深入tornado中的IOStream
Posted 叶祖辉
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深入tornado中的IOStream相关的知识,希望对你有一定的参考价值。
iostream对tornado的高效起了很大的作用,他封装了socket的非阻塞IO的读写操作。大体上可以这么说,当连接建立后,服务端与客户端的请求响应都是基于IOStream的,也就是说:IOStream是用来处理连接的。
接下来说一下有关接收请求的大体流程:
当连接建立,服务器端会产生一个对应该连接的socket,同时将该socket封装至IOStream实例中(这代表着IOStream的初始化)。
我们知道tornado是基于IO多路复用的(就拿epoll来说),此时将socket进行register,事件为READABLE,这一步与IOStream没有多大关系。
当该socket事件发生时,也就是意味着有数据从连接发送到了系统缓冲区中,这时就需要将chunk读入到我们在内存中为其开辟的_read_buffer中,在IOStream中使用deque作为buffer。_read_buffer表示读缓冲,当然也有_write_buffer,但不管是读缓冲还是写缓冲本质上就是tornado进程开辟的一段用来存储数据的内存。
而这些chunk一般都是客户端发送的请求了,但是我们还需要对这些chunk作进一步操作,比如这个chunk中可能包含了多个请求,如何把请求分离?(每个请求首部的结束符是b\'\\r\\n\\r\\n\'),这里就用到read_until来分离请求并设置callback了。同时会将被分离的请求数据从_read_buffer中移除。
然后就是将callback以及他的参数(被分离的请求数据)添加至IOLoop._callbacks中,等待下一次IOLoop的执行,届时会迭代_callbacks并执行回调函数。
补充: tornado是水平触发,所以假如读完一次chunk后系统缓存区中依然还有数据,那么下一次的epoll.poll()依然会返回该socket。
在iostream中有一个类叫做:IOStream
有几个较为重要的属性:

def __init__():
self.socket = socket # 封装socket
self.socket.setblocking(False) # 设置socket为非阻塞
self.io_loop = io_loop or ioloop.IOLoop.current()
self._read_buffer = deque() # 读缓冲
self._write_buffer = deque() # 写缓冲
self._read_callback = None # 读到指定字节数据时,或是指定标志字符串时,需要执行的回调函数
self._write_callback = None # 发送完_write_buffer的数据时,需要执行的回调函数
有几个较为重要的方法
class IOStream(object):
def read_until(self, delimiter, callback):
def read_bytes(self, num_bytes, callback, streaming_callback=None):
def read_until_regex(self, regex, callback):
def read_until_close(self, callback, streaming_callback=None):
def write(self, data, callback=None):
以上所有的方法都需要一个可选的callback参数,如果该参数为None则该方法会返回一个Future对象。
以上所有的读方法本质上都是读取该socket所发送来的数据,然后当读到指定分隔符或者标记的时候,停止读,然后将该分隔符以及其前面的数据作为callback(如果没有callback,则将数据设置为Future对象的result)的参数,然后将callback添加至IOLoop._callbacks中。当然其中所有的"读"操作是非阻塞的!
