Spark Streaming 编程指南
Posted 顧棟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark Streaming 编程指南相关的知识,希望对你有一定的参考价值。
Spark Streaming Programming Guide
原文地址:https://spark.apache.org/docs/2.3.3/streaming-programming-guide.html
文章目录
- Spark Streaming Programming Guide
- Overview
- A Quick Example
- Basic Concepts
- Linking
- Initializing StreamingContext
- Discretized Streams (DStreams)
- Input DStreams and Receivers
- Transformations on DStreams
- Output Operations on DStreams
- DataFrame and SQL Operations
- MLlib Operations
- Caching / Persistence
- Checkpointing
- Accumulators, Broadcast Variables, and Checkpoints
- Deploying Applications
- Monitoring Applications
- Performance Tuning
- Fault-tolerance Semantics
- Where to Go from Here
Overview
Spark Streaming 是核心 Spark API 的扩展,支持实时数据流的可扩展、高吞吐量、容错流处理。 数据可以从许多来源(如 Kafka、Flume、Kinesis 或 TCP 套接字)获取,并且可以使用复杂的算法进行处理,这些算法用高级函数(如 map、reduce、join 和 window)表示。 最后,处理后的数据可以推送到文件系统、数据库和实时仪表板。 事实上,您可以将 Spark 的机器学习和图形处理算法应用于数据流。

在内部,它的工作原理如下。 Spark Streaming 接收实时输入数据流并将数据分成批次,然后由 Spark 引擎处理以批量生成最终的结果流。
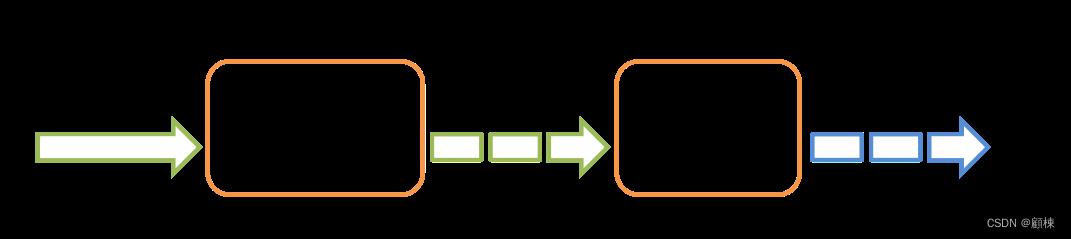
Spark Streaming 提供了一种称为离散流或 DStream 的高级抽象,它表示连续的数据流。 DStream 可以从来自 Kafka、Flume 和 Kinesis 等源的输入数据流创建,也可以通过对其他 DStream 应用高级操作来创建。 在内部,一个 DStream 表示为一个 RDD 序列。
本指南向您展示如何开始使用 DStreams 编写 Spark Streaming 程序。 您可以使用 Scala、Java 或 Python(在 Spark 1.2 中引入)编写 Spark Streaming 程序,所有这些都在本指南中介绍。 您将在本指南中找到标签,让您在不同语言的代码片段之间进行选择。
Note: There are a few APIs that are either different or not available in Python. Throughout this guide, you will find the tag Python API highlighting these differences.
A Quick Example
在我们详细介绍如何编写自己的 Spark Streaming 程序之前,让我们快速看一下简单的 Spark Streaming 程序是什么样的。 假设我们要计算从侦听 TCP 套接字的数据服务器接收到的文本数据中的字数。 您需要做的如下。
首先,我们将 Spark Streaming 类的名称和一些来自 StreamingContext 的隐式转换导入到我们的环境中,以便为我们需要的其他类(如 DStream)添加有用的方法。 StreamingContext 是所有流功能的主要入口点。 我们创建一个带有两个执行线程的本地StreamingContext,批处理间隔为 1 秒。
import org.apache.spark._
import org.apache.spark.streaming._
import org.apache.spark.streaming.StreamingContext._ // not necessary since Spark 1.3
// Create a local StreamingContext with two working thread and batch interval of 1 second.
