x86架构初探之8086
Posted CS生
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了x86架构初探之8086相关的知识,希望对你有一定的参考价值。
x8086
计算机的组成
下图是组成计算机的硬件们的抽象图。
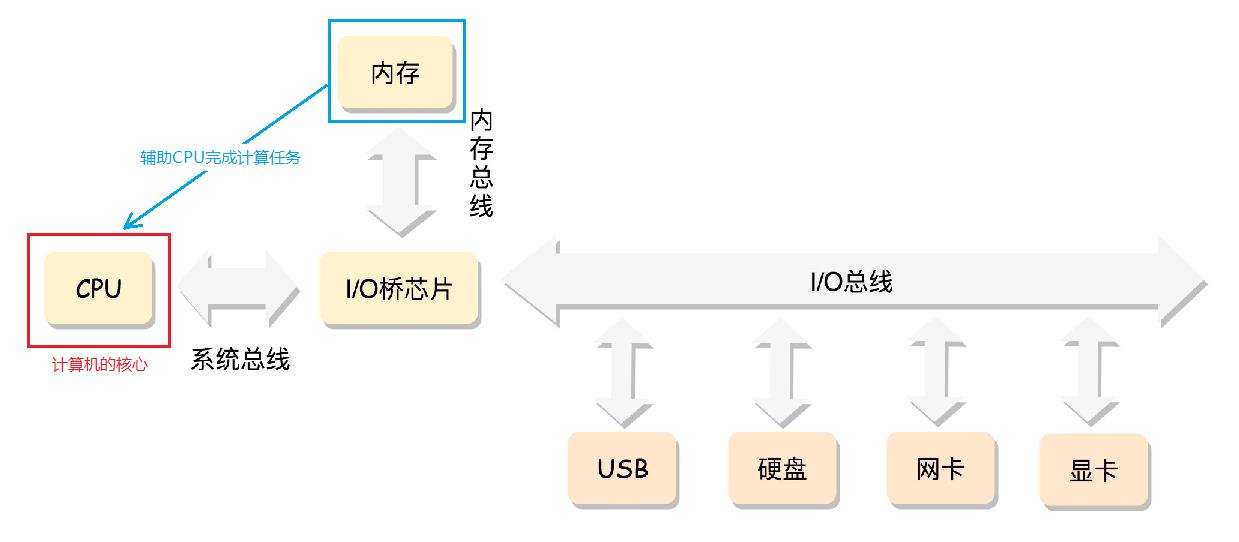
- CPU:计算机的最核心的硬件,负责执行(计算)程序。所有硬件设备都围绕它工作。
- 总线:主板上密密麻麻的集成电路,负责CPU和其它设备的高速通信。
- 内存:辅助计算机完成计算任务。因为复杂的任务需要复杂的计算步骤,复杂的计算步骤产生的计算结果的量是CPU寄存器无法容下的,内存负责帮助CPU存储超出CPU寄存器容量的那些中间结果。
- 其它设备:总线上还有一些其他设备,例如显卡会连接显示器、磁盘控制器会连接硬盘、USB 控制器会连接键盘和鼠标等等。
CPU的组成
