WebGPU开发详解
Posted 新缸中之脑
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了WebGPU开发详解相关的知识,希望对你有一定的参考价值。
WebGPU 是即将推出的 Web API,提供了一组访问 GPU的低级通用API。
我对图形学不是很有经验。我通过阅读有关如何使用 OpenGL 构建游戏引擎的教程来学习 WebGL 的知识点,并通过观看Inigo Quilez在ShaderToy上仅使用着色器(不使用任何 3D 网格或模型)做令人惊奇的事情来了解有关着色器的更多信息。这让我可以在PROXX中构建背景动画之类的东西,但我对 WebGL 并不满意,我将很快解释原因。

当 WebGPU 出现在我的视野中时,我想深入了解它,但很多人警告我,WebGPU 的样板比 WebGL 还要多。虽然没有被吓倒,但我预见到最坏的情况,教程和规范并不多,因为还处于 WebGPU 的早期阶段。深入以后,我发现我没有发现 WebGPU 实际上是一个我更熟悉的 API。
所以在这里。我想分享在研究 GPU 和 WebGPU 时学到的东西。这篇博文的目标是让 Web 开发人员可以访问 WebGPU。但这里有一个提醒:我不会使用 WebGPU 来生成图形。相反,我将使用 WebGPU 来访问 GPU 提供的原始计算能力。也许我会写一篇后续博客文章如何使用 WebGPU 渲染到你的屏幕上,但是已经有相当多的内容了。我将尽可能深入地理解 WebGPU,并希望能让你有效地使用它——虽然不一定是有效的。
1、WebGL
WebGL于 2011 年问世,到目前为止,它是唯一可以从 Web 访问 GPU 的低级 API。WebGL 的 API 实际上只是 OpenGL ES 2.0,带有一些瘦包装器和辅助工具以使其与 Web 兼容。WebGL 和 OpenGL 都由Khronos Group标准化,这基本上是 3D 图形的 W3C。
OpenGL 的 API 本身可以追溯到更远,按照今天的标准,它并不是一个很好的 API。该设计以内部的全局状态对象为中心。从这样的角度来看,这种设计是有意义的,因为它可以最大限度地减少任何给定调用需要传入和传出 GPU 的数据量。但是,它也引入了很多精神负担。
WebGL 内部全局状态对象的可视化。摘自WebGL Fundamentals。
内部状态对象基本上是指针的集合。你的 API 调用会影响状态对象指向的对象,但也会影响状态对象本身。因此,API 调用的顺序非常重要,我总觉得这使得构建抽象和库变得困难。你必须非常细致地清理所有可能干扰将要进行的 API 调用的指针和状态项,还要将指针和值恢复到它们之前的值,以便你的抽象正确组合。我经常发现自己盯着一个黑色的画布(因为这几乎是你在 WebGL 中报告错误的全部内容)并且暴力破解当前没有指向正确方向的指针。老实说,我不知道ThreeJS如何设法变得如此强大,但它确实以某种方式管理。我认为这是大多数人直接使用 ThreeJS 而不是 WebGL 的主要原因之一。
不是你,是我:需要明确的是,我无法内化 WebGL 可能是我自己的一个缺点。比我聪明的人已经能够使用 WebGL(以及 Web 之外的 OpenGL)构建出令人惊叹的东西,但它从来没有真正让我满意。
随着机器学习、神经网络以及加密货币的出现,GPU 已经表明它们不仅仅可以用于在屏幕上绘制三角形。使用 GPU 进行任何类型的计算通常被称为通用 GPU 或 GPGPU,而 WebGL 1 在这方面并不出色。如果你想在 GPU 上处理任意数据,则必须将其编码为纹理,在着色器中对其进行解码,进行计算,然后将结果重新编码为纹理。WebGL 2 使用Transform Feedback让这件事变得更容易,但直到 2021 年 9 月,Safari 才支持 WebGL2(而大多数其他浏览器自 2017 年 1 月起支持 WebGL2),所以它不是一个真正的选择。即便如此,WebGL2 的某些限制仍然让人感觉有些笨拙。
2、WebGPU
在 Web 之外,新一代的图形 API 已经建立起来,它们向图形卡公开了一个更底层的接口。这些新的 API 适应了设计 OpenGL 时不存在的新用例和约束。一方面,GPU 现在几乎无处不在。甚至我们的移动设备也内置了功能强大的 GPU。因此,两者都现代图形编程(3D 渲染和光线追踪)和 GPGPU 用例越来越普遍。另一方面,我们的大多数设备都有多核处理器,因此能够从多个线程与 GPU 交互可能是一个重要的优化向量。当 WebGPU 人员参与其中时,他们还重新审视了之前的一些设计决策,并预先加载了 GPU 必须完成的大量验证工作,从而使开发人员能够从他们的 GPU 中榨取更多性能。
最受欢迎的下一代 GPU API 是Khronos Group的Vulkan 、 Apple的Metal和微软的DirectX 12。为了将这些新功能带入网络,WebGPU 应运而生。虽然 WebGL 只是 OpenGL 的一个薄包装层,但 WebGPU 选择了不同的方法。它引入了自己的抽象,并且不直接反映任何这些原生 API。这部分是因为没有单一的 API 在所有系统上都可用,还因为许多概念(例如极低级别的内存管理)对于面向 Web 的 API 来说并不惯用。取而代之的是,WebGPU 被设计成既能让人感觉“webby”,又能舒适地坐在任何原生图形 API 之上,同时抽象它们的特性。它在 W3C 中被标准化,所有主要的浏览器供应商都拥有一席之地。由于其相对低级的性质和强大的功能,WebGPU 有一些学习曲线并且在设置上相对繁重,
3、WebGPU适配器和设备
我们接触到的 WebGPU 的第一个抽象是适配器和(逻辑)设备。
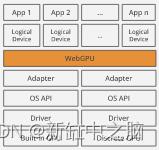
抽象层,从物理 GPU 到逻辑设备
物理设备是 GPU 本身,通常区分为内置 GPU 和独立 GPU。通常,任何给定设备都只有一个 GPU,但也可能有两个或更多 GPU。例如,微软的 SurfaceBook 以低功耗的集成 GPU 和高性能的独立 GPU 著称,操作系统将根据需要在它们之间切换。
由 GPU 制造商提供的驱动程序将以操作系统理解和期望的方式向操作系统公开 GPU 的功能。反过来,操作系统可以使用操作系统提供的图形 API(如 Vulkan 或 Metal)将其暴露给应用程序。
