视频插帧XVFI: eXtreme Video Frame Interpolation
Posted 氢氧化Na
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了视频插帧XVFI: eXtreme Video Frame Interpolation相关的知识,希望对你有一定的参考价值。
XVFI: eXtreme Video Frame Interpolation
原文地址:https://arxiv.org/pdf/2103.16206.pdf
Github 地址:https://github.com/JihyongOh/XVFI
Abstract
在这篇文章中,我们首先向研究界展示了一个数据集( X4K1000FPS ),该数据集包含 4K 分辨率、1000 fps 帧率的,具有极端运动情况的视频,将其用于视频插帧( VFI )。我们还提出了一个极端的视频插帧网络,叫做 XVFI-Net,该网络首次处理了大运动 4K 视频的插帧问题。
XVFI-Net 基于一个递归的多尺度共享结构,该结构由两个级联模块所组成,这两个模块分别用于两个输入帧之间的双向光流学习( BiOF-I ),以及目标帧到输入帧的双向光流学习( BiOF-T )。光流通过 BiOF-T 模块中提出的互补流逆转( CFR )实现稳定地近似。模型推理期间, BiOF-I 模块能够以任意尺寸的输入开始,而 BiOF-T 模块则只能在原始输入尺寸下运行,这样就可以在加速推理的同时,保持高度精确的视频插帧性能。
大量实验结果表明,我们的 XVFI-Net 能够成功捕获到具有极端大运动和复杂纹理的物体的重要信息,而目前最先进的方法则展现出了较差的性能。此外,我们的 XVFI-Net 框架还在之前更低分辨率的基准数据集上具有相当的表现,这也体现出了我们算法的鲁棒性。
所有的源码、预训练模型,以及所提出的 X4K1000FPS 数据集,均公开发布于 https://github.com/JihyongOh/XVFI。
1. Introduction
视频插帧技术通过在给定的两个连续帧之间合成一至多个中间帧,将低帧率( LFR ) 内容转换为高帧率( HFR ) 视频,然后,高速运动的视频就能够在增加的帧率中平滑渲染,从而缓解运动抖动。因此,它被广泛用于各种实际应用中,例如自适应流媒体,新视图插值合成,帧率提升与转换,慢动作生成,以及视频修复。然而,视频插帧具有很大的挑战性,它由多种因素所导致,如遮挡,大运动,光线变化。最近,对基于深度学习的视频插帧领域的研究呈现积极态势,表现卓越。然而,他们通常只为那些现有的低帧率基准数据集做优化,这可能会导致较差的插帧性能,特别是对于那些 4K 分辨率( 4096×2160 )或是拥有更大运动、更高分辨率的视频来说。这样的 4K 视频通常包含具有极大像素位移的快速运动的帧,对于此类情况,传统的卷积神经网络无法在有限大小的感受野中有效地进行工作。
为了解决基于深度学习的视频插帧方法所拥有的上述问题,我们直接拍摄了 4K 视频来构建一个高质量的高分辨率、高帧率数据集 X4K1000FPS。图 1 展示了我们数据集中的一些示例。如图所示,我们的 4K 分辨率视频包含了极大运动和遮挡的情况。

我们还首次提出了一个极端的视频插帧模型 XVFI-Net,改模型设计旨在有效地处理如此具有挑战性的 4K 1000fps 数据集。我们的 XVFI-Net 是简单而有效的,它基于一个递归多尺度共享结构,而不是像最近视频修复的趋势那样,用可变形卷积的连续特征空间直接捕获极端运动,或是采用含有如上下文,深度,流,边缘等额外信息的大尺寸预训练网络。这个 XVFI-Net 包含两个级联模块:一个用于两个输入帧之间的双向光流学习( BiOF-I ),另一个用于目标帧到输入帧的双向光流估计( BiOF-T )。这两个模块结合多尺度损失进行训练。然而,一旦经过训练, BiOF-I 模块能从任意缩小的输入向上启动,而推理过程中, BiOF-T 模块则只能在原始输入尺寸下运行,这样计算是很有效的,并且有助于在任意目标时刻生成中间帧。从结构方面来看, 即使训练已经结束了,XVFI-Net 也可以根据输入的分辨率或是运动大小,对推理的尺度数量进行调整。我们还提出了一个新的从时间 t 到那些输入的光流估计算法,叫做互补流逆转( CFR ),它能通过互补流有效地填补空洞。为了公平比较,我们进行了大量实验,结果证明,在 X4K1000FPS 数据集上,我们的 XVFI-Net 拥有相对较小的复杂度,表现优于先前的视频插帧算法 SOTA,尤其是对于如图 2 所示的极端运动情况而言。我们还在先前的 LR-LFR 基准数据集上做了进一步实验,这也证明了 XVFI-Net 的鲁棒性。

