深度学习中注意力机制集锦 Attention Module
Posted 青盏
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习中注意力机制集锦 Attention Module相关的知识,希望对你有一定的参考价值。
注意力机制模仿的是人类观察模式。一般我们在观察一个场景时,首先观察到的是整体场景,但当我们要深入了解某个目标时,我们的注意力就会集中到这个目标上,甚至为了观察到目标的纹理,我们会靠近目标,仔细观察。同理在深度学习中,我们提取到的信息流以同等重要性向后流动,而如果我们知道某些先验信息,我们就能够根据这些信息抑制某些无效信息的流动,从而使得重要信息得以保留。这是一种模式,而并非具体的公式,因此存在各种各样的实现方法。最为简单的理解方式,举个极端例子,对信息进行softmax后我们会得到每个logits的概率,这可以看成模型对每个logits的重视程度。概率越大,说明这个信息对模型越有利。很多时候我们都知道注意力机制可以抑制无效信息的前向移动,其实注意力机制还有利于梯度信息的后向传播,这在RNN这一类保存长期信息的过程中防止梯度消失尤其有效,所以也可以认为这是skip connect的一种特殊形式。
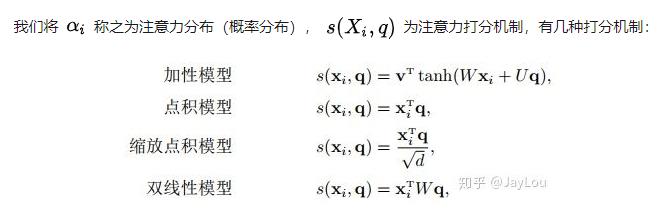