GPU 是共享资源。它不仅被许多应用程序同时使用,而且还控制你在显示器上看到的内容。需要有一些东西可以让多个进程同时使用 GPU,这样每个应用程序都可以将自己的 UI 放在屏幕上,而不会干扰其他应用程序,甚至不会恶意读取其他应用程序的数据。对于每个进程,看起来他们对物理 GPU 拥有唯一的控制权,但显然情况并非如此。这种多路复用主要由驱动程序和操作系统完成。
反过来,适配器是从操作系统的本机图形 API 到 WebGPU 的转换层。由于浏览器是可以运行多个 Web 应用程序的单一 OS 级应用程序,因此再次需要多路复用,以便每个 Web 应用程序感觉就像它拥有对 GPU 的唯一控制权。这是在 WebGPU 中使用逻辑设备的概念建模的。
要访问适配器,请调用navigator.gpu.requestAdapter(). 在撰写本文时,requestAdapter()选择很少。这些选项允许你请求高性能或低能耗适配器。
软件渲染:一些实现还为没有 GPU 或 GPU 能力不足的系统提供“后备适配器”。后备适配器实际上是一种纯软件实现,它不会很快,但可以保持你的应用程序正常运行。
如果成功,即返回的适配器不是null,就可以检查适配器的功能并使用 adapter.requestDevice()向适配器请求逻辑设备。
if (!navigator.gpu) throw Error("WebGPU not supported.");
const adapter = await navigator.gpu.requestAdapter();
if (!adapter) throw Error("Couldn’t request WebGPU adapter.");
const device = await adapter.requestDevice();
if (!device) throw Error("Couldn’t request WebGPU logical device.");
如果没有任何选项,requestDevice()将返回一个不一定与物理设备的功能相匹配的设备,而是 WebGPU 团队认为合理的、所有 GPU 的最低公分母的设备。详细信息在 WebGPU 标准中指定。例如,即使我的 GPU 能够轻松处理最大 4GiB 的数据缓冲区,device返回的数据缓冲区也只会允许最大 1GiB 的数据缓冲区,并且会拒绝任何更大的数据缓冲区。这可能看起来有限制,但实际上很有帮助:如果你的 WebGPU 应用程序使用默认设备运行,它将在绝大多数设备上运行。如有必要,你可以利用adapter.limits检查物理 GPU 的实际限制并通过将选项对象传递给requestDevice() 来请求一个 device 。
4、WebGPU着色器
如果您曾经使用过 WebGL,那么可能熟悉顶点着色器和片段着色器。无需过多深入,传统设置的工作原理如下:你将数据缓冲区上传到 GPU,并告诉它如何将该数据解释为一系列三角形。每个顶点占据该数据缓冲区的一块,描述该顶点在 3D 空间中的位置,但可能还包括颜色、纹理 ID、法线和其他内容等辅助数据。列表中的每个顶点都由 GPU 在顶点阶段处理,在每个顶点上运行顶点着色器,这将应用平移、旋转或透视变形。
着色器: “着色器”这个词曾经让我感到困惑,因为你可以做的不仅仅是着色。但在过去(即 1980 年代后期!),这个术语是恰当的:它是在 GPU 上运行的一小段代码,用于决定每个像素应该是什么颜色,这样你就可以对正在渲染的对象进行着色,实现灯光和阴影的错觉。如今,着色器泛指在 GPU 上运行的任何程序。
GPU 现在对三角形进行光栅化,这意味着 GPU 会计算出每个三角形在屏幕上覆盖的像素。然后每个像素由片段着色器处理,它可以访问像素坐标,也可以访问辅助数据来决定该像素应该是哪种颜色。如果使用得当,可以使用此过程创建令人惊叹的 3D 图形。
这种将数据传递到顶点着色器,然后到片段着色器,然后将其直接输出到屏幕上的系统称为管道,在 WebGPU 中,你必须明确定义管道。
5、WebGPU管道
目前,WebGPU 允许你创建两种类型的管道:渲染管道和计算管道。顾名思义,渲染管道渲染某些东西,这意味着它创建了一个 2D 图像。该图像不必在屏幕上,而可以只渲染到内存(称为帧缓冲区)。计算更通用,因为它返回一个缓冲区,该缓冲区可以包含任何类型的数据。在这篇博文的其余部分,我将专注于计算管道,因为我喜欢将渲染管道视为计算管道的专业化/优化。现在,这既是历史上的倒退——计算管道是作为专门构建的渲染管道的泛化而构建的——而且还大大低估了这些管道在你的 GPU 中是物理上不同的电路。然而,就 API 而言,我发现这个心智模型很有帮助。在未来,似乎更多类型的管道——也许是光线追踪管道——将被添加到 WebGPU 中。
使用 WebGPU,管道由一个(或多个)可编程阶段组成,其中每个阶段由一个着色器和一个入口点定义。计算管道只有一个compute阶段,而渲染管道将有一个vertex和一个fragment阶段:
const module = device.createShaderModule(
code: `
@stage(compute) @workgroup_size(64)
fn main()
// Pointless!
`,
);
const pipeline = device.createComputePipeline(
compute:
module,
entryPoint: "main",
,
);
这是WebGPU着色语言 WGSL(发音为“wig-sal”)第一次出现。WGSL 对我来说就像是 Rust 和 GLSL 的交叉。它有很多 Rust-y 语法,带有 GLSL 的全局函数(如dot(), norm(), len(), …),类型(如vec2, mat4x4, …)和swizzling符号(如some_vec.xxy, …)。浏览器会将你的 WGSL 编译为底层系统所期望的。这可能是 DirectX 12 的 HLSL、Metal 的 MSL 和Vulkan的 SPIR-V。
SPIR-V:SPIR-V很有趣,因为它是由 Khronos Group 标准化的开放、二进制、中间格式。你可以将 SPIR-V 视为并行编程语言编译器的 LLVM,并且支持将多种语言编译为SPIR-V 以及将 SPIR-V 编译为多种其他语言。
在上面的着色器模块中,我们只是创建了一个名为main的函数,并使用@stage(compute)属性将其标记为计算阶段的入口点。你可以将多个函数标记为着色器模块中的入口点,因为可以为多个管道重用相同的着色器模块,并通过entryPoint选项选择不同的函数来调用。但是那个@workgroup_size(64)属性是什么?
