大饼博士的神经网络/机器学习算法收录合集:2020年整理,持续更新ing
Posted 大饼博士X
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大饼博士的神经网络/机器学习算法收录合集:2020年整理,持续更新ing相关的知识,希望对你有一定的参考价值。
文章目录
- Reversible Residual Network
- 异步SGD的延迟补偿算法,DC-ASGD,2016年
- CoordConv, Uber, 2018 [1] [2]
- NullHop,稀疏CNN计算加速器, ETH Zurich,2018
- Learning rate, batchsize and minima [3]
- An Empirical Model of Large-Batch Training
- 参考资料
今年外面疫情严重,周末在家也不能出去,只能在家看论文了,哈哈。我看的论文很具有随机性,只要我能看懂并且觉得有点意思的就放在这里吧。来源都是一些公众号推荐,或者晚上随机搜索到的,主要是关注一些我觉得有趣的AI算法、网络结构、硬件论文。比较杂,随时看到随时记录,主要是自己mark用的。
Reversible Residual Network
论文:The Reversible Residual Network: BackpropagationWithout Storing Activations,2017
这篇论文是17年提出来的,我一直觉得挺有意思,就记录一下。在传统的BP算法训练NN的过程中,需要记录每一层的activations(Feature Map的一部分),作者认为这些activations太占空间了。因此就设计了Reversible网络结构,让每一层的activations(input)可以用下一层的activations(也就是这一层的输出)计算得到。
算法既参考了Residual Block的设计,又参考了以前一些旧的Reversible Network的设计思想。
下面是标准的Residual Block设计,其中F表示residual function。

以前也有一些Reversible Architectures,比如下面两种:

和
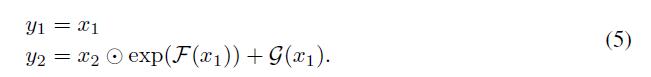
什么意思呢?我们先看(4),就是说,把输入的神经元分成两部分,
x
1
x_1
x1和
x
2
x_2
x2。然后前向计算完成后,得到了
y
1
y_1
y1和
y
2
y_2
y2。在反向的时候,我们可以不用一直保存
x
1
x_1
x1和
x
2
x_2
x2,只需要知道
y
1
y_1
y1我们就直接得到了
x
1
x_1
x1,然后我们就可以通过重新计算
F
(
x
1
)
F(x_1)
F(x1),然后
x
2
=
y
2
−
F
(
x
1
)
x_2 = y2 - F(x_1)
x2=y2−F(x1)。(5)也是类似了,无非注意点乘的计算罢了。
但是本文作者认为上述两种方法在表达网络能力上不足,因此提出了自己的方法(如下图):
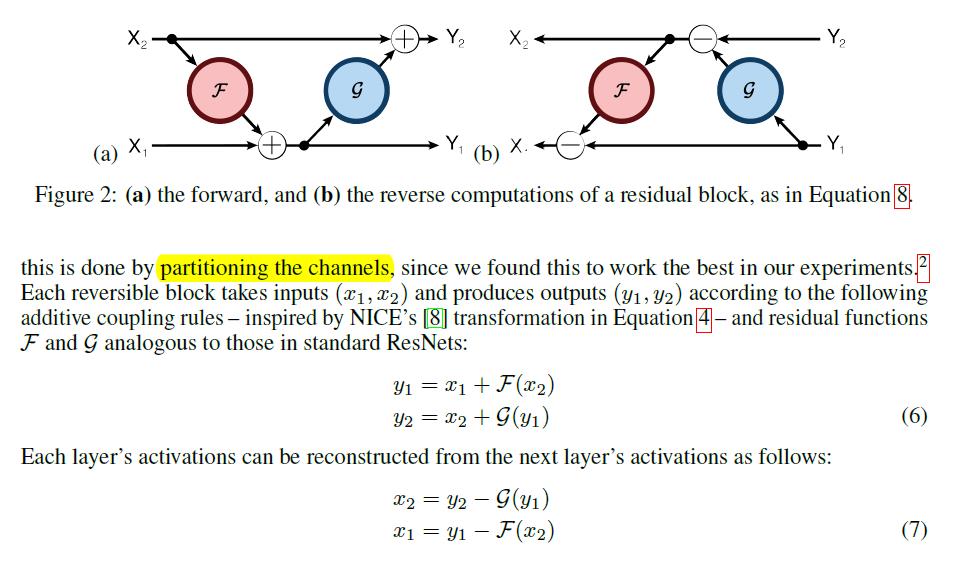
需要有两个residual function F和G,然后通过(6)可以完成前向计算。通过(7)我们就可以在反向的时候重新计算出
x
1
x_1
x1和
x
2
x_2
x2。原理上就是这样的,然后作者又说在实际实现的时候再引入一个
z
1
z_1
z1。实验结果就是,和一般的ResNet效果基本差不多。
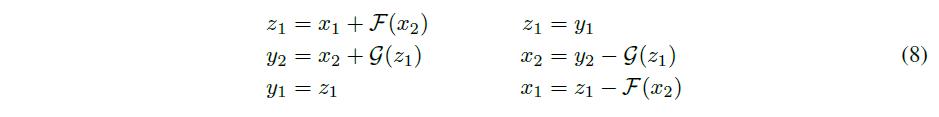

