论文速递COLING 2022 - 联合语言语义和结构嵌入用于知识图补全
Posted Trouble..
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文速递COLING 2022 - 联合语言语义和结构嵌入用于知识图补全相关的知识,希望对你有一定的参考价值。
【论文速递】COLING 2022 - 联合语言语义和结构嵌入用于知识图补全
【论文原文】:Joint Language Semantic and Structure Embedding for Knowledge Graph Completion
【作者信息】:Jianhao Shen,Chenguang Wang,Linyuan Gong,Dawn Song
论文:https://arxiv.org/pdf/2209.08721.pdf
代码:https://github.com/pkusjh/LASS
博主关键词:链路预测、语义信息、结构信息、预训练微调
推荐论文:无
摘要
补全知识三元组的任务具有广泛的下游应用。结构信息和语义信息在知识图补全中都起着重要作用。与以往依赖知识图谱的结构或语义的方法不同,我们提出将语义与知识三元组的结构信息联合嵌入到知识三元组的自然语言描述中。我们的方法通过针对概率结构化损失微调预训练的语言模型,为补全任务嵌入知识图,其中语言模型的前向传递捕获语义,损失重建结构。我们在各种知识图谱基准上的大量实验已经证明了我们方法的最先进的。我们还表明,由于更好地使用语义,我们的方法可以在低资源状态下显著提高性能。
简介
知识图谱(KG),如Wikidata和Freebase (Bollacker et al, 2008),由事实三元组组成。KG对人类和机器都是有用的资源。(头实体,关系,尾实体)形式的三元组,其中关系涉及头和尾实体,已被用于各种各样的应用,例如问题回答(Guu et al;Hao等人,2017)和网络搜索(Xiong等人,2017)。不完整性一直是KG中的一个长期问题(Carlson et al, 2010),阻碍了其在现实应用中的广泛采用。