// The master requires 2 cores to prevent a starvation scenario.
val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(conf, Seconds(1))
使用这个上下文,我们可以创建一个表示来自 TCP 源的流数据的 DStream,指定为主机名(例如 localhost)和端口
val lines = ssc.socketTextStream("localhost", 9999)
这lines DStream 表示将从数据服务器接收的数据流。 此 DStream 中的每条记录都是一行文本。 接下来,我们要按空格字符将行拆分为单词。
val words = lines.flatMap(_.split(" "))
flatMap 是一个一对多的 DStream 操作,它通过从源 DStream 中的每条记录生成多个新记录来创建一个新的 DStream。 在这种情况下,每一行将被分成多个单词,单词流表示为words DStream。 接下来,我们要计算这些单词。
import org.apache.spark.streaming.StreamingContext._ // not necessary since Spark 1.3
// Count each word in each batch
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
// Print the first ten elements of each RDD generated in this DStream to the console
wordCounts.print()
words DStream 被进一步映射(一对一转换)到 (word, 1) 对的 DStream,然后对其进行归约以获得每批数据中词的频率。 最后, wordCounts.print() 将打印每秒生成的一些计数。
请注意,当执行这些行时,Spark Streaming 仅设置它在启动时将执行的计算,并且尚未开始真正的处理。 在所有转换设置完成后开始处理,我们最后调用
ssc.start() // Start the computation
ssc.awaitTermination() // Wait for the computation to terminate
完整的代码可以在 Spark Streaming 示例 NetworkWordCount 中找到。
如果您已经下载并构建了 Spark,则可以按如下方式运行此示例。 您首先需要运行 Netcat(大多数类 Unix 系统中的一个小工具)作为数据服务器,使用
$ nc -lk 9999
然后,在不同的终端中,您可以使用
$ ./bin/run-example streaming.NetworkWordCount localhost 9999
然后,在运行 netcat 服务器的终端中键入的任何行都会被计数并每秒打印在屏幕上。 它看起来像下面这样。
# TERMINAL 1:
# Running Netcat
$ nc -lk 9999
hello world
...
# TERMINAL 2: RUNNING NetworkWordCount
$ ./bin/run-example streaming.NetworkWordCount localhost 9999
...
-------------------------------------------
Time: 1357008430000 ms
-------------------------------------------
(hello,1)
(world,1)
...
Basic Concepts
接下来,我们将超越简单的示例,详细介绍 Spark Streaming 的基础知识。
Linking
与 Spark 类似,Spark Streaming 可通过 Maven Central 获得。 要编写您自己的 Spark Streaming 程序,您必须将以下依赖项添加到您的 SBT 或 Maven 项目中。
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.3.3</version>
</dependency>
要从 Spark Streaming 核心 API 中不存在的 Kafka、Flume 和 Kinesis 等来源摄取数据,您必须将相应的工件spark-streaming-xyz_2.11添加到依赖项中。 例如,一些常见的如下。
| Source | Artifact |
|---|---|
| Kafka | spark-streaming-kafka-0-10_2.11 |
| Flume | spark-streaming-flume_2.11 |
| Kinesis | spark-streaming-kinesis-asl_2.11 [Amazon Software License] |
有关最新列表,请参阅 Maven 存储库以获取支持的源和工件的完整列表。
Initializing StreamingContext
要初始化 Spark Streaming 程序,必须创建一个 StreamingContext 对象,它是所有 Spark Streaming 功能的主要入口点。
可以从 SparkConf 对象创建 StreamingContext 对象。
import org.apache.spark._
import org.apache.spark.streaming._
