计算机架构如何计算 CPU 时间
Posted 柠檬叶子C
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了计算机架构如何计算 CPU 时间相关的知识,希望对你有一定的参考价值。

目录
0x00 响应时间和吞吐量(Response Time and Throughput)
0x01 相对性能(Relative Performance)
0x02 执行时间测量(Measuring Execution Time)
0x06 性能摘要(Performance Summary)
0x00 响应时间和吞吐量(Response Time and Throughput)
响应时间 (Response time):完成任务所需的时间
吞吐量 (Throughput):每个单位时间内完成的总工作量 (比如: tasks/transactions... per hours)
存在多种因素可以对响应时间和吞吐量造成影响,包括但不限于:
- 处理能力:通过升级到更快的处理器或添加更多处理器,可以减少响应时间并增加吞吐量。这是因为更快或更强大的处理器可以在更短的时间内处理更多的任务。
- 系统负载:如果系统过载,处理过多的任务或用户,将会对响应时间和吞吐量产生负面影响。这是因为系统可能无法处理工作负荷,导致响应时间更长,吞吐量降低。
- 网络延迟:如果网络延迟较高,响应时间和吞吐量可能会受到影响。这是因为数据传输需要更长的时间,从而导致响应时间变长和吞吐量降低。
换更快的处理器?添加更多的处理器?本章我们更关注的是 响应时间 (Response time) 。
0x01 相对性能(Relative Performance)
📚 定义:性能 = 1 / 执行时间:
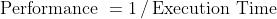
 比
比  快
快  倍:
倍:
💭 举个例子:运行程序所需时间,在 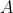 机器上为 10s,在
机器上为 10s,在 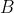 机器上为 15s
机器上为 15s
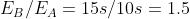
因此, 比 快 1.5 倍。
0x02 执行时间测量(Measuring Execution Time)
执行时间测量 (Measuring Execution Time) 指的是在计算机程序中测量代码执行所需的时间。这通常是通过在代码开始和结束时记录时间戳来实现的,然后计算时间戳之间的差异来计算程序执行所需的时间。
执行时间测量通常是性能优化和调试代码的重要工具。通过测量程序中不同部分的执行时间,开发人员可以确定哪些部分需要进行优化,以使程序更加高效。
在实际应用中,执行时间测量可以使用多种不同的技术和工具来实现,例如内置的计时器函数、性能分析工具、代码覆盖率工具等等。不同的方法适用于不同的场景和需求。
总的反应时间 (Elapsed time):
- 总响应时间,包括所有方面 (Processing, I/O, OS overhead, idle time)
- 确定系统性能
CPU 时间 (CPU time):
- 用于处理给定作业的时间 (Discounts I/O time, other jobs’ shares)
- 包括用户 CPU 时间和系统 CPU 时间
- 不同的程序受 CPU 和系统性能的影响不同
0x03 CPU 时钟(Clocking)
CPU Clocking(CPU 时钟)指的是计算机 CPU 内部的时钟系统。这个时钟系统会以固定的速率来发出脉冲信号,这些信号会让 CPU 的不同部件在每个时钟周期内执行相应的操作。
数字硬件的操作受到固定速率时钟的控制:
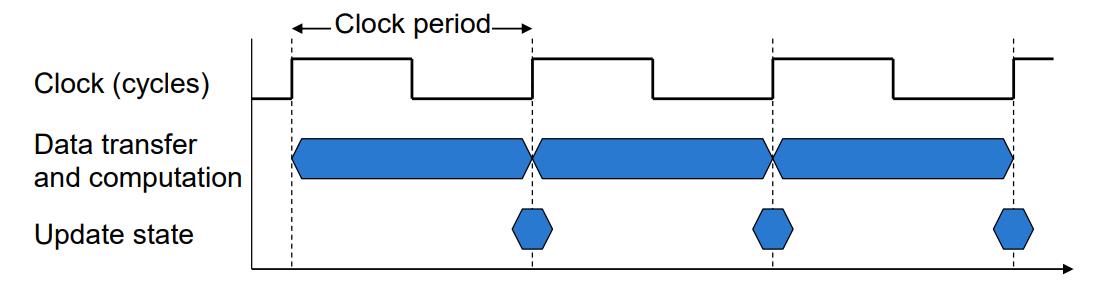
