OpenGL ES 学习教程(十七) Unity GPU Instance 原理及 GLES 实现
Posted _Captain
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了OpenGL ES 学习教程(十七) Unity GPU Instance 原理及 GLES 实现相关的知识,希望对你有一定的参考价值。
目录
2.static/dynamic batch与GPU Instance异同
4.1 查询当前系统GLES支持的Uniform变量个数上限
我们口中常说的Unity batch有2种形式:
- static/dynamic batch
- GPU Instance
static/dynamic 都是在软件层面上对Mesh进行合并,而GPU Instance则是图形框架提供的功能,任何游戏引擎都可以实现上面2种形式的batch。
这次我们就来探究下Unity GPU Instance的原理及实现。
1.为什么要合并DrawCall?
首先需要了解的是CPU与GPU交互,是CS架构的。
我们口头上常说的一个DrawCall,指的是从指定GPU Program,指定各种参数,上传纹理,顶点数据到GPU,最后调用glDrawxxx 这个接口命令GPU开始渲染这一系列过程。
这一系列过程都由CPU进行调用执行,整个游戏的渲染过程,就是一个While死循环,不断的执行上面的一系列过程。
1个DrawCall就只需要执行一次,10000个DrawCall,就需要执行10000次。
执行次数越多,自然CPU的消耗就越高。
2.static/dynamic batch与GPU Instance异同
相同点:
- 目标相同 减DrawCall
不同点:
- static/dynamic batch:针对相同材质,不同或相同Mesh,进行合并的操作,是逻辑层的功能。
- GPU Instance:针对同一个Mesh多次渲染,是图形框架提供的功能。
3.图形框架提供的接口介绍
GPU Instance是OpenGL ES 3.0版本才开始提供的功能,之前博客里面使用到的都是OpenGL ES 2.0版本,在3.0版本里,新增了以下改动。
3.1 接口方面修改
与渲染单个物体使用的 glDrawArrays / glDrawElements 对应,OpenGL提供了多实例渲染的接口 glDrawArraysInstanced / glDrawElementsInstanced。
看下2种接口的定义:
GL_APICALL void GL_APIENTRY glDrawArrays (GLenum mode, GLint first, GLsizei count);
GL_APICALL void GL_APIENTRY glDrawElements (GLenum mode, GLsizei count, GLenum type, const void *indices);GL_APICALL void GL_APIENTRY glDrawArraysInstanced (GLenum mode, GLint first, GLsizei count, GLsizei instancecount);
GL_APICALL void GL_APIENTRY glDrawElementsInstanced (GLenum mode, GLsizei count, GLenum type, const void *indices, GLsizei instancecount);最后多出的参数 instancecount,表示需要渲染的实例个数。
3.2 Shader代码修改
在Shader中新增了 gl_InstanceID 变量表示当前渲染的实例 index。
在代码中传入多个实例的数组数据后,就可以用 gl_InstanceID 作为下标取出。
例如:
uniform mat4 m_mvps[50];//mvp矩阵数组,存储每个立方体的mvp。然后以gl_InstanceID为下标来取。
void main()
vec4 pos=vec4(m_position,1);
mat4 mvp = m_mvps[gl_InstanceID];//gl_InstanceID是递增的
......
4.实例测试 glDrawArraysInstanced
以 OpenGL ES 学习教程(九) 油腻的效果 Lighting Maps 高光贴图 这篇文章进行修改。(注意项目里更新了OpenGL ES 3.0的库)。
4.1 查询当前系统GLES支持的Uniform变量个数上限
uniform mat4 m_mvps[50];//mvp矩阵数组,存储每个立方体的mvp。然后以gl_InstanceID为下标来取。我这里将50个实例的MVP矩阵 以 uniform 数组形式传入到顶点Shader中,但是在glsl中 uniform 变量是有个数上限的,这里 50 个实例的mvp数组,就占用了 50 个 uniform 变量。
是的,uniform 数组中的一个元素,就占了一个 uniform 名额。
通过下面的代码,查询当前系统支持的 uniform 个数上限。
//获取顶点shader uniform最大数量。gles3 这边查询到是256,那么GLProgram_Cube里有3个变量数组,最多创建85个Instance。应该减少数组,将运算放到顶点shader中。
GLint maxVertUniformsVect = 0;
glGetIntegerv(GL_MAX_VERTEX_UNIFORM_VECTORS, &maxVertUniformsVect);我电脑上是256个。

本次测试实例,顶点Shader有 3 个 Uniform数组。
uniform mat4 m_mvps[50];//mvp矩阵数组,存储每个立方体的mvp。然后以gl_InstanceID为下标来取。
uniform mat4 m_models[50];
uniform mat4 m_modelsofnormal[50];那么最多可以绘制的实例数量为85个。
4.2 顶点Shader 准备接收数组数据
顶点Shader 修改如下:
//GLProgram_Cube.h Line62
const char* vertexShader=
"precision lowp float;"
"attribute vec3 m_position;"
//接受数组数据
"uniform mat4 m_mvps[50];"//mvp矩阵数组,存储每个立方体的mvp。然后以gl_InstanceID为下标来取。
"uniform mat4 m_models[50];"
"uniform mat4 m_modelsofnormal[50];"
"attribute vec3 m_normal;"
"varying vec3 out_normal;"
"varying vec3 out_fragpos;"
"attribute vec2 m_uv;"
"varying vec2 m_outUV;"
"void main()"
""
" vec4 pos=vec4(m_position,1);"
//从数组中取出数据
" mat4 mvp = m_mvps[gl_InstanceID];"//gl_InstanceID是递增的
" mat4 model = m_models[gl_InstanceID];"
" mat4 modelofnormal = m_modelsofnormal[gl_InstanceID];"
" gl_Position=mvp*pos;"
" out_normal=mat3( modelofnormal) * m_normal ;"
" out_fragpos=vec3(model*vec4(m_position,1));"
" m_outUV=m_uv;"
""
;4.3 C++代码向顶点Shader传入数据
修改C++部分代码如下:
//MyApp.h Line73
m_programCube.begin();
......