CPU 其实也不是单纯的一块,它包括三个部分,运算单元、数据单元和控制单元。
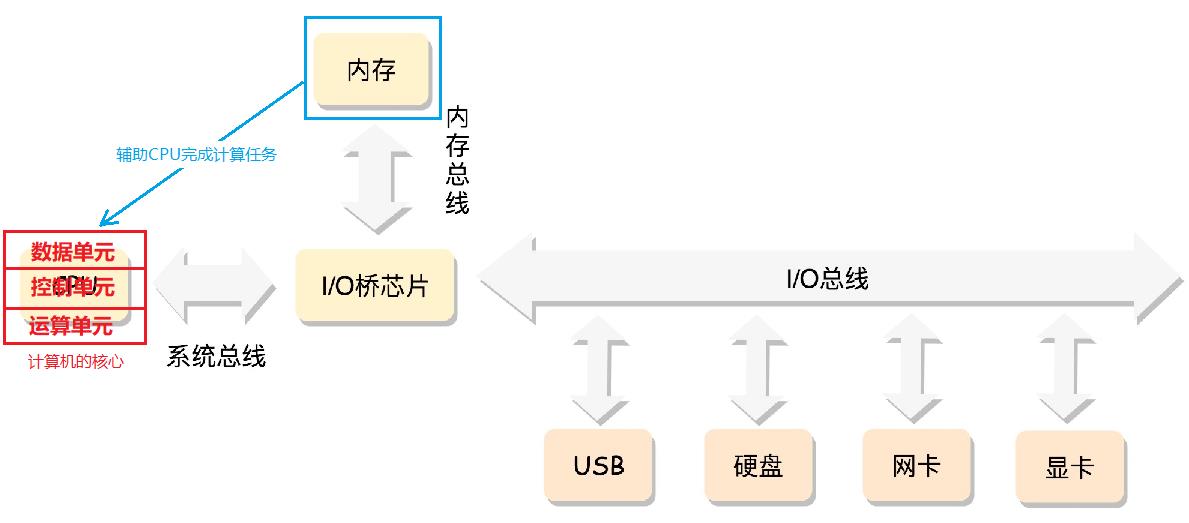
- 运算单元:负责运算,例如做加法、做位移等。但是,它不知道应该算哪些数据,运算结果应该放在哪里。运算单元计算的数据如果每次都要经过总线,到内存里面现拿,这样就太慢了,所以就有了
- 数据单元:负责暂时存放数据和运算结果。数据单元包括 CPU 内部的缓存和寄存器组,空间很小,但是速度飞快。
- 控制单元:负责到底做什么运算。是一个统一的指挥中心,它的寄存器可以获得下一条指令,然后执行这条指令。这个指令会指导运算单元取出数据单元中的某几个数据,计算出个结果,然后放在数据单元的某个地方。
CPU和内存的配合
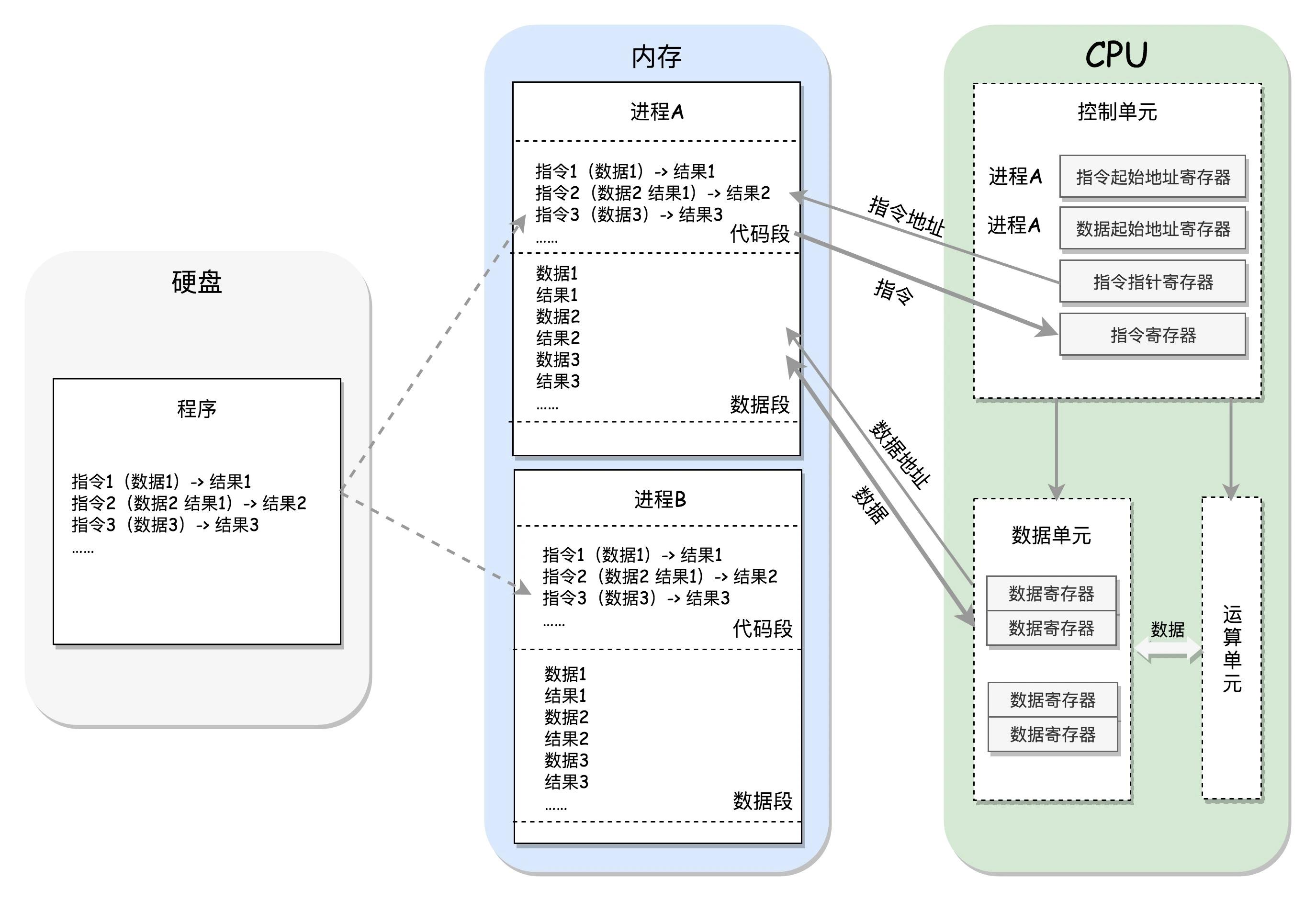
首先,要明确的是,
- 每个进程都会对应一个程序,程序是以二进制的形式存放咋硬盘上的。
- 进程一旦运行,就会有自己的独立的内存空间。例如:图中的进程A和B的内存空间就是互相隔离且不连续。
- 进程的内存空间会分为代码段和数据段,这是相对抽象的划分方法,实际上要更复杂。
- 指令分为两部分。前面一部分是操作数,代表做什么运算;后面一部分是操作的数据。
- 指令指针寄存器:为于CPU控制单元,它里面存放的是下一条指令在内存中的地址。
之后,我们看一下CPU和内存的交互过程,
- 首先,位于CPU控制单元的指令指针寄存器会指引控制单元持续不断地从代码段中读取指令,并把指令存放到位于控制单元中的指令寄存器。
- 之后,指令的第一部分交给运算单元,第二部分交给数据单元。
- 在之后,数据单元根据数据地址将数据段中的数据读到数据单元的数据寄存器中,此时数据就可以参与运算单元的运算了。
- 运算完成后,产生的结果会暂存在数据单元的数据寄存器中。
- 最终,会有指令将数据写回内存中的数据段。
CPU如何区分要执行的进程
上述的过程是针对一个进程而言的,那多进程时候CPU又是如何区分的呢?