就拿最为常见的read_until方法来说,下面是代码简化版:
def read_until(self, delimiter, callback=None, max_bytes=None):
future = self._set_read_callback(callback) # 可能是Future对象,也可能是None
self._read_delimiter = delimiter # 设置分隔符
self._read_max_bytes = max_bytes # 设置最大读字节数
self._try_inline_read()
return future
其中_set_read_callback会根据callback是否存在返回None或者Future对象(存在返回None,否则返回一个Future实例对象)
如果我们
再来看_try_inline_read方法的简化版:
def _try_inline_read(self):
"""
尝试从_read_buffer中读取所需数据
"""
# 查看是否我们已经在之前的读操作中得到了数据
self._run_streaming_callback() # 字符流回调,一般是读操作没有彻底读够而处于streaming状态,一般默认是None,如果调用read_bytes和read_until_close并指定了streaming_callback参数就会造成这个回调
pos = self._find_read_pos() # 尝试在_read_buffer中找到分隔符的位置。找到则返回分隔符末尾所处的位置,如果不能,则返回None。
if pos is not None:
self._read_from_buffer(pos)
return
self._check_closed() # 检查当前IOStream是否关闭
pos = self._read_to_buffer_loop() # 从系统缓冲中读取一个chunk,检查是否含有分隔符,没有则继续读取一个chunk,合并两个chunk,再次检查是否函数分隔符…… 如果找到了分隔符,会返回分隔符末尾在_read_buffer中所处的位置
if pos is not None: # 如果找到了分隔符,
self._read_from_buffer(pos) # 将所需的数据从_read_buffer中移除,并将其作为callback的参数,然后将callback封装后添加至IOLoop._callbacks中
return
# 没找到分隔符,要么关闭IOStream,要么为该socket在IOLoop中注册事件
if self.closed():
self._maybe_run_close_callback()
else:
self._add_io_state(ioloop.IOLoop.READ)
上面的代码被我用空行分为了三部分,每一部分顺序的对应下面每一句话
分析该方法:
1 首先在_read_buffer第一项中找分隔符,找到了就将分隔符以及其前的数据从_read_buffer中移除并将其作为参数传入回调函数,没找到就将第二项与第一项合并然后继续找……;
2 如果在_read_buffer所有项中都没找到的话就把系统缓存中的数据读取至_read_buffer,然后合并再次查找,
3 如果把系统缓存中的数据都取完了都还没找到,那么就等待下一次该socket发生READ事件后再找,这时的找则就是:将系统缓存中的数据读取到_read_buffer中然后找,也就是执行第2步。
来看一看这三部分分别调用了什么方法:
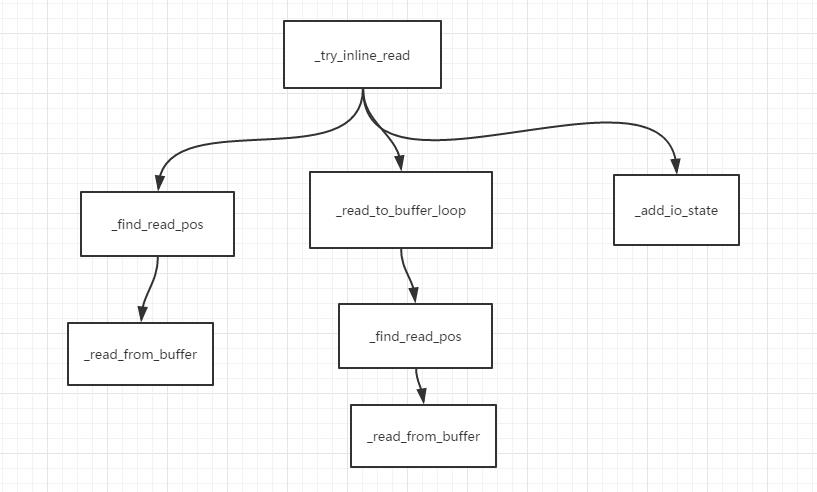
第一部分中的_find_read_pos以及_read_from_buffer
前者主要是在_read_buffer中查找分隔符,并返回分隔符的位置,后者则是将分隔符以及分隔符前面的所有数据从_read_buffer中取出并将其作为callback的参数,然后将callback封装后添加至IOLoop._callbacks中
来看_find_read_pos方法的简化版:
 _find_read_pos _read_from_buffer _run_read_callback
_find_read_pos _read_from_buffer _run_read_callback这里面还用到一个很有意思的函数:_merge_prefix ,这个函数的作用就是将deque的首项调整为指定大小
_merge_prefix
第二部分的_read_to_buffer_loop
_read_to_buffer_loop
第三部分_add_io_state,该函数和ioloop异步相关
_add_io_state
参考:
http://www.nowamagic.net/academy/detail/13321051
以上是关于深入tornado中的IOStream的主要内容,如果未能解决你的问题,请参考以下文章