6、WebGPU的并行性
GPU 以延迟为代价针对吞吐量进行了优化。要理解这一点,我们必须看一下 GPU 的架构。我不想(老实说,不能)完整地解释它。我会尽可能深入。如果你想了解更多信息,Fabian Giesen的这个由13 部分组成的博客文章系列非常棒。
众所周知,GPU 具有大量内核,可以进行大规模并行工作。但是,这些内核并不像你在为多核 CPU 编程时所习惯的那样独立。首先,GPU 核心是分层分组的。层次结构中不同层的术语在供应商和 API 之间并不一致。英特尔有一个很好的文档,提供了对其架构的高级概述,我被告知可以安全地假设其他 GPU 至少可以类似地工作,尽管 GPU 的确切架构是受 NDA 保护的机密。
在英特尔的情况下,层次结构中的最低级别是“执行单元”(EU),它有多个(在本例中为七个)SIMT内核。这意味着它有七个以锁步方式运行并始终执行相同指令的内核。但是,每个内核都有自己的一组寄存器和堆栈指针。因此,虽然他们必须执行相同的操作,但他们可以在不同的数据上执行它。这也是 GPU 性能专家避免分支(如if/else或循环)的原因:如果 EU 遇到if/ else,所有内核都必须同时执行分支,除非所有核心碰巧采用相同的分支。可以告诉每个核心忽略它正在输入的指令,但这显然浪费了可以用于计算的宝贵周期。这同样适用于循环!如果一个核心提前完成了他们的循环,它将不得不假装执行循环体,直到所有核心都完成了循环。
尽管内核的频率很高,但从内存(或纹理中的像素)获取数据仍然需要相对较长的时间——Fabian 说这需要几百个时钟周期。这几百个周期可以用于计算。为了利用这些原本空闲的周期,每个欧盟的工作都严重超额认购。每当 EU 最终空闲(例如,等待内存中的值)时,它就会切换到另一个工作项,并且只有在新的工作项需要等待某事时才会切换回来。这是 GPU 如何以延迟为代价优化吞吐量的关键技巧:单个工作项将花费更长的时间,因为切换到另一个工作项可能会停止执行的时间超过必要的时间,但总体利用率更高并导致更高的吞吐量。

英特尔 Iris Xe 图形芯片的架构
不过,EU 只是层次结构中的最低级别。多个 EU 被分组为英特尔所谓的“SubSlice”。SubSlice 中的所有 EU 都可以访问少量共享本地内存 (SLM),在英特尔的情况下约为 64KiB。如果要运行的程序有任何同步命令,则必须在同一个 SubSlice 内执行,因为只有它们有共享内存进行同步。
在最后一层,多个 SubSlice 被组合成一个 Slice,形成 GPU。对于集成的 Intel GPU,最终总共有 170-700 个内核。离散 GPU 可以轻松拥有 1500 个或更多内核。同样,这里的命名取自英特尔,其他供应商可能使用不同的名称,但每个 GPU 的总体架构都是相似的。
为了充分利用这种架构的好处,需要专门为这种架构设置程序,以便纯程序化的 GPU 调度程序可以最大限度地利用。因此,图形 API 公开了一个线程模型,自然允许以这种方式剖析工作。在 WebGPU 中,这里重要的原语是“工作组”。
7、WebGPU工作组
在传统设置中,顶点着色器会为每个顶点调用一次,片段着色器会为每个像素调用一次(我知道我在这里略过一些细节)。在 GPGPU 设置中,将为你安排的每个工作项调用一次计算着色器。由你来定义工作项是什么。
所有工作项的集合(我将其称为“工作负载”)被分解为工作组。工作组中的所有工作项都计划一起运行。在 WebGPU 中,工作负载被建模为一个 3 维网格,其中每个“立方体”是一个工作项,工作项被分组为更大的立方体以形成一个工作组。

这是一个工作负载。白边立方体是一个工作项。红边长方体是一个工作组
最后,我们有足够的信息来讨论这个@workgroup_size(x, y, z)属性,在这一点上它甚至可能是不言自明的:这个属性允许你告诉 GPU 这个着色器的工作组的大小应该是多少。或者用上图的语言,@workgroup_size属性定义了红边立方体的大小。 x×y×z 表示每个工作组的工作项数。任何跳过的参数都假定为 1,因此@workgroup_size(64)等价于@workgroup_size(64, 1, 1)。
当然,实际的 EU 并不排列在芯片上的 3D 网格中。在 3D 网格中建模工作项的目的是增加局部性。假设相邻的工作组很可能会访问内存中的相似区域,因此当顺序运行相邻的工作组时,缓存中已经有值的机会更高,无需从缓存中抓取它们,从而节省了几百个周期记忆。然而,大多数硬件似乎只是以串行顺序运行工作组,因为运行着色器@workgroup_size(64)与@workgroup_size(8, 8)之间的差异可以忽略不计。所以这个概念被认为有点遗留。
但是,工作组受到多种方式的限制:device.limits有许多值得了解的属性:
// device.limits
// ...
maxComputeInvocationsPerWorkgroup: 256,
maxComputeWorkgroupSizeX: 256,
maxComputeWorkgroupSizeY: 256,
maxComputeWorkgroupSizeZ: 64,
maxComputeWorkgroupsPerDimension: 65535,
// ...