KG补全旨在预测事实三元组中缺失的实体或关系。现有三元组中的结构模式有助于预测缺失的元素(Bordes et al, 2013;Sun等人,2019)。例如,可以学习组合模式,根据两个连续的mother_Of关系预测关系grandmother_Of。除了结构信息,实体和关系之间的语义相关性对于推断具有相似含义的实体或关系也是至关重要的(An et al, 2018;Yao等,2019;Wang et al, 2021)。例如,如果两个实体之间存在关系CEO_Of,则关系employee_Of也存在。有两种KG补全方法,属于不同的学习范式。首先,基于结构的方法将实体和关系视为节点和边,并使用图嵌入方法来学习它们的表示。其次,基于语义的方法通过语言模型对实体和关系的文本描述进行编码。虽然结构和语义对KG的补全都很重要,但现有方法同时处理结构和语义信息并非易事。
在本文中,我们提出了一种用于知识图补全的联合语言语义和结构嵌入方法——LASS,它将语义和结构结合在一个KG三元组中。LASS通过微调预训练语言模型(LM),将一个三元组嵌入到一个向量空间中。LASS包括语义嵌入和结构嵌入。语义嵌入捕获三元组的语义,这对应于预先训练的LM对三元组的自然语言描述的向前传递。结构嵌入的目的是重构语义嵌入中的结构,语义嵌入对应于通过LM的反向传播优化概率结构损失。直观地说,结构化损失将两个实体之间的关系视为实体嵌入之间的转换。在一系列KG补全基准测试中,LASS的表现优于现有方法。我们进一步评估了低资源环境下的LASS,发现它比其他方法数据效率更高。原因是我们的方法在训练数据中利用了语义信息和结构信息。
我们的主要贡献:
- 我们设计了一种自然语言嵌入方法LASS,该方法集成了KG的结构信息和语义信息,用于KG补全。我们通过微调预训练的LMs w.r.t.结构化损失来训练LASS,其中LMs的前向传递捕获语义,损失重建结构。该方法由KG模块和LM模块组成,揭示了KG模块与深度语言表示之间的联系,推进了这两个领域交叉的研究。
- 我们在两个KG补全任务,链路预测和三重组分类上评估了LASS,并获得了最先进的性能。研究结果表明,语义和结构的捕获对于理解KG至关重要,研究结果对许多下游知识驱动应用都有帮助。
- 我们表明,与现有方法相比,我们可以显著提高低资源设置下的性能,这要归功于语义知识的改进迁移。
2、LASS
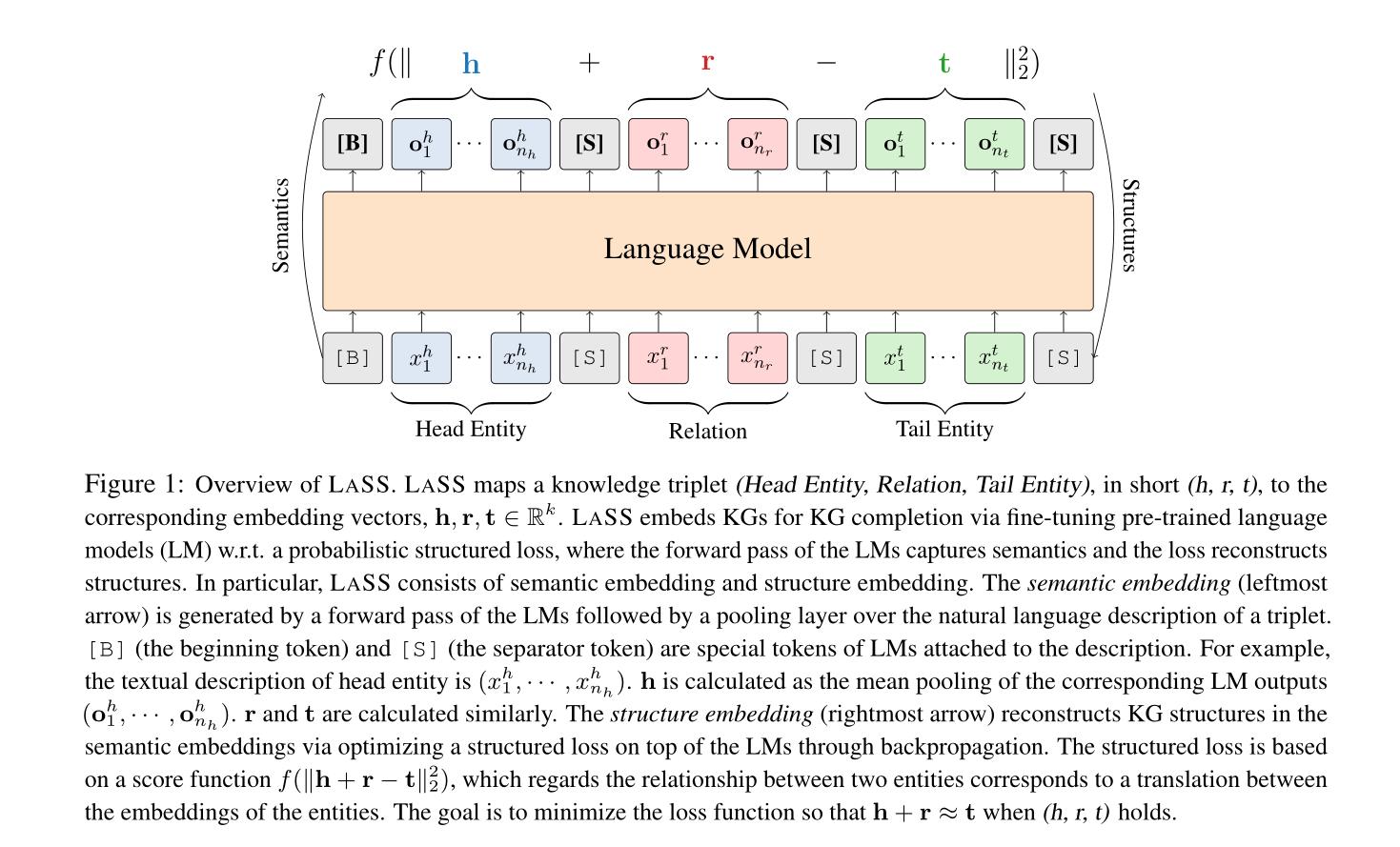