我们的贡献可以总结为:
-
我们首次提出了一个高质量的 4K 高帧率视频数据集 X4K1000FPS,该数据集包含各种纹理,极大运动,缩放和遮挡。
-
我们提出了 CFR 互补流逆转法,从时间 t 到输入帧生成稳定的光流估计结果,提高定性和定量的性能。
-
我们所提出的 XVFI-Net 可以从任意缩放尺寸的输入向上启动,它能根据输入的分辨率或运动幅度对推理的尺度数量进行调整。
-
与先前的 SOTA 算法相比,我们的 XVFI-Net 在 X4K1000FPS 测试集上实现了最先进的性能,并且与之拉开了很大的差距,同时具有少量过滤器参数的计算效率。所有源码和提出的 X4K1000FPS 数据集均公开发布于 https://github.com/JihyongOh/XVFI。
2. Related Work
2.1. Video Frame Interpolation
大多数的视频插帧方法可以分为基于光流或内核的以及基于像素幻觉的方法。
基于流的视频插帧. Super-SloMo 首次对两个输入帧之间的预测光流进行线性组合,以近似于从目标中间帧到输入帧的流。二次视频插帧利用四个输入帧,通过二次近似来应对非线性运动的建模,当只给定两个输入帧时,视频插帧的一般化情形就受到了限制。它还提出了流逆转(投影)以实现更精准的图像变形。另一方面,DAIN 通过流投影层,根据场景的物体深度,给予重叠流向量不同的权重。然而,DAIN 同时采用了 PWC-Net 和 MegaDepth 并对它们进行了微调,这对于推导中间的高分辨率帧来说,计算量是很大的。AdaCoF 提出了一种通用的变形模块来处理复杂运动。然而,一旦训练完成,由于固定的膨胀度,它便无法自适应地去处理更高分辨率的帧。
基于像素幻觉的视频插帧. FeFlow 受益于中间帧生成器的可变形卷积,采用偏移向量来替代光流。Zooming Slow-Mo 也通过特征域可变形卷积的帮助进行插帧。然而,这些方法与基于流的视频插帧方法不同,由于它们直接幻化了像素,因此当快速运动的物体出现时,预测帧往往会变得模糊。
最重要的是,由于计算复杂度很高,上述视频插帧方法很难一次性对整个 HR 帧进行操作。另一方面,我们对 XVFI-Net 的设计,旨在用更少的参数,高效地对完整的 4K 输入帧一次性完成操作,并且能够有效地捕获大运动。
2.2. Networks for Large Pixel Displacements
PWC-Net 是一种最先进的光流估计手段,它已经被一些视频插帧算法采纳,用于预训练光流估计器。由于 PWC-Net 拥有 6 层特征金字塔结构和更大尺寸的感受野,因此它能有效预测大运动。IM-Net 也采用了多尺度结构来覆盖相邻帧中物体的大幅度位移,但覆盖范围受限于自适应滤波器的尺寸。尽管有多尺度金字塔结构,但上述方法缺乏自适应性,因为每个网络中最粗略的层在训练后是固定的,即每个尺度层都由其自身的(而非共享的)参数组成。RRPN 在一个灵活的循环金字塔结构中,跨越不同尺度层共享权重参数。然而,它只能推导中间时刻的帧,而不能在任意时刻进行推导。所以它只能在以2为幂的时间点递归地合成中间帧。因此,中间帧在两个输入帧之间进行递归合成的过程中,预测所产生的误差就会被不断累积。因此, 对于在任意目标时刻 t 进行的视频插帧任务来说,RRPN 受限于时间上的灵活性。
与上述方法不同的是,我们所提出的 XVFI-Net 拥有一个可扩展的结构,对于各种输入分辨率都有可共享的参数。不同于 RRPN,XVFI-Net 在结构上分为 BiOF-I 和 BiOF-T 模块,它能借助互补流逆转的方式,有效地预测任意时刻 t 的中间帧。也就是说,BiOF-T 模块可以在推导过程中跳过缩小层级,这样我们的模型就可以一次性推导出 4K 的中间帧,而无需像所有其他之前的方法那样进行任何的块迭代,使其可以被用于现实世界的应用当中。