时钟周期 (Clock period):时钟信号一个完整的循环所需要的时间。

时钟频率 (Clock Rate):每秒钟时钟信号产生的周期数。

0x04 计算CPU时间(T=CC/CR)
性能可以通过减少时钟周期数、增加时钟速度来改善。
硬件设计人员通常需要在时钟速度和时钟周期数量之间进行权衡。
🔺 CPU Time 计算公式如下:
CPU 时间 = CPU 时钟周期数 × 时钟周期
= CPU 时钟周期数 ÷ 时钟频率

📜 简化记忆:
- 求 CPU 时间:
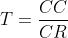 ,
, 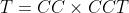
- 求时钟频率 (Clock Rate) :
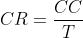
- 求时钟周期 (Clock Cycle) :
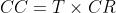
💭 举个例子:
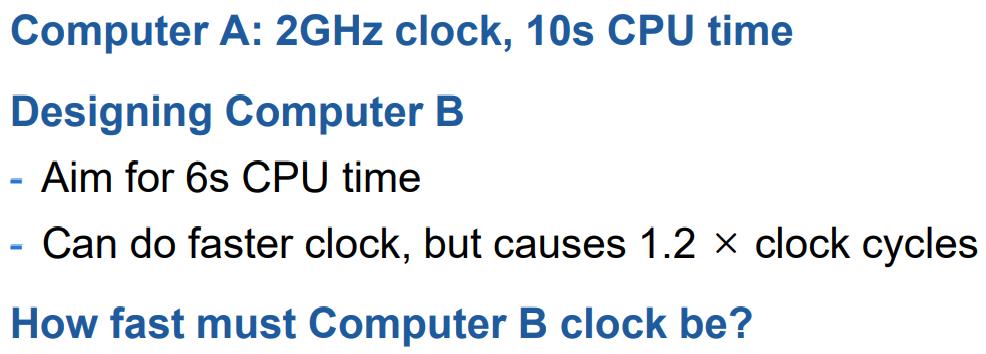
计算机 A 有 2GHz 的时钟, 10s 的CPU 时间,请设计计算机 B,目标达到 10s 的 CPU 时间。可以使用更快的时钟,但会导致 1.2 × 时钟周期,问计算机 B 的时钟应该多快?
💡 解答:已知 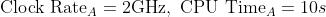 ,计算
,计算 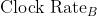
* 根据上述公式 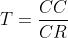 ,那么 ,
,那么 ,
根据题意,使用更快时钟导致  倍
倍 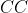 ,并且目标 CPU 时间
,并且目标 CPU 时间 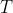 为
为 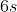 ,可列出公式:
,可列出公式:

此时我们需要计算 A 的时钟周期,根据公式 ,那么时钟周期 :
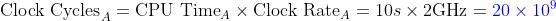
此时我们已经得到了 
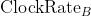 :
:
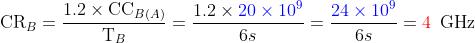
0x05 指令计数 IC 和 每条指令所需的时钟周期数 CPI
 (Instruction Count),指的是 指令计数。
(Instruction Count),指的是 指令计数。
 (Cycle Per Instrution),指的是 每条指令所需的时钟周期数。即 平均执行周期数
(Cycle Per Instrution),指的是 每条指令所需的时钟周期数。即 平均执行周期数
是指在一个程序中,每个时钟周期所执行的平均指令数。这两个概念都是计算机性能评估中的关键指标。通过减少指令计数或降低 CPI,可以提高计算机系统的性能。

📃 简化记忆:
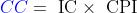

Execution time = (Instruction count * CPI) / Clock rate
程序的指令计数是由程序本身、指令集架构 (ISA) 和编译器所决定的。每个指令的平均时钟周期数取决于CPU硬件。如果不同的指令具有不同的CPI,则平均 CPI 受指令组合的影响。
💭 CPI 计算例子:

计算机 A 的周期时间 = 250ps,CPI = 2.0,计算机 B 的周期时间 为 500ps,CPI = 1.2
ISA 相同,哪台计算机更快?快多少?
