用 Python 计算 Hurst 指数并预测市场趋势
Posted Python中文社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用 Python 计算 Hurst 指数并预测市场趋势相关的知识,希望对你有一定的参考价值。

建造水库是一个高风险的问题。如果计算错误,成千上万的人可能会失去他们的家园。在20世纪中期,英国水文学家埃德温-哈罗德-赫斯特在解决这类问题方面取得了重大突破。他开发了后来被称为Hurst指数的东西,这是一个衡量时间序列中自动相关的指标。虽然它是为了估计河流中的水量而开发,但正如我们所期望的那样,对于涉及时间序列的数学计算,Hurst指数在金融市场研究中得到了有趣的应用。
下面将展示如何计算Hurst指数,并使用它来评估标准普尔500指数、比特币和美元/瑞士法郎交易对的特性,看看我们是否能理解这些金融序列的交易趋势。
什么是Hurst指数?
Hurst指数可以用来确定一个时间序列是否倾向于向单一方向移动(H>0.5),振荡(H<0.5),或随机(H=0.5)。
虽然赫斯特发现这种关系在各种自然现象中很有用,如洪水、河流排放和树木年轮,但我们也可以用它来将一个市场归类为趋势性或均值回归性。如果我们知道一个市场倾向于以某种方式行事,我们可以尝试用适当的均值回归或趋势跟踪策略来捕捉这一点,或者在你的算法交易系统中使用它作为一个过滤器。
如何计算Hurst指数?计算Hurst指数需要估计多个不同时间段的R/S统计量,然后将其与各时间段绘制成对数图,并找出斜率。这条线的斜率就是Hurst指数 —— H。
有多种方法来估计Hurst指数。就我所知,重新标定的范围分析方法是最古老的,但使用去趋势波动分析(DFA)是最常见的。我们将使用后者,因为尽管它听起来很复杂,但它只需要3-4行代码就能运行,而且比我的重标范围分析实现快一个数量级。这两种方法都是可行的,但它们略有不同。
假设我们有一个价格序列,我们称之为x。然后我们可以看一下x在不同时间t的差异,并取其差值。这个时间差将被称为lag(滞后)。我们想得到这些滞后差值的标准差的关系。
我们可以按以下步骤写出我们的计算结果。
1、选择一个滞后期的范围(如2到100)。
2、计算x中所有点的滞后差值。
3、计算每个lag的标准差。
4、将标准差的对数与lag的对数作图,以估计H。
数学上的公式为:
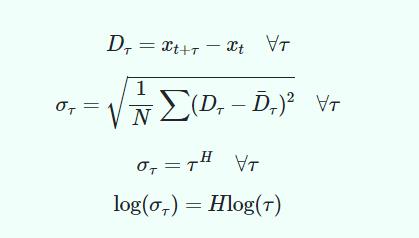
将所有的数据插入最后一个方程,我们可以找到最佳拟合线,我们就得到了H的值。让我们来看看如何用Python来做这件事!