3. Proposed X4K1000FPS Dataset
尽管许多视频插帧方法已经在不同的基准数据集上得到了训练和评估,例如 Adobe240fps,DAVIS,UCF101,Middlebury 和 Vimeo90K,但没有一个数据集包含大量的 4K 高帧率视频。这限制了某些复杂插帧算法的研究,这些算法服务于针对高分辨率视频的插帧应用。
为了解决这一具有挑战性的极端 VFI 任务,我们提供了一组丰富的 4K@1000fps 视频,视频由 Phantom Flex4KTM 相机所拍摄,其 4K 空间分辨率为 4096×2160,帧率为 1000fps,共生产了 175 个视频场景,其中每个场景均由 5000 帧组成,拍摄时长为 5 秒。
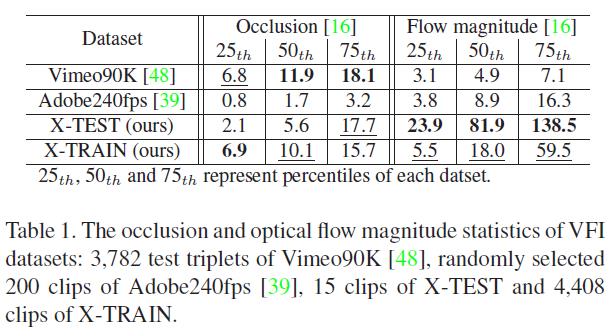
为了能为 VFI 任务选择有价值的数据样本,我们使用 IRR-PWC 估计了每 32 帧场景的双向遮挡图和光流。遮挡图预示着在下一帧中将要被遮挡的物体部分。遮挡使得光流估计和插帧变得很有挑战性。因此,综合考量遮挡程度,光流大小和场景多样性,我们人工选择了 15 个场景作为测试集 X-TEST。X-TEST 中的的每个场景都仅包含一个测试样本,该样本由时间距离为 32 帧中的两个输入帧组成,近似对应于 30fps 的帧率。测试评估被设定为插入 7 个中间帧,从而得到 240fps 连续帧的结果。对于训练集 X-TRAIN,通过考虑遮挡的数量,我们裁剪并选择了 4408 个 768×768 大小的片段,片段长度为 65 个连续帧。更多细节将在 补充材料 中进行描述说明。
表 1 比较了几个数据集的统计结果:Vimeo90K,Adobe240fps,X-TEST 和 X-TRAIN。我们在 [0,255] 的范围内对遮挡进行了估计,还估计了输入对之间的光流大小,并计算了每个数据集的百分比。如表1所示,与先前的 VFI 数据集相比,我们的数据集包含与之相当的遮挡,但运动幅度明显更大。
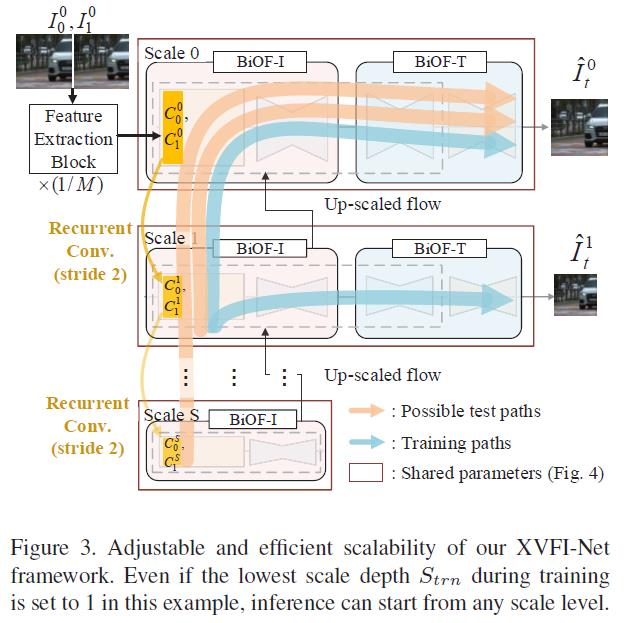
4. Proposed Method : XVFI-Net Framework
4.1. Design Considerations
我们的 XVFI-Net 旨在两个连续的输入帧 I0 和 I1 之间的任意时间点 t 插入一个包含极端运动的高分辨率中间帧 It。
尺度自适应. 诸如 PWC-Net 那样的具有固定数量尺度层级的架构很难适应输入视频的各种空间分辨率,因为每个尺度层级的结构在不同尺度层级之间是不共享的,所以需要为了一个新增尺度深度的新架构进行重新训练。为了能够拥有尺度自适应性,以应对输入帧的各种空间分辨率,我们的 XVFI-Net 被设计为可以从任意需要的粗糙尺度层级开始进行光流估计,以适应输入帧中的运动幅度。为了做到这一点,我们的 XVFI-Net 在不同的尺度层级之间共享它们的参数。
捕获大运动. 为了有效地捕捉两个输入帧之间的大运动,XVFI-Net 中的特征提取块首先通过跨步卷积,将两个输入帧的空间分辨率按照模块比例系数 M 进行缩减,从而得到空间上被缩小的特征,然后将其转换为两个上下文特征图 C 0 0 C^0_0 C00 和 C 1 0 C^0_1 C10。图 3 中的特征提取块是由跨步卷积和两个残差块所组成的。接下来,在每个尺度层级,XVFI-Net 都在以 M 为比例缩小的空间尺寸下,对目标帧 It 到两个输入帧进行光流估计。预测光流将被放大( × M \\times M ×M ),从而将每个尺度层级的输入帧变形至时间 t。
4.2. XVFI-Net Architecture