💡 题解:根据题意得知: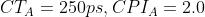 ,
,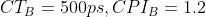
既然要比谁更快,那么我们分别计算出 A, B 的 CPU Time:
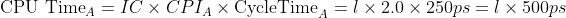

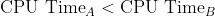 ,因此 A 速度更快。
,因此 A 速度更快。
下面计算快多少:
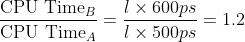
0x06 关于CPI 的更多细节
如果不同的指令类别需要不同的时钟周期数:

加权平均 CPI (Avg):
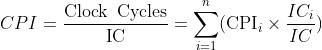
💭 例子:Alternative compiled code sequences using instructions in classes A, B, C:

💡 解读:Sequence 1 中 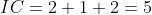
根据公式:
再根据图表给出的 IC, CPI 即可计算出 Clock Cycles:

然后通过公式计算平均:
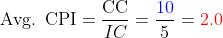
0x07 性能摘要(Performance Summary)
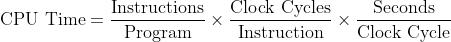
性能摘要 (Performance Summary) 是指对计算机系统、软件或应用程序性能进行评估、分析和总结的过程。在性能摘要中,可以考虑多种性能指标,如执行时间、吞吐量、响应时间、负载等。通常,性能摘要的目的是发现瓶颈、评估系统的优化潜力、指导系统设计和优化、以及进行比较评估等。在实践中,性能摘要是计算机系统开发和维护中非常重要的一环,可以帮助提高系统的性能、可靠性和稳定性。