我们介绍LASS,用自然语言嵌入知识图谱的语义和结构。如图1所示,LASS包含了两种嵌入:语义嵌入和结构嵌入。语义嵌入捕获了KG三元组自然语言描述中的语义。结构嵌入在语义嵌入的基础上进一步重构了KG的结构信息。LASS通过对预训练好的语言模型(LM) w.r.t.结构化损失进行微调,将KG嵌入到向量空间中,其中前向传递进行语义嵌入,结构化损失优化进行结构嵌入。
一个三元组KG记为
G
G
G,
G
G
G的每个三元组以
(
h
,
r
,
t
)
(h, r, t)
(h,r,t)的形式表示,其中
h
,
t
∈
E
h,t∈E
h,t∈E,
r
∈
R
r∈R
r∈R。
E
E
E是实体的集合,
R
R
R是关系的集合。头实体
h
h
h、关系
r
r
r和尾实体
t
t
t之间的语义相似性对于补全一个事实三元组至关重要。例如,给定$h =
‘
"
B
o
b
D
y
l
a
n
"
‘
和
`" Bob Dylan "`和
‘"BobDylan"‘和r =
‘
"
w
a
s
b
o
r
n
i
n
"
‘
,任务是预测缺失的
`" was born in "`,任务是预测缺失的
‘"wasbornin"‘,任务是预测缺失的t$,其中候选是" Duluth "和" Apple "。“Bob Dylan”和“Duluth”之间的语义相似度,以及“was born in”和“Duluth”之间的相似度应该比“Apple”之间的相似度要大,因为“Duluth”是标准的答案。预训练的LMs通过对大规模文本语料库的预训练来捕获自然语言中丰富的语义。这启发我们使用存储在LM参数中的语义来编码三元组的语义。
形式上,对于三元组 ( h , r , t ) (h, r, t) (h,r,t),实体 ( h , t ) (h,t) (h,t)和关系 ( r ) (r) (r)都由它们对应的自然语言描述来表示。头实体 h h h表示为一系列符号, T h = ( x 1 h , … , x n h h ) T^h = (x^h_1,\\ldots,x^h_n_h) Th=(x1h,…,xnhh)来描述实体。同样, T t = ( x 1 t , … , x n t t ) T^t = (x^t_1,\\ldots,x^t_n_t) Tt=(x1t,…,xntt)表示尾实体 t t t。 T r = ( x 1 r , … , x n r r ) T^r = (x^r_1,\\ldots,x^r_n_r) Tr=(x1r,…,xnrr)表示关系 r r r。