BiOF-I 模块. 图 4 展示了我们的 XVFI-Net 在尺度层级 s 上的架构,其中 Is 表示缩小 1 / 2 s 1/2^s 1/2s 次幂。首先,上下文金字塔 C = C s C = \\C^s\\ C=Cs 是通过步距为 2 的卷积从 C 0 0 C^0_0 C00 和 C 1 0 C^0_1 C10 开始循环提取的,随后,它将被用作 XVFI-Net 每一尺度层级 s ( s = 0, 1, 2, … ) 的输入,其中,s = 0 表示原始输入帧的尺度。 F t a t b s F^s_t_at_b Ftatbs 表示在尺度 s 下,时间 ta 到 tb 的光流。 F 01 s F^s_01 F01s 和 F 10 s F^s_10 F10s 是尺度 s 下,输入帧之间的双向光流。 F t 0 s F^s_t0 Ft0s 和 F t 1 s F^s_t1 Ft1s 分别是从 I t s I^s_t Its 到 I 0 s I^s_0 I0s 和 I 1 s I^s_1 I1s 的双向光流。
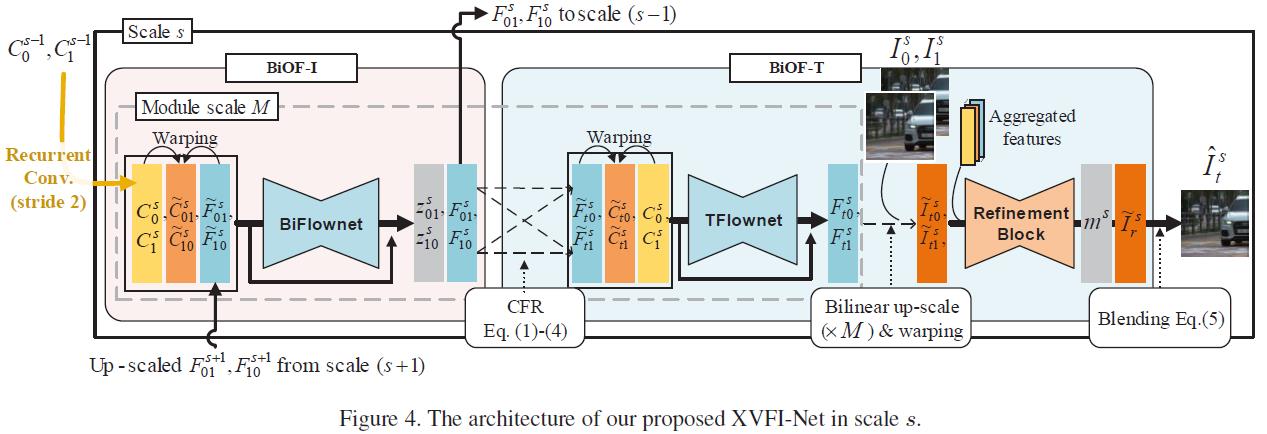
从前一个尺度 (s + 1) 估计的光流
F
01
s
+
1
F^s+1_01
F01s+1,
F
10
s
+
1
F^s+1_10
F10s+1 经过
×
2
\\times2
×2 双线性放大后,被设置为当前尺度 s 的初始光流,即,
F
~
01
s
=
F
01
s
+
1
↑
2
\\widetildeF^s_01 = F^s+1_01 \\uparrow_2
F
01s=F01s+1↑2,
F
~
10
s
=
F
10
s
+
1
↑
2
\\widetildeF^s_10 = F^s+1_10 \\uparrow_2
F
10s=F10s+1↑2。为了更新当前尺度的初始光流,首先,通过初始光流对
C
0
s
C^s_0
C0s 和
C
1
s
C^s_1
C1s 进行变形,也就是说,
C
~
01
s
=
W
(
F
~
01
s
,
C
1
s
)
\\widetildeC^s_01 = W(\\widetildeF^s_01, C^s_1)
C
01s=W(F
01s,C1s),
C
~
10
s
=
W
(
F
~
10
s
,
C
0
s
)
\\widetildeC^s_10 = W(\\widetildeF^s_10, C^s_0)
C
10s=W(F
10s,C0s),其中,W 是一个向后变形操作。接下来,
C
~
01
s
\\widetildeC^s_01
C
01s,
C
~
10
s
\\widetildeC^s_10
C
10基于光流的视频插帧算法 TOFlow 解读教程
在之前的文章中,我们介绍了基于深度学习的视频插帧。视频插帧旨在提高视频的帧率和流畅度,让视频看起来更加“丝滑”。
OpenMMLab:一键慢镜头:视频插帧,让老电影“纵享丝滑”13 赞同 · 2 评论文章正在上传…重新上传取消
基于深度学习的视频插帧算法可分为以下几类:
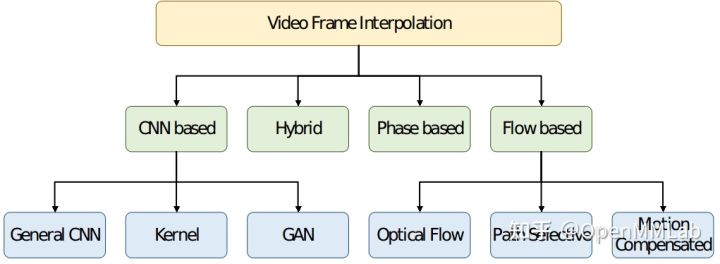
其中基于 Flow 的算法通过确定连续帧中相应实体之间流的性质,合成中间图像,以提高生成的视频质量。基于 Flow 的算法包括光流、路径选择、运动补偿,依赖于精确的运动估计技术,相比其他方法能够获取更佳的插帧效果。
今天我们就以 TOFlow (Video Enhancement with Task-Oriented Flow) 为例介绍基于光流的视频插帧算法以及其在 MMEditing 中的实现。
目录
TOFlow 的贡献
光流算法的目标是让扭曲后的图像和目标图像一致。但这种精确的光流估计前提是假设亮度一致,在变化的光照、姿势等具有挑战性的情况下,光流图的估计并不准确,导致目标边界模糊。此外,这种符合物体运动变化的图像光流估计并不适用于所有的视频处理任务。下图中,虽然 EpicFlow (Revaud et al 2015) 预测了目标的精准光流信息,但光流场中的细小误差会导致插帧结果中的伪影,例如(I-c)中模糊的手指。在视频去噪任务中,EpicFlow 预测了准确的光流但是去噪结果中依然包含噪声。

因此 TOFlow 提出将预训练的光流模块和后续处理联合训练,去学习适用于特定任务的光流特征表达。该模型使用基于光流的方法实现了视频插帧、视频去噪和视频超分辨率三个任务,计算量小且处理效果达到最优水平(例如上图 I-e 和 II-e)。
MMEditing 过往版本支持 TOFlow 视频超分辨率算法的推理,v0.14.0 版本新增了 TOFlow 视频插帧算法的训练与推理。
