Python实现GWO智能灰狼优化算法优化Catboost分类模型(CatBoostClassifier算法)项目实战
Posted 胖哥真不错
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python实现GWO智能灰狼优化算法优化Catboost分类模型(CatBoostClassifier算法)项目实战相关的知识,希望对你有一定的参考价值。
说明:这是一个机器学习实战项目(附带数据+代码+文档+视频讲解),如需数据+代码+文档+视频讲解可以直接到文章最后获取。

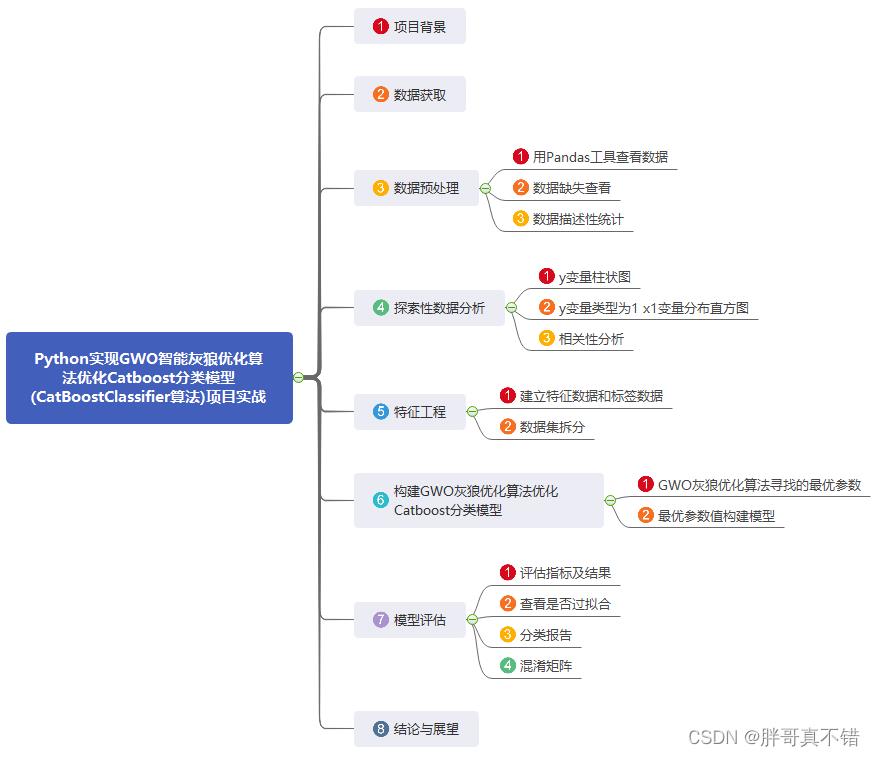
1.项目背景
灰狼优化算法(GWO),由澳大利亚格里菲斯大学学者 Mirjalili 等人于2014年提出来的一种群智能优化算法。灵感来自于灰狼群体捕食行为。优点:较强的收敛性能,结构简单、需要调节的参数少,容易实现,存在能够自适应调整的收敛因子以及信息反馈机制,能够在局部寻优与全局搜索之间实现平衡,因此在对问题的求解精度和收敛速度方面都有良好的性能。缺点:存在着易早熟收敛,面对复杂问题时收敛精度不高,收敛速度不够快。
灰狼群体中有严格的等级制度,一小部分拥有绝对话语权的灰狼带领一群灰狼向猎物前进。灰狼群一般分为4个等级:αβδω(权利从大到小)模拟领导阶层。集体狩猎是灰狼的一种社会行为,社会等级在集体狩猎过程中发挥着重要的作用,捕食的过程在α的带领下完成。主要包括三个步骤:
跟踪和接近猎物
骚扰、追捕和包围猎物,直到它停止移动
攻击猎物
本项目通过GWO灰狼优化算法优化Catboost分类模型。
2.数据获取
本次建模数据来源于网络(本项目撰写人整理而成),数据项统计如下:

数据详情如下(部分展示):