性能取决于 算法 (影响 IC,可能影响 CPI)、编程语言 (影响 IC,CPI)、编译器(影响 IC,CPI)、指令集架构(影响 IC,CPI,Tc)。
🔺 计算公式总结:
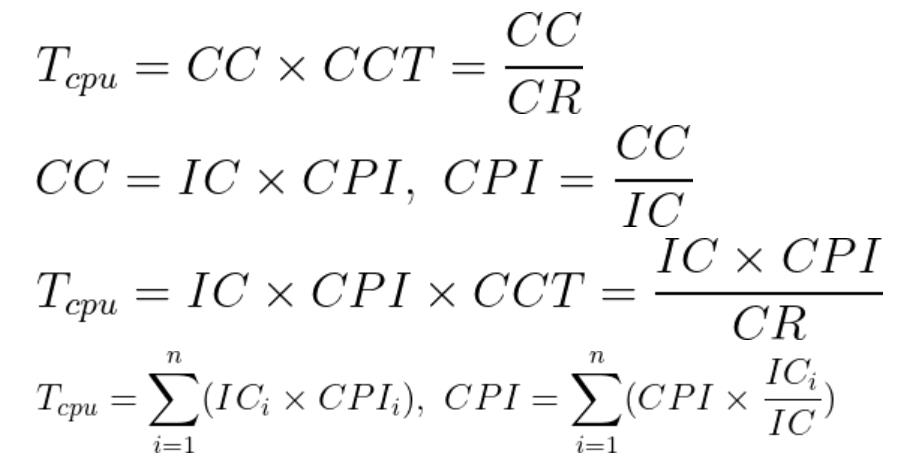

📌 [ 笔者 ] 王亦优
📃 [ 更新 ] 2022.3.
❌ [ 勘误 ] /* 暂无 */
📜 [ 声明 ] 由于作者水平有限,本文有错误和不准确之处在所难免,
本人也很想知道这些错误,恳望读者批评指正!| 📜 参考资料 C++reference[EB/OL]. []. http://www.cplusplus.com/reference/. Microsoft. MSDN(Microsoft Developer Network)[EB/OL]. []. . 百度百科[EB/OL]. []. https://baike.baidu.com/. |
x86架构初探之8086
x8086
计算机的组成
下图是组成计算机的硬件们的抽象图。
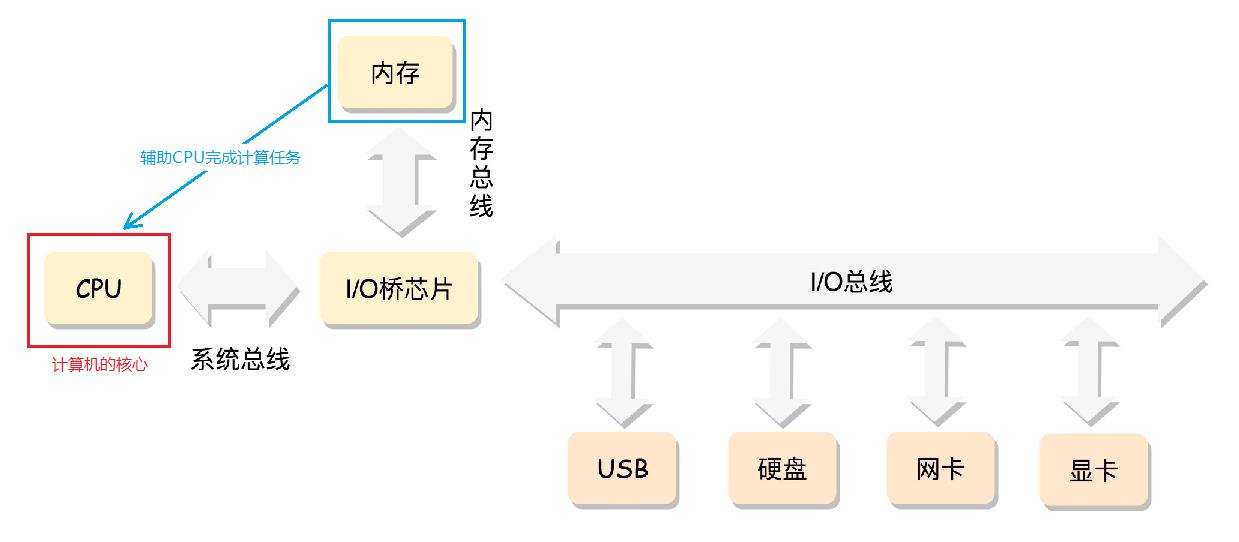
- CPU:计算机的最核心的硬件,负责执行(计算)程序。所有硬件设备都围绕它工作。
- 总线:主板上密密麻麻的集成电路,负责CPU和其它设备的高速通信。
- 内存:辅助计算机完成计算任务。因为复杂的任务需要复杂的计算步骤,复杂的计算步骤产生的计算结果的量是CPU寄存器无法容下的,内存负责帮助CPU存储超出CPU寄存器容量的那些中间结果。
- 其它设备:总线上还有一些其他设备,例如显卡会连接显示器、磁盘控制器会连接硬盘、USB 控制器会连接键盘和鼠标等等。
CPU的组成
CPU 其实也不是单纯的一块,它包括三个部分,运算单元、数据单元和控制单元。