val conf = new SparkConf().setAppName(appName).setMaster(master)
val ssc = new StreamingContext(conf, Seconds(1))
appName 参数是您的应用程序在集群 UI 上显示的名称。
master 是 Spark、Mesos 或 YARN 集群 URL,或者是一个特殊的**“local[]”**字符串,以在本地模式下运行。 实际上,在集群上运行时,您不会希望在程序中对 master 进行硬编码,而是使用 spark-submit 启动应用程序并在那里接收它。 但是,对于本地测试和单元测试,您可以通过“local[]”在进程内运行 Spark Streaming(检测本地系统中的核心数)。 请注意,这会在内部创建一个 SparkContext(所有 Spark 功能的起点),它可以作为ssc.sparkContext访问。
必须根据应用程序的延迟要求和可用集群资源设置批处理间隔。 有关更多详细信息,请参阅性能调整部分。
StreamingContext 对象也可以从现有的 SparkContext 对象创建。
import org.apache.spark.streaming._
val sc = ... // existing SparkContext
val ssc = new StreamingContext(sc, Seconds(1))
定义上下文后,您必须执行以下操作。
- 通过创建输入 DStream 来定义输入源。
- 通过对 DStream 应用转换和输出操作来定义流计算。
- 开始接收数据并使用
streamingContext.start()进行处理。 - 使用
streamingContext.awaitTermination()等待处理停止(手动或由于任何错误)。 - 可以使用
streamingContext.stop()手动停止处理。
Points to remember:
- 一旦上下文开始,就不能设置或添加新的流计算。
- 一旦上下文停止,就不能重新启动。
- 一个 JVM 中只能同时激活一个 StreamingContext。
- StreamingContext 上的 stop() 也会停止 SparkContext。 要仅停止 StreamingContext,请将名为
stopSparkContext的stop()的可选参数设置为 false。 - 一个 SparkContext 可以重复用于创建多个 StreamingContext,只要在创建下一个 StreamingContext 之前停止前一个 StreamingContext(不停止 SparkContext)。
Discretized Streams (DStreams)
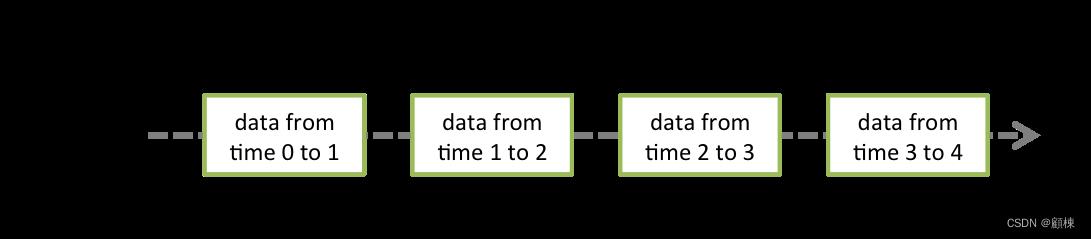
Discretized Stream 或 DStream 是 Spark Streaming 提供的基本抽象。 它表示一个连续的数据流,要么是从源接收到的输入数据流,要么是对输入流进行转换后生成的经过处理的数据流。 在内部,DStream 由一系列连续的 RDD 表示,这是 Spark 对不可变的分布式数据集的抽象(有关详细信息,请参阅 Spark 编程指南)。 DStream中的每个RDD都包含一定间隔的数据,如下图所示。
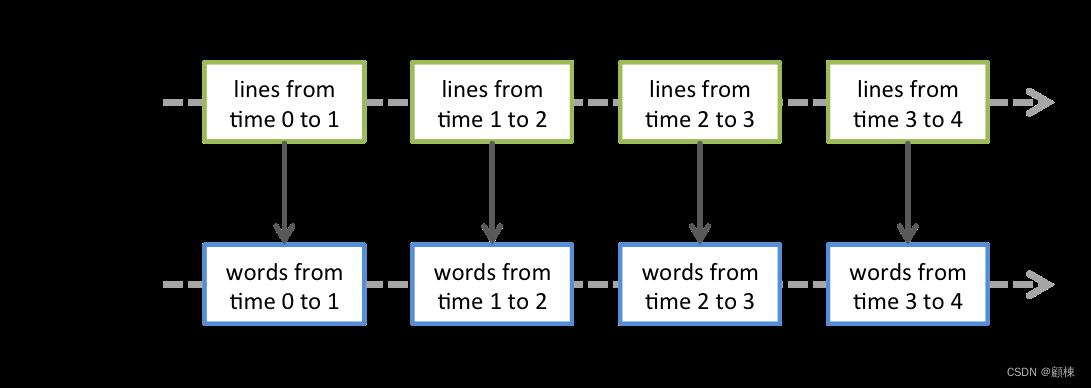
应用于 DStream 的任何操作都将转换为对底层 RDD 的操作。 例如,在前面将行流转换为单词的示例中,对lines DStream 中的每个 RDD 应用 flatMap操作以生成words DStream 的 RDD。 如下图所示。
这些底层 RDD 转换由 Spark 引擎计算。 DStream 操作隐藏了大部分这些细节,并为开发人员提供了更高级别的 API 以方便使用。 这些操作将在后面的部分中详细讨论。
Input DStreams and Receivers
输入 DStream 是表示从流式源接收的输入数据流的 DStream。 在这个快速示例中,lines 是一个输入 DStream,因为它表示从 netcat 服务器接收到的数据流。 每个输入 DStream(文件流除外,本节稍后讨论)都与一个Receivers对象相关联,该对象从源接收数据并将其存储在 Spark 的内存中以进行处理。
Spark Streaming 提供了两类内置的流源。
- Basic sources: StreamingContext API 中直接可用的源。 示例:文件系统和套接字连接。
- Advanced sources: Kafka、Flume、Kinesis 等资源可通过额外的实用程序类获得。 这些需要链接额外的依赖项,如 linking 部分所述。
我们将在本节后面讨论每个类别中的一些来源。
请注意,如果您想在您的流应用程序中并行接收多个数据流,您可以创建多个输入 DStream(在Performance Tuning部分中进一步讨论)。 这将创建多个接收器,它们将同时接收多个数据流。 但请注意,Spark worker/executor 是一项长时间运行的任务,因此它占用了分配给 Spark Streaming 应用程序的核心之一。 因此,重要的是要记住,需要为 Spark Streaming 应用程序分配足够的内核(或线程,如果在本地运行)来处理接收到的数据,以及运行接收器。
Points to remember