用Python中计算Hurst指数
首先导入几个包:
import numpy as np
import matplotib.pyplot as plt然后定义我们的 hurst()函数。
def hurst(price, min_lag=2, max_lag=100):
lags = np.arange(min_lag, max_lag + 1)
tau = [np.std(np.subtract(price[lag:], price[:-lag]))
for lag in lags]
m = np.polyfit(np.log10(lags), np.log10(tau), 1)
return m, lags, tau我们可以通过使用一个计算所有滞后差值的标准差的列表来理解,将所有的东西整合在几行紧凑的线条中。
接下来,让我们在一些我们知道答案的序列上测试这个函数。这将有助于确保我们的计算是正确的。
N = 10000
rand = np.cumsum(np.random.randn(N) + 0.01)
mr = np.cumsum(np.sin(np.linspace(0, N/3*np.pi, N))/2 + 1)
tr = np.cumsum(np.arange(N)/N)
m_rand, lag_rand, rs_rand = hurst(rand)
m_mr, lag_mr, rs_mr = hurst(mr)
m_tr, lag_tr, rs_tr = hurst(tr)
print(f"Hurst(Random):\\tm_rand[0]:.3f")
print(f"Hurst(MR):\\tm_mr[0]:.3f")
print(f"Hurst(TR):\\tm_tr[0]:.3f")Hurst(Random): 0.499
Hurst(MR): 0.075
Hurst(TR): 0.997此外,我们可以将这些系列与我们的lag值和统计数据的对数图一起绘制。
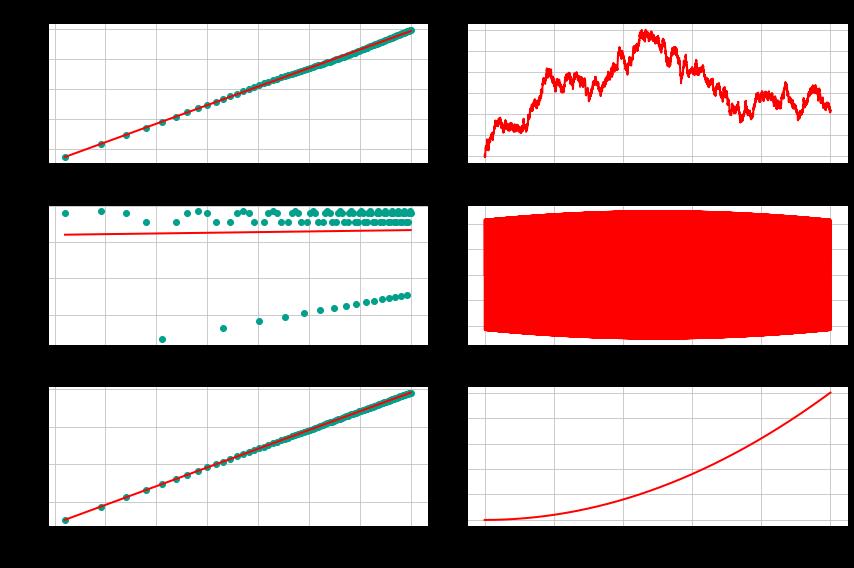
左栏中的图是对数图。你可以看到我们试图在Y轴上拟合标准差统计数字。对于随机和趋势的时间序列,它们匹配得很好。均值回归的是一个快速振荡的正弦波——完全不一致,但斜率仍然是正的,并且小于0.5。在你的生活中,你永远不会看到这样的金融时间序列,但它应该给你信心,我们的函数是有效的!
