编码器-解码器架构-读书笔记
Posted 取个名字真难呐
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了编码器-解码器架构-读书笔记相关的知识,希望对你有一定的参考价值。
文章目录
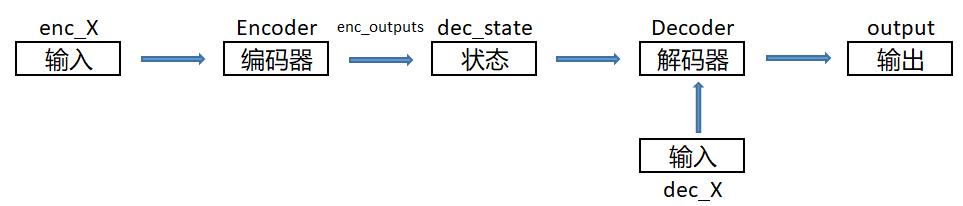
1. Encoder-Decoder 架构图
- 目标:通过编码器与解码器架构,我们可以将不同长度的序列先通过
编码器编码成固定长度的隐藏层状态,再通过解码器将固定长度的隐藏层状态解码成不同长度的序列
2. Encoder_Decoder 代码
- 接口代码
from torch import nn
class Encoder(nn.Module):
"""编码器-解码器架构的基本编码器接口"""
def __init__(self,**kwargs):
super(Encoder,self).__init__(**kwargs)
def forward(self,X,*args):
raise NotImplementedError
class Decoder(nn.Module):
"""编码器-解码器架构的基本解码器接口"""
def __init__(self,**kwargs):
super(Decoder,self).__init__(**kwargs)
def init_state(self,enc_outputs,*args):
raise NotImplementedError
def forward(self,X,state)
raise NotImplementedError
class EncoderDecoder(nn.Module):
"""编码器-解码器架构的基类"""
def __init__(self,encoder,decoder,**kwargs):
super(EncoderDecoder,self).__init__(**kwargs)
self.encoder = encoder
self.decoder = decoder
def forward(self,enc_X,dec_X,*args):
enc_outputs = self.encoder(enc_X,*args)
dec_state = self.decoder.init_state(enc_outputs,*args)
return self.decoder(dec_X,dec_state)
3. 小结
Encoder-Decoder 架构定义了三个类
- Encoder 类
- Decoder 类
- EncoderDecoder 类
而这种架构非常像我们设计模式中的策略者模式,通过策略者模式,我们可以非常清晰的将业务逻辑设计出来。 - OmniGraffle画图软件
『TensorFlow』读书笔记_降噪自编码器
之前学习过的代码,又敲了一遍,新的收获也还是有的,因为这次注释写的比较详尽,所以再次记录一下,具体的相关知识查阅之前写的文章即可(见上面链接)。
# Author : Hellcat
# Time : 2017/12/6
import numpy as np
import sklearn.preprocessing as prep
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
def xavier_init(fan_in,fan_out, constant = 1):
\'\'\'
xavier 权重初始化方式
:param fan_in: 行数
:param fan_out: 列数
:param constant: 常数权重,调节初始化范围的倍数
:return: 初始化后的权重tensor
\'\'\'
low = -constant * np.sqrt(6.0 / (fan_in + fan_out))
high = constant * np.sqrt(6.0 / (fan_in + fan_out))
return tf.random_uniform((fan_in, fan_out),
minval=low, maxval=high)
class AdditiveGaussianNoiseAutoencoder():
def __init__(self, n_input, n_hidden,
transfer_function=tf.nn.softplus,
optimizer=tf.train.AdamOptimizer(),scale=0.1):
\'\'\'
初始化自编码器
:param n_input: 输入层结点数
:param n_hidden: 隐藏层节点数
:param transfer_function: 隐藏层激活函数
:param optimizer: 优化器,是实例化的对象
:param scale: 高斯噪声系数
\'\'\'
self.n_input = n_input
self.n_hidden = n_hidden
self.transfer = transfer_function
self.scale = tf.placeholder(tf.float32) # 实际网络中调用的
self.training_scale = scale # 训练用噪声系数
network_weights = self._initialize_weights()
self.weights = network_weights
self.x = tf.placeholder(tf.float32, [None, self.n_input])
self.hidden = \\
self.transfer(
tf.add(
tf.matmul(
self.x + self.scale * tf.random_normal((n_input,)),
self.weights[\'w1\']),
self.weights[\'b1\']))
# 重建部分没有使用激活函数
self.reconstruction = \\
tf.add(
tf.matmul(
self.hidden, self.weights[\'w2\']),
self.weights[\'b2\'])
self.cost = 0.5 * tf.reduce_sum(tf.pow(tf.subtract(self.reconstruction,self.x),2.0))
# 可以将类的实例过程作为实参传入函数
self.optimizer = optimizer.minimize(self.cost)
init = tf.global_variables_initializer()
self.sess = tf.Session()
self.sess.run(init)
def _initialize_weights(self):
\'\'\'
初始化全部变量
:return: 装有变量的字典
\'\'\'
all_weights = dict()
all_weights[\'w1\'] = tf.Variable(xavier_init(self.n_input, self.n_hidden))