- 在本地运行 Spark Streaming 程序时,请勿使用“local”或“local[1]”作为主 URL。 这些中的任何一个都意味着只有一个线程将用于在本地运行任务。 如果您使用的是基于接收器(例如套接字、Kafka、Flume 等)的输入 DStream,那么将使用单线程来运行接收器,不留任何线程来处理接收到的数据。 因此,在本地运行时,始终使用“local[n]”作为主 URL,其中 n > 要运行的接收器数量(请参阅 Spark 属性了解如何设置主控)。
- 将逻辑扩展到在集群上运行,分配给 Spark Streaming 应用程序的核心数量必须大于接收器的数量。 否则系统将接收数据,但无法处理它。
Basic Sources
我们已经看过 快速示例 中的 ssc.socketTextStream(...)从通过 TCP 套接字连接接收的文本数据创建 DStream。 除了套接字之外,StreamingContext API 还提供了从文件作为输入源创建 DStream 的方法。
File Streams
为了从与 HDFS API 兼容的任何文件系统(即 HDFS、S3、NFS 等)上的文件读取数据,可以通过 StreamingContext.fileStream[KeyClass, ValueClass, InputFormatClass]来创建 DStream。
文件流不需要运行接收器,因此不需要分配任何内核来接收文件数据。
对于简单的文本文件,最简单的方法是 StreamingContext.textFileStream(dataDirectory).
streamingContext.fileStream[KeyClass, ValueClass, InputFormatClass](dataDirectory)
对于文本文件
streamingContext.textFileStream(dataDirectory)
How Directories are Monitored如何监控目录
Spark Streaming 将监视目录dataDirectory并处理在该目录中创建的所有文件。
- 可以监控一个简单的目录,例如
"hdfs://namenode:8040/logs/"。直接在此类路径下的所有文件将在发现时进行处理。 - 可以提供 POSIX glob 模式,例如
"hdfs://namenode:8040/logs/2017/ *"。在这里,DStream 将包含与该模式匹配的目录中的所有文件。也就是说:它是目录的模式,而不是目录中的文件。 - 所有文件必须采用相同的数据格式。
- 一个文件被认为是基于其修改时间的时间段的一部分,而不是它的创建时间。
- 处理后,对当前窗口内文件的更改不会导致文件被重新读取。也就是说:更新被忽略。
- 目录下的文件越多,扫描更改所需的时间就越长——即使没有文件被修改。
- 如果使用通配符来标识目录,例如
“hdfs://namenode:8040/logs/2016-*”,重命名整个目录以匹配路径会将目录添加到监控目录列表中。只有目录中修改时间在当前窗口内的文件才会包含在流中。 - 调用 [
FileSystem.setTimes()](https://hadoop.apache.org/docs/current/api/org/apache/hadoop/fs/FileSystem.html#setTimes-org.apache.hadoop.fs。修复时间戳的 Path-long-long-) 是一种在以后的窗口中拾取文件的方法,即使其内容没有更改。
Using Object Stores as a source of data 使用对象存储作为数据源
诸如 HDFS 之类的“完整”文件系统倾向于在创建输出流后立即对其文件设置修改时间。打开文件时,甚至在数据完全写入之前,它也可能包含在 DStream 中 - 之后在同一窗口中对文件的更新将被忽略。也就是说:可能会错过更改,并且可能会从流中省略数据。
为保证在窗口中获取更改,请将文件写入不受监控的目录,然后在输出流关闭后立即将其重命名为目标目录。如果重命名的文件在创建窗口期间出现在扫描的目标目录中,则将拾取新数据。
相比之下,Amazon S3 和 Azure 存储等对象存储的重命名操作通常很慢,因为数据实际上是被复制的。此外,重命名的对象可能会将 rename() 操作的时间作为其修改时间,因此可能不会被视为原始创建时间所暗示的窗口的一部分。
需要对目标对象存储进行仔细测试,以验证存储的时间戳行为是否与 Spark Streaming 预期的一致。直接写入目标目录可能是通过所选对象存储流式传输数据的适当策略。
有关此主题的更多详细信息,请参阅 Hadoop 文件系统规范。
Streams based on Custom Receivers
可以使用通过自定义接收器接收到的数据流来创建 DStream。 有关详细信息,请参阅 自定义接收器指南。
Queue of RDDs as a Stream
为了使用测试数据测试 Spark Streaming 应用程序,还可以使用streamingContext.queueStream(queueOfRDDs)创建基于 RDD 队列的 DStream。 每个推入队列的 RDD 都会被视为 DStream 中的一批数据,像流一样处理。
For more details on streams from sockets and files, see the API documentations of the relevant functions in StreamingContext for Scala, JavaStreamingContext for Java, and StreamingContext for Python.