金融时间序列的Hurst指数
将Hurst应用于金融数据也同样简单明了。我们可以把它应用于一些常见的时间序列,看看我们得到什么。
我们将使用美元/瑞士法郎交易对、BTC和SPY来感受一下这些数据。
用yfinance软件包抓取数据。
import pandas as pd
import yfinance as yf
tickers = ['CHF=X', 'BTC-USD', 'SPY', 'GLD', 'USO']
start = '2010-01-01'
end = '2021-12-31'
yfObj = yf.Tickers(tickers)
df = yfObj.history(start=start, end=end)
df.drop(['Stock Splits', 'Dividends', 'Volume',
'Open', 'High', 'Low'], axis=1, inplace=True)
df.columns = df.columns.swaplevel()我们在这里只对收盘价感兴趣,所以我们可以放弃所有其他的列,并在这些列上运行swaplevel(),这样我们就可以按股票代码进行索引。
接下来,我们需要通过Hurst()函数运行每个时间序列,以获得指数和相关值。
vals = c[0]: hurst(df[c].dropna().values) for c in df.columns一旦完成,我有一个辅助函数来绘制结果。
def plotHurst(m, x, y, series, name):
fig, ax = plt.subplots(1, 2, figsize=(15, 6))
ax[0].plot(np.log10(x), m[0] * np.log10(x) + m[1])
ax[0].scatter(np.log10(x), np.log10(y), c=colors[1])
ax[0].set_title(f"name (H = m[0]:.3f)")
ax[0].set_xlabel(r"log($\\tau$)")
ax[0].set_ylabel(r"log($\\sigma_\\tau$)")
ax[1].plot(series)
ax[1].set_title(f"name")
ax[1].set_ylabel("Price ($)")
ax[1].set_xlabel("Date")