我们通过LM的前向传递生成语义嵌入,如图1所示。知识图谱补全任务需要显式地建模头实体、关系和尾实体的依赖关系。例如,在链接预测任务中,头实体与尾实体之间的连接以及关系与尾实体之间的连接都有助于对尾实体的预测。因此,我们使用 T h , T r , T t T^h,T^r,T^t Th,Tr,Tt的连接作为LM的输入序列,并使用 T h , T r , T t T^h,T^r,T^t Th,Tr,Tt中每个token的输出表示的进行平均池化,从LM的前向传播作为 h , r , t ∈ R k h, r, t∈\\mathbbR^k h,r,t∈Rk,其中 k k k是嵌入向量的维数。
更具体地说,我们按照以下格式构造输入序列:[B]
T
h
T^h
Th [S]
T
r
T^r
Tr [S]
T
t
T^t
Tt [S],其中[B]是添加在每个输入序列前面的一个特殊符号,[S]是一个特殊的分隔符。对于不同的LM,特殊的token是不同的。例如,对于BERT, [B]和[S]分别实现为[CLS]和[SEP] (Devlin et al, 2019)。然后将输入序列转换为LM的相应输入嵌入。例如,BERT的输入嵌入是token嵌入、段嵌入和位置嵌入的和。输入嵌入被输入到LM中。我们在LM的输出层上添加了一个均值池化层,并对
T
h
T^h
Th中每个token的输出表示进行均值池化,即
(
o
1
h
,
…
,
o
n
h
h
)
(o^h_1,\\ldots,o^h_n_h)
(o1h,…,onhh),得到如图1所示的
h
h
h。我们用同样的方法得到
r
r
r和
t
t
t。维数
k
k
k等于LM的隐藏大小。
3、实验
实验结果
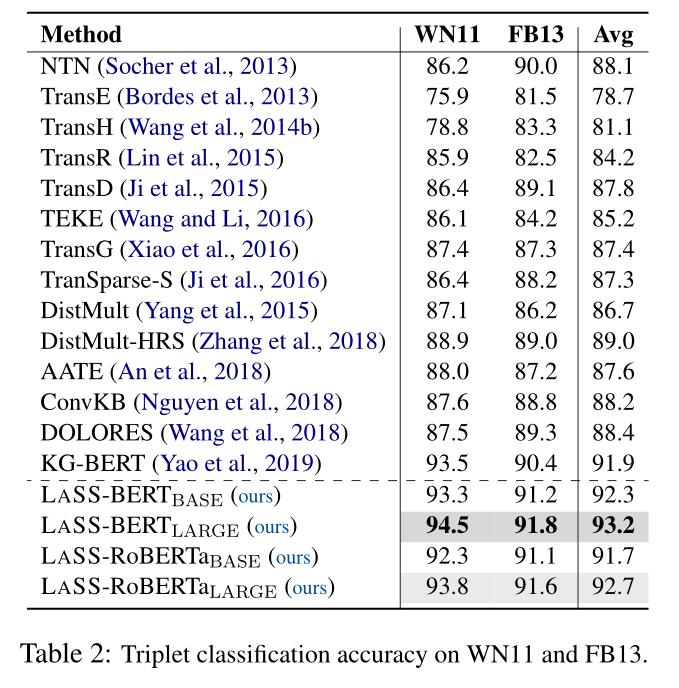

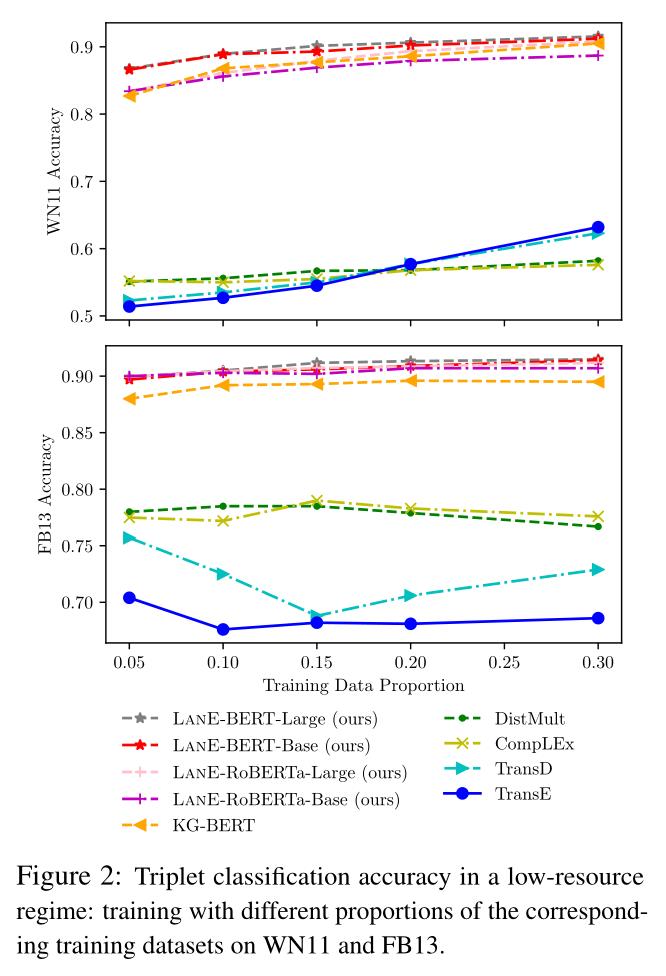
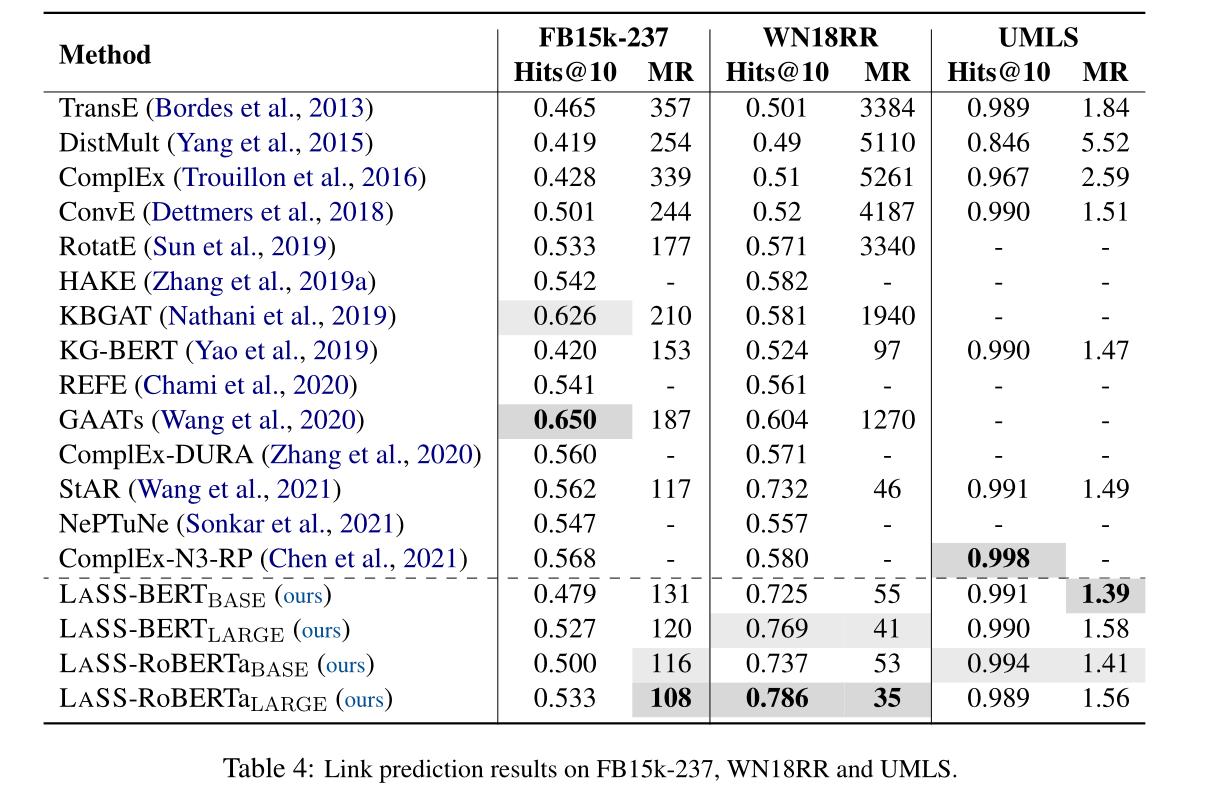
我们还注意到,LASS在FB15k-237上只产生了适度的Hits@10。主要原因是,与表1所示的其他链路预测数据集相比,FB15k-237呈现出更复杂的实体之间的关系。因此,更复杂的结构性损失有望使LASS获得进一步的改善。


【论文速递 | 精选】