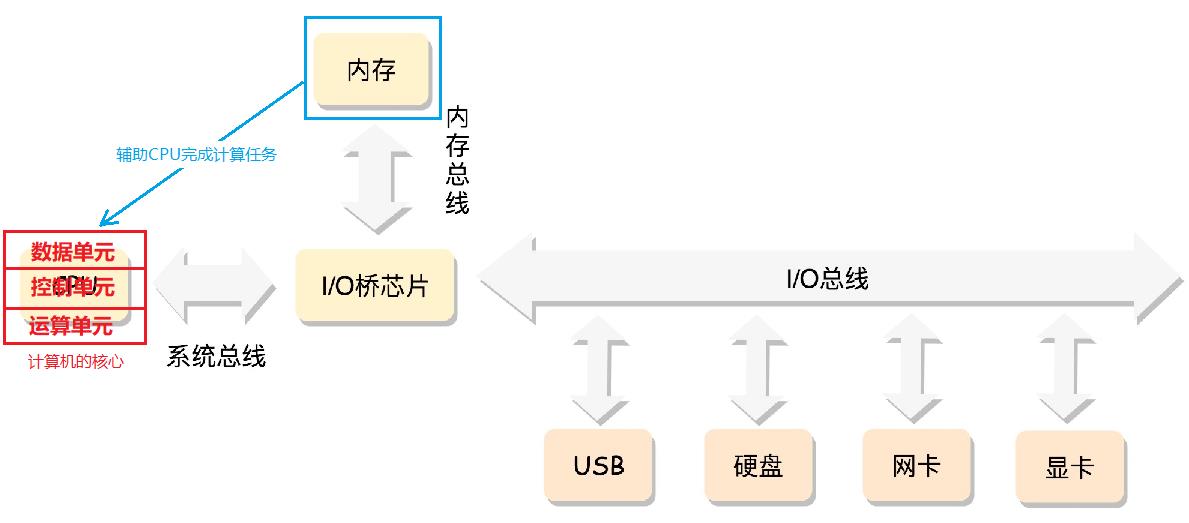
- 运算单元:负责运算,例如做加法、做位移等。但是,它不知道应该算哪些数据,运算结果应该放在哪里。运算单元计算的数据如果每次都要经过总线,到内存里面现拿,这样就太慢了,所以就有了
- 数据单元:负责暂时存放数据和运算结果。数据单元包括 CPU 内部的缓存和寄存器组,空间很小,但是速度飞快。
- 控制单元:负责到底做什么运算。是一个统一的指挥中心,它的寄存器可以获得下一条指令,然后执行这条指令。这个指令会指导运算单元取出数据单元中的某几个数据,计算出个结果,然后放在数据单元的某个地方。
CPU和内存的配合
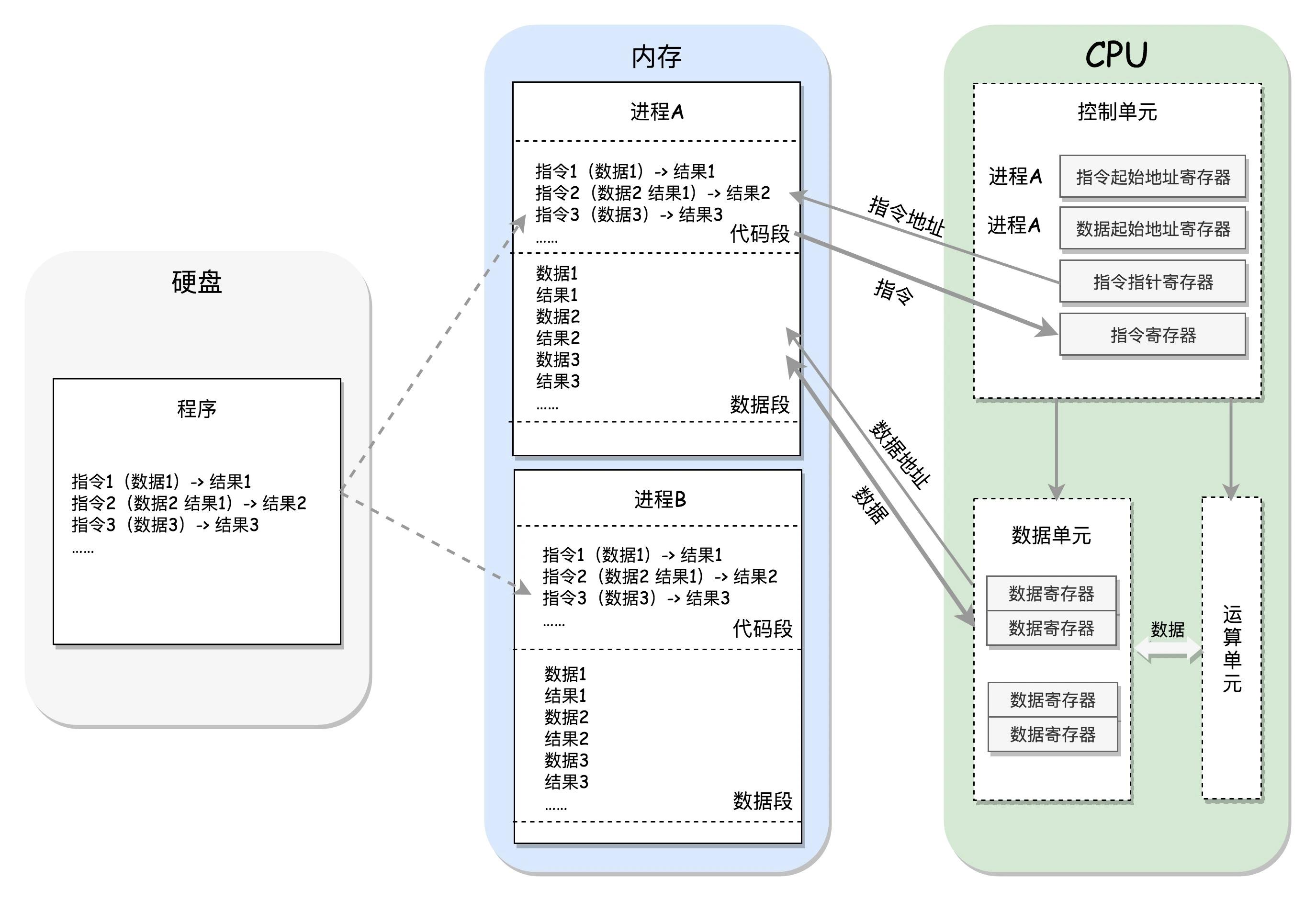
首先,要明确的是,
- 每个进程都会对应一个程序,程序是以二进制的形式存放咋硬盘上的。
- 进程一旦运行,就会有自己的独立的内存空间。例如:图中的进程A和B的内存空间就是互相隔离且不连续。
- 进程的内存空间会分为代码段和数据段,这是相对抽象的划分方法,实际上要更复杂。
- 指令分为两部分。前面一部分是操作数,代表做什么运算;后面一部分是操作的数据。
- 指令指针寄存器:为于CPU控制单元,它里面存放的是下一条指令在内存中的地址。
之后,我们看一下CPU和内存的交互过程,
- 首先,位于CPU控制单元的指令指针寄存器会指引控制单元持续不断地从代码段中读取指令,并把指令存放到位于控制单元中的指令寄存器。
- 之后,指令的第一部分交给运算单元,第二部分交给数据单元。
- 在之后,数据单元根据数据地址将数据段中的数据读到数据单元的数据寄存器中,此时数据就可以参与运算单元的运算了。
- 运算完成后,产生的结果会暂存在数据单元的数据寄存器中。
- 最终,会有指令将数据写回内存中的数据段。
CPU如何区分要执行的进程
上述的过程是针对一个进程而言的,那多进程时候CPU又是如何区分的呢?