//对应顶点Shader uniform数组
glm::mat4 mvps[50];
glm::mat4 models[50];
glm::mat4 modelsofnormal[50];
int index = 0;
float offset = 5.0f;
for (int x = -5; x < 5; x++)
for (int y = -2; y < 3; y++)
//model;
glm::mat4 trans = glm::translate(glm::vec3(offset*x, offset*y, 0));
glm::mat4 scale = glm::scale(glm::vec3(1.5f, 1.5f, 1.5f));
glm::mat4 rotation = glm::eulerAngleYXZ(glm::radians(0.0f), glm::radians(0.0f), glm::radians(0.0f));
glm::mat4 model = trans*scale*rotation;
glm::mat4 mvp = proj*view*model;
mvps[index] = mvp;
models[index] = model;
glm::mat4 modelofnormal = glm::transpose(glm::inverse(model));
modelsofnormal[index] = modelofnormal;
index++;
//向顶点Shader 传递数组数据
for (unsigned int i = 0; i < 50; i++)
std::stringstream ss;
std::string index;
ss << i;
index = ss.str();
m_programCube.setMat4(("m_mvps[" + index + "]").c_str(), mvps[i]);
m_programCube.setMat4(("m_models[" + index + "]").c_str(), models[i]);
m_programCube.setMat4(("m_modelsofnormal[" + index + "]").c_str(), modelsofnormal[i]);
......
//一次性绘制50个实例
glDrawArraysInstanced(GL_TRIANGLES, 0, 6 * 6, 50);
4.4 运行效果
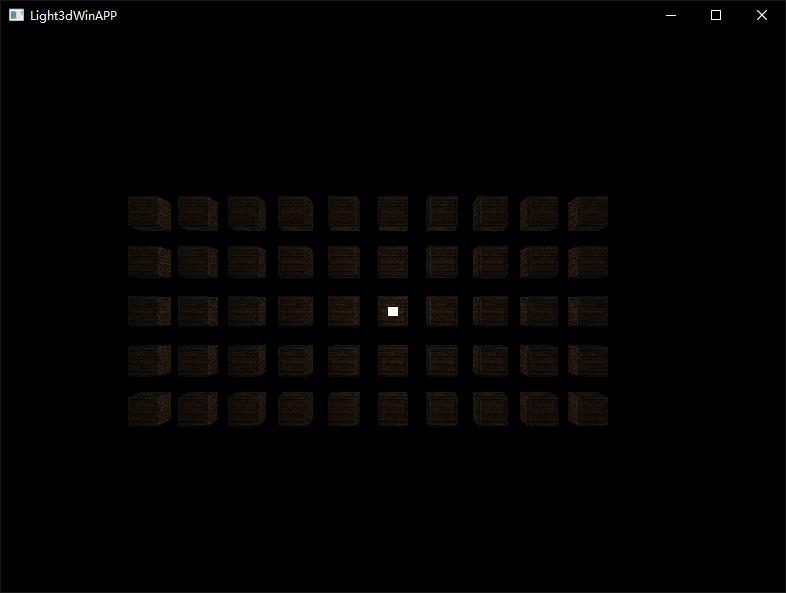
实际运行效果如上图,这是一个DrawCall完成的。
5.缺点&优化
使用uniform 数组的形式,受限制与 uniform 变量个数上限,本文的例子,一次不能超过85个箱子。
优化的方式就是减少Uniform 变量个数,例如只传输 model 矩阵数组到顶点shader,mvp和 modelsofnormal 都在顶点shader中进行计算得到,这样可以一次性绘制200多个。
缺点就是突破不了256个,那在草地的场景里,就使不上劲了。
Opengl中提供了更为先进的API,下一篇再介绍。
6.实例代码下载
https://download.csdn.net/download/cp790621656/145033527.参考资料
https://www.khronos.org/registry/OpenGL-Refpages/es3.0/
https://learnopengl-cn.github.io/04%20Advanced%20OpenGL/10%20Instancing/
以上是关于OpenGL ES 学习教程(十七) Unity GPU Instance 原理及 GLES 实现的主要内容,如果未能解决你的问题,请参考以下文章