CPU控制单元中有两个寄存器是专门区分当前应该执行那个进程的,它们分别是指令起始地址寄存器和数据起始地址寄存器。
- 指令起始地址寄存器:用来指向代码段的起始地址。
- 数据起始地址寄存器:用来指向数据段的起始地址。
当两个寄存器的指向都属于同一进程的内存空间,那么当前执行的就是这一进程的指令。
总线——CPU与内存交互的通道
CPU与内存的交互主要就两类数据,一类是地址,也就是我想拿内存中哪个位置的数据;一类是数据,真正的数据。它们通过不同类型的总线进行传输,分别是地址总线与数据总线。
- 地址总线:位数决定了能访问的地址范围到底有多广。例如只有两位,那 CPU 就只能认 00,01,10,11 四个位置,超过四个位置,就区分不出来了。位数越多,能够访问的位置就越多,能管理的内存的范围也就越广。
- 数据总线:位数决定了一次能拿多少个数据进来。例如只有两位,那 CPU 一次只能从内存拿两位数。要想拿八位,就要拿四次。位数越多,一次拿的数据就越多,访问速度也就越快。
X86架构
16位模型——8086处理器
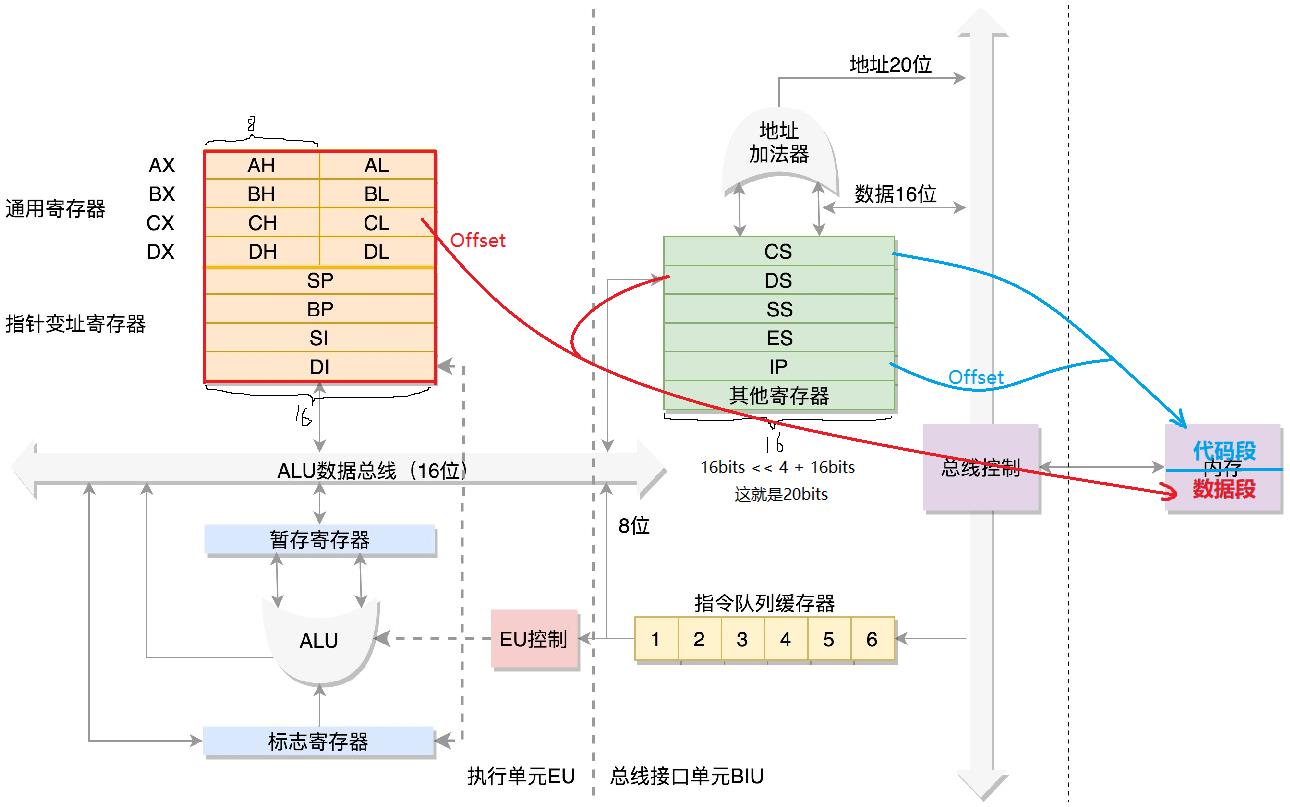
控制单元
先看一下控制单元的寄存器们:
- IP寄存器:指令指针寄存器。指向代码段中下一条指令的位置上。CPU 会根据它来不断地将指令从内存的代码段中,加载到 CPU 的指令队列中,然后交给运算单元去执行。
- CS寄存器:代码段寄存器,就是前一个图中的指令起始地址寄存器。
- DS寄存器:数据段寄存器,就是前一个图中的数据起始地址寄存器。
- SS寄存器:堆栈段寄存器,存放堆栈段的起始地址。
- ES寄存器
- 其它寄存器
数据单元
先看一下控制单元的寄存器们:
- 通用寄存器:8个16位,位数取决于机器字长。分别是 AX、BX、CX、DX、SP、BP、SI、DI。这些寄存器主要用于在计算过程中暂存数据。
