Flink运行时架构及各部署模式下作业提交流程
Posted hmi1024
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink运行时架构及各部署模式下作业提交流程相关的知识,希望对你有一定的参考价值。
1.运行时架构
1.1 核心组件
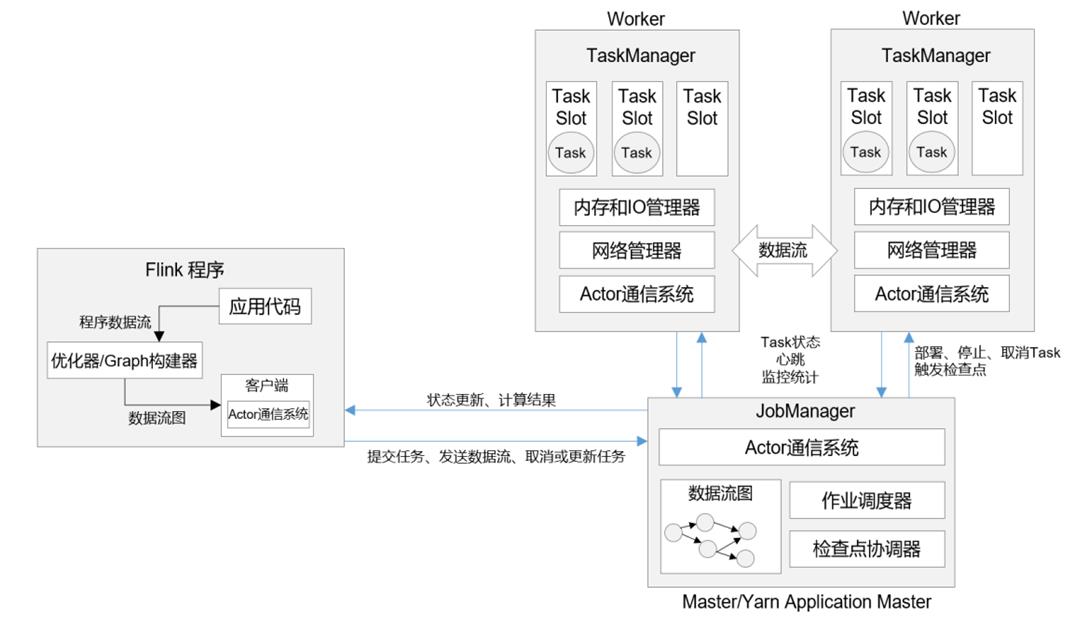
1.1.1 JobManager
作业管理器,对于一个提交执行的作业,JobManager 是真正意义上的“管理者”(Master),负责管理调度,是一个 Flink 集群中任务管理和调度的核心,是控制应用执行的主进程。在不考虑高可用的情况下只能有一个
JobManager ,只有一个是正在运行的领导节点(leader),其他都是备用节点(standby)
JobManager包含三大核心组件:
- JobMaster
- JobMaster是JobManager的核心组件,负责处理单独的作业(job)
- JobMaster和Job是一一对应的,多个Job可以运行在一个Flink集群中, 每个Job都有一个自己的JobMaster
- 在作业提交时,JobMaster会先接收到要执行的应用,一般是由客户端提 交来的,包括 Jar包,数据流图(dataflow Graph)和作业图(JobGraph)
- jobMaster会将JobGraph转换为一个物理层面的数据流图执行图(ExecutionGraph),它包含所有可以并发执行的任务
- JobMaster会向资源管理器ResourceManager发出请求,申请必要的资源,一旦获取到足够的资源,就会将执行图分发到真正运行他们的TaskManager上
- 在作业的运行过程中,JobMaster会负责所有需要中央协调的操作,比如说检查点(checkpoints)的协调
- ResourceManager
注意:该ResourceManager是Flink内置的,不是其他资源调度平台(如YARN)的 ResourceManager
- ResourceManager主要负责资源的分配和管理,在Flink集群中只有一个
- 资源主要指的是TaskManager的槽(task slots),任务槽是Flink集群中的资源调配单元,包含了机器用来计算的一组CPU和内存资源
- 每一个task都要分配到一个slot上进行
- Flink集群Standalone部署模式下,TaskManager是单独启动的(没有Per-Job模式),此时的ResourceManager只能分发可用的TaskManager任务槽,不能单独启动新的TaskManager
- Flink集群部署资源管理平台时(YARN 、K8s)等,ResourceManager 会将有空闲槽位的 TaskManager 分配给 JobMaster。若ResourceManager 没有足够的任务槽,它还可以向资源提供平台请求提供启动 TaskManager 进程的容器。另外,ResourceManager 还负责停掉空闲的 TaskManager,释放计算资源
- Dispatcher
- Dispatcher分发器主要提供一个REST接口,用来提交应用
- 为每一个新提交的作业启动一个新的JobMaster组件
- 启动Web UI,方便地展示和监控作业信息