工作组大小的每个维度的大小都受到限制,但即使 x、y 和 z 分别在限制范围内,它们的乘积 ( =x×y×z )可能不是,因为有其自己的限制,你只能使用这么多工作组。
专业提示:不要产生最大数量的线程。尽管 GPU 由操作系统和底层调度程序管理,但你可能会使用长时间运行的 GPU 程序冻结整个系统。
那么合适的工作组规模是多少?这实际上取决于你分配工作项坐标的语义。我确实意识到这并不是一个真正有用的答案,所以我想给你如下建议:“使用 [a workgroup size of] 64,除非你知道你的目标是什么 GPU 或者你的工作负载需要不同的东西。” 这似乎是一个安全的数字,可以在许多 GPU 上运行良好,并允许 GPU 调度程序让尽可能多的 EU 保持忙碌。
8、WebGPU命令执行
我们已经编写了着色器并设置了管道。剩下要做的就是调用 GPU 来执行它。由于 GPU可以是具有自己的内存芯片的完全独立的卡,因此你可以通过所谓的命令缓冲区或命令队列来控制它。命令队列是一块内存,其中包含供 GPU 执行的编码命令。编码高度特定于 GPU,由驱动程序负责。WebGPU 公开了一个CommandEncoder以利用该功能。
const commandEncoder = device.createCommandEncoder();
const passEncoder = commandEncoder.beginComputePass();
passEncoder.setPipeline(pipeline);
passEncoder.dispatch(1);
passEncoder.end();
const commands = commandEncoder.finish();
device.queue.submit([commands]);
commandEncoder有多种方法可让你将数据从一个 GPU 缓冲区复制到另一个 GPU 缓冲区并操作纹理。它还允许你创建PassEncoder,它对管道的设置和调用进行编码。在这种情况下,我们有一个计算管道,因此我们必须创建一个计算通道,将其设置为使用我们预先声明的管道,最后调用dispatch(w_x, w_y, w_z)以告诉 GPU 沿每个维度创建多少个工作组。换句话说,我们的计算着色器将被调用的次数等于 wx×wy×wz×x×y×z 。 顺便说一句,pass 编码器是 WebGPU 的抽象,用于避免我在这篇博文开始时描述的内部全局状态对象。运行 GPU 管道所需的所有数据和状态都通过 pass 编码器显式传递。
抽象:命令缓冲区也是驱动程序或操作系统的挂钩,让多个应用程序使用 GPU 而不会相互干扰。当你将命令排队时,下面的抽象层将向队列中注入额外的命令,以保存先前程序的状态并恢复您的程序状态,这样就感觉没有其他人在使用 GPU。
运行这段代码,我们实际上在 GPU 上生成了 64 个线程,它们完全没有任何作用。但它有效,所以这很酷。让我们谈谈我们如何给 GPU 一些数据来工作。
9、WebGPU交换数据
正如所承诺的,我不会直接将 WebGPU 用于图形,因此我认为在 GPU 上运行物理模拟并使用 Canvas2D 将其可视化会很有趣。也许我自称是“物理模拟”——我正在做的是生成一大堆圆圈,让它们在平面上以随机方向滚动并让它们发生碰撞。
为此,我们需要将一些模拟参数和初始状态推送到GPU,在 GPU 上运行模拟并从GPU 读取模拟结果。这可以说是 WebGPU 最令人毛骨悚然的部分,因为有一堆数据杂技(不是说看似毫无意义的复制),但这就是让 WebGPU 成为以最高性能水平运行的与设备无关的 API 的原因。
10、WebGPU绑定组布局
为了与 GPU 交换数据,我们需要使用绑定组布局扩展我们的管道定义。绑定组是在管道执行期间可访问的 GPU 实体(内存缓冲区、纹理、采样器等)的集合。绑定组布局预先定义了这些 GPU 实体的类型、用途和用途,这使 GPU 可以提前弄清楚如何最有效地运行管道。让我们在这个初始步骤中保持简单,并让我们的管道访问单个内存缓冲区:
const bindGroupLayout =
device.createBindGroupLayout(
entries: [
binding: 1,
visibility: GPUShaderStage.COMPUTE,
buffer:
type: "storage",
,
],
);
const pipeline = device.createComputePipeline(
layout: device.createPipelineLayout(
bindGroupLayouts: [bindGroupLayout],
),
compute:
module,
entryPoint: "main",
,
);
该binding数字可以自由选择,并用于将 WGSL 代码中的变量与绑定组布局的此槽中的缓冲区内容联系起来。我们bindGroupLayout还定义了每个缓冲区的用途,在本例中为"storage". 另一个选项是"read-only-storage",它是只读的,并允许 GPU 在永远不会写入此缓冲区并且因此不需要同步的基础上进行进一步的优化。缓冲区类型的最后一个可能值是"uniform",在计算管道的上下文中,它在功能上主要等同于存储缓冲区。