论文速递ECCV2022 - 密集高斯过程的小样本语义分割
【论文速递】ECCV2022 - 密集高斯过程的小样本语义分割
【论文原文】:Dense Gaussian Processes for Few-Shot Segmentation
获取地址:https://arxiv.org/pdf/2110.03674.pdf
博主关键词: 小样本学习,语义分割,高斯过程
推荐相关论文:
- 无
摘要:
小样本分割是一项具有挑战性的密集预测任务,它需要分割一个新的查询图像,只给予一个小的注释支持集。因此,关键问题是设计一种方法,可以从支持集中聚合详细信息,同时对外观和上下文的巨大变化具有健壮性。为此,我们提出了一种基于密集高斯过程(GP)回归的小样本分割方法。给定支持集,我们的密集GP学习从局部深度图像特征到掩码值的映射,能够捕获复杂的外观分布。 此外,它提供了一种捕获不确定性的原则性手段,作为CNN解码器获得的最终分割的另一个强大线索。我们不再使用一维掩码输出,而是进一步利用我们方法的端到端学习功能来为GP学习高维输出空间。我们的方法在PASCAL-5i和COCO-20i基准上达到了SOTA,在COCO-20i 5-shot条件下实现了+8.4 mIoU的绝对增益。此外,当增加支持集大小时,我们方法的分割质量可以优雅地扩展,同时实现健壮的跨数据集传输。代码和训练过的模型可以在https://github.com/joakimjohnander/dgpnet上找到。
简介:
语义类[28]的图像小样本分割(FSS)近年来受到越来越多的关注。其目的是基于少量带注释的训练样本(通常称为支持集)对新的查询图像进行分割。因此,FSS方法需要从支持集中提取信息,以便准确地分割给定的查询图像。这个问题非常具有挑战性,因为查询图像可能会呈现与支持集中所表示的完全不同的视图、上下文、场景和对象。
任何FSS框架的核心组件都是从支持集中提取信息以指导查询图像分割的机制。然而,这个模块的设计提出了几个挑战。首先,它需要从支持集中聚合详细但可概括的信息,这**需要灵活的表示** 。其次,FSS方法应该有效地利用更大的支持集,在 增加其大小时实现可扩展的分割性能 。虽然乍一看可能微不足道,但这已被证明是许多最先进的方法的主要障碍,如图1所示。第三,该方法必须在支持集中不包含外观的情况下进行查询 。即使在这种常见情况下,为了实现稳健的预测,该方法也需要评估支持图像中信息的相关性,以便在必要时优雅地恢复到例如学习的分割先验。