- 在架构中并不是必须的,在不同的部署模式下可能会被忽略
1.1.2 TaskManager
任务管理器,是Flink中的工作进程,称为Worker
- 数据流的具体计算由它来完成,每个Flink集群至少一个TaskManager,每一个TaskManager包含一定数量的任务槽(slot),slot是资源调度的最小单位,slot的数量决定了TaskManager并行处理任务的数量
- 启动后,TaskManager会向ResourceManager注册它的slots,收到ResourceManager的指令后,TaskManager就会将一个或多个slot提供给JobMaster调用,JobMaster就可以分配任务来执行了
- 在执行过程中,TaskManager 可以缓冲数据,还可以跟其他运行同一应用的 TaskManager交换数据
1.2 作业图
2. 作业提交流程
2.1 抽象流程
Flink 的提交流程,随着部署模式、资源管理平台的不同,会有不同的变化。首先我们从一个高层级的视角,来做一下抽象提炼,看一看作业提交时宏观上各组件是怎样交互协作的
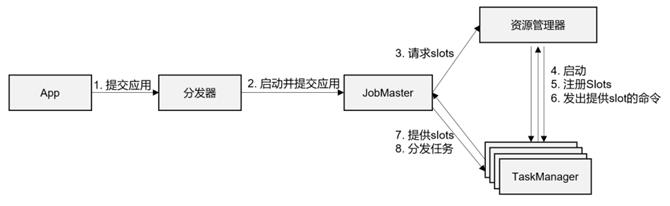
- Client向Dispatcher提交作业
- Dispatcher通过REST接口将作业(包含 JobGraph)提交给 JobMaster
- JobMaster将JobGraph解析成可执行的ExecutionGraph得到所需资源的数量,向ResourceManager申请作业所需要的slots
- ResourceManager判断当前是否有足够的可用资源,如果没有则启动新的TaskManager
- TaskManager启动之后,向ResourceManager注册可用的slot
- ResourceManager向TaskManager发出命令,为新作业提供slots
- TaskManager向JobMaster提供slots
- JobMaster向TaskManager分发任务
- TaskManager执行任务,相互之间可以交换数据
2.2 独立模式(Standalone)
在独立模式下,只有两种部署方式会话模式和应用模式,没有分离模式。Flink的三种部署方式
两者整体的作业提交流程十分相似:TaskManager都需要手动启动,JobMaster向ResourceManager申请资源时,ResourceManager会直接要求TaskManager提供资源,区别在于,会话模式下,TaskManager是预先启动的,应用模式的TaskManager是作业提交时启动的

该作业流程除了ResourceManager不需要启动TaskManager,而是直接向已有的TaskManager要求资源,和上述抽象流程完全一致
2.3 FLINK ON YARN
flink在资源管理平台的作业提交流程,以YARN集群为例
- 会话模式
需要事先申请资源,如图所示:
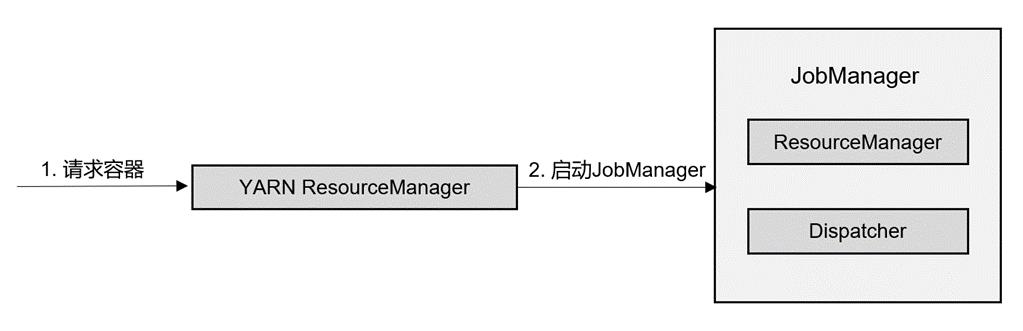
这里只启动了 JobManager,在 JobManager 内部,由于还没有提交作业,故只有ResourceManager 和 Dispatcher 在运行,而 TaskManager 可以根据需要动态地启动。如图所示:
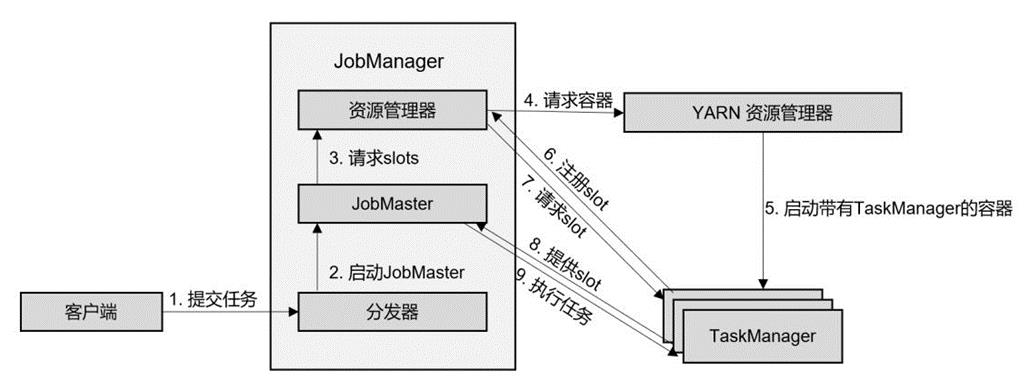
- Client提交任务到Dispatcher
- Dispatcher启动JobMaster
- JobMaster向ResourceManager(Flink)申请slots
- ResourceManager(Flink)向ResourceManager(YARN)申请Container资源
- ResourceManager(YARN)启动TaskManager
- TaskManager向ResourceManager(Flink)注册可用slots
- ResourceManager(Flink)向TaskManager请求slots
- TakManager向JobMaster提供slots
- JobMaster分发任务给TaskManager,TaskManager执行任务
- 分离模式
在分离模式下,Flink 集群不会预先启动,而是在提交作业时,才启动新的 JobManager。具体流程如图所示:
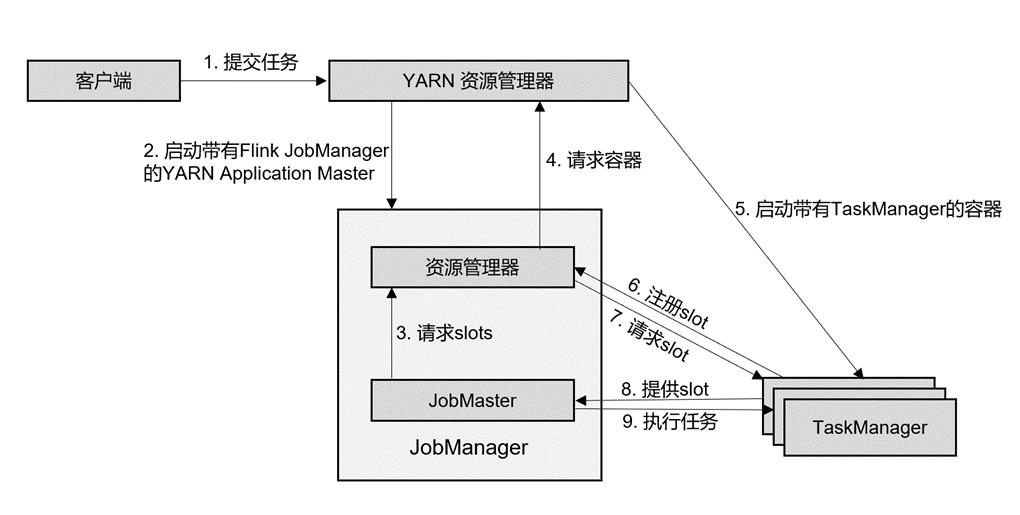
- Client提交任务到ResourceManager(YARN)
- ResourceManager(YARN)分配Container资源,启动Flink的JobMaster,并将作业提交给JobMaster,此处省略Dispatcher(与会话模式的区别点)
- JobMaster向ResourceManager(Flink)请求slots
- ResourceManager(Flink)向ResourceManager(YARN)请求Container资源
- ResourceManager(YARN)启动新的TaskManager容器
- TaskManager向ResourceManager(Flink)注册可用的slots
- ResourceManager(Flink)向TaskManager请求slots
- TaskManager向JobMaster提供slots
- JobMaster分发任务给TaskManager,TaskManager执行任务
- 应用模式
应用模式与分离模式的提交流程非常相似,只是初始提交给 YARN 资源管理器的不再是具体的作业,而是整个应用。一个应用中可能包含了多个作业,这些作业都将在 Flink 集群中启动各自对应的 JobMaster.
flink运行架构详解

一、开发模式
per-job-cluster 提交模式
1.一个Job会对应一个Flink集群,每提交一个作业会根据自身的情况,都会单独向yarn申请资源,直到作业执行完成,一个作业的失败与否并不会影响下一个作业的正常提交和运行。独享Dispatcher和ResourceManager,按需接受资源申请;适合规模大长时间运行的作业。
2.优点
每次提交都会创建一个新的flink集群,任务之间互相独立,互不影响,方便管理。任务执行完成之后创建的集群也会消失。
Session-Cluster
1.Session-Cluster模式需要先启动Flink集群,向Yarn申请资源。以后提交任务都向这里提交。这个Flink集群会常驻在yarn集群中,除非手工停止。
2.缺点
如果提交的作业中有长时间执行的大作业, 占用了该Flink集群的所有资源, 则后续无法提交新的job.