绑定组布局就位。现在我们可以创建绑定组本身,其中包含绑定组布局所期望的 GPU 实体的实际实例。一旦带有缓冲区的绑定组就位,计算着色器可以用数据填充它,我们可以从 GPU 读取它。但是有一个障碍:暂存缓冲区。
11、WebGPU暂存区
我再说一遍:GPU 以延迟为代价对吞吐量进行了高度优化。GPU 需要能够以令人难以置信的高速率向内核提供数据,以维持该吞吐量。Fabian 从 2011 年开始在他的博客文章系列中做了一些背后的数学运算,得出的结论是 GPU 需要维持 3.3GB/s 的速度,仅用于以 1280x720 分辨率运行的着色器的纹理样本。为了适应当今的图形需求,GPU 需要更快地挖掘数据。这只有在 GPU 的内存与内核紧密集成的情况下才能实现。这种紧密的集成使得很难将相同的内存也暴露给主机进行读写。
相反,GPU 有额外的内存库,主机和 GPU 都可以访问,但集成度不高,无法快速提供数据。暂存缓冲区是在此中间内存领域中分配的缓冲区,可以映射到主机系统进行读写。为了从 GPU 读取数据,我们将数据从内部高性能缓冲区复制到暂存缓冲区,然后将暂存缓冲区映射到主机,以便我们可以将数据读回主内存。对于写作,这个过程是相同的,但相反。
回到我们的代码:我们将创建一个可写缓冲区并将其添加到绑定组,以便计算着色器可以写入它。我们还将创建一个大小相同的第二个缓冲区,作为暂存缓冲区。每个缓冲区都使用usage位掩码创建,你可以在其中声明您打算如何使用该缓冲区。然后,GPU 将确定缓冲区的位置以实现所有这些用例,或者如果标志组合无法实现,则抛出错误。
const BUFFER_SIZE = 1000;
const output = device.createBuffer(
size: BUFFER_SIZE,
usage: GPUBufferUsage.STORAGE | GPUBufferUsage.COPY_SRC
);
const stagingBuffer = device.createBuffer(
size: BUFFER_SIZE,
usage: GPUBufferUsage.MAP_READ | GPUBufferUsage.COPY_DST,
);
const bindGroup = device.createBindGroup(
layout: bindGroupLayout,
entries: [
binding: 1,
resource:
buffer: output,
,
],
);
请注意,createBuffer()返回一个 GPUBuffer,而不是ArrayBuffer. 暂时无法读取或写入它们。为此,它们需要被映射,这是一个单独的 API 调用,并且只会对具有GPUBufferUsage.MAP_READ或GPUBufferUsage.MAP_WRITE的缓冲区成功。
TypeScript:我发现 TypeScript 在探索新 API 时非常有用。幸运的是,Chrome 的 WebGPU 团队维护@webgpu/types,因此你可以享受准确的自动完成。
现在我们不仅有了绑定组布局,甚至还有实际的绑定组本身,我们需要更新我们的调度代码以使用这个绑定组。之后,我们映射暂存缓冲区以将结果读回 javascript。
const commandEncoder = device.createCommandEncoder();
const passEncoder = commandEncoder.beginComputePass();
passEncoder.setPipeline(pipeline);
passEncoder.setBindGroup(0, bindGroup);
passEncoder.dispatch(1);
passEncoder.dispatch(Math.ceil(BUFFER_SIZE / 64));
passEncoder.end();
commandEncoder.copyBufferToBuffer(
output,
0, // Source offset
stagingBuffer,
0, // Destination offset
BUFFER_SIZE
);
const commands = commandEncoder.finish();
device.queue.submit([commands]);
await stagingBuffer.mapAsync(
GPUMapMode.READ,
0, // Offset
BUFFER_SIZE // Length
);
const copyArrayBuffer =
stagingBuffer.getMappedRange(0, BUFFER_SIZE);
const data = copyArrayBuffer.slice();
stagingBuffer.unmap();
console.log(new Float32Array(data));
