Python数据挖掘—爬虫基础
Posted 之墨_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python数据挖掘—爬虫基础相关的知识,希望对你有一定的参考价值。
Python数据挖掘—爬虫基础
反爬手段
1.User‐Agent
User Agent中文名为用户代理,简称 UA,它是一个特殊字符串头,使得服务器能够识别客户使用的操作系统及版本、CPU 类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等。
2.代理IP
西次代理
快代理
什么是高匿名、匿名和透明代理?它们有什么区别?
1. 使用透明代理,对方服务器可以知道你使用了代理,并且也知道你的真实IP。
2. 使用匿名代理,对方服务器可以知道你使用了代理,但不知道你的真实IP。
3.
4. 使用高匿名代理,对方服务器不知道你使用了代理,更不知道你的真实IP。
3. 验证码访问
打码平台
云打码平台
超级🦅
4.动态加载网页
网站返回的是js数据 并不是网页的真实数据
selenium驱动真实的浏览器发送请求
5.数据加密
分析js代码
urllib库
urllib.request.urlopen() 模拟浏览器向服务器发送请求
response 服务器返回的数据
response的数据类型是HttpResponse
字节‐‐>字符串
解码decode
字符串‐‐>字节
编码encode
read() 字节形式读取二进制 扩展:rede(5)返回前几个字节
readline() 读取一行
readlines() 一行一行读取 直至结束
getcode() 获取状态码
geturl() 获取url
getheaders() 获取headers
urllib.request.urlretrieve()
请求网页
请求图片
请求视频
请求对象的定制
语法:request = urllib.request.Request()
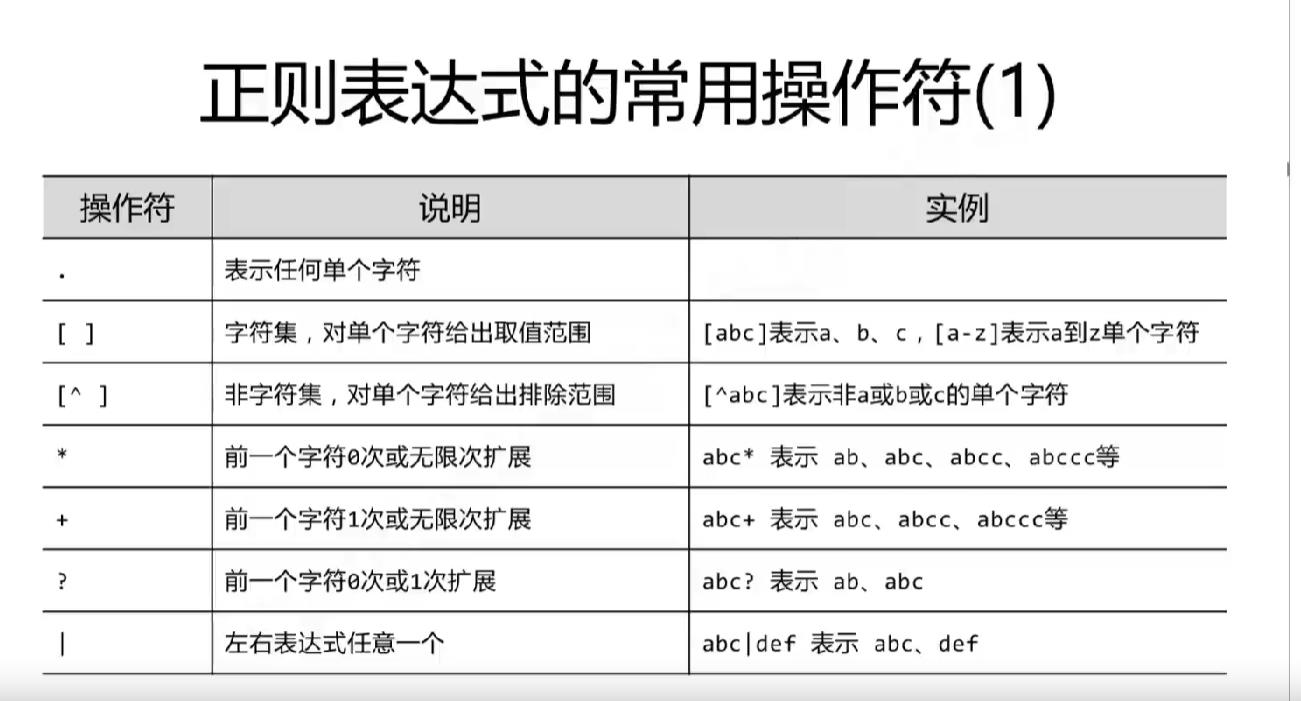
正则表达式
以上是关于Python数据挖掘—爬虫基础的主要内容,如果未能解决你的问题,请参考以下文章