3.优点
Session-Cluster适合那些需要频繁提交的多个小Job, 并且执行时间都不长的Job.
(因为使用其他模式 频繁提交多个小job,导致申请资源时间大于 执行job时间)
二、运行时架构

1 job manager
1>ResourceManager
整个 Flink 集群中只有一个 ResourceManager. 注意这个ResourceManager不是Yarn中的ResourceManager, 是Flink中内置的, 只是赶巧重名了而已.
主要负责管理任务管理器(TaskManager)的插槽(slot),TaskManger插槽是Flink中定义的处理资源单元。
2>Dispatcher
负责接收用户提供的作业,并且负责为这个新提交的作业启动一个新的JobMaster 组件. Dispatcher也会启动一个Web UI,用来方便地展示和监控作业执行的信息。Dispatcher在架构中可能并不是必需的,这取决于应用提交运行的方式。
3> JobMaster
JobMaster负责管理单个JobGraph的执行.多个Job可以同时运行在一个Flink集群中, 每个Job都有一个自己的JobMaster.
2.TaskManager
Flink中的工作进程。通常在Flink中会有多个TaskManager运行,每一个TaskManager都包含了一定数量的插槽(slots)。插槽的数量限制了TaskManager能够执行的任务数量。
启动之后,TaskManager会向资源管理器注册它的插槽;收到资源管理器的指令后,TaskManager就会将一个或者多个插槽提供给JobManager调用。JobManager就可以向插槽分配任务(tasks)来执行了。
任务流程
- Flink任务提交后,Client向HDFS上传Flink的Jar包和配置
- 向Yarn ResourceManager提交任务,ResourceManager分配Container资源
- 通知对应的NodeManager启动ApplicationMaster,ApplicationMaster启动后加载Flink的Jar包和配置构建环境,然后启动JobManager
- ApplicationMaster向ResourceManager申请资源启动TaskManager
- ResourceManager分配Container资源后,由ApplicationMaster通知资源所在节点的NodeManager启动TaskManager
- NodeManager加载Flink的Jar包和配置构建环境并启动TaskManager
TaskManager启动后向JobManager发送心跳包,并等待JobManager向其分配任务。
三、核心概念
什么是slot?
插槽,每个TaskManager 默认配置 1。 一般配置和cpu核心数,多个slot均分 TaskManager 的内存资源,与其他slot之间 内存隔离,共享cpu资源。slot内共享(多个task 和共享一块内存)
一个job 分配多少个 slot?
所有slot共享组最大并行度之和
slot 共享组?
.slotSharingGroup("group1")
默认只有一个共享组。不同的共享组之间一定占用不同的slot
任务链?
多个算子 之间 组成任务链
Stream在算子之间传输数据的形式可以是one-to-one(forwarding)的模式也可以是redistributing的模式,具体是哪一种形式,取决于算子的种类。
- One-to-one:
stream(比如在source和map operator之间)维护着分区以及元素的顺序。那意味着flatmap 算子的子任务看到的元素的个数以及顺序跟source 算子的子任务生产的元素的个数、顺序相同,map、fliter、flatMap等算子都是one-to-one的对应关系。
- Redistributing:
stream(map()跟keyBy/window之间或者keyBy/window跟sink之间)的分区会发生改变。每一个算子的子任务依据所选择的transformation发送数据到不同的目标任务。例如,keyBy()基于hashCode重分区、broadcast和rebalance会随机重新分区,这些算子都会引起redistribute过程,而redistribute过程就类似于Spark中的shuffle过程。
并行度相同的 前后两个算子,并且one_to_one传输,则flink (自动优化)会将这两个 task合并。
目的:减少数据交换产生的消耗,在减少时延的同时提升吞吐量。
当然也可以断开这两个算子
* 算子.startNewChain() => 与前面断开
* 算子.disableChaining() => 与前后都断开
* env.disableOperatorChaining() => 全局都不串
断开操作链的好处在于减少某个slot的压力。
以上是关于Flink运行时架构及各部署模式下作业提交流程的主要内容,如果未能解决你的问题,请参考以下文章
最新 Flink 1.13 运行时架构(JobManagerTaskManagerYARNSlotsJobGraph)快速入门详细教程
8.一文搞定Flink单作业提交模式(per-job)的运行时状态