- AX、BX、CX、DX 可以分成两个 8 位的寄存器来使用,分别是 AH、AL、BH、BL、CH、CL、DH、DL,其中 H 就是 High(高位),L 就是 Low(低位)的意思。
CPU如何从内存中取数据
数据总线只有16位,即地址也是16位。而地址总线有20位,所以如何寻址呢?CS、DS对应的是起始位置,起始位置只能标定开头,想要确定段中的具体位置还需要段内位置,此之称为偏移量。计算公式为:
段内具体的位置 = 起始位置 << 4 + 偏移量。
代码段的偏移量在IP寄存器中,数据段的偏移量在通用寄存器中。另外,加法并不会导致数据位数溢出,因为,偏移量的范围是根据段的起始地址和段的结束地址而定的,并不是像多大就能多大。比如:段起始地址是FFFF0,段结束地址最大为FFFFF,偏移量的范围是0000~000F,偏移量根本不可能是FFFF。
这是一种直接的方法,从段寄存器这届拿取段起始地址。
32位模型
x86架构是一个兼容结构,32位的设计也要兼顾16位架构的设计。
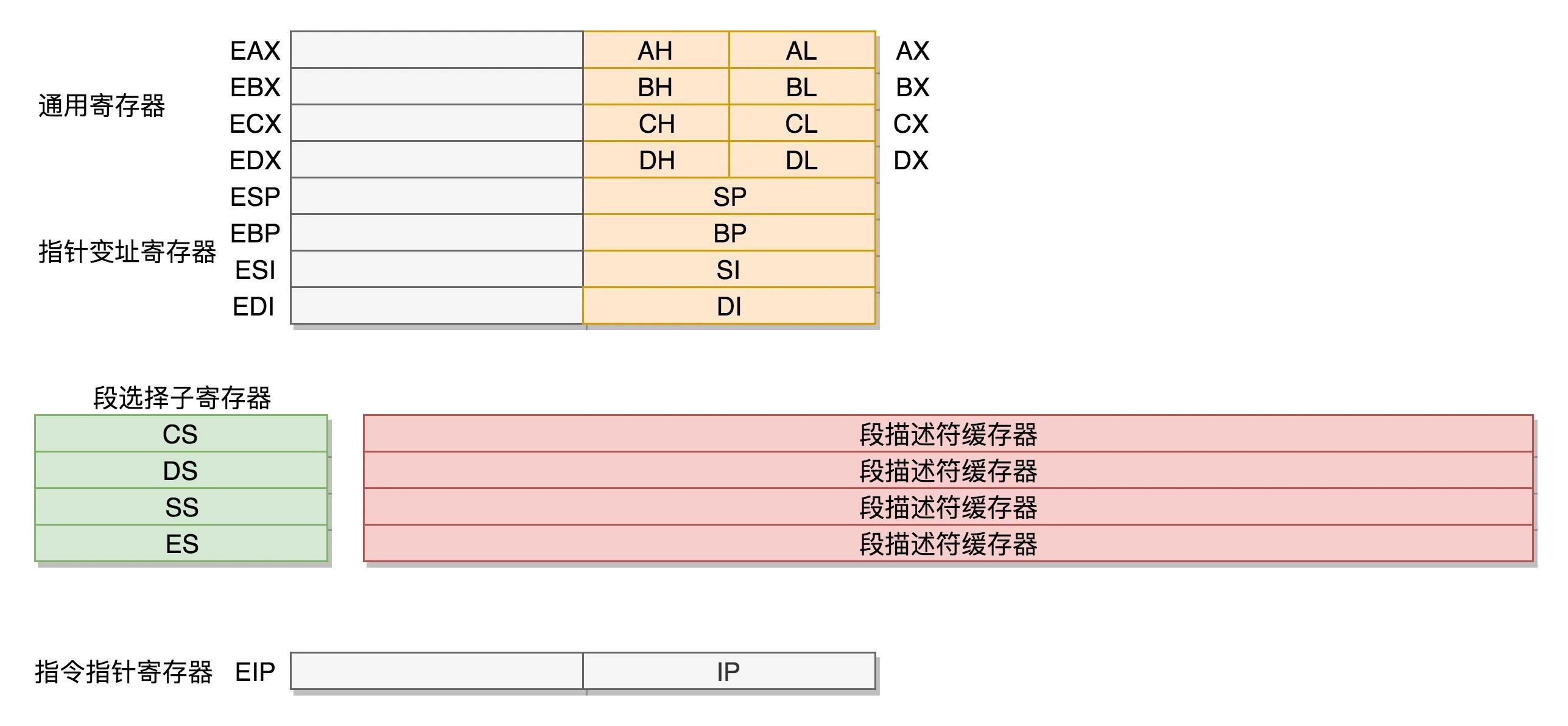
数据单元
- 通用寄存器:将原先的16位寄存器扩展到32位,但是依然保留8位和16位的组成。
控制单元
- IP寄存器:16位扩展到32位。
控制单元和原来16位设计不兼容的地方
因为原来的模式(16位的设计)其实有点不伦不类,因为它没有使用 16 位的数据作为一个段的起始地址,也没有按 8 位或者 16 位扩展的形式,而是根据当时的硬件,弄了一个不上不下的 20 位的地址。这样每次都要左移四位,也就意味着段的起始地址不能是任何一个地方,只是能整除 16 的地方。
如何解决呢?另起炉灶!
- 段描述符缓存器:真正的段起始地址。
- 某种表格:由段描述符组成,表格每一项是段描述符。
- CS、DS、SS、ES寄存器:仍然是16位,存表格中的某一项。