return fig, ax这使得绘制我们的数值变得更加容易。如果我们想绘制所有的数值,我们可以循环浏览我们的vals字典,并调用plt.show(),如下面的代码所示。
for k, v in vals.items():
fig, ax = plotHurst(*v, df[k], k)
plt.show()让我们依次看一下结果,看看我们是否能从Hurst指数告诉我们的东西中得到一些启示。
美元/瑞士法郎交易对均值回归
我们将从Hurst指标中看到的最强烈的信号开始,即美元/瑞士法郎交叉。
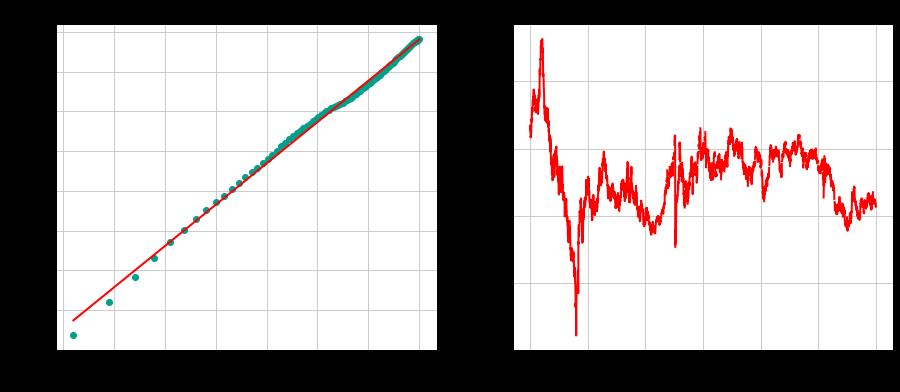
大多数交易员都有一种直觉,即货币对总体上是均值回归的,而对于强势货币之间的货币对,如美元和瑞士法郎,它尤其明显。
这正是我们在这里看到的情况。
不过,值得注意的是,较短的时间框架与我们在这里看到的较长的时间框架有一定的偏差。在最短的时间范围内,已实现波动率的期限结构(即蓝点所在的位置)低于红线。
出于好奇,我绘制了各种最大lag值的Hurst指数,看看这个系列是否曾经成为一个趋势系列。
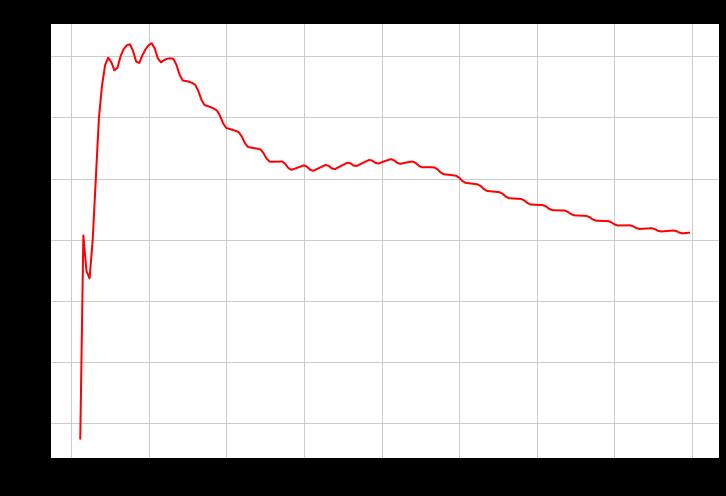
并非如此。
它确实越长越平均,表明美元和瑞士法郎之间有一个相当稳定的长期关系。这是每日数据,所以它可以提供一些指导,作为你应该交易的时间框架。考虑到它在60天以上会变得更加均值化,也许在这个时间范围内(或更长)运行的均值化策略将是最有效的。
比特币是一种动量游戏
比特币暴涨暴跌的势头恰恰相反。
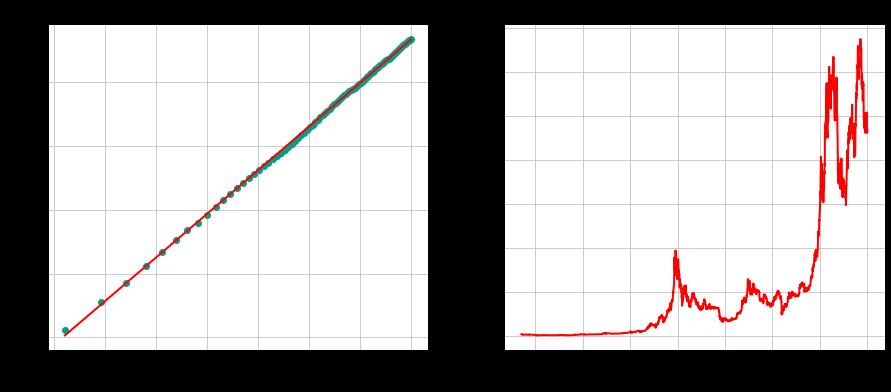
Hurst指数给出了一个相当明确的信号:这是一个动量交易,而已实现的波动率期限结构显示出令人惊讶的少数偏差。
但有趣的是,2021年的情况。
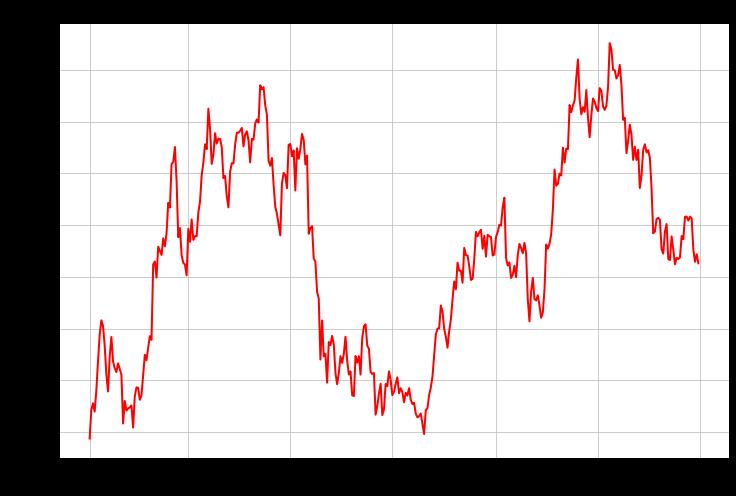
在比特币2020年的巨大牛市之后,它在2021年度过了一个随机/平均回归阶段。请注意,这不是那么多的数据,但有趣的是,不知道比特币是否已经进入了一个趋势变化。在2017年的大牛市之后,它在2018-2019年进入了一个类似的趋势,它有两年时间在进行均值回归,直到2020年起飞。
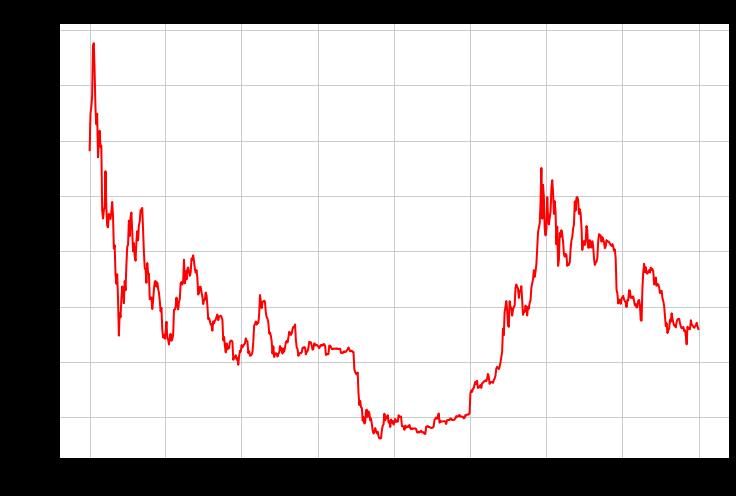
到目前为止,2022年已经显示出类似的模式。它能在今年剩下的时间里持续下去吗?