3.数据预处理
3.1用Pandas工具查看数据
使用Pandas工具的head()方法查看前五行数据:

关键代码:

3.2数据缺失查看
使用Pandas工具的info()方法查看数据信息:
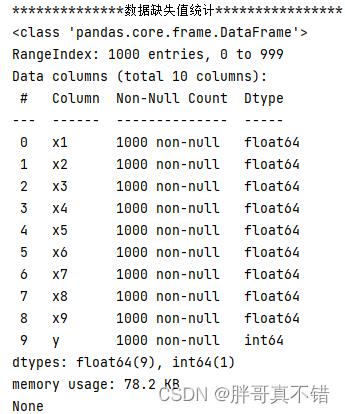
从上图可以看到,总共有10个变量,数据中无缺失值,共1000条数据。
关键代码:

3.3数据描述性统计
通过Pandas工具的describe()方法来查看数据的平均值、标准差、最小值、分位数、最大值。

关键代码如下:

4.探索性数据分析
4.1 y变量柱状图
用Matplotlib工具的plot()方法绘制直方图:

4.2y=1样本x1变量分布直方图
用Matplotlib工具的hist()方法绘制直方图:

4.3相关性分析
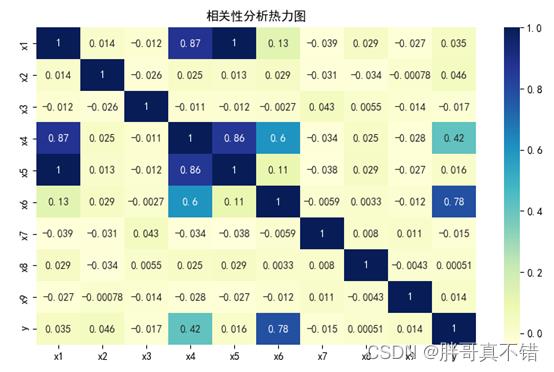
从上图中可以看到,数值越大相关性越强,正值是正相关、负值是负相关。
5.特征工程
5.1建立特征数据和标签数据
关键代码如下:
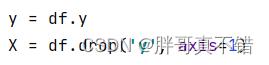
5.2数据集拆分
通过train_test_split()方法按照80%训练集、20%测试集进行划分,关键代码如下:

6.构建GWO灰狼优化算法优化Catboost分类模型
主要使用GWO灰狼优化算法优化CatBoostClassifier算法,用于目标分类。
6.1GWO灰狼优化算法寻找的最优参数
关键代码:

每次迭代的过程数据:
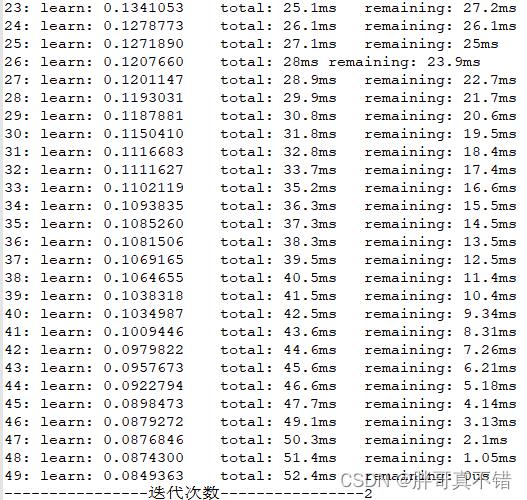
最优参数:
----------------4. 最优结果展示----------------- The best depth is 4 The best learning_rate is 0.101
|
6.2最优参数值构建模型
编号 | 模型名称 | 参数 |
1 | Catboost分类模型 | depth=int(abs(best_depth)) |
2 | learning_rate=best_learning_rate |
7.模型评估
7.1评估指标及结果
评估指标主要包括准确率、查准率、查全率、F1分值等等。

从上表可以看出,F1分值为0.9209,说明模型效果比较好。
关键代码如下:

7.2查看是否过拟合

从上图可以看出,训练集和测试集分值相当,无过拟合现象。
7.3分类报告
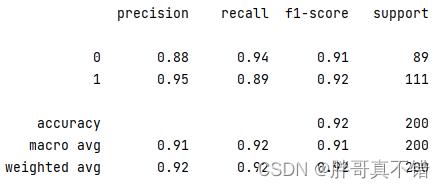
从上图可以看出,分类为0的F1分值为0.91;分类为1的F1分值为0.92。
7.4混淆矩阵

从上图可以看出,实际为0预测不为0的 有12个样本;实际为1预测不为1的 有5个样本,整体预测准确率良好。
8.结论与展望
综上所述,本文采用了GWO灰狼优化算法寻找CatBoostClassifier算法的最优参数值来构建分类模型,最终证明了我们提出的模型效果良好。此模型可用于日常产品的预测。
本次机器学习项目实战所需的资料,项目资源如下:
项目说明:
链接:https://pan.baidu.com/s/1c6mQ_1YaDINFEttQymp2UQ
提取码:thgk更多项目实战,详见机器学习项目实战合集列表:
https://blog.csdn.net/weixin_42163563/article/details/127714353
智能优化算法之灰狼优化算法(GWO)的实现(Python附源码)
文章目录
一、灰狼优化算法的实现思路
灰狼优化算法(Grey Wolf Optimizer,简称GWO)是由Seyedali Mirjalili等人于2014年提出的一种群智能优化算法,这一算法主要由自然界中的灰狼群体的捕食行为启发而来,灰狼是一种群居动物,一般群体中由5到12个个体构成,与一般动物群体不同的是,这一群体中存在十分严格的社会主导阶层,且与金字塔结构十分相似,主要由四个层级构成。
首先最高的层级可以被称为α,它们主要对种群中的各种规则进行制定,如狩猎地点、休息地点等,整个种群都会听从它们的决定。然后第二个层级被称为β,这一层级的灰狼个体主要帮助α制定相关决策,同时将各种决策上出现的问题反馈给α狼,它在整个种群中的地位仅次于α狼,因此低等级的灰狼个体也必须听命于β狼。紧接着的一个阶级为δ,这一个层级扮演着执行者的角色并将α狼与β狼制定的规则与命令付诸行动,它们可以是哨兵、侦查者、猎人,甚至是种群中受伤狼群的看护者。最后一个层级为ω,这个层级的灰狼个体为最弱势的个体,它们一般为种群中年迈或残疾的个体,因此它们只能去服从前面每个层级的灰狼个体。
结合上述思想,可以将灰狼优化算法的原理归为四个基本行为,它们分别为社会等级结构分级、搜索猎物、包围猎物以及攻击猎物,下面将分别从这四个基本行为进行介绍。
1、社会等级结构分级
该算法为了符合灰狼群体的社会等级结构,将候选解决方案的优劣性作为评判的标准,另外由于解决方案的独特性,因此将前三个等级α、β以及δ的数量设定为一个,即将候选解决方案中表现最优的方案设为α,第二个与第三个最优解决方案分别设定为β与δ,其余的解决方案则均为ω。按照等级较低的灰狼个体跟随等级较高的灰狼个体规则,ω解决方案将不断学习α、β以及δ解决方案以获得更好的表现。
2、包围猎物
针对灰狼群体包围猎物的特性,使用下列公式对其行为进行描述:

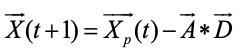
其中t为当前迭代次数,A ⃗和C ⃗为系数向量,(X_p ) ⃗为灰狼个体的位置向量,X ⃗为灰狼个体的位置信息。
A ⃗和C ⃗将分别通过下面两个公式计算得出:
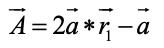

其中a ⃗将随着迭代的次数由2到0线性递减,r1与r2均为0到1之间的随机向量。
3、攻击猎物
通过包围行为,所有灰狼个体将猎物控制在一个包围圈内,之后ω狼将在α、β以及δ狼的引导下进行捕猎,由于目前猎物的位置是未知的,而代表最优解决方案的灰狼α、β以及δ的位置信息是已知的,因此ω狼将通过学习灰狼α、β以及δ的位置信息来进行移动以完成对猎物的捕食。下面几个公式代表了灰狼个体的捕食行为:
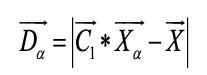