全局注意力:
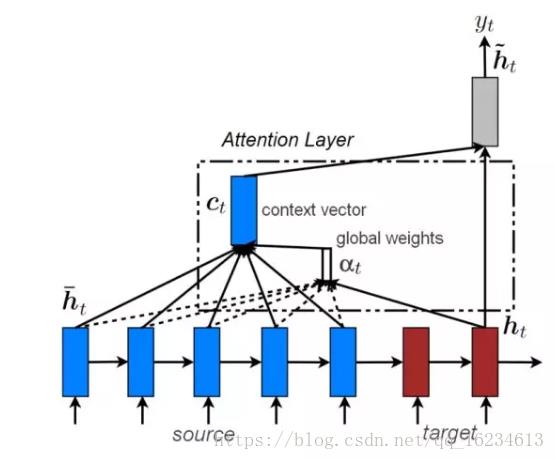
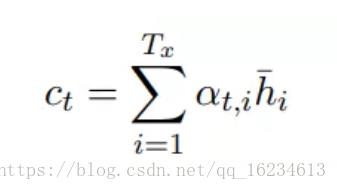

RNN模型输出的每一步隐藏状态ht-,在生成上下文向量c时,并不是简单的相加,而是利用ht和ht-二者之间计算一个score后进行softmax,从而生成对于ht-的全局注意力,进行加权相加。
局部注意力:

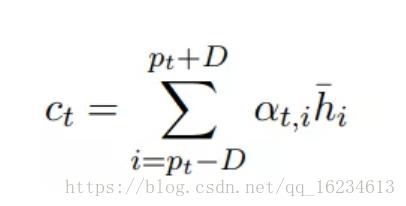

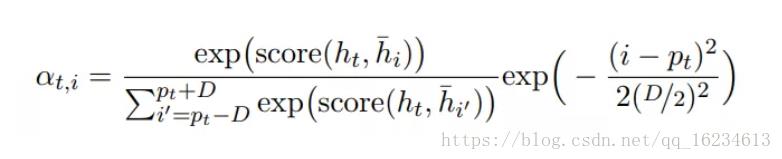
前面的全局注意力每生成一个词都需要考虑整个输入序列ht-,计算量较大,我们可以考虑对部分ht-进行计算,只关注2D+1窗口大小,其中pt是窗口中心。
自注意力:

隐藏向量 ht 首先会传递到全连接层。然后校准系数 α_t 会对比全连接层的输出 ut 和可训练上下文向量 u(随机初始化),并通过 Softmax 归一化而得出。注意力向量 s 最后可以为所有隐藏向量的加权和。
RA-CNN(Recurrent Attention):

与一般的attention机制输出概率不同,该attention回归出模型认为存在重点关注特征的坐标位置,将其裁剪放大后继续放入模型进行预测。模型存在两种loss:classification loss和ranking loss。