标准普尔500指数的均值回归
这个对我来说是最大的惊喜。Hurst指数显示,标普500指数是一个平均回归的时间序列。
看看它右边的价格图,它看起来有一个强大的上升趋势。
我们的算法揭示了我们眼睛看不到的东西。
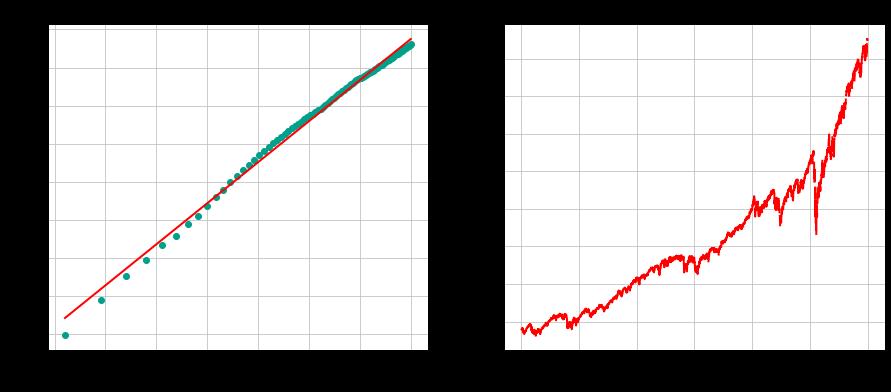
我们可以对标准普尔500指数进行与美元/瑞士法郎汇率相同的分析,看看在不同的滞后期是否有任何拐点或赫斯特指数的变化。
当我们这样做时,我们会得到下面的图表。
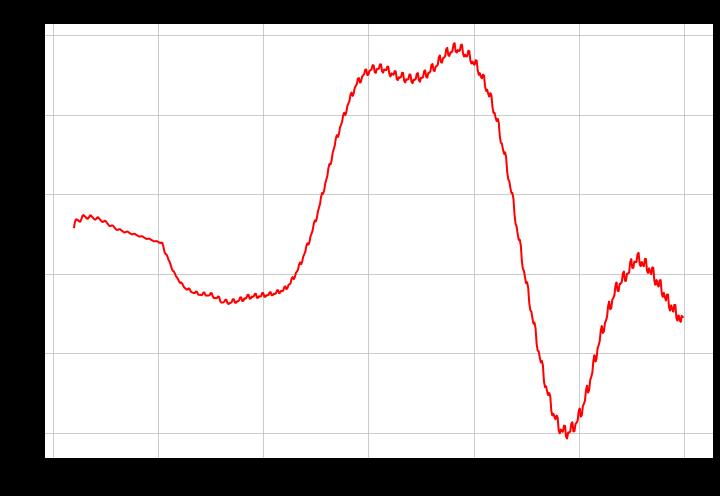
在这幅图中,H值随着滞后期的变化而明显变化。在中短期内,该系列是平均回归的,但在较长的时间范围内,它变得有强烈的趋势性。在非常长的时间内(超过400天),它又回到了强烈的均值回归。
让我们看看这在不同的时间范围内是否成立。
我们将回到过去,从1993年开始到2021年,获取SPY的数据。这将产生7,284个交易日。此外,我们将把它分为四个时间段,并在这四个时间段中的每一个时间段运行相同的分析,以查看SPY的行为是否在较小的间隔内发生变化。
这就产生了下面的图表。
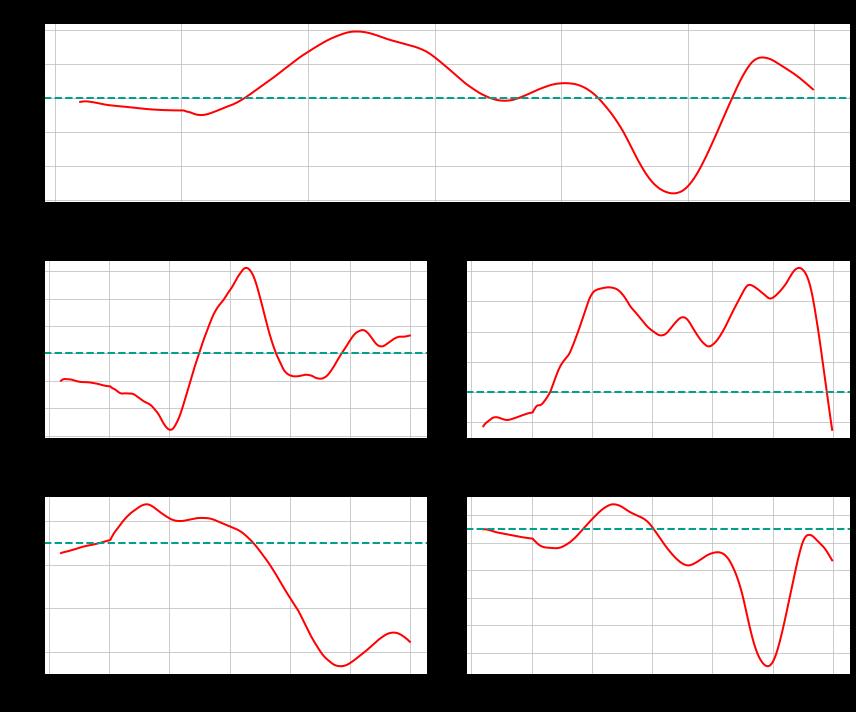