有关来自套接字和文件的流的更多详细信息,请参阅 StreamingContext 中相关函数的 API 文档 用于 Scala,[JavaStreamingContext](https://spark.apache.org/docs/2.3.3/api/java/index.html?org/apache/spark/streaming/api/java/ JavaStreamingContext.html) 和 Python 的 StreamingContext。
Advanced Sources
Python API As of Spark 2.3.3, out of these sources, Kafka, Kinesis and Flume are available in the Python API.
这类源需要与外部非 Spark 库进行交互,其中一些具有复杂的依赖关系(例如 Kafka 和 Flume)。 因此,为了最大限度地减少与依赖项的版本冲突相关的问题,从这些源创建 DStreams 的功能已移至可以 链接 的单独库在必要时明确显示。
请注意,这些高级源在 Spark shell 中不可用,因此无法在 shell 中测试基于这些高级源的应用程序。 如果您真的想在 Spark shell 中使用它们,您必须下载相应的 Maven 工件的 JAR 及其依赖项并将其添加到类路径中。
Some of these advanced sources are as follows.
- Kafka: Spark Streaming 2.3.3 与 Kafka 代理版本 0.8.2.1 或更高版本兼容。 有关详细信息,请参阅 Kafka 集成指南。
- Flume: Spark Streaming 2.3.3 与 Flume 1.6.0 兼容。 有关详细信息,请参阅 Flume 集成指南。
- Kinesis: Spark Streaming 2.3.3 与 Kinesis 客户端库 1.2.1 兼容。 有关详细信息,请参阅 Kinesis 集成指南。
Custom Sources
Python API This is not yet supported in Python.
输入 DStream 也可以从自定义数据源中创建。 您所要做的就是实现一个用户定义的 receiver(请参阅下一节了解它是什么),它可以从自定义源接收数据并将其推送到 Spark。 有关详细信息,请参阅 自定义接收器指南。
Receiver Reliability
根据其可靠性,可以有两种数据源。 源(如 Kafka 和 Flume)允许确认传输的数据。 如果从这些可靠源接收数据的系统正确确认接收到的数据,则可以确保不会因任何类型的故障而丢失数据。 这导致了两种接收器:
- Reliable Receiver - 当数据已被接收并通过复制存储在 Spark 中时,可靠的接收器正确地向可靠的源发送确认。
- Unreliable Receiver - 不可靠的接收器不会向源发送确认。 这可用于不支持确认的来源,甚至在不想或不需要进入确认的复杂性时用于可靠来源。
有关如何编写可靠接收器的详细信息,请参阅 Custom Receiver Guide.