- 段选择子寄存器:CS、DS、SS、ES寄存器组成。
CPU如何从内存中取数据

段选择自寄存器先从表格中选取一项,再从这项中拿到段起始地址。段起始地址最开始是在内存中,CPU为了更快的获得地址,会把段起始地址放入CPU的缓存中。
这是一种间接的方法。
CPU的实模式与保护模式
| CPU模式 | 区分方式 | 所处时间 | 备注 |
|---|---|---|---|
| 实模式 | 从段寄存器中直接拿取段起始地址 | 系统刚启动时 | 此时是兼容16位的 |
| 保护模式 | 间接地先从段寄存器找到表格中的一项,再从表格中的一项中拿到段起始地址 | 需要更多内存时时 | 遵循一定的规则,进行一系列的操作地切换 |
Lucene初探之总体架构
从总体上来说,Lucene的可以被概括为三点:
- 高效、可扩展的全文检索库;
- 基于Java实现;
- 支持对纯文本文件进行索引可搜索;
Lucene的工作流程和架构如下所示:
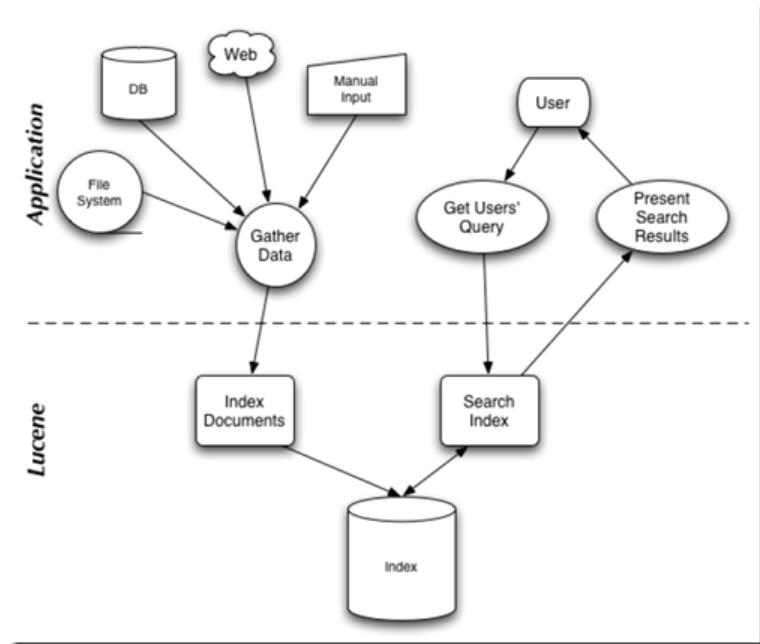
通过该图片,我们可以看出,Lucene的工作流程可以被分为两个部分:索引、搜索。
我们可以将这些过程进行抽象组件化:
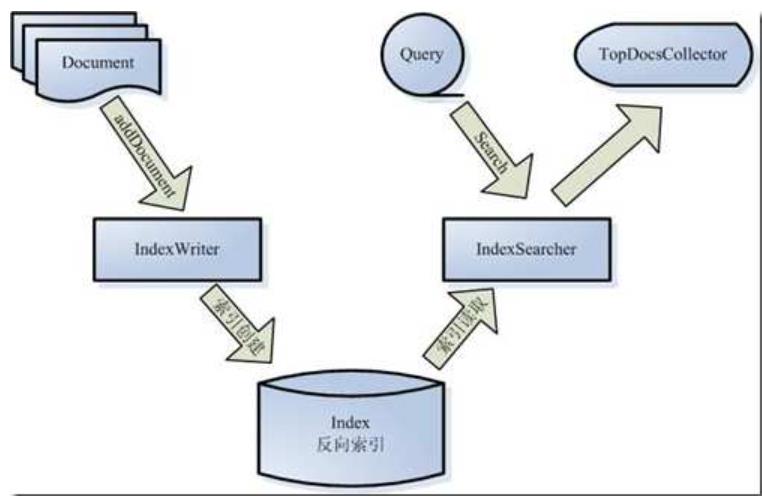
通过上下两个图片的对比,基本上可以直观地了解各个组件的工作:
- Document代表被索引的各个分散的文档;
- IndexWirter将Document写入索引中,这个过程也就是创建索引的过程;
- 当用户有查询请求时,其查询条件为Query,Query被传递给IndexSearch;
- IndexSearch对Index索引进行查询,并得到符合Query条件的文档集合;
- 文档集合在IndexSearch中进一步进行权重和打分计算;
- 按照分值排序后的查询结果被展示给用户;