这表明,标准普尔500指数在不同的lag(滞后)期会经历更多的趋势和更多的均值回归时期。例如,比较2000-2007年期间。在这里,我们从互联网的繁荣和萧条到全球金融危机的高峰,几乎所有的滞后期都是趋势的。从那时起,在200-300区间内,趋势的持续程度较低,但其他地方的均值回归更为普遍。
值得注意的是,在我们看的每一个时间框架内,该系列似乎都在200-300天范围内有趋势。这似乎表明,标普500指数在这些时间范围内表现出强烈的趋势行为,可以通过趋势跟踪模型加以利用,而均值回归模型在较短的时间范围内会更有价值。
这种对200-300天范围内趋势的观察似乎与著名的海龟交易员杰里-帕克的轶事观察相吻合,即现代趋势跟踪在这些200天以上的时间范围内效果最好。
总结
一个市场是倾向于趋势、均值回归,还是随机的,这对交易者来说是有价值的信息。虽然赫斯特指数本身并不是一个入场信号,但它可以作为一个系统的过滤器。考虑到市场制度可能会随着时间的推移而发生变化,有利于一种或另一种方法,用Hurst过滤器覆盖你的模型,可以帮助防止你的算法在均值回归的市场中买入突破,或在市场走向新高时在回撤之前做空。
从本质上讲,它可以帮助你的算法与它所交易的市场相匹配。当然,这需要大量的回测。

以上是关于用 Python 计算 Hurst 指数并预测市场趋势的主要内容,如果未能解决你的问题,请参考以下文章
采用R/S分析法的Hurst指数估计算法——Python实现
采用R/S分析法的Hurst指数估计算法——Python实现