Transformations on DStreams
与 RDD 类似,转换允许修改来自输入 DStream 的数据。 DStreams 支持普通 Spark RDD 上可用的许多转换。 一些常见的如下。
| Transformation | 意义 |
|---|---|
| map(func) | 通过函数 func 传递源 DStream 的每个元素,返回一个新的 DStream。 |
| flatMap(func) | 类似于 map,但每个输入项可以映射到 0 个或多个输出项。 |
| filter(func) | 通过仅选择 func 返回 true 的源 DStream 的记录来返回一个新的 DStream。 |
| repartition(numPartitions) | 通过创建更多或更少的分区来更改此 DStream 中的并行级别。 |
| union(otherStream) | 返回一个新的 DStream,它包含源 DStream 和 otherDStream 中的元素的并集。 |
| count() | 通过计算源 DStream 的每个 RDD 中的元素数,返回一个新的单元素 RDD 的 DStream。 |
| reduce(func) | 通过使用函数func(接受两个参数并返回一个)聚合源DStream 的每个RDD 中的元素,返回一个新的单元素RDD DStream。 该函数应该是关联的和可交换的,以便可以并行计算。 |
| countByValue() | 当在 K 类型元素的 DStream 上调用时,返回 (K, Long) 对的新 DStream,其中每个键的值是它在源 DStream 的每个 RDD 中的频率。 |
| reduceByKey(func, [numTasks]) | 当在 (K, V) 对的 DStream 上调用时,返回 (K, V) 对的新 DStream,其中每个键的值使用给定的 reduce 函数聚合。 注意: 默认情况下,这使用 Spark 的默认并行任务数(本地模式为 2,在集群模式下,数量由配置属性spark.default.parallelism 确定)进行分组。 您可以传递一个可选的 numTasks 参数来设置不同数量的任务。 |
| join(otherStream, [numTasks]) | 当在 (K, V) 和 (K, W) 对的两个 DStream 上调用时,返回一个由 (K, (V, W)) 对组成的新 DStream,其中包含每个键的所有元素对。 |
| cogroup(otherStream, [numTasks]) | 当在 (K, V) 和 (K, W) 对的 DStream 上调用时,返回 (K, Seq[V], Seq[W]) 元组的新 DStream。 |
| transform(func) | 通过对源 DStream 的每个 RDD 应用 RDD-to-RDD 函数返回一个新的 DStream。 这可用于对 DStream 执行任意 RDD 操作。 |
| updateStateByKey(func) | 返回一个新的“状态” DStream,其中每个键的状态通过对键的先前状态和键的新值应用给定函数来更新。 这可用于维护每个键的任意状态数据。 |
其中一些转换值得更详细地讨论。
UpdateStateByKey Operation
updateStateByKey 操作允许您在使用新信息不断更新状态的同时保持任意状态。 要使用它,您必须执行两个步骤。
- Define the state - 状态可以是任意数据类型。
- Define the state update function - 使用函数指定如何使用先前状态和来自输入流的新值更新状态。
在每个批次中,Spark 都会对所有现有的键应用状态更新功能,无论它们是否有新的数据。 如果更新函数返回 None 则键值对将被消除。
让我们用一个例子来说明这一点。 假设您想维护文本数据流中每个单词的运行计数。 这里,运行计数是状态,它是一个整数。 我们将更新函数定义为:
def updateFunction(newValues: Seq[Int], runningCount: Option[Int]): Option[Int] =
val newCount = ... // add the new values with the previous running count to get the new count
Some(newCount)
This is applied on a DStream containing words (say, the pairs DStream containing (word, 1) pairs in the earlier example).
val runningCounts = pairs.updateStateByKey[Int](updateFunction _)
将为每个单词调用更新函数,newValues 具有 1 的序列(来自 (word, 1) 对),而 runningCount 具有先前的计数。
注意使用updateStateByKey需要配置checkpoint目录,在checkpointing部分中有详细讨论。
Transform Operation
transform 操作(以及它的变体,如 transformWith)允许在 DStream 上应用任意 RDD-to-RDD 函数。 它可用于应用未在 DStream API 中公开的任何 RDD 操作。 例如,将数据流中的每个批次与另一个数据集连接的功能并未直接在 DStream API 中公开。 但是,您可以轻松地使用 transform 来执行此操作。 这实现了非常强大的可能性。 例如,可以通过将输入数据流与预先计算的垃圾邮件信息(可能也使用 Spark 生成)连接起来,然后基于它进行过滤来进行实时数据清理。
val spamInfoRDD = ssc.sparkContext.newAPIHadoopRDD(...) // RDD containing spam information
val cleanedDStream = wordCounts.transform rdd =>
rdd.join(spamInfoRDD).filter(...) // join data stream with spam information to do data cleaning
...