CPU控制单元中有两个寄存器是专门区分当前应该执行那个进程的,它们分别是指令起始地址寄存器和数据起始地址寄存器。
- 指令起始地址寄存器:用来指向代码段的起始地址。
- 数据起始地址寄存器:用来指向数据段的起始地址。
当两个寄存器的指向都属于同一进程的内存空间,那么当前执行的就是这一进程的指令。
总线——CPU与内存交互的通道
CPU与内存的交互主要就两类数据,一类是地址,也就是我想拿内存中哪个位置的数据;一类是数据,真正的数据。它们通过不同类型的总线进行传输,分别是地址总线与数据总线。
- 地址总线:位数决定了能访问的地址范围到底有多广。例如只有两位,那 CPU 就只能认 00,01,10,11 四个位置,超过四个位置,就区分不出来了。位数越多,能够访问的位置就越多,能管理的内存的范围也就越广。
- 数据总线:位数决定了一次能拿多少个数据进来。例如只有两位,那 CPU 一次只能从内存拿两位数。要想拿八位,就要拿四次。位数越多,一次拿的数据就越多,访问速度也就越快。
X86架构
16位模型——8086处理器
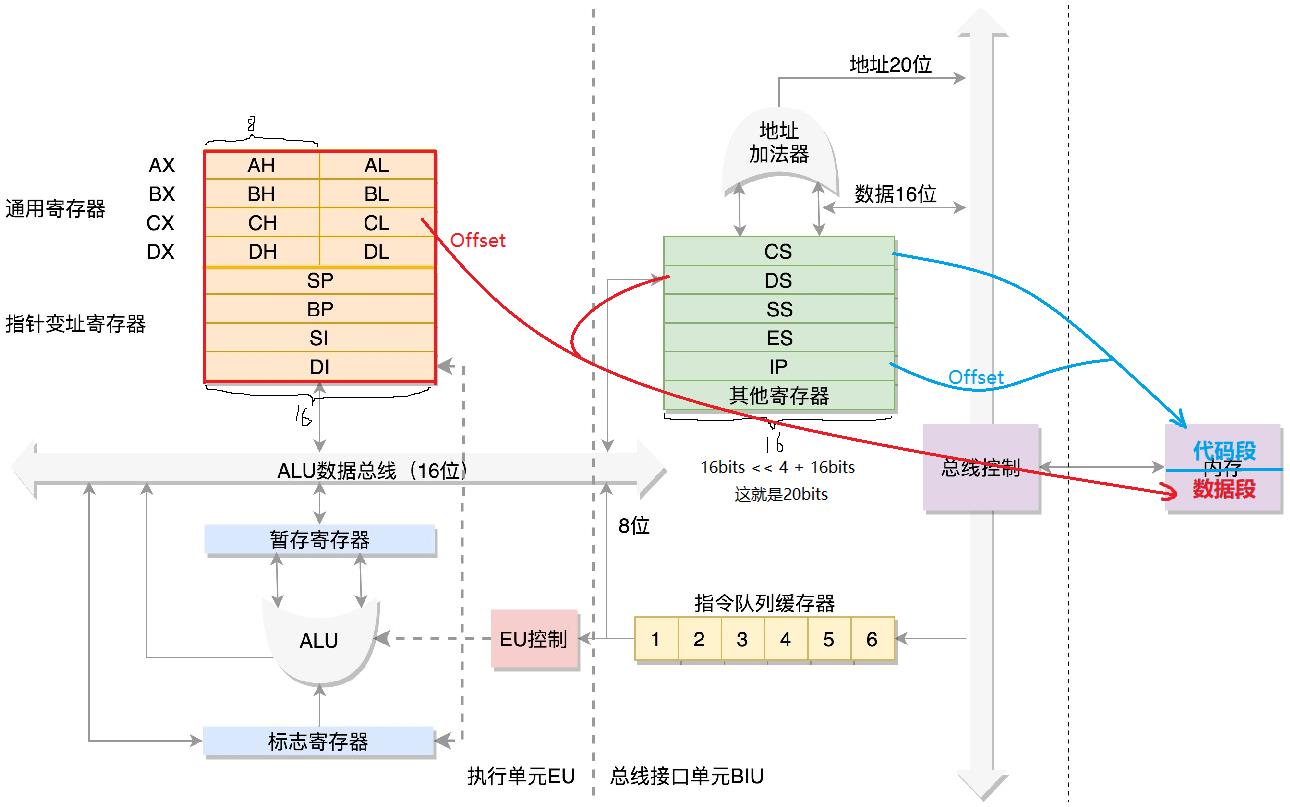
控制单元
先看一下控制单元的寄存器们:
- IP寄存器:指令指针寄存器。指向代码段中下一条指令的位置上。CPU 会根据它来不断地将指令从内存的代码段中,加载到 CPU 的指令队列中,然后交给运算单元去执行。
- CS寄存器:代码段寄存器,就是前一个图中的指令起始地址寄存器。
- DS寄存器:数据段寄存器,就是前一个图中的数据起始地址寄存器。