那么这些不同的组件是如何被使用的呢?
我们来举一个例子,通过这个例子来看一下如何通过对Lucene API的调用来实现索引创建和搜索查询。

通过这个图片,我们可以清晰地看到通过代码去实现索引和搜索的过程主要有以下几个步骤:
索引过程:
- 声明一个Document对象,将要索引的文件内容和文件路径通过add方法添加进入对象中;
- 创建一个IndexWriter,初始化好索引的路径,分词器等信息;
- IndexWriter调用addDocument方法将申明好的Document对象写入到索引中;
- 关闭IndexWriter;
搜索过程:
- 创建一个IndexReader对象,打开索引并读入内存中;
- 创建一个IndexSearcher对象;
- 创建一个Analyzer分词器;
- 创建一个QueryParser对象,对查询域进行词法分析和语法分析并处理;
- 使用相同的QueryParser对查询语句进行分析,行程查询语法数;
- 创建一个TopScoreDocCollector打分器;
- IndexSearcher对象调用search,对索引进行query条件查询并通过打分器打分;
- 将得到的结果返回给用户;
上图是对Lucene的简单demo应用,但是Lucene的真正的实现远不止看起来这么简单,如果我们深入Lucene源码的话,我们会发现Lucene的内部实现包之间的关系非常复杂。
下面是的一些内部模块关系图:


注:上图来自http://www.slideshare.net/Manishkumar1192/search-engine-capabilities-apache-solrlucene
简单地了解了Lucene的整体架构之后,我们就可以正式开始进入Lucene的内部世界去探秘啦!
以上是关于x86架构初探之8086的主要内容,如果未能解决你的问题,请参考以下文章