大数据运维实战:hive锁泄露导致的zookeeper异常
Posted 涤生大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据运维实战:hive锁泄露导致的zookeeper异常相关的知识,希望对你有一定的参考价值。
问题描述:
突然收到生产集群告警HDFS服务两个Failover Controller服务,备节点RM服务,以及集群中的zookeeper服务全部出现异常告警。已提交任务出现大量失败。
问题排查:
查看cm控制台,果然发现告警的几个服务都出现红色告警标志,因为出现问题的服务貌似都和zk服务有关联,于是先排查zk服务异常的原因。
观察zk的几个核心监控指标,最明显的发现角色的cpu突然飙高,cm的Canary 持续时间从平时的几秒直接飙升到二十几秒。同时我们观察到一个核心指标项,zk服务的数据大小也是直线飙升。同时zk服务节点出现GC。
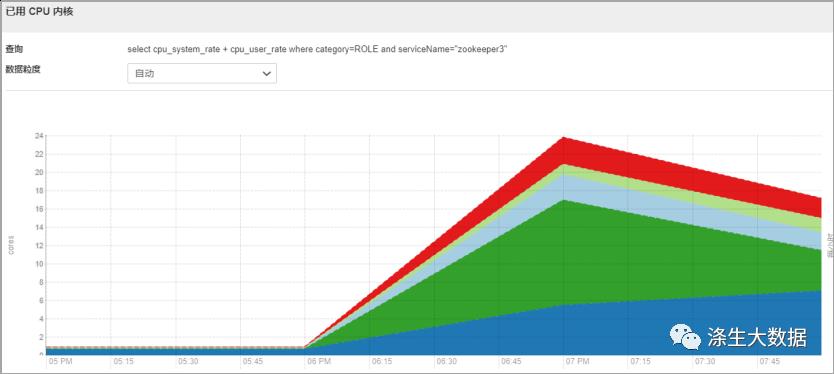
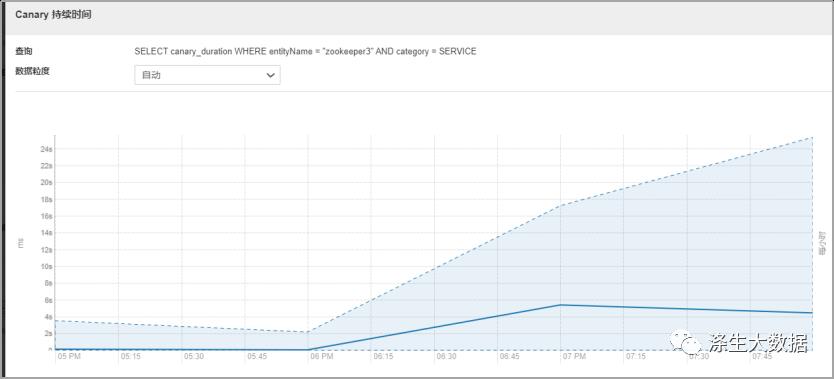
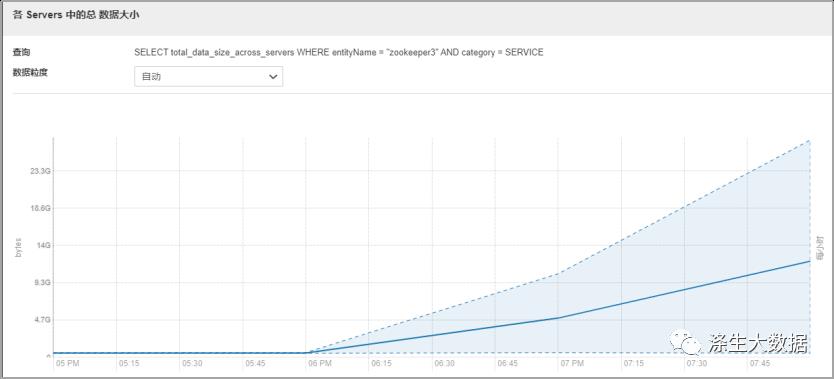
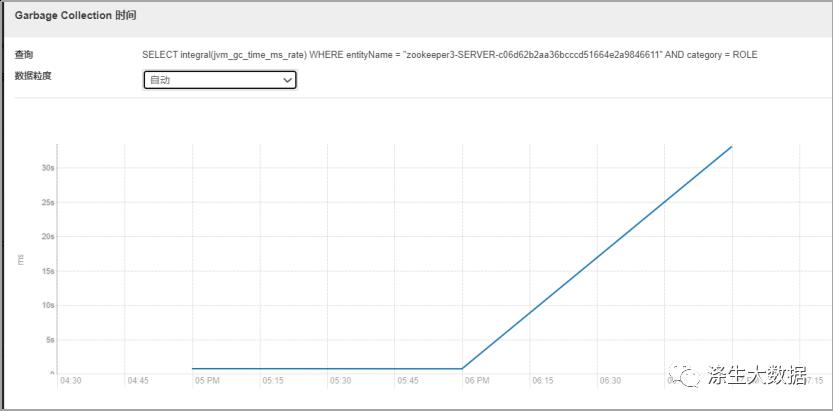
结合以上信息,因为是线上服务,影响面积较大,想着要先恢复服务,于是重启了整个zk集群,但是!!!Zk服务并没有成功启动。并且现象还是zk服务GC。于是想到应该有大量的请求在访问zk服务,到导致zk服务负载过高,触发了GC。
分析zk快照文件:
提示:关于zk快照文件等知识需要大家另行补充!!!下面只列出操作步骤。
通过zk自带的工具类格式化快照文件:
| java -Djute.maxbuffer=3145728 -cp /opt/cloudera/parcels/CDH/lib/zookeeper/lib/slf4j-api-1.7.5.jar:/opt/cloudera/parcels/CDH/lib/zookeeper/zookeeper.jar org.apache.zookeeper.server.SnapshotFormatter /var/lib/zookeeper/version-2/snapshot.33000205eb > /tmp/zk/zk.log |
汇总znode并排序:
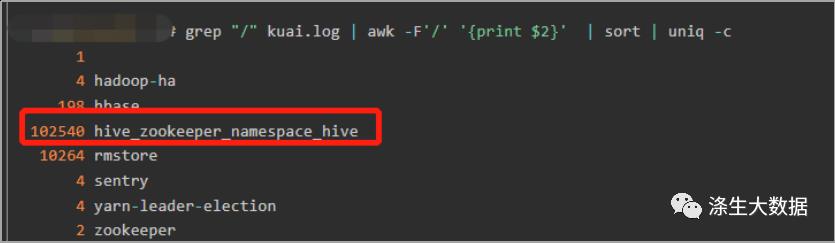
| grep "/" /tmp/zk/zk.log | awk -F'/' 'print $2' | sort | uniq -c |
发现大量的znode集中在hive_zookeeper_namespace_hive。立马想到应该和集群中任务有关,因为这里hive_zookeeper_namespace_hive主要是hive的锁在zk的 持久节点。
查看hive_zookeeper_namespace_hive节点详情:

但是查看集群整体的任务量,发现并没有激增,不是很理解为什么会导致znode节点的激增。
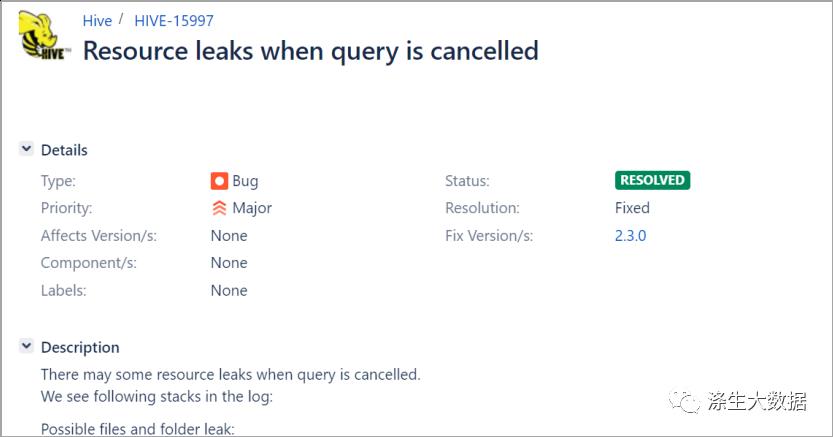
于是乎请教了google,然后出现了以下结论;

出问题去官网查看jiar哈:https://issues.apache.org/jira/browse/HIVE-15997
故障恢复:
知道了问题的原因,于是先临时停止hiveserver2服务,阻止新任务的提交,降低zk的负载,zk这边也加大了jvm的堆内存,然后再重启整个zk服务。Zk服务正常运行。然后重启rm和hdfs服务也都恢复正常。
以上是关于大数据运维实战:hive锁泄露导致的zookeeper异常的主要内容,如果未能解决你的问题,请参考以下文章