异步SGD的延迟补偿算法,DC-ASGD,2016年
论文:Asynchronous Stochastic Gradient Descent with Delay Compensation
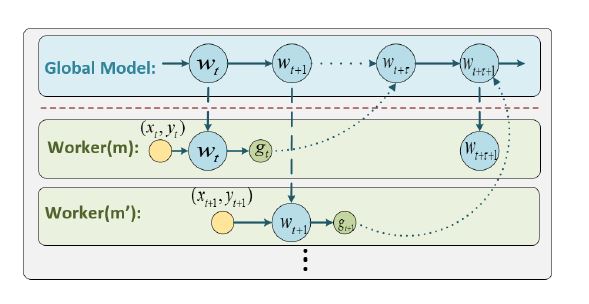
作者考察的算法是传统的异步SGD,如下图,每一个worker之间不会进行等待同步,因此会出现更新全局参数时,用的旧的参数产生的梯度,叫做delayed gradient问题。

这样就对更新过程产生了影响,往往体现在精度不如同步SGD。
对新参数梯度在旧参数梯度上一阶泰勒展开:

上面的(3)式,作者认为误差的来源就在于用的是0阶泰勒展开项来作为跟新梯度(用
g
(
w
t
)
g(w_t)
g(wt)来近似
g
(
w
t
+
τ
)
g(w_t+\\tau)
g(wt+τ)),这个就是精度误差的来源。所以作者提出用一阶展开来近似。其中
∇
g
(
w
t
)
\\nabla g(w_t)
∇g(wt)实际上是Hessian矩阵。作者基于Fisher矩阵是Hessian矩阵的一个合理估计,则计算Fisher矩阵来代替上面的Hession矩阵。Fisher矩阵如果不知道的话可以看下我写的:一文看懂二阶优化算法Natural Gradient Descent(Fisher Information)
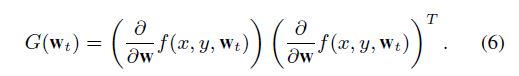
但实际上Fisher矩阵完全计算也是不可能的,参数大的话也存不下。作者又提出只保留Fisher矩阵的对角线元素(也就是梯度的对角线元素平方)。

因此得到了DC-ASGD算法的流程:
- Worker:没什么区别,就是拉一个新的Weight下来,然后算一个梯度,再把梯度推到Parameter Server上去。
- Parameter Server:需要维护每一个Worker的发送时刻的Weight版本 w t w_t wt,然后当PS收到新的梯度Push时,就用上面的(10)式来更新Global Parameter;当PS收到拉参数请求,就把当前的Global Parameter w t w_t wt备份一下(对应device m m m),然后把 w t w_t wt发给device m m m。
算法效果还算不错,在Imagenet上,16卡异步训练甚至可以比普通的SGD收敛地更好。再大的规模就不知道了。不过我们可以仔细看下这个算法,需要备份
W
b
a
k
(
m
)
W_bak(m)
Wbak(m)对每一个m(卡),这样,会需要多存M份Weight!这个代价还是很大的。我感觉这个存储代价是一个问题。如何在延迟补偿技术和额外存储开销上找到好的平衡点,也许是以后其他工作需要考虑的。