- SS寄存器:堆栈段寄存器,存放堆栈段的起始地址。
- ES寄存器
- 其它寄存器
数据单元
先看一下控制单元的寄存器们:
- 通用寄存器:8个16位,位数取决于机器字长。分别是 AX、BX、CX、DX、SP、BP、SI、DI。这些寄存器主要用于在计算过程中暂存数据。
- AX、BX、CX、DX 可以分成两个 8 位的寄存器来使用,分别是 AH、AL、BH、BL、CH、CL、DH、DL,其中 H 就是 High(高位),L 就是 Low(低位)的意思。
CPU如何从内存中取数据
数据总线只有16位,即地址也是16位。而地址总线有20位,所以如何寻址呢?CS、DS对应的是起始位置,起始位置只能标定开头,想要确定段中的具体位置还需要段内位置,此之称为偏移量。计算公式为:
段内具体的位置 = 起始位置 << 4 + 偏移量。
代码段的偏移量在IP寄存器中,数据段的偏移量在通用寄存器中。另外,加法并不会导致数据位数溢出,因为,偏移量的范围是根据段的起始地址和段的结束地址而定的,并不是像多大就能多大。比如:段起始地址是FFFF0,段结束地址最大为FFFFF,偏移量的范围是0000~000F,偏移量根本不可能是FFFF。
这是一种直接的方法,从段寄存器这届拿取段起始地址。
32位模型
x86架构是一个兼容结构,32位的设计也要兼顾16位架构的设计。
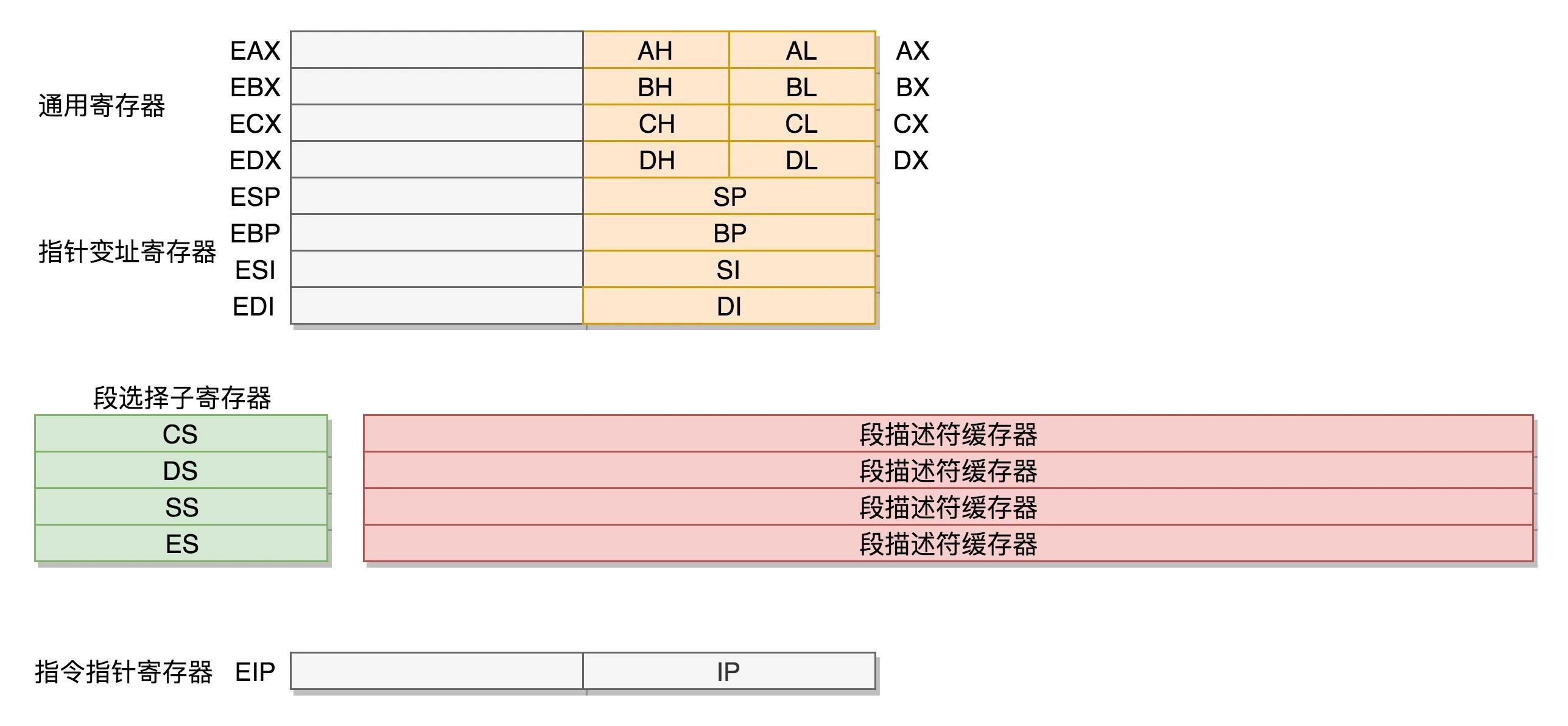
数据单元
- 通用寄存器:将原先的16位寄存器扩展到32位,但是依然保留8位和16位的组成。
控制单元
- IP寄存器:16位扩展到32位。