由于我们向管道添加了绑定组布局,因此任何不提供绑定组的调用现在都会失败。在我们定义“pass”之后,我们通过命令编码器添加一个额外的命令,将数据从输出缓冲区复制到暂存缓冲区,并将我们的命令缓冲区提交到队列。GPU 将开始通过命令队列工作。我们不知道 GPU 何时会准确完成,但我们已经可以提交我们的请求stagingBuffer以进行映射。这个函数是异步的,因为它需要等待命令队列被完全处理。当返回的 promise 解析时,缓冲区被映射,但还没有暴露给 JavaScript。stagingBuffer.getMappedRange()让我们请求一个小节(或整个缓冲区)作为一个好的 ol’ 暴露给 JavaScriptArrayBuffer. 这是真实的、映射的 GPU 内存,这意味着数据将在stagingBuffer未映射时消失(ArrayBuffer将“分离”),因此我在使用slice()创建 JavaScript 拥有的副本。
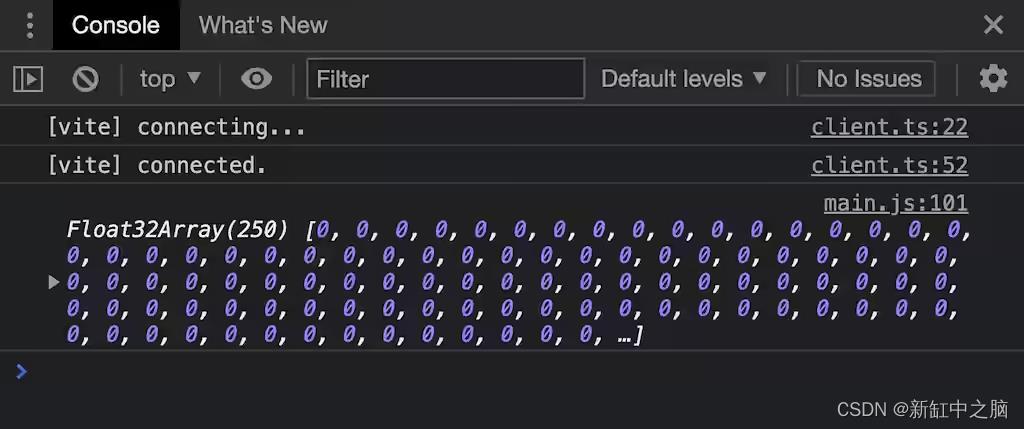
不是很令人兴奋,但我们从 GPU 的内存中复制了这些零
零以外的东西可能会更有说服力。在我们开始在我们的 GPU 上进行任何高级计算之前,让我们将一些手工挑选的数据放入我们的缓冲区中,以证明我们的管道确实按预期工作。这是我们新的计算着色器代码,为了清晰起见,有额外的间距。
@group(0) @binding(1)
var<storage, write> output: array<f32>;
@stage(compute) @workgroup_size(64)
fn main(
@builtin(global_invocation_id)
global_id : vec3<u32>,
@builtin(local_invocation_id)
local_id : vec3<u32>,
)
output[global_id.x] =
f32(global_id.x) * 1000. + f32(local_id.x);
前两行声明了一个名为 的模块范围变量output,它是一个动态大小的数组f32。属性声明数据的来源:从我们第一个(第 0 个)绑定组中的缓冲区,binding值为 1 的条目。数组的长度将自动反映底层缓冲区的长度(向下舍入)。
变量: WGSL 与 Rust 的不同之处在于声明的变量let是不可变的。如果你希望一个变量是可变的,应该使用关键字是var。
我们main()函数的签名增加了两个参数:global_id和local_id。我可以选择任何名称——它们的值由与它们关联的属性决定: Theglobal_invocation_id是一个内置值,对应于工作负载中此着色器调用的全局 x/y/z 坐标。local_invocation_id是工作组中此着色器的 x/y/z坐标。
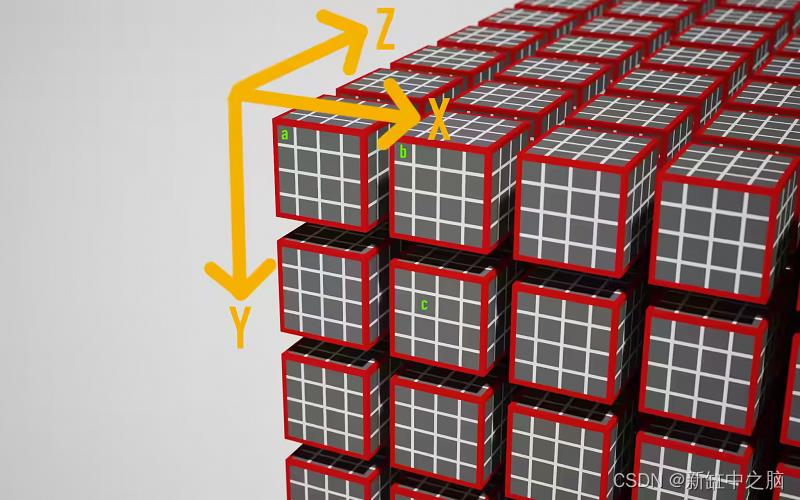
工作量中标记的三个工作项 a、b 和 c 的示例
此图显示了工作负载@workgroup_size(4, 4, 4)坐标系的一种可能解释。可以为你的用例定义坐标系。如果我们在上面绘制的轴上达成一致,我们将看到main() 的以下a、b 和 c参数:
a:
- local_id=(x=0, y=0, z=0)
- global_id=(x=0, y=0, z=0)
b:
- local_id=(x=0, y=0, z=0)
- global_id=(x=4, y=0, z=0)
c:
- local_id=(x=1, y=1, z=0)
- global_id=(x=5, y=5, z=0)
在我们的着色器中,我们有@workgroup_size(64, 1, 1),因此local_id.x范围从 0 到 63。为了能够检查这两个值,我将它们“编码”为一个数字。请注意,WGSL 是严格类型的: local_id和global_id都是 vec3,因此我们必须显式地将它们的值转换f32为能够将它们分配给我们的f32输出缓冲区。
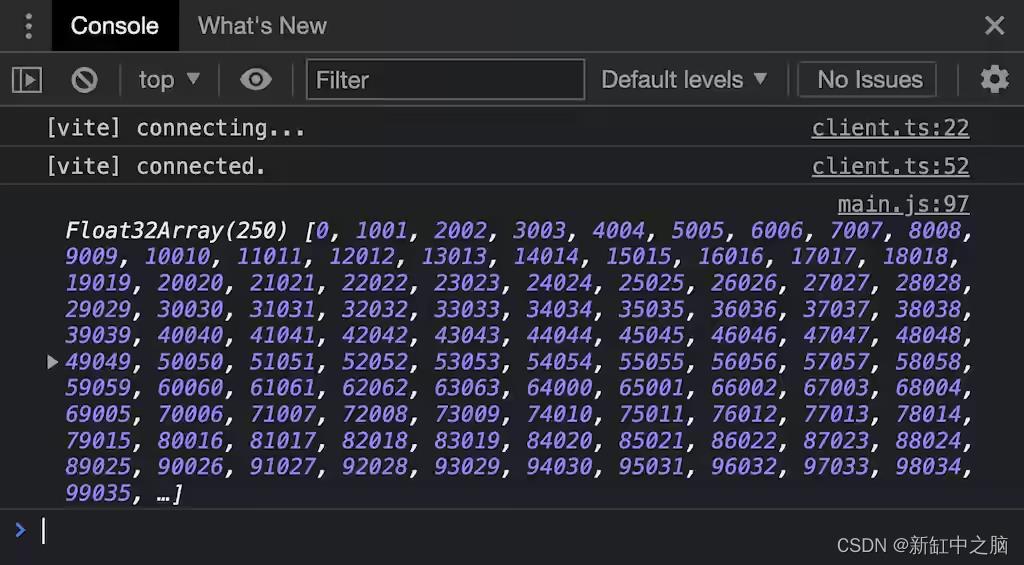
GPU 填写的实际值
这证明了我们的计算着色器确实为输出内存中的每个值调用并用唯一值填充它。我们不知道这些数据是按什么顺序填写的,因为这是故意未指定的,并留给 GPU 的调度程序。
12、WebGPU过调度
精明的观察者可能已经注意到,着色器调用的总数 ( Math.ceil(BUFFER_SIZE / 64) * 64) 将导致global_id.x大于我们数组的长度,因为每个f32占用 4 个字节。幸运的是,访问数组受到隐式钳位的保护,因此每次超出数组末尾的写入最终都会写入数组的最后一个元素。这样可以避免内存访问错误,但仍可能生成不可用的数据。事实上,如果你检查返回缓冲区的最后 3 个元素,会发现数字 247055、248056 和 608032。我们有责任通过提前退出来防止在着色器代码中发生这种情况:
fn main( /* ... */)
if(global_id.x >= arrayLength(&output))
return;
output[global_id.x] =
f32(global_id.x) * 100. + f32(local_id.x);
如果需要,您可以运行此演示并检查完整源代码。
13、WebGPU结构对齐