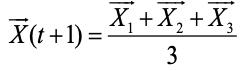
由上述公式可以了解到,猎物的位置是随机的,灰狼个体将通过学习灰狼α、β以及δ的位置信息在猎物附近进行随机移动,以此来估计猎物的具体位置。
4、搜索猎物
在灰狼种群开始了对猎物的随机包围时,对猎物的搜索过程也在随之展开,由攻击猎物的原理过程可以了解到,A ⃗这一系数向量的大小将会直接影响到灰狼个体位置的移动,在整个迭代过程中,除了A ⃗的绝对值小于1外,还存在A ⃗的绝对值大于1的情况,在这种条件下,灰狼个体将向包围圈周围扩张,以此发现更多猎物可能存在的位置。即当|A|≥1时,候选解决方案倾向于偏离当前猎物,当|A|<1时,候选解决方案逐渐收敛于猎物的位置。
除系数向量A ⃗之外,还存在一个系数向量C ⃗,C ⃗通常是0到2之间的一个随机值,这一向量的角色类似于为猎物位置信息新添一个随机权重,在自然界中,灰狼种群对猎物的捕食通常不会是顺利的,有时会出现一定的障碍对整个搜索行为进行影响,使得灰狼种群无法直接快速得接近猎物,系数向量C ⃗则可以在为整个搜索过程增加一个随机性的同时使整个灰狼种群在优化过程中表现出更随机的行为,以此来探索更多区域并避免陷入局部最优。
二、算法步骤
使用灰狼优化算法对优化问题进行求解时的具体步骤可以归纳如下:
- 以种群个体的位置信息作为待优化问题的解,根据待优化问题的解的范围,随机初始化种群所有个体的位置信息;
- 初始化参数a ⃗,A ⃗和C ⃗;
- 根据待优化问题,计算每个种群个体的适应度值,并对其进行排序,适应度值越高,则个体的位置信息越接近最优解,将适应度值排在前三个个体分别设定为灰狼α、β以及δ,并保存当前最优的位置信息;
- 依次对种群中每个个体的位置信息进行更新;
- 针对每个个体更新后的位置信息,重新进行适应度值的计算,根据新的适应度值的大小更新灰狼α、β与δ的位置信息以及历史最优的位置信息,更新参数a ⃗,A ⃗和C ⃗;
- 根据迭代的次数重复步骤3到步骤5,当达到最大迭代次数时停止迭代过程,输出历史最优的位置信息,该位置信息即为算法优化后获得的最优解。
三、实例
待求解问题:
Rosenbrock’s,取值范围为[-10,10],取值范围内的理想最优解为0,将其搜索的空间维度设为20。
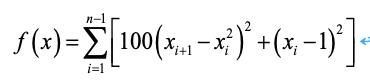
实现源码:
#库的导入
import numpy as np
import matplotlib.pyplot as plt
import heapq
#待求解问题,求解问题为求最小值
def function(x):
y1 = 0
for i in range(len(x)-1):
y2 = 100*((x[i+1] - x[i]**2)**2)+(x[i]-1)**2
y1 = y1 + y2
y = abs(0 - y1)
return y
m = 30 #种群数量
imax = 100 #迭代次数
dimen = 20 #解的搜索维度
rangelow = -10 #解的最小取值
rangehigh = 10 #解的最大取值
amax = 2 #系数向量初始值
#pop用于存储种群个体的位置信息,pop_fitness用于存储个体对应的适应度值
pop = np.zeros((m,dimen))