控制单元和原来16位设计不兼容的地方
因为原来的模式(16位的设计)其实有点不伦不类,因为它没有使用 16 位的数据作为一个段的起始地址,也没有按 8 位或者 16 位扩展的形式,而是根据当时的硬件,弄了一个不上不下的 20 位的地址。这样每次都要左移四位,也就意味着段的起始地址不能是任何一个地方,只是能整除 16 的地方。
如何解决呢?另起炉灶!
- 段描述符缓存器:真正的段起始地址。
- 某种表格:由段描述符组成,表格每一项是段描述符。
- CS、DS、SS、ES寄存器:仍然是16位,存表格中的某一项。
- 段选择子寄存器:CS、DS、SS、ES寄存器组成。
CPU如何从内存中取数据

段选择自寄存器先从表格中选取一项,再从这项中拿到段起始地址。段起始地址最开始是在内存中,CPU为了更快的获得地址,会把段起始地址放入CPU的缓存中。
这是一种间接的方法。
CPU的实模式与保护模式
| CPU模式 | 区分方式 | 所处时间 | 备注 |
|---|---|---|---|
| 实模式 | 从段寄存器中直接拿取段起始地址 | 系统刚启动时 | 此时是兼容16位的 |
| 保护模式 | 间接地先从段寄存器找到表格中的一项,再从表格中的一项中拿到段起始地址 | 需要更多内存时时 | 遵循一定的规则,进行一系列的操作地切换 |
以上是关于计算机架构如何计算 CPU 时间的主要内容,如果未能解决你的问题,请参考以下文章
系统架构设计师计算机组成与体系结构 ① ( 计算机组成 | CPU | 存储器 | 总线 | IO 外设 | CPU 组成 | 运算器 | 控制器 )