我们的目标是让整个乐塔球在 2D 空间中移动并进行愉快的小碰撞。为此,每个球都需要有一个半径、一个位置和一个速度矢量。我们可以继续处理array,并说第一个浮点数是第一个球的 x 位置,第二个浮点数是第一个球的 y 位置,依此类推。这不是我所说的人体工程学。幸运的是,WGSL 允许我们定义自己的结构,将多条数据捆绑在一个整洁的包中。
旧消息:如果你知道什么是内存对齐,则可以跳过本节(尽管请看一下代码示例)。如果你还不知道它是什么,我不会真正解释原因,而是向你展示它是如何体现的以及如何使用它。
因此,用所有这些组件定义一个struct Balla 并将我们的array转换为array是有意义的。所有这一切的缺点:我们必须谈论对齐。
struct Ball
radius: f32;
position: vec2<f32>;
velocity: vec2<f32>;
@group(0) @binding(1)
var<storage, write> output: array<f32>;
var<storage, write> output: array<Ball>;
@stage(compute) @workgroup_size(64)
fn main(
@builtin(global_invocation_id) global_id : vec3<u32>,
@builtin(local_invocation_id) local_id : vec3<u32>,
)
let num_balls = arrayLength(&output);
if(global_id.x >= num_balls)
return;
output[global_id.x].radius = 999.;
output[global_id.x].position = vec2<f32>(global_id.xy);
output[global_id.x].velocity = vec2<f32>(local_id.xy);
如果运行此演示,你将在控制台中看到:
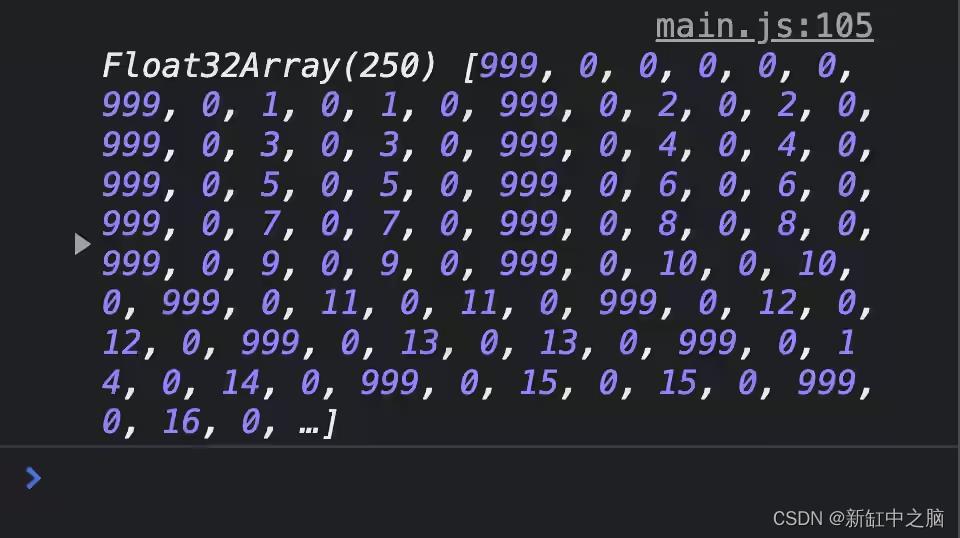
由于对齐约束,该结构在其内存布局中有一个填充
我放置999到结构的第一个字段,以便于查看结构在缓冲区中的开始位置。在我们到达下一个之前总共有 6 个数字999,这有点令人惊讶,因为该结构实际上只有 5 个数字要存储:radius、position.x、position.y 、velocity.x和velocity.y。仔细一看,很明显radius后面的数字总是0。这是对齐的原因。
每种 WGSL 数据类型都有明确定义的对齐要求。如果数据类型的对齐方为N,这意味着该数据类型的值只能存储在一个内存地址是N的倍数. f32对齐为 4,而vec2对齐为 8。如果我们假设我们的结构从地址 0 开始,则该radius字段可以存储在地址 0,因为 0 是 4 的倍数。结构中的下一个字段是vec2,对齐为 8。但是,之后的第一个空闲地址radius是 4,它不是8 的倍数。为了解决这个问题,编译器添加了 4 个字节的填充以到达下一个 8 的倍数的地址。这解释了我们在 DevTools 控制台中看到一个值为 0 的未使用字段。
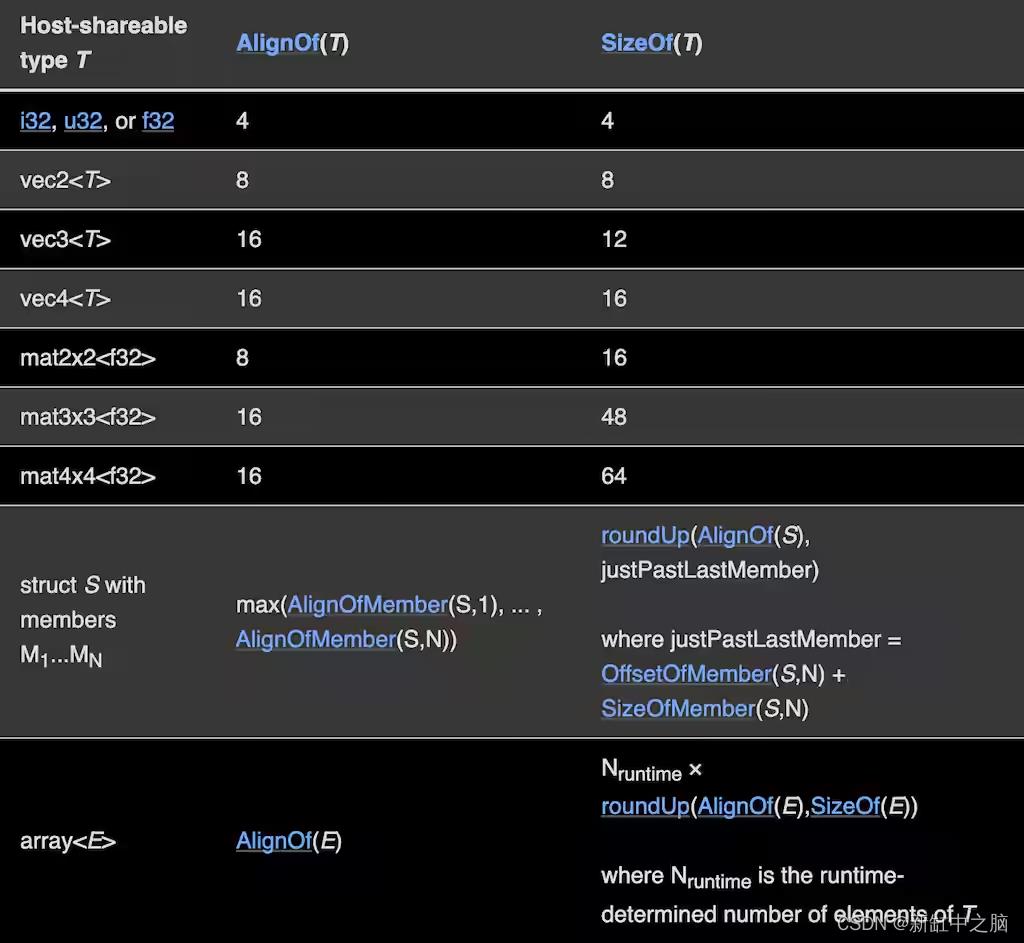
WGSL 规范中的(缩短的)对齐表
现在知道了结构在内存中是如何布局的,我们可以从 JavaScript 填充它以生成我们的初始状态球,并将其读回以可视化它。
14、WebGPU输入输出
我们已经成功地从 GPU 读取数据,将其带到 JavaScript 并“解码”它。现在是处理另一个方向的时候了。我们需要在 JavaScript 中生成所有球的初始状态并将其提供给 GPU,以便它可以在其上运行计算着色器。生成初始状态相当简单:
let inputBalls = new Float32Array(new ArrayBuffer(BUFFER_SIZE));
for (let i = 0; i < NUM_BALLS; i++)
inputBalls[i * 6 + 0] = randomBetween(2, 10); // radius
inputBalls[i * 6 + 1] = 0; // padding
inputBalls[i * 6 + 2] = randomBetween(0, ctx.canvas.width); // position.x
inputBalls[i * 6 + 3] = randomBetween(0, ctx.canvas.height); // position.y
inputBalls[i * 6 + 4] = randomBetween(-100, 100); // velocity.x
inputBalls[i * 6 + 5] = randomBetween(-100, 100); // velocity.y
Buffer-backed-object:对于更复杂的数据结构,从 JavaScript 中操作数据会变得相当乏味。虽然最初是为工人用例编写的,但我的库buffer-backed-object在这里可以派上用场!
