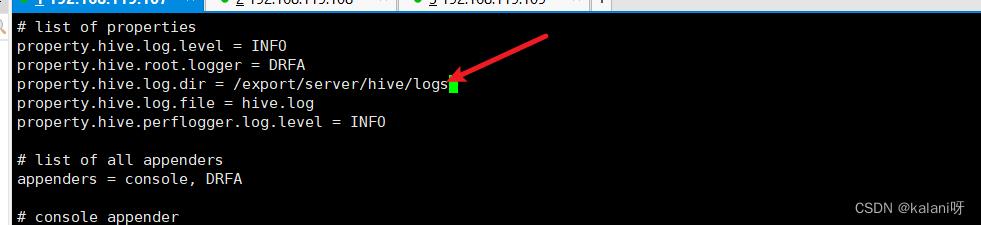
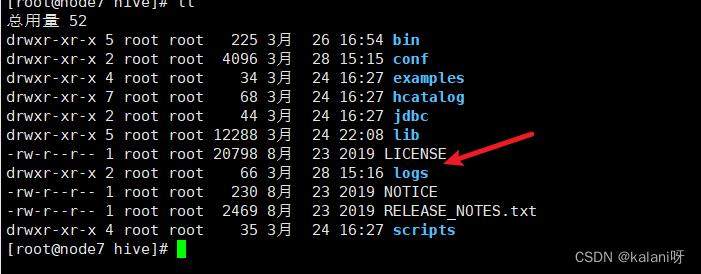
3. ⽤hive-script.sh restart重启服务后,查看/export/server/hive/logs⽬录 ,已生成新的日志。
hive中创建外部分区表使用location是指定数据存放位置还是指数据来源
指定数据存放位置,如果没有指定,就会在hdfs的默认位置建立表文件。
Hive 没有专门的数据存储格式,也没有为数据建立索引,用户可以非常自由的组织 Hive 中的表,只需要在创建表的时候告诉 Hive 数据中的列分隔符和行分隔符,Hive 就可以解析数据。
Hive 中所有的数据都存储在 HDFS 中,Hive 中包含以下数据模型:表(Table),外部表(External Table),分区(Partition),桶(Bucket)。

扩展资料:
Hive中的表和数据库中的表在概念上相似。 每个表在Hive中都有一个对应的目录来存储数据。
例如,一个表pvs,其在HDFS中的路径为:/ wh / pvs,其中wh是在 hive-site.xml 中由 $hive.metastore.warehouse.dir 指定的数据仓库的目录,所有表数据( 不包括外部表)存储在此目录中。
Partition 对应于数据库中的 Partition 列的密集索引,但是Hive中的Partition的组织方式与数据库中的完全不同。 在Hive中,表中的Partition与表下的目录相对应,所有Partition的数据都存储在相应的目录中。
参考技术A 外部表的话,这个路径既是数据存放位置也是数据来源路径,因为外部表不会移动数据 参考技术B 当然是指定数据存放位置,如果没有指定,就会在hdfs的默认位置建立表文件 参考技术C 首先,Hive 没有专门的数据存储格式,也没有为数据建立索引,用户可以非常自由的组织 Hive 中的表,只需要在创建表的时候告诉 Hive 数据中的列分隔符和行分隔符,Hive 就可以解析数据。其次,Hive 中所有的数据都存储在 HDFS 中,Hive 中包含以下数据模型:表(Table),外部表(External Table),分区(Partition),桶(Bucket)。Hive 中的 Table 和数据库中的 Table 在概念上是类似的,每一个 Table 在 Hive 中都有一个相应的目录存储数据。例如,一个表 pvs,它在 HDFS 中的路径为:/wh/pvs,其中,wh 是在 hive-site.xml 中由 $hive.metastore.warehouse.dir 指定的数据仓库的目录,所有的 Table 数据(不包括 External Table)都保存在这个目录中。
Partition 对应于数据库中的 Partition 列的密集索引,但是 Hive 中 Partition 的组织方式和数据库中的很不相同。在 Hive 中,表中的一个 Partition 对应于表下的一个目录,所有的 Partition 的数据都存储在对应的目录中。例如:pvs 表中包含 ds 和 city 两个 Partition,则对应于 ds = 20090801, ctry = US 的 HDFS 子目录为:/wh/pvs/ds=20090801/ctry=US;对应于 ds = 20090801, ctry = CA 的 HDFS 子目录为;/wh/pvs/ds=20090801/ctry=CA
Buckets 对指定列计算 hash,根据 hash 值切分数据,目的是为了并行,每一个 Bucket 对应一个文件。将 user 列分散至 32 个 bucket,首先对 user 列的值计算 hash,对应 hash 值为 0 的 HDFS 目录为:/wh/pvs/ds=20090801/ctry=US/part-00000;hash 值为 20 的 HDFS 目录为:/wh/pvs/ds=20090801/ctry=US/part-00020 参考技术D 方法一:利用编辑器直接插入控制字符,以Vi为例。进入Vi:Shell代码收藏代码$visupply-20110101.txt在Vi命令模式下,键入:setlist,设置控制字符可见,成功后Vi会立即显示一个行结束标志$。