TOFlow 模型结构
TOFlow 模型结构包含三个部分:
- Flow Estimation 光流估计
- Transformation 光流变换
- Image Processing 图像处理
分别对应着下图中的三个阶段。在视频插帧任务中,输入的帧数 N=3;去噪和超分任务中,输入的帧数 N=7。
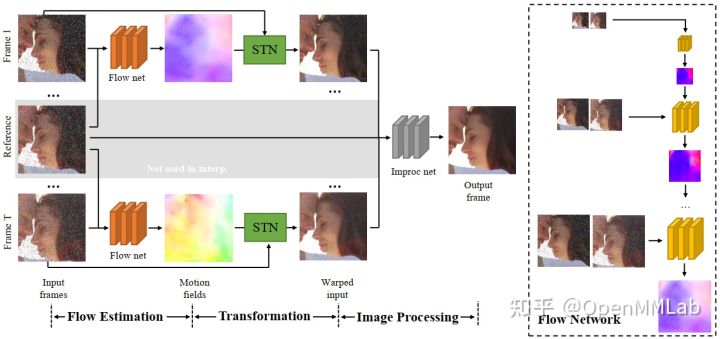
Flow Estimation
Flow Estimation 模块以预训练的 SPyNet 为 backbone,有 N-1 个结构相同、参数共享的 SPyNet 光流网络。值得注意的是,SPyNet 官方模型不包含 BN 结构,TOFlow 论文使用的 SPyNet 模型增加了 BN 结构。由于 TOFlow 的 batch_size 为 1,MMEditing 复现的模型中采用 SPyNet 官方模型,不包含 BN。
在视频插帧任务中,reference frame 是需要生成的帧,因此不包含在输入中,模型不包括上图中灰色区域。在插帧任务中,TOFlow 网络使用 SPyNet 处理 frame1 和 frame 3 以获取 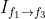
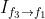 和 。
和 。
Transformation
借助 Flow Estimation 模块预测出的光流场,transformation 模块使用 `flow_warp` 函数(对应上图中的 STN)将输入帧 register 到参考帧。在视频插帧任务中,该部分获取 frame 1 和 frame 3 到 frame 2 的映射: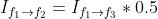
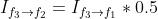
Image Processing
Image Processing 模块使用 ResNet 结构,将 Transformation 模块获取到的映射图像加工成最终的插帧结果。
Vimeo90k-triplet 数据集
Video Enhancement with Task-Oriented Flow 论文中提出 TOFlow 模型的同时提供了 Vimeo90k 数据集,其中 Vimeo90k-triplet 为用于插帧的数据集,每个场景包含 3 张图片,使用 im1.png 和 im3.png 求解得到 im2.png。MMEditing 中已支持 Vimeo90k-triplet 数据集。
- 训练集数据量:51.3k
- 测试集数据量:3.8k
- tri_testlist.txt / tri_trainlist.txt 标注结构:
00001/0001
00001/0002
数据集的文件结构如下所示:
├── tri_testlist.txt
├── tri_trainlist.txt
├── sequences
│ ├── 00001
│ │ ├── 0001
│ │ │ ├── im1.png
│ │ │ ├── im2.png
│ │ │ └── im3.png
│ │ ├── 0002
│ │ ├── 0003
│ │ ├── ...
│ ├── 00002
│ ├── ...
MMEditing 中的 TOFlow
TOFlow 基于预训练的 SPyNet,根据预训练 SPyNet 的训练数据,MMEditing 提供了以下 5 个模型:
| Method | PSNR / SSIM |
|---|---|
| tof_vfi_spynet_chair_nobn_1xb1_vimeo90k | 33.3294 / 0.9465 |
| tof_vfi_spynet_kitti_nobn_1xb1_vimeo90k | 33.3339 / 0.9466 |
| tof_vfi_spynet_sintel_clean_nobn_1xb1_vimeo90k | 33.3170 / 0.9464 |