Advanced LSTM:
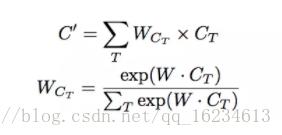

在LSTM中将前几个单元的输出同样输入到当前单元,实现历史信息的传递。在传递过程中使用注意力机制来控制信息量。
GAU:全局注意力上采样:

在使用金字塔特征进行上采样时加入注意力机制,使用高层全局特征信息对底层特征在组合时进行筛选。
Bottom-Up and Top-Down Attention:


这个模型主要用于视觉问答和图像标注之类的结合图像和NLP的task。第一张图为Bottom-Up attention,其实就是使用Faster R-CNN提取区域进行分类,由于提取出来的是一个个目标区域,可以认为比全局更为底层。提取出来的局部特征经过全局均值池化后形成k个特征Vi。第二张图里有Top-Down attention模块,可以看到这个LSTM模块输入的是语言LSTM的t-1隐状态、k个vi的均值(可以认为是图像的全局信息)和当前t时刻的词向量,输出的是t时刻隐状态,用于和k个区域图像特征生成关于v的attention,从而输出到语言LSTM中。有意思的是可以看到这两个LSTM在互相使用彼此的信息。
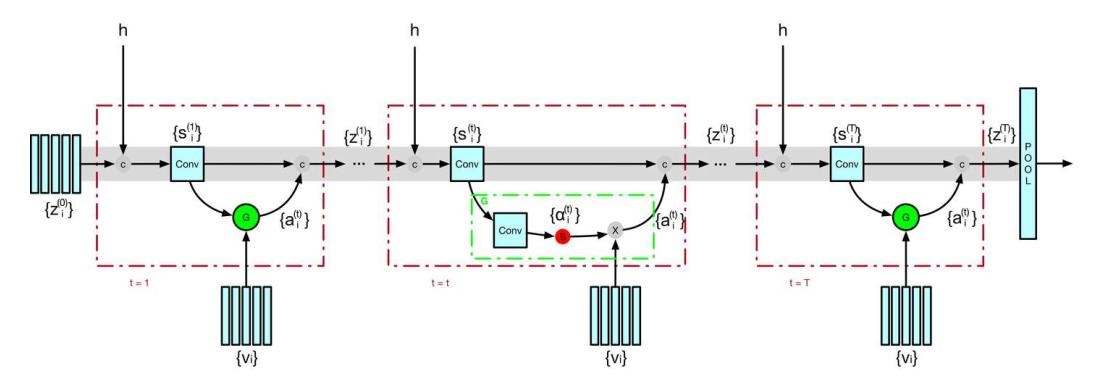