CoordConv, Uber, 2018 [1] [2]
An Intriguing Failing of Convolutional Neural Networks and the CoordConv Solution论文中,作者研究并分析了卷积神经网络的一种常见缺陷,即它无法将空间表示转换成笛卡尔空间中的坐标和one-hot像素空间中的坐标。这很意外,因为这些任务似乎很简单,并且此类坐标的转换也是解决常见问题的必备方法,例如图像中的物体检测、训练生成模型、训练强化学习智能体等等,所以也很重要。经过研究我们发现,这些任务已经多多少少受到卷积结构的限制。所以为了提升性能,我们提出了一种名为CoordConv的解决方案,在多个领域进行了成果展示。
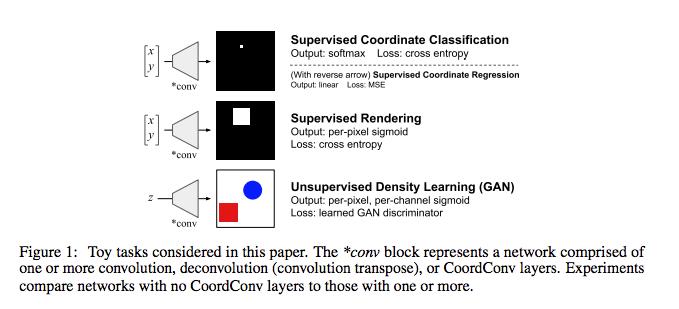
- Supervised Coordinate Classification task:输入x, y,输出一张图片只有x, y 为白色1,其余位置都为黑色0。 我们发现使用Convolution 的方法仅能够达到80% 的准确度,当添加CoordConv 的时候就可以达到趋近于100% 的准确度。
- Supervised Rendering task:输入x, y,输出一张图片以x, y为中心,画出一个白色正方形,其余位置都为黑色。

另外:
- Object Detection: 在侦测MNIST 的资料集中,相较于没有使用CoordConv,加入CoordConv 后让IoU 提升了24%
- Generative Model: 这边是假设mode collapse 的问题是因为latent space 无法学习好空间的相关性所导致的,而这时候使用CoordConv 或许会有帮助,感觉是结果论。
方法就是:在input层上添加(i,j)坐标两个channel,会预处理在[-1, 1] 之间。有一些实验还有添加r coordinate(添加第3 个Channel),

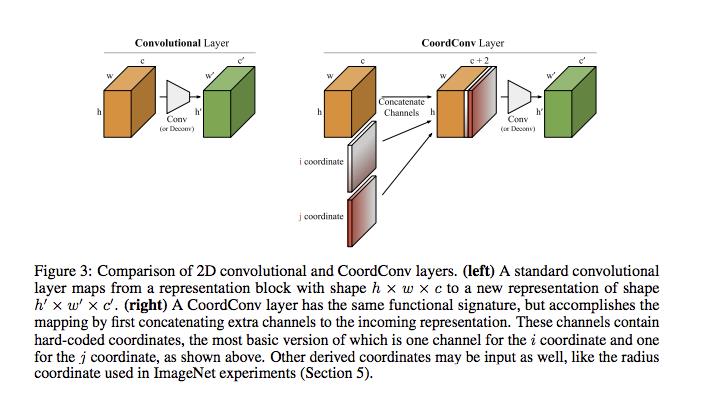
很简单,有趣的一个工作。我个人理解相当于在Conv(第一层)中添加了一个位置编码,这个和NLP的language model任务中position embedding有点类似,但是Coordconv还是简单粗暴了一些,是一种绝对位置编码,没有考虑相对位置编码,因此损失了Conv的平移不变性的特点。我觉得如果采用相对位置编码,通过learning对应的weight,应该还是可以做到平移不变性的。(Uber这篇也被怼了:Uber发布的CoordConv遭深度质疑,“翻译个坐标也需要训练?” )
NullHop,稀疏CNN计算加速器, ETH Zurich,2018
论文:NullHop: A Flexible Convolutional Neural Network Accelerator Based on Sparse Representations of Feature Maps, 2018
论文比较完整,设计了一个Feature Map稀疏压缩和计算的加速器,实现ASIC仿真,并在FPGA上实现。原理不算复杂,加速器单元组成如下图,详细我就不展开了。简单说几点,CCM是计算单元,一个MAC单元处理一个卷积filter的参数,而所有MAC单元会共享相同的数据。