填入Hive表中需要的每列数据,比如我这里需要创建一个分区表:Hiveshell代码收藏代码hive(ch09)>createtablesupply(idint,partstring,quantityint)partitionedby(dayint);hive(ch09)>altertablesupplyaddpartition(day=20110101);hive(ch09)>altertablesupplyaddpartition(day=20110102);hive(ch09)>altertablesupplyaddpartition(day=20110103);可以看到一共需要三列数据,分别是id,part,quantity。在Vi中进入编辑模式,并填入:Vi代码收藏代码10part10100$我在这里是想输入10作为ID,part10作为part,100作为quantity,最后的$是行结束标志。然后移动光标到需要插入分隔符的地方,首先键入Ctrl+V,再键入字段分隔符Ctrl+A:Vi代码收藏代码10^Apart10100$依次插入其他分隔符,并完成编辑:Vi代码收藏代码10^Apart10^A100$11^Apart11^A90$12^Apart12^A110$13^Apart13^A80$这时候可以导入数据到HiveTable了:Hiveshell代码收藏代码hive(ch09)>loaddatalocalinpath'$env:HOME/data/supply-20110103.txt'overwriteintotablesupply>partition(day='20110103');Copyingdatafromfile:/root/data/supply-20110103.txtCopyingfile:file:/root/data/supply-20110103.txtLoadingdatatotablech09.supplypartition(day=20110103)rmr:DEPRECATED:Pleaseuse'rm-r'instead.Moved:'hdfs://n8.example.com:8020/user/hive/warehouse/ch09.db/supply/day=20110103'totrashat:hdfs://n8.example.com:8020/user/root/.Trash/CurrentPartitionch09.supplyday=20110103stats:[num_files:1,num_rows:0,total_size:54,raw_data_size:0]Tablech09.supplystats:[num_partitions:3,num_files:3,num_rows:0,total_size:147,raw_data_size:0]OKTimetaken:0.522seconds查看一下刚才load的数据,确保正确:Hiveshell代码收藏代码hive(ch09)>select*fromsupplywhereday='20110103';OKidpartquantityday10part101002011010311part11902011010312part121102011010313part138020110103Timetaken:0.229seconds可以看到数据完全正确,这里还可以看到,Hive自动把select*这样的操作转换成文件系统操作,没有生成任何MapReduceJob。方法二:自定义HiveTable的分隔符。Hiveshell代码收藏代码CREATETABLEsupply(idINT,partSTRING,quantityINT)PARTITIONEDBY(dayINT)ROWFORMATDELIMITEDFIELDSTERMINATEDBY'.'COLLECTIONITEMSTERMINATEDBY','MAPKEYSTERMINATEDBY'='STOREDASSEQUENCEFILE;这样就可以避开控制字符。出自:/blog/1922887
以上是关于修改Hive运⾏⽇志的存放位置的主要内容,如果未能解决你的问题,请参考以下文章