pop_fitness = np.zeros(m)
#对种群个体进行初始化并计算对应适应度值
for j in range(m):
pop[j] = np.random.uniform(low=rangelow, high=rangehigh,size=(1, dimen))
pop_fitness[j] = function(pop[j])
#allbestpop,allbestfit分别存储种群在历史迭代过程中最优个体解及对应适应度
allbestpop,allbestfit = pop[pop_fitness.argmin()].copy(),pop_fitness.min()
#通过排序找出种群中适应度值最优的前三个个体,并获得它们的位置信息
pop_fitness1 = pop_fitness.flatten()
pop_fitness1 = pop_fitness1.tolist()
three = list(map(pop_fitness1.index, heapq.nsmallest(3, pop_fitness1)))
Xalpha = pop[three[0]]
Xbeta = pop[three[1]]
Xdelta = pop[three[2]]
#his_bestfit存储每次迭代时种群历史适应度值最优的个体适应度
his_bestfit=np.zeros(imax)
#开始训练
for i in range(imax):
print("The iteration is:", i + 1)
#对系数向量的计算参数a进行计算
iratio = i / imax
a = amax * (1 - iratio)
#对每个个体进行位置更新
for j in range(m):
#分别计算在适应度值最优的前三个个体的影响下,个体的位置移动量X1、X2、X3
C1 = 2 * np.random.rand()
Dalpha = np.abs(C1 * Xalpha - pop[j])
A1 = 2 * a * np.random.rand() - a
X1 = Xalpha - A1 * Dalpha
C2 = 2 * np.random.rand()
Dbeta = np.abs(C2 * Xbeta - pop[j])
A2 = 2 * a * np.random.rand() - a
X2 = Xbeta - A2 * Dbeta
C3 = 2 * np.random.rand()
Ddelta = np.abs(C3 * Xdelta - pop[j])
A3 = 2 * a * np.random.rand() - a
X3 = Xdelta - A3 * Ddelta
#计算个体移动后的位置及适应度值
pop[j] = (X1 + X2 + X3) / 3
pop_fitness[j] = function(pop[j])
#对种群历史最优位置信息与适应度值进行更新
if pop_fitness.min() < allbestfit:
allbestfit = pop_fitness.min()
allbestpop = pop[pop_fitness.argmin()].copy()
#通过排序找出种群中适应度值最优的前三个个体,并获得它们的位置信息
pop_fitness1 = pop_fitness.flatten()
