学习记录:正负样本分配策略之YoloX | SimOTA-简单易懂版
Posted Double-Zh
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了学习记录:正负样本分配策略之YoloX | SimOTA-简单易懂版相关的知识,希望对你有一定的参考价值。
学习记录:正负样本分配策略之YoloX | SimOTA-简单易懂版
文献阅读和分享
《Bridging the Gap Between Anchor-based and Anchor-free Detection via Adaptive Training Sample Selection》 ,首先来感受下这篇2020年目标检测领域最有价值之一的文章;

原文链接:https://arxiv.org/abs/1912.02424
个人感觉文章最大的亮点就是揭露anchor-based和anchor-free两类算法本质的区别、以及提出了一种名为ATSS的正负样本选择方法。文章具体创新点如下:

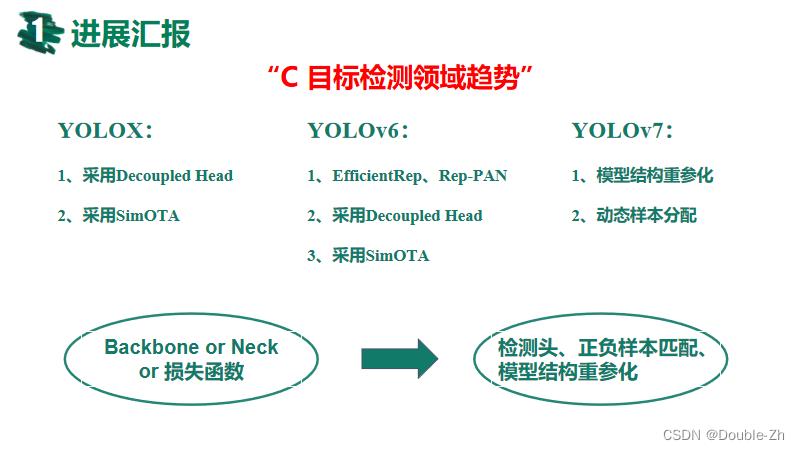
目标检测领域趋势
近年来,模型结构重参化和动态标签分配已逐渐成为目标检测中的重要优化方向。
正负样本分配策略——SimOTA
网络训练(恋爱历程)
-
首先,我们把网络训练比作小白、小里和小腾等多个同学的谈恋爱过程;SimOTA比作为中介;(注:多个同学是因为图片中往往不止一个目标)
-
接着,SimOTA给目标框定义正负样本,即中介给这些同学分配多个对象;(注:多个对象是重点,也是这个中介的厉害之处)
-
开始训练,反向优化,即开始谈恋爱,总结经验。

SimOTA具体流程(中介分配对象流程)
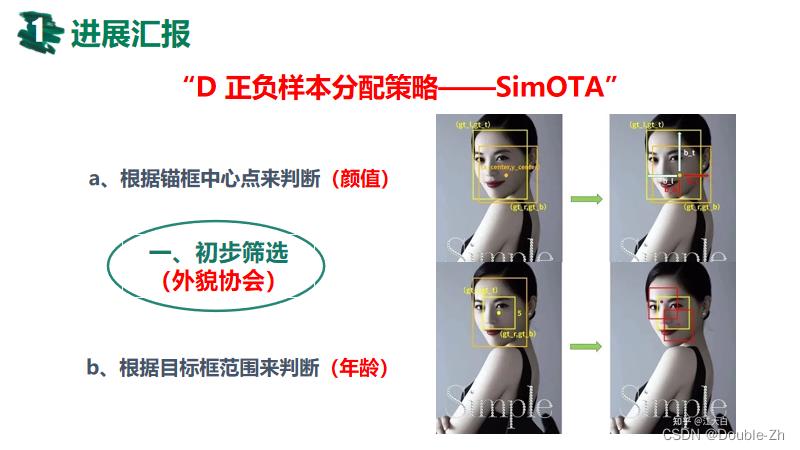
一、初步筛选(外貌协会)
-
首先,根据Anchor Box中心点是否落在Ground-truth Box范围内,筛选出符合的Anchors;
(即,依照小白他们各自对颜值的需求,选出一批满意的对象) -
接着,根据Ground-truth Box中心点上下左右2.5的距离,形成一个边长为5的矩形框,筛选出中心点落在这个区域的Anchors;
(即,根据小白他们各自的年龄,选出一批跟他们年龄相差不超过2.5年的对象) -
最终这两部分Anchors即为初步筛选出的对象。
二、精细筛选(深入接触)
-
首先,提取初筛Anchors的信息,位置IoU、前背景目标、类别等;
(即,获得这些对象的地区、性格、共同点等信息) -
接着,计算Loss函数并构建cost矩阵;
(即,开始给这些对象打分,地区权重为3,看来这个中介也知道异地很难) -
重点!!:根据前10个IoU给每个目标框动态分配k个候选框,具体为:
a)根据上一步算得的IoU矩阵(目标框和候选框),排序并取前10个候选框;
b)对这10个候选框的IoU进行相加,并向下取整(int操作),最终得到k的具体数值,即为该目标框的分配候选框对象个数;
(即,根据地域远近,中介给小白他们确定对象的分配个数) -
最后,根据cost矩阵挑出前k个候选框,并去除重复候选框。
(即,根据之前给对象的打分,挑选出最满意的k个对象;然而,小白看上的对象可能小腾也看上了,难道谁充钱多这个对象就给谁吗?中介很正直,谁跟这个对象更合适就给谁分配!)

个人疑惑
个人疑惑:为什么k值不直接设定成固定值?如果要固定,那具体设置多大才合适呢?
个人理解(不一定正确,欢迎交流):k设置成一个随着训练而动态变化的值,大概也符合网络通过不断学习,其精度不断改善的变化趋势吧。就比如小白、小里和小腾(渣男们)通过不断和多个对象谈恋爱,逐渐知道找对象不仅要注意外在形象,也要提升自己的内在修养,自然才能吸引到更多的对象(也就是说训练过程中,k值会变大,正样本会变多),最终才能找到合适自己的人,对吧hhh!
以上就是个人对SimOTA的一点学习记录,希望能够对大家起到一定的帮助!
ps:PPT已放到参考链接[2],有需要可自取。
参考
[1]: https://zhuanlan.zhihu.com/p/397993315
[2]: https://github.com/Double-zh/PPT-YoloX-SimOTA.git
以上是关于学习记录:正负样本分配策略之YoloX | SimOTA-简单易懂版的主要内容,如果未能解决你的问题,请参考以下文章