kafka:replica副本同步机制
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了kafka:replica副本同步机制相关的知识,希望对你有一定的参考价值。
参考技术AKafka的流行归功于它设计和操作简单、存储系统高效、充分利用磁盘顺序读写等特性、非常适合在线日志收集等高吞吐场景。
Kafka特性之一是它的复制协议。复制协议是保障kafka高可靠性的关键。对于单个集群中每个Broker不同工作负载情况下,如何自动调优Kafka副本的工作方式是比较有挑战的。它的挑战之一是要知道如何避免follower进入和退出同步副本列表(即ISR)。从用户的角度来看,如果生产者发送一大批海量消息,可能会引起Kafka Broker很多警告。这些警报表明一些topics处于“under replicated”状态,这些副本处于同步失败或失效状态,更意味着数据没有被复制到足够数量Broker从而增加数据丢失的概率。因此Kafka集群中处于“under replicated”中Partition数要密切监控。这个警告应该来自于Broker失效,减慢或暂停等状态而不是生产者写不同大小消息引起的。
Kafka中主题的每个Partition有一个预写式日志文件,每个Partition都由一系列有序的、不可变的消息组成,这些消息被连续的追加到Partition中,Partition中的每个消息都有一个连续的序列号叫做offset, 确定它在分区日志中唯一的位置。
Kafka每个topic的partition有N个副本,其中N是topic的复制因子。Kafka通过多副本机制实现故障自动转移,当Kafka集群中一个Broker失效情况下仍然保证服务可用。在Kafka中发生复制时确保partition的预写式日志有序地写到其他节点上。N个replicas中。其中一个replica为leader,其他都为follower,leader处理partition的所有读写请求,与此同时,follower会被动定期地去复制leader上的数据。
