各种熵,条件熵,KL
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了各种熵,条件熵,KL相关的知识,希望对你有一定的参考价值。
参考技术A参考《统计学习方法》李航
通俗理解信息熵 - 忆臻的文章 - 知乎 https://zhuanlan.zhihu.com/p/26486223
熵表示一个事件的信息量。
一般认为,如果一个事件的随机性很大,那么这个事件的熵很大。
如果一个事件比较确定,那么这个事件的熵很小。
一个【具体】事件的信息量应该是随着其发生概率而递减的,且不能为负。
对于一个二分类事件,概率为[0.9999,0.0001],基本就是个随机性很小的事件,对应它的熵应该很小。
反之,如果这个二分类事件概率为[0.5,0.5],比如抛硬币,正反概率差不多,基本很难确定,那么它的熵很大。
定义:
设x是一个取有限个值的离散随机变量,其概率分布是:
则随机变量x的熵定义为: ,若 则定义0log0=0。
在这里,一个事件分布的熵可以看作是 具体事件信息量的期望 。(即对各个事件的信息量依照概率加权)。
注意:最后得到的熵与x无关,只与概率分布有关。
所以我们可以得到二分类事件熵的函数图:
H(Y|X) : 是已知随机变量X的前提下,随机变量Y的不确定性。
定义:
即,已知X的取值情况,则先求x确定下的事件信息量,H(Y|X= ),再对信息量求一个期望。
信息增益:
知道随机变量X,使随机变量Y的信息,不确定性减少的程度。
g(D,A) = H(D) - H(D|A)
信息增益比:
参考花书《深度学习》第三章
如果我们对同一个随机变量x,有两个单独的概率分布,P(x)和Q(x),我们可以使用KL散度,来 衡量这两个分布的差异 。
p在前,表示以p为基准,去考虑p和q相差多少
信息量的差值:
表示分布差异,再×概率得到期望。
性质:
KL 散度有很多有用的性质,最重要的是它是 非负 的。 KL 散度为 0 当且仅当P 和 Q 在离散型变量的情况下是相同的分布(此时P(x)/Q(x)=1) ,或者在连续型变量的情况下是 ‘‘几乎处处’’ 相同的。因为 KL 散度是非负的并且衡量的是两个分布之间的差异,它经常被用作分布之间的某种距离。然而,它并不是真的距离因为它不是对称的:对于某些 P 和 Q,
pytorch对应损失函数:
示例
常用的损失函数。不具有对称性。H(P , Q)≠H(Q , P) 且非负。
二分类问题的交叉熵损失函数的本质是假设数据服从以模型输出为参数的伯努利分布的极大似然估计。(为什么交叉熵(cross-entropy)可以用于计算代价? - Chris的回答 - 知乎 https://www.zhihu.com/question/65288314/answer/244601417 )
实际计算:
可以直接 认为是这样的一个概率和,
如果是多分类,假设真实标签[0,1,2,1,1,2,1]
那就是
因为在实际运算中,目标label已确定,对应概率值就是1
机器学习——决策树
整理自:
https://blog.csdn.net/woaidapaopao/article/details/77806273?locationnum=9&fps=1
- 各种熵的计算
- 常用的树搭建方法
- 防止过拟合—剪枝
- 前剪枝的几种停止条件
1.各种熵的计算
熵、联合熵、条件熵、交叉熵、KL散度(相对熵)
- 熵用于衡量不确定性,所以均分的时候熵最大
- KL散度用于度量两个分布的不相似性,KL(p||q)等于交叉熵H(p,q)-熵H(p)。交叉熵可以看成是用q编码P所需的bit数,减去p本身需要的bit数,KL散度相当于用q编码p需要的额外bits。
- 交互信息Mutual information :I(x,y) = H(x)-H(x|y) = H(y)-H(y|x) 表示观察到x后,y的熵会减少多少。
2.常用的树搭建方法
ID3、C4.5、CART分别利用信息增益、信息增益率、Gini指数作为数据分割标准。
- 其中信息增益衡量按照某个特征分割前后熵的减少程度,其实就是上面说的交互信息。

- 用上述信息增益会出现优先选择具有较多属性的特征,毕竟分的越细的属性确定性越高。所以提出了信息增益率的概念,让含有较多属性的特征的作用降低。
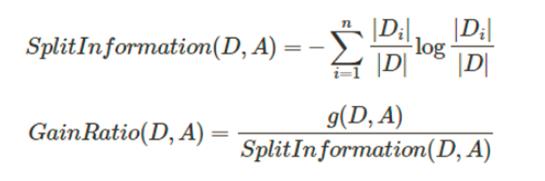
- CART树在分类过程中使用的基尼指数Gini,只能用于切分二叉树,而且和ID3、C4.5树不同,Cart树不会在每一个步骤删除所用特征。

3.防止过拟合—剪枝
剪枝分为前剪枝和后剪枝,前剪枝本质就是早停止,后剪枝通常是通过衡量剪枝后损失函数变化来决定是否剪枝。后剪枝有:错误率降低剪枝、悲观剪枝、代价复杂度剪枝
4.前剪枝的几种停止条件
- 节点中样本为同一类
- 特征不足返回多类
- 如果某个分支没有值则返回父节点中的多类
- 样本个数小于阈值返回多类
以上是关于各种熵,条件熵,KL的主要内容,如果未能解决你的问题,请参考以下文章