all_weights[\'b1\'] = tf.Variable(tf.zeros([self.n_hidden], dtype=tf.float32))
all_weights[\'w2\'] = tf.Variable(tf.zeros([self.n_hidden, self.n_input], dtype=tf.float32))
all_weights[\'b2\'] = tf.Variable(tf.zeros([self.n_input], dtype=tf.float32))
return all_weights
def partial_fit(self, X):
\'\'\'
进行单次训练并返回loss
:param X: 训练数据
:return: 本次损失函数值
\'\'\'
cost, opt = self.sess.run((self.cost, self.optimizer),
feed_dict={self.x:X, self.scale:self.training_scale})
return cost
def calc_totul_cost(self, X):
\'\'\'
计算损失函数,不触发训练
:param X: 训练数据
:return: 损失函数
\'\'\'
return self.sess.run(self.cost, feed_dict={self.x:X, self.scale:self.training_scale})
def transform(self, X):
\'\'\'
返回隐藏层输出结果,目的是获取抽象后的特征
:param X: 训练数据
:return: 隐藏层输出
\'\'\'
return self.sess.run(self.hidden, feed_dict={self.x:X, self.scale:self.training_scale})
def generate(self, hidden=None):
\'\'\'
通过隐藏层特征重建
:param hidden: 隐藏层特征
:return: 重建数据
\'\'\'
if hidden is None:
hidden = np.random.normal(size=[self.n_input])
return self.sess.run(self.reconstruction, feed_dict={self.hidden:hidden})
def reconstruct(self,X):
\'\'\'
从原始数据重建
:param X: 训练数据
:return: 重建数据
\'\'\'
return self.sess.run(self.reconstruction,
feed_dict={self.x:X, self.scale:self.training_scale})
def getWeights(self):
\'\'\'
获取参数值
:return: 隐藏层权重
\'\'\'
return self.sess.run(self.weights[\'w1\'])
def getBaises(self):
\'\'\'
获取参数值
:return: 隐藏层偏置
\'\'\'
return self.sess.run(self.weights[\'b1\'])
def standard_scale(X_train, X_test):
\'\'\'
标准化数据
:param X_train: 训练数据
:param X_test: 测试数据
:return: 标准化之后的训练、测试数据
\'\'\'
preprocessor = prep.StandardScaler().fit(X_train)
X_train = preprocessor.transform(X_train)
X_test = preprocessor.transform(X_test)
return X_train, X_test
def get_random_block_from_data(data, batch_size):
start_index = np.random.randint(0, len(data) - batch_size)
return data[start_index:(start_index + batch_size)]
if __name__ == \'__main__\':
mnist = input_data.read_data_sets(\'../../../Mnist_data/\',one_hot=True)
X_train, X_test = standard_scale(mnist.train.images, mnist.test.images)
n_samples = int(mnist.train.num_examples)
train_epochs = 20
batch_size = 20
display_step = 1
autoencoder = AdditiveGaussianNoiseAutoencoder(
n_input=784,
n_hidden=200,
transfer_function=tf.nn.softplus,
optimizer=tf.train.AdamOptimizer(learning_rate=0.001),
scale=0.01)
for epoch in range(train_epochs):
avg_cost = 0.
totu_batch = int(n_samples / batch_size)
for i in range(totu_batch):
batch_xs = get_random_block_from_data(X_train, batch_size)
# 单数据块训练并计算损失函数
cost = autoencoder.partial_fit(batch_xs)
avg_cost += cost / n_samples * batch_size
if epoch % display_step == 0:
print(\'epoch : %04d, cost = %.9f\' % (epoch + 1,avg_cost))
# 计算测试集上的cost
print(\'Total coat:\',str(autoencoder.calc_totul_cost(X_test)))
部分输出如下:
……
epoch : 0020, cost = 1509.876800515
epoch : 0020, cost = 1510.107261985
epoch : 0020, cost = 1510.332509055
epoch : 0020, cost = 1510.551538707
Total coat: 768927.0
1.xavier初始化权重方法
2.函数实参可以是class(),即实例化的类
以上是关于编码器-解码器架构-读书笔记的主要内容,如果未能解决你的问题,请参考以下文章
论文笔记-Deep Learning on Graphs: A Survey(上)
机器翻译数据集 编码器-解码器架构以及实现 动手学深度学习v2
机器翻译数据集 编码器-解码器架构以及实现 动手学深度学习v2