我们通过使用高斯过程(GPs)在支持集中密集聚集信息来解决上述挑战。具体来说,我们使用GP学习密集局部深度特征向量与其对应掩码值之间的映射。 基于相应特征向量之间的相似性,假设掩码值具有联合高斯分布,并具有协方差。这允许我们从支持集中提取详细的关系,并具有建模复杂的非线性映射的能力。作为一个非参数模型[25],GP进一步有效地受益于额外的支持样本,因为所有给定的数据都被保留。如图1所示,该方法的分割精度随着支持样本数量的增加而不断提高。最后,GP的预测协方差提供了基于支持集中局部特征相似性的不确定性的原则性度量。
我们的FSS方法通过情景训练进行端到端学习,将GP视为神经网络中的一层。 这进一步允许我们了解GP的输出空间。为此,我们用神经网络对给定的支持掩码进行编码,以实现多维输出表示。为了生成最终的掩码,我们的解码器模块使用了预测的平均查询编码,以及协方差信息。因此,我们的解码器能够推理不确定性时,融合预测掩码编码与学习分割先验。最后,我们进一步改进了FSS方法,在多个尺度上整合密集GPs。
我们在两个基准上进行了综合实验:PASCAL-5i[28]和COCO-20i[22]。我们提出的DGPNet优于现有的5- shot方法,在两个基准上都设定了新的最先进的技术。当使用ResNet101主干时,我们的DGPNet在具有挑战性的COCO-20i基准上实现了5-shot分割的绝对增益8.4,与文献中报道的最佳结果相比。我们进一步展示了DGPNet方法从COCO-20i到PASCAL的跨数据集传输能力,并进行了详细的消融研究,以探测我们贡献的有效性。

以上是关于论文速递COLING 2022 - 联合语言语义和结构嵌入用于知识图补全的主要内容,如果未能解决你的问题,请参考以下文章
论文速递IJCV2022 - CRCNet:基于交叉参考和区域-全局条件网络的小样本分割
论文速递ECCV2022 - 开销聚合与四维卷积Swin Transformer_小样本分割
论文精读COLING 2022-KiPT: Knowledge-injected Prompt Tuning for Event Detection
论文速递ICCV2021 - 基于超相关压缩实现实时高精度的小样本语义分割