我们也已经知道如何将缓冲区暴露给我们的着色器。只需要调整我们的管道绑定组布局以期望另一个缓冲区:
const bindGroupLayout = device.createBindGroupLayout(
entries: [
binding: 0,
visibility: GPUShaderStage.COMPUTE,
buffer:
type: "read-only-storage",
,
,
binding: 1,
visibility: GPUShaderStage.COMPUTE,
buffer:
type: "storage",
,
,
],
);
…并创建一个我们可以使用绑定组绑定的 GPU 缓冲区:
const input = device.createBuffer(
size: BUFFER_SIZE,
usage: GPUBufferUsage.STORAGE | GPUBufferUsage.COPY_DST,
);
const bindGroup = device.createBindGroup(
layout: bindGroupLayout,
entries: [
binding: 0,
resource:
buffer: input,
,
,
binding: 1,
resource:
buffer: output,
,
,
],
);
现在是新的部分:向 GPU 发送数据。就像读取数据一样,我们在技术上必须创建一个可以映射的暂存缓冲区,将我们的数据复制到暂存缓冲区,然后发出命令将我们的数据从暂存缓冲区复制到存储缓冲区。然而,WebGPU 提供了一个方便的功能,它可以为我们选择最有效的方式将我们的数据放入存储缓冲区,即使这涉及动态创建临时暂存缓冲区:
device.queue.writeBuffer(input, 0, inputBalls);
这样就行了?是的!我们甚至不需要命令编码器。我们可以直接把这个命令放到命令队列中。device.queue还为纹理提供了一些其他类似的便利功能。
现在我们需要将这个新缓冲区绑定到 WGSL 中的一个变量并对其进行处理:
struct Ball
radius: f32;
position: vec2<f32>;
velocity: vec2<f32>;
@group(0) @binding(0)
var<storage, read> input: array<Ball>;
@group(0) @binding(1)
var<storage, write> output: array<Ball>;
let TIME_STEP: f32 = 0.016;
@stage(compute) @workgroup_size(64)
fn main(
@builtin(global_invocation_id)
global_id : vec3<u32>,
)
let num_balls = arrayLength(&output);
if(global_id.x >= num_balls)
return;
output[global_id.x].position =
input[global_id.x].position +
input[global_id.x].velocity * TIME_STEP;
我希望这个着色器代码的绝大部分在这一点上不会让你感到意外。

每一帧更新球的位置并使用 Canvas2D 绘制到屏幕上
最后,我们需要做的就是将output缓冲区读回 JavaScript,编写一些 Canvas2D 代码来可视化缓冲区的内容并将其全部放入requestAnimationFrame()循环中。你可以看到这个演示的结果。
15、WebGPU性能
上一个演示只是沿着它们的速度矢量移动每个球。不完全令人兴奋或计算复杂。在我们查看我们的创作的性能特征之前,让我在着色器中放入一些适当的物理计算。我不会在这里解释它们——博客文章已经足够长了——但我会说我采取了最幼稚的方法:每个球都检查与其他球的碰撞。如果你好奇,你可以看看最终演示的源代码,其中还包含指向我用来编写物理-y 位的资源的链接。

…现在有弹性墙壁和弹性球!
我不想对这个实验进行任何精确的测量,因为我没有优化物理算法,也没有优化我对 WebGPU 的使用。然而,即使是这种幼稚的实现也表现得非常好(在我的 M1 MacBook Air 上)这一事实给我留下了深刻的印象。在我们降到 60fps 以下之前,我可以去大约 2500 个球。但是,查看轨迹,很明显,在 2500 个球时,瓶颈是 Canvas2D 尝试绘制场景,而不是 WebGPU 计算。
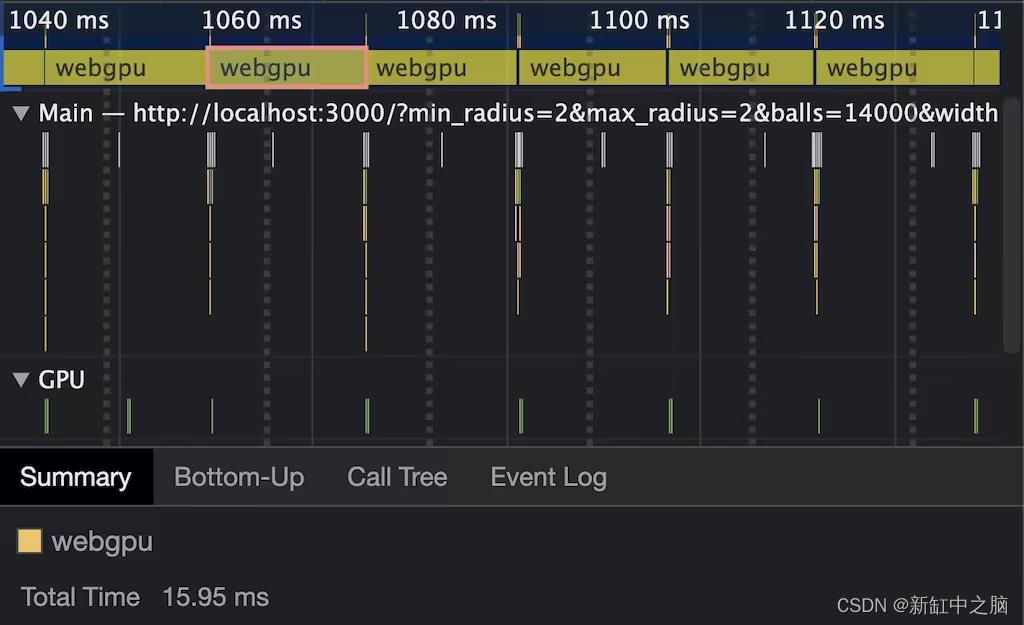
在 14000 个球上,原始 GPU 计算时间在 M1 MBA 上达到约 16 毫秒
为了看看这到底有多快,我禁用了渲染,而是performance.measure()在用尽 16 毫秒的帧预算之前查看我可以模拟多少个球。这发生在我的机器上大约 14000 个球。这种未经优化的快速运行真的让我陶醉于 WebGPU 让我访问的计算能力。
16、WebGPU稳定性和可用性
WebGPU 已经开发了一段时间,我认为标准组渴望将 API 声明为稳定的。话虽如此,该 API 仅在 Chrome 和 Firefox 中可用。我对 Safari 提供此 API 持乐观态度,但在撰写本文时,Safari TP 中还没有什么可看的。
在稳定性方面,即使在我为本文进行研究时,也发生了一些变化。例如,属性的语法从 更改[[stage(compute), workgroup_size(64)]]为@stage(compute) @workgroup_size(64)。在撰写本文时,Firefox 仍在使用旧语法。passEncoder.end()曾经是passEncoder.endPass()。规范中还有一些内容尚未在任何浏览器中实现,例如着色器常量或移动设备上可用的 API。
基本上我想说的是:当浏览器和标准人员处于这个 API 的 ✨stable✨ 之旅的最后阶段时,预计会发生更多的重大变化。
17、结束语
拥有一个现代 API 来与 Web 上的 GPU 对话将非常有趣。在投入时间克服最初的学习曲线之后,我真的觉得自己有能力使用 JavaScript 在 GPU 上运行大规模并行工作负载。还有wgpu,它在 Rust 中实现了 WebGPU API,允许你在浏览器之外使用 API。wgpu 还支持将 WebAssembly 作为编译目标,因此可以在浏览器外部和通过 WebAssembly 在浏览器内部本地运行 WebGPU 程序。有趣的事实:Deno是第一个开箱即用也支持 WebGPU 的运行时(感谢 wgpu)。
原文链接:WebGPU深入探索 — BimAnt
以上是关于WebGPU开发详解的主要内容,如果未能解决你的问题,请参考以下文章