pop_fitness1 = pop_fitness1.tolist()
three = list(map(pop_fitness1.index, heapq.nsmallest(3, pop_fitness1)))
Xalpha = pop[three[0]]
Xbeta = pop[three[1]]
Xdelta = pop[three[2]]
#存储当前迭代下的种群历史最优适应度值并输出
his_bestfit[i] = allbestfit
print("The best fitness is:", allbestfit)
print("After iteration, the best pop is:",allbestpop)
print("After iteration, the best fitness is:","%e"%allbestfit)
#输出训练后种群个体适应度值的均值与标准差
mean = np.sum(pop_fitness)/m
std = np.std(pop_fitness)
print("After iteration, the mean fitness of the swarm is:","%e"%mean)
print("After iteration, the std fitness of the swarm is:","%e"%std)
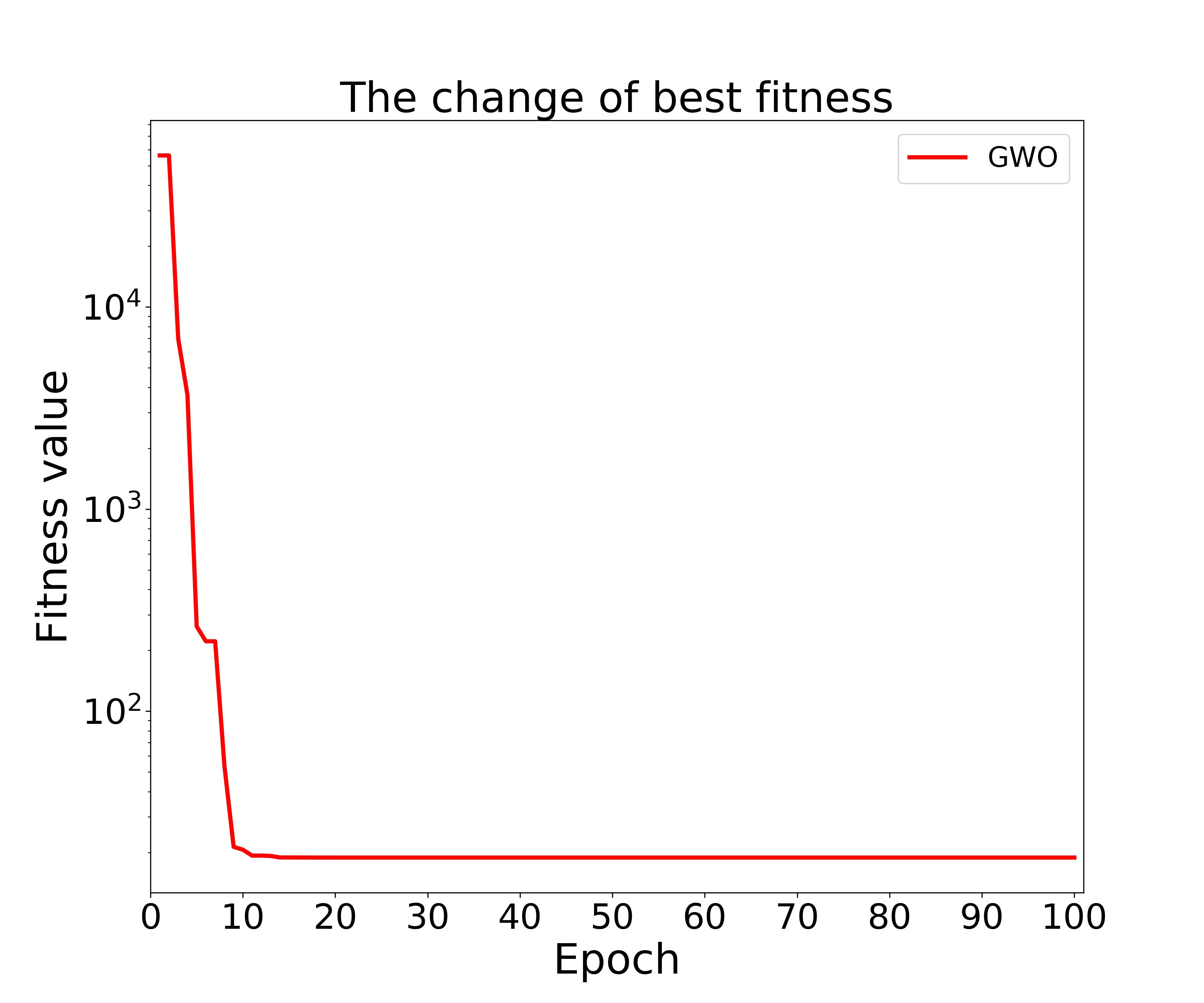
#将结果进行绘图
fig=plt.figure(figsize=(12, 10), dpi=300)
plt.title('The change of best fitness',fontdict='weight':'normal','size': 30)
x=range(1,101,1)
plt.plot(x,his_bestfit,color="red",label="GWO",linewidth=3.0, linestyle="-")
plt.tick_params(labelsize=25)
plt.xlim(0,101)
plt.yscale("log")
plt.xlabel("Epoch",fontdict='weight':'normal','size': 30)
plt.ylabel("Fitness value",fontdict='weight':'normal','size': 30)
plt.xticks(range(0,101,10))
plt.legend(loc="upper right",prop='size':20)
plt.savefig("GWO.png")
plt.show()
图中横轴为迭代次数,纵轴为最优适应度值。
参考源码
以上是关于Python实现GWO智能灰狼优化算法优化Catboost分类模型(CatBoostClassifier算法)项目实战的主要内容,如果未能解决你的问题,请参考以下文章
Python实现GWO智能灰狼优化算法优化Catboost分类模型(CatBoostClassifier算法)项目实战
Python实现GWO智能灰狼优化算法优化LightGBM回归模型(LGBMRegressor算法)项目实战
优化算法灰狼优化算法(GWO)含Matlab源码 1305期