| tof_vfi_spynet_sintel_final_nobn_1xb1_vimeo90k | 33.3237 / 0.9465 |
| tof_vfi_spynet_pytoflow_nobn_1xb1_vimeo90k | 33.3426 / 0.9467 |
本文以 tof_vfi_spynet_chair_nobn_1xb1_vimeo90k 为例介绍 MMEditing 中的 TOFlow。
其中 tof_vfi 是模型名称,spynet_chair_nobn 表示使用 chair 数据集预训练的无 BN 结构的 SPyNet 模型,1xb1 代表模型在单卡上训练,每张卡上 batch_size=1,vimeo90k 表示训练数据集是 vimeo90k-triplet。
定义 Model 和 Backbone
训练时需要导入预训练的 SPyNet 参数,如下面代码所示:
# pretrained SPyNet
source = 'https://download.openmmlab.com/mmediting/video_interpolators/toflow'
spynet_file = 'pretrained_spynet_chair_20220321-4d82e91b.pth'
load_pretrained_spynet = f'source/spynet_file'
# model settings
model = dict(
type='BasicInterpolator',
generator=dict(
type='TOFlowVFI',
rgb_mean=[0.485, 0.456, 0.406],
rgb_std=[0.229, 0.224, 0.225],
flow_cfg=dict(norm_cfg=None, pretrained=load_pretrained_spynet)),
pixel_loss=dict(type='CharbonnierLoss', loss_weight=1.0, reduction='mean'))
# model training and testing settings
train_cfg = None
test_cfg = dict(metrics=['PSNR', 'SSIM'], crop_border=0) 定义数据处理 pipeline
TOFlow 未进行数据增广处理,因此测试、验证的 pipeline 与训练 pipeline 相同,如下面代码所示:
train_pipeline = [
dict(
type='LoadImageFromFileList',
io_backend='disk',
key='inputs',
channel_order='rgb',
backend='pillow'),
dict(
type='LoadImageFromFile',
io_backend='disk',
key='target',
channel_order='rgb',
backend='pillow'),
dict(type='RescaleToZeroOne', keys=['inputs', 'target']),
dict(type='FramesToTensor', keys=['inputs']),
dict(type='ImageToTensor', keys=['target']),
dict(
type='Collect',
keys=['inputs', 'target'],
meta_keys=['inputs_path', 'target_path', 'key'])
]
Demo pipeline 则为训练 pipeline 剔除 `target` 相关关键词的结果:
demo_pipeline = [
dict(
type='LoadImageFromFileList',
io_backend='disk',
key='inputs',
channel_order='rgb',
backend='pillow'),
dict(type='RescaleToZeroOne', keys=['inputs']),