重点看一下稀疏编码的方式,采用简单的Non-zero Value List,加一个bitmap表示0和非0。对于每一个16bit数据,需要多1个bit的Sparsity Map,因此稀疏率(0的比例)只要> 1/16就在空间上有的赚。
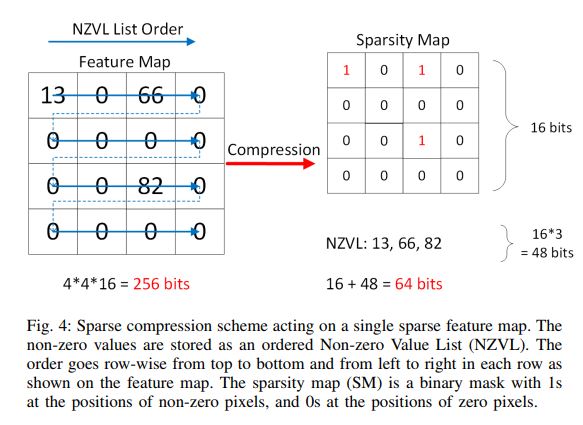
保存的格式如下:先存一个16bit的SM,只要不是全0,后面就跟着非0的像素值。如果是全0的SM,后面会继续跟一个SM。在计算的时候,只需要解码SM,来获得一次计算的像素值个数,以及需要取的weight的位置,取出相应的weight值,参与乘累加运算。因为做的33卷积为例,送进去44数据,一次会出来2*2个数据结果(把channel维度累加完。)

Learning rate, batchsize and minima [3]
Stochastic gradient descent is no different, and recent work suggests that the procedure is really a Markov chain that, under certain assumptions, has a stationary distribution that can be seen as a sort of variational approximation to the posterior. So when you stop your SGD and take the final parameters, you’re basically sampling from this approximate distribution. I found this idea to be illuminating, because the optimizer’s parameters (in this case, the learning rate) make so much more sense that way.
As an example, as you increase the learning parameter (learning rate) of SGD the Markov chain becomes unstable until it finds wide local minima that samples a large area; that is, you increase the variance of procedure. On the other hand, if you decrease the learning parameter, the Markov chain slowly approximates narrower minima until it converges in a tight region; that is, you increase the bias for a certain region.
Another parameter, the batch size in SGD, also controls what type of region the algorithm converges two: wider regions for small batches and sharper regions with larger batches.

SGD prefers wide or sharp minima depending on its learning rate or batch size. Wider minima:large learning rate,small batch size,i.e., large variance. Sharp minima:small learning rate,large batch size,i.e., small variance.
An Empirical Model of Large-Batch Training
参考资料
[1] https://xiaosean.github.io/deep%20learning/computer%20vision/2018-12-23-CoordConv/
[2] Uber提出CoordConv:解决普通CNN坐标变换问题
[3] http://hyperparameter.space/blog/when-not-to-use-deep-learning/
[4] NullHop: A Flexible Convolutional Neural Network Accelerator Based on Sparse Representations of Feature Maps,2018
[5]
[6]
[7]
[8]
[9]
[10]
以上是关于大饼博士的神经网络/机器学习算法收录合集:2020年整理,持续更新ing的主要内容,如果未能解决你的问题,请参考以下文章