Sparse Attentive Backtracking(稀疏注意力回溯):
如前面介绍的全局注意力,一个很大的问题就是,模型每生成一个ht,都要与前面所有历史状态计算一个注意力机制,这对于模型的反向梯度传播的计算开销是极其昂贵的。但是对于我们人类来说,一般我们回想过去时只会与过去某几个时间点相关连。基于此稀疏注意力认为有些某些过去状态的考虑是没有必要的。
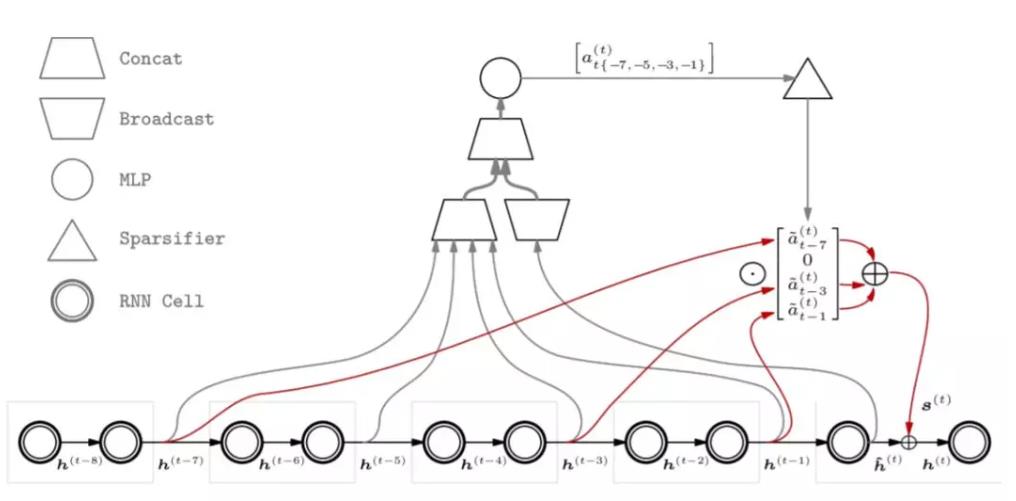
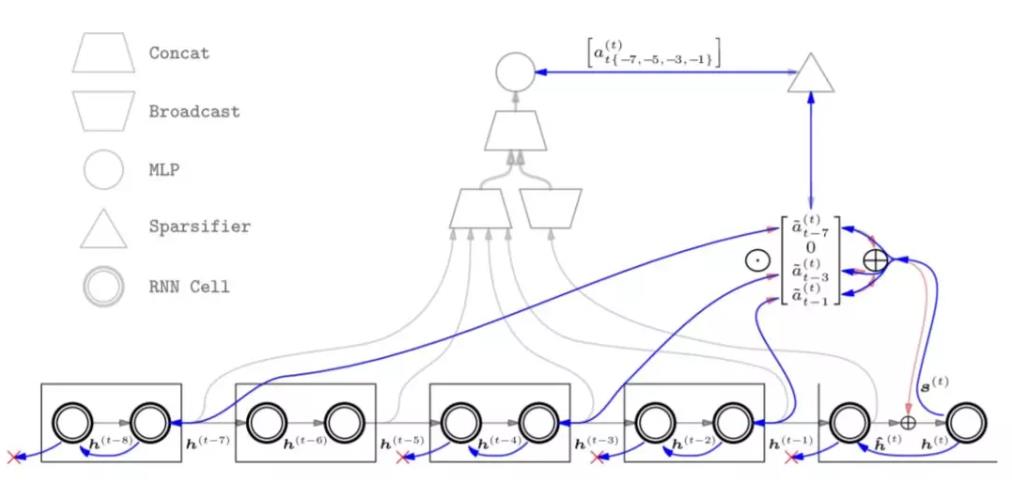
如上图展示了在 ktop = 3, katt = 2, ktrunc = 2 的情况下 SAB 中的前馈传播过程。灰色箭头显示了注意力权重 a(t)是如何被估计出来的,首先将历史记忆状态和当前的临时隐藏状态 hˆ(t)连接,然后通过多层感知机计算出原始注意力权重。稀疏处理器会选择出最大的 ktop 个原始注意力权重,并进行归一化处理,而其它的注意力权值则表示为 0。红色箭头显示了对应非零稀疏化注意力权值被加权求和的过程,然后将其添加到临时隐藏状态 hˆ(t) 中去计算最终的隐藏状态 h(t)。这样对于注意力权重0的就无需反向传递梯度了。下图表示梯度方向传播路径,其中红色叉叉表示传播路径被截断。