请注意,在每个批处理间隔中都会调用提供的函数。 这允许你做随时间变化的RDD 操作,即 RDD 操作、分区数、广播变量等可以在批次之间改变。
Window Operations
Spark Streaming 还提供窗口计算,它允许您在数据的滑动窗口上应用转换。 下图说明了这个滑动窗口。
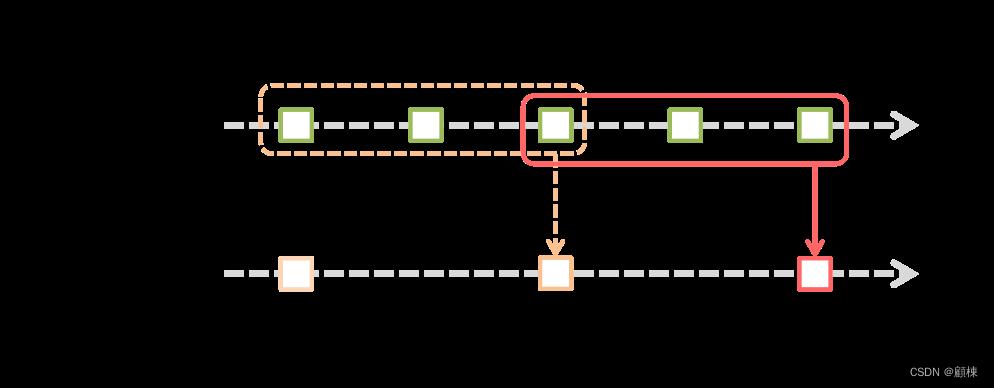
如图所示,每次窗口在源 DStream 上滑动时,落入窗口内的源 RDD 都会被组合并操作,以产生窗口化 DStream 的 RDD。 在这种特定情况下,该操作应用于数据的最后 3 个时间单位,并滑动 2 个时间单位。 这说明任何窗口操作都需要指定两个参数。
- window length - 窗口的持续时间(图中的 3)
- sliding interval - 执行窗口操作的时间间隔(图中的2)。
这两个参数必须是源DStream的批处理间隔的倍数(图中1)。
让我们用一个例子来说明窗口操作。 假设您想通过每 10 秒生成过去 30 秒数据的字数来扩展 earlier example。为此,我们必须在过去 30 秒的数据中对 (word, 1) 对的 pairs DStream 应用 reduceByKey 操作。 这是使用reduceByKeyAndWindow操作完成的。
// Reduce last 30 seconds of data, every 10 seconds
val windowedWordCounts = pairs.reduceByKeyAndWindow((a:Int,b:Int) => (a + b), Seconds(30), Seconds(10))
一些常见的窗口操作如下。 所有这些操作都采用上述两个参数 - windowLength 和 slideInterval。
| Transformation | Meaning |
|---|---|
| window(windowLength, slideInterval) | 返回一个基于源 DStream 的窗口批次计算的新 DStream。 |
| countByWindow(windowLength, slideInterval) | 返回流中元素的滑动窗口计数。 |
| reduceByWindow(func, windowLength, slideInterval) | 返回一个新的单元素流,它是通过使用 func 在滑动间隔内聚合流中的元素而创建的。 该函数应该是关联的和可交换的,以便可以并行正确计算。 |
| reduceByKeyAndWindow(func, windowLength, slideInterval, [numTasks]) | 当在 (K, V) 对的 DStream 上调用时,返回 (K, V) 对的新 DStream,其中每个键的值使用给定的 reduce 函数 func 在滑动窗口中的批次上聚合。 注意: 默认情况下,这使用 Spark 的默认并行任务数(本地模式为 2,在集群模式下,数量由配置属性spark.default.parallelism 确定)进行分组。 您可以传递一个可选的 numTasks 参数来设置不同数量的任务。 |
| reduceByKeyAndWindow(func, invFunc, windowLength, slideInterval, [numTasks]) | 上述 reduceByKeyAndWindow() 的更高效版本,其中每个窗口的 reduce 值是使用前一个窗口的 reduce 值递增计算的。 这是通过减少进入滑动窗口的新数据和“反向减少”离开窗口的旧数据来完成的。 一个例子是在窗口滑动时“添加”和“减去”键的计数。 但是,它只适用于“可逆归约函数”,即那些具有相应“逆归约”函数(作为参数invFunc)的归约函数。 就像在 reduceByKeyAndWindow 中一样,reduce 任务的数量可以通过一个可选参数进行配置。Note that checkpointing must be enabled for using this operation. |
| countByValueAndWindow(windowLength, slideInterval, [numTasks]) | 当在 (K, V) 对的 DStream 上调用时,返回 (K, Long) 对的新 DStream,其中每个键的值是其在滑动窗口内的频率。 就像在 reduceByKeyAndWindow 中一样,reduce 任务的数量可以通过一个可选参数进行配置。 |
Join Operations
最后,值得强调的是,您可以轻松地在 Spark Streaming 中执行不同类型的连接。
Stream-stream joins
流可以很容易地与其他流连接。
val stream1: DStream[String, String] = ...
val stream2: DStream[String, String] = ...
val joinedStream = stream1.join(stream2)
这里,在每个批次间隔中,stream1 生成的 RDD 将与 stream2 生成的 RDD 相结合。 你也可以做leftOuterJoin、rightOuterJoin、fullOuterJoin。 此外,在流的窗口上进行连接通常非常有用。 这也很容易。
val windowedStream1 = stream1.window(Seconds(20))
val windowedStream2 = stream2.window(Minutes(1))
val joinedStream = windowedStream1.join(windowedStream2)
Stream-dataset joins
这在前面解释 DStream.transform 操作时已经显示。 这是将窗口流与数据集连接的另一个示例。
val dataset: RDD[String, String] = ...
val windowedStream = stream.window(Seconds(20))...
val joinedStream = windowedStream.transform rdd => rdd.join(dataset)
事实上,您还可以动态更改要加入的数据集。 提供给 transform 的函数会在每个批次间隔进行评估,因此将使用 dataset 引用指向的当前数据集。
API 文档中提供了 DStream 转换的完整列表。For the Scala API, see DStream and PairDStreamFunctions. For the Java API, see JavaDStream and JavaPairDStream. For the Python API, see DStream.