dict(type='FramesToTensor', keys=['inputs']),
dict(type='Collect', keys=['inputs'], meta_keys=['inputs_path', 'key'])
]
定义训练和测试配置
如下面代码所示:
root_dir = 'data/vimeo_triplet'
data = dict(
workers_per_gpu=1,
train_dataloader=dict(samples_per_gpu=1, drop_last=True), # 1 gpu
val_dataloader=dict(samples_per_gpu=1),
test_dataloader=dict(samples_per_gpu=1),
# train
train=dict(
type='RepeatDataset',
times=1000,
dataset=dict(
type=train_dataset_type,
folder=f'root_dir/sequences',
ann_file=f'root_dir/tri_trainlist.txt',
pipeline=train_pipeline,
test_mode=False)),
# val
val=dict(
type=train_dataset_type,
folder=f'root_dir/sequences',
ann_file=f'root_dir/tri_validlist.txt',
pipeline=train_pipeline,
test_mode=True),
# test
test=dict(
type=train_dataset_type,
folder=f'root_dir/sequences',
ann_file=f'root_dir/tri_testlist.txt',
pipeline=train_pipeline,
test_mode=True),
)
其中 tri_validlist.txt 来源于 tri_testlist.txt,为 tri_testlist.txt 中匹配 00001/* 的 42 条数据。RepeatDataset 对训练集文件列表进行了复制,从而扩充训练数据。
定义优化器、学习策略和 Hook
如下面代码所示:
# optimizer
optimizers = dict(
generator=dict(type='Adam', lr=5e-5, betas=(0.9, 0.99), weight_decay=1e-4))
# learning policy
total_iters = 1000000
lr_config = dict(
policy='Step',
by_epoch=False,
gamma=0.5,
step=[200000, 400000, 600000, 800000])
checkpoint_config = dict(interval=5000, save_optimizer=True, by_epoch=False)
evaluation = dict(interval=5000, save_image=True)
log_config = dict(
interval=100, hooks=[
dict(type='TextLoggerHook', by_epoch=False),
])
visual_config = None
结语
MMEditing 是面向底层视觉任务的工具包,经过社区开发者的不懈努力,MMEditing 已经支持了大量先进的超分辨率模型,可以将视频和图像从低分辨率无损放大到高分辨率。同时,MMEditing 也提供了 TOFlow、CAIN 等视频插帧算法,我们的模块化设计可以让大家方便地增加或减少各种 pipeline。欢迎大家来体验,享受一下高帧率的快感。
https://github.com/open-mmlab/mmeditinggithub.com/open-mmlab/mmediting
以上是关于视频插帧XVFI: eXtreme Video Frame Interpolation的主要内容,如果未能解决你的问题,请参考以下文章