Stacked Latent Attention(层叠自注意力):

多注意力机制的叠加,第一张图里s是输出的权重,但存在一个问题就是s只是个概率,不利于梯度的后向传播,抑制了信息的流动,因此作者将注意力机制移出来,当成一路,而为了信息的流动,使用类似残差网络的跳跃连接直接向后流动。
Attention Is You All Need:
transformer的attention机制是将每个单词特征分别与句子中所有单词特征进行交互,然后加权求和获得一个新的特征表示,举例如下:
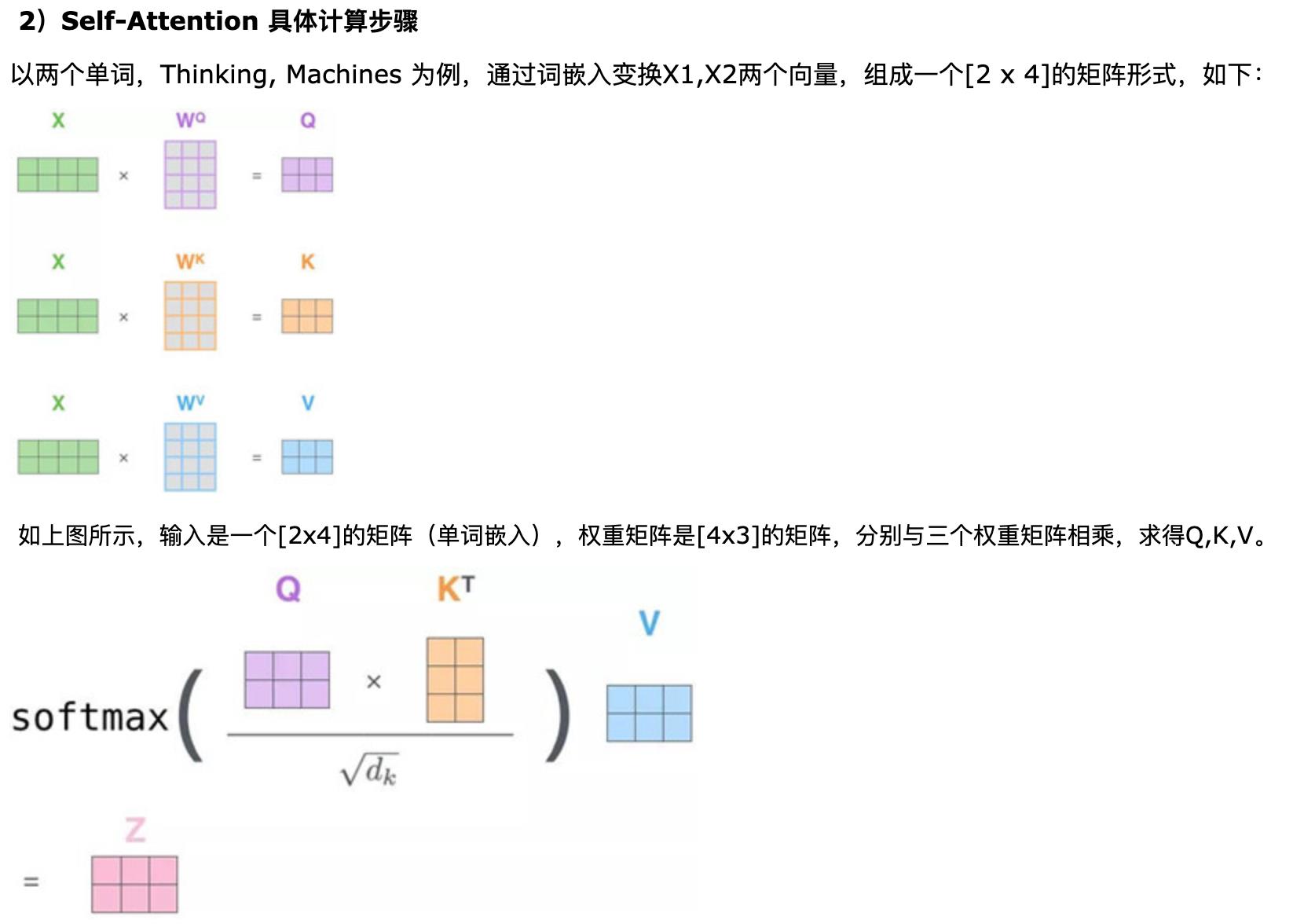
attention的详细操作如下:

然后对上面的单个attention机制操作h遍,concat起来:
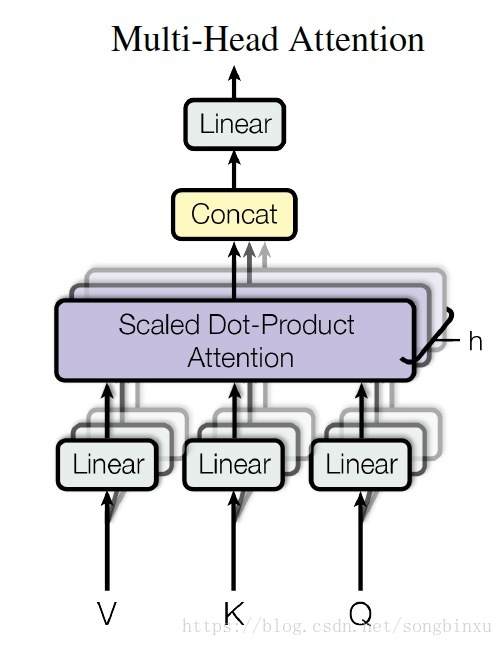
Transparent Attention:透明注意力:
注意力对前向传播的影响因直观的可视化和语言学阐释而受到广泛关注,但它对梯度流的影响却常常被忽略。考虑没有注意力机制的原始 seq2seq 模型。为了将解码器最后一层的误差信号传播到编码器的第一层,信号必须穿过解码器中的多个时间步,通过编码器-解码器瓶颈,再穿过编码器中的多个时间步,才能到达需要更新的参数。每个时间步都会有一定量的信息损失,尤其是在训练早期。注意力 (Bahdanau et al., 2015) 创建了一条从解码器到达编码器第一层的直接路径,确保信号随时间的高效传播。这一内部连接性的增强显著缩短了信用分配(credit assignment)路径 (Britz et al., 2017),使得网络不易受到梯度消失等优化问题的影响。
但对于更深的网络,误差信号还需要通过编码器层。为此我们提出了一种注意力机制的扩展,类似于创建沿着编码器深度的加权残差连接,这使得误差信号可以同时沿着编码器层和时间进行传播。使用可训练权重,这一「透明」注意力可使模型根据训练阶段灵活调节编码器中不同层的梯度流。
Pervasive Attention:普适注意力:
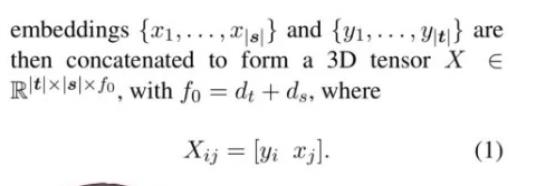

该注意力机制旨在使用2d CNN解决序列attention问题。它使用source sentence embedding后的特征与target sequence embedding后的特征concat后形成了3D的特征。为了避免卷积核感受到还未预测的特征,对卷积核的后半部分mask掉。如图中卷积层的filter大小是3×3,它只能根据先前的输出计算,不能读取目标序列内容。图中深蓝色表示一层感受野,浅蓝色是二层感受野,灰色部分是filter被禁止查看的部分
层次注意力(Hierarchical Attention):
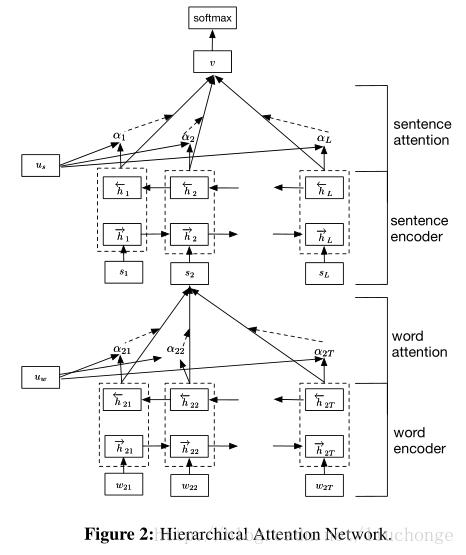
对句子中的单词首先做attention机制,然后生成关于句子的语义编码,再对句子生成的语义编码重新进行attention机制加权,因而叫层次。
SENET:

对特征通道做attention。
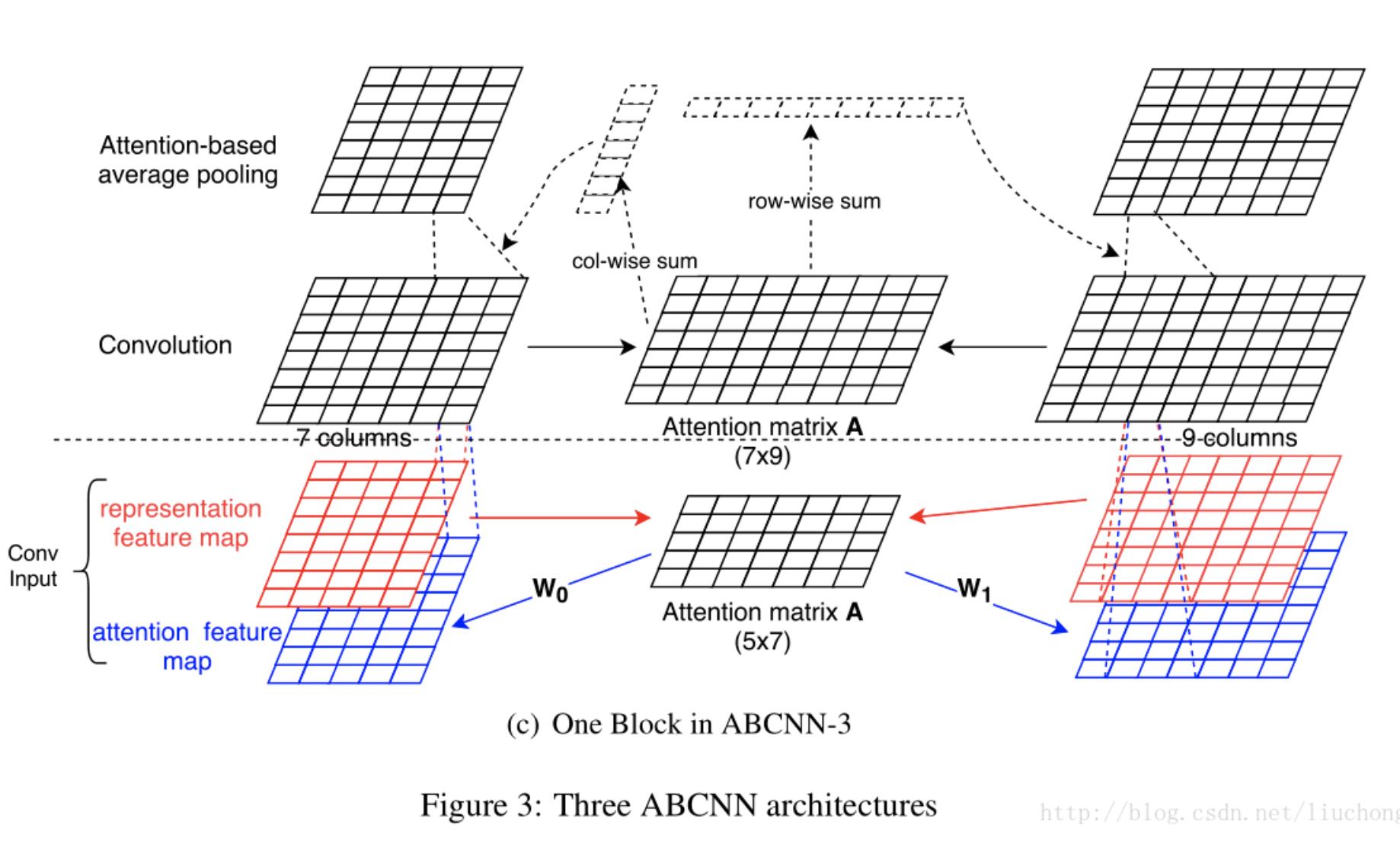
ABCNN:
对两个特征图做attention,一是对输入生成attention map加入特征图,另外是对输出就行weighted pooling。链接
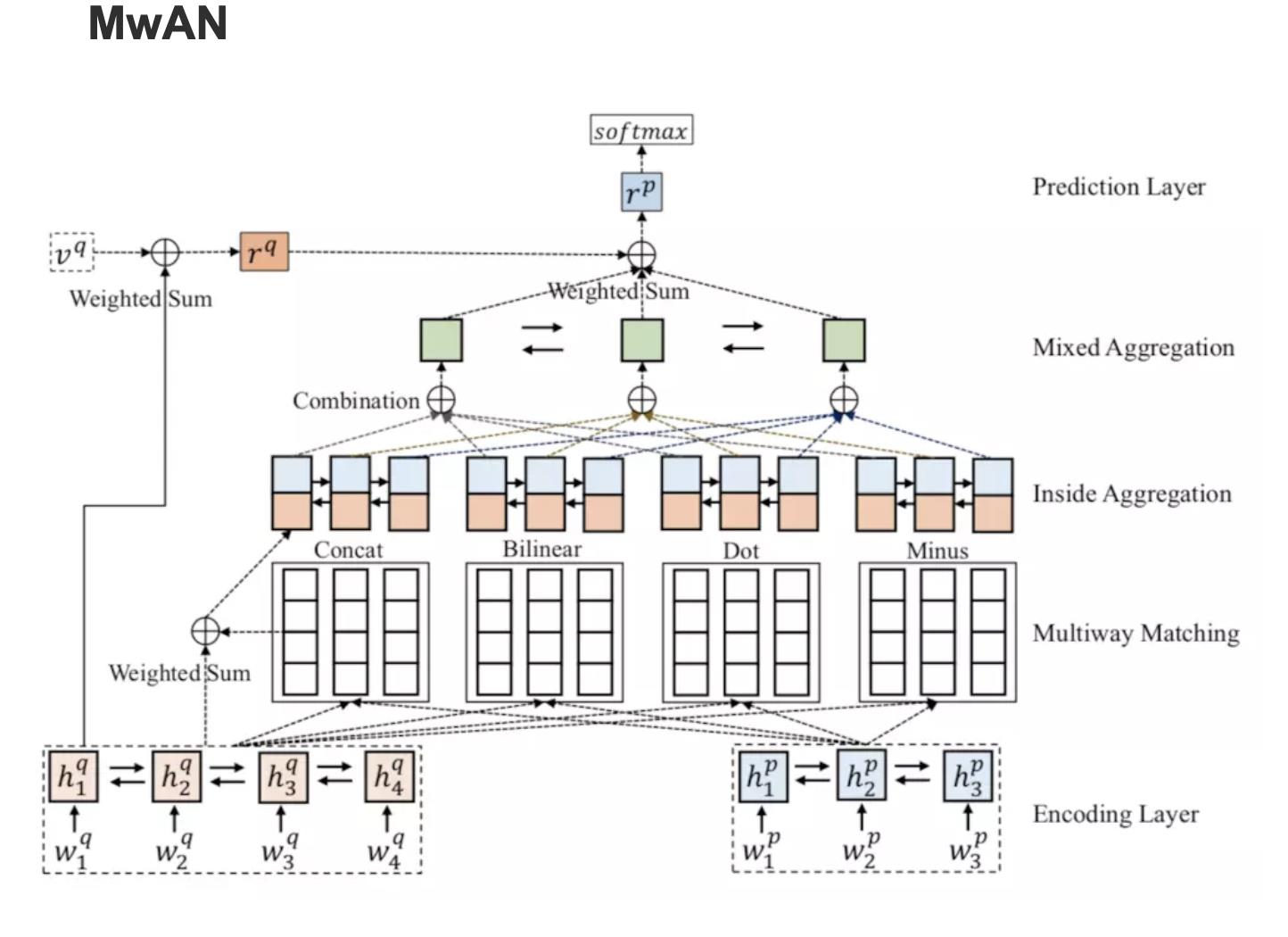
MwAN:
使用了四种不同的attention机制来多角度提取特征。链接
以上是关于深度学习中注意力机制集锦 Attention Module的主要内容,如果未能解决你的问题,请参考以下文章
注意力机制 attention 注意力分数 动手学深度学习v2
深度学习与图神经网络核心技术实践应用高级研修班-Day1注意力机制(Attention)
注意力机制 attention 注意力分数 动手学深度学习v2
《自然语言处理实战入门》深度学习基础 ---- attention 注意力机制 ,Transformer 深度解析与学习材料汇总