Output Operations on DStreams
输出操作允许 DStream 的数据被推送到外部系统,如数据库或文件系统。 由于输出操作实际上允许外部系统使用转换后的数据,因此它们会触发所有 DStream 转换的实际执行(类似于 RDD 的操作)。 目前,定义了以下输出操作:
| Output Operation | Meaning |
|---|---|
| print() | 在运行流应用程序的驱动程序节点上打印 DStream 中每批数据的前十个元素。 这对于开发和调试很有用。Python API This is called pprint() in the Python API. |
| saveAsTextFiles(prefix, [suffix]) | 将此 DStream 的内容保存为文本文件。 每个批处理间隔的文件名是根据 prefix 和 suffix 生成的:“prefix-TIME_IN_MS[.suffix]”。 |
| saveAsObjectFiles(prefix, [suffix]) | 将此 DStream 的内容保存为序列化 Java 对象的SequenceFiles。 每个批处理间隔的文件名是根据 prefix 和 suffix 生成的:“prefix-TIME_IN_MS[.suffix]”。Python API This is not available in the Python API. |
| saveAsHadoopFiles(prefix, [suffix]) | 将此 DStream 的内容保存为 Hadoop 文件。 每个批处理间隔的文件名是根据prefix和suffix生成的:*“prefix-TIME_IN_MS[.suffix]”*Python API This is not available in the Python API. |
| foreachRDD(func) | 将函数 func 应用于从流生成的每个 RDD 的最通用的输出运算符。 该函数应该将每个 RDD 中的数据推送到外部系统,例如将 RDD 保存到文件中,或者通过网络将其写入数据库。 请注意,函数 func 在运行流式应用程序的驱动程序进程中执行,并且通常会在其中包含强制计算流式 RDD 的 RDD 操作。 |
Design Patterns for using foreachRDD
dstream.foreachRDD 是一个强大的原语,允许将数据发送到外部系统。 但是,了解如何正确有效地使用此原语非常重要。 一些需要避免的常见错误如下。
通常将数据写入外部系统需要创建一个连接对象(例如与远程服务器的 TCP 连接)并使用它来将数据发送到远程系统。 为此,开发人员可能无意中尝试在 Spark 驱动程序中创建连接对象,然后尝试在 Spark 工作人员中使用它来将记录保存在 RDD 中。 例如(在 Scala 中),
dstream.foreachRDD rdd =>
val connection = createNewConnection() // executed at the driver
rdd.foreach record =>
connection.send(record) // executed at the worker
这是不正确的,因为这需要将连接对象序列化并从驱动程序发送到工作程序。 这样的连接对象很少能跨机器转移。 该错误可能表现为序列化错误(连接对象不可序列化)、初始化错误(连接对象需要在worker处初始化)等。正确的解决方案是在worker处创建连接对象。
但是,这可能会导致另一个常见错误——为每条记录创建一个新连接。 例如,
dstream.foreachRDD rdd =>
rdd.foreach record =>
val connection = createNewConnection()
connection.send(record)
connection.close()
通常,创建连接对象具有时间和资源开销。 因此,为每条记录创建和销毁一个连接对象会导致不必要的高开销,并且会显着降低系统的整体吞吐量。 更好的解决方案是使用 rdd.foreachPartition - 创建单个连接对象并使用该连接发送 RDD 分区中的所有记录。
dstream.foreachRDD rdd =>
rdd.foreachPartition partitionOfRecords =>
val connection = createNewConnection()
partitionOfRecords.foreach(record => connection.send(record))
connection.close()
以上是关于Spark Streaming 编程指南的主要内容,如果未能解决你的问题,请参考以下文章
Apache Spark 2.2.0 中文文档 - Spark Streaming 编程指南 | ApacheCN
Apache Spark 2.2.0 中文文档 - Spark Streaming 编程指南 | ApacheCN
Apache Spark 2.2.0 中文文档 - Structured Streaming 编程指南 | ApacheCN