信息论中的各种熵
Posted Young_Gy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了信息论中的各种熵相关的知识,希望对你有一定的参考价值。
本文简单介绍了信息论中的各种熵,包括自信息、熵;联合熵、条件熵、互信息;KL散度、交叉熵。并在最后用信息论中的交叉熵推导了逻辑回归,得到了和最大似然法相同的结果。

熵
熵是信息的关键度量,通常指一条信息中需要传输或者存储一个信号的平均比特数。熵衡量了预测随机变量的不确定度,不确定性越大熵越大。
针对随机变量 X ,其信息熵的定义如下:
信息熵是信源编码中,压缩率的下限。当我们使用少于信息熵的信息量做编码,那么一定有信息的损失。
联合熵
联合熵是一集变量之间不确定的衡量手段。
H(X,Y)=∑∑−p(x,y)log(p(x,y))
条件熵
条件熵描述变量Y在变量X确定的情况下,变量Y的熵还剩多少。
H(Y|X)=∑∑−p(x,y)log(p(y|x))
联合熵和条件熵的关系是:
H(X,Y)=H(X)+H(Y|X)=H(Y)+H(X|Y)=H(Y,X)
自信息
自信息表示概率空间中与单一事件或离散变量的值相关的信息量的量度。
I(x)=−log(p(x))
平均的自信息就是信息熵。
H(X)=E[log2(X)]=∑−p(x)log2(p(x))
互信息
两个随机变量的互信息,是变量间相互依赖性的量度,不同于相关系数,互信息不限于实值随机变量,其更加一般。
I(X;Y)=∑∑−p(x,y)log(p(x)p(y)p(x,y))
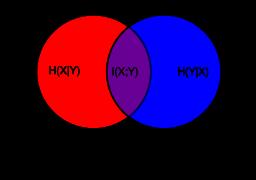
I(X;Y)=H(X)−H(X|Y)=H(Y)−H(Y|X)=H(X)+H(Y)−H(X,Y)=H(X,Y)−H(X|Y)−H(Y|X)
其意义为,若我们想知道Y包含多少X的信息,在尚未得到 Y之前,我们的不确定性是 H(X),得到Y后,不确定性是H(X|Y)。所以一旦得到Y后,我们消除了 H(X)-H(X|Y)的不确定量,这就是Y对X的信息量。
KL散度(信息增益)
KL散度,又称为相对熵(relative entropy)、信息散度(information divergence)、信息增益(information gain)。
KL散度是两个概率分布P和Q差别非对称性的度量。KL散度用来度量基于Q的编码来编码来自P的样本平均所需的额外的位元数。典型情况下,P表示数据的真实分布,Q表述数据的模型分布。
DKL(P||Q)=∑iP(i)logP(i)Q(i)
交叉熵
交叉熵衡量了在真实分布是P的情况的情况下,使用分布Q去编码数据,需要的平均比特。
H(p,q)=Ep[−logq]=H(p)+Dkl(p|q)
H(p,q)=∑−p(x)log(q(x))
交叉熵与逻辑回归的关系如下:
逻辑回归中:
- qy=1=y^=g以上是关于信息论中的各种熵的主要内容,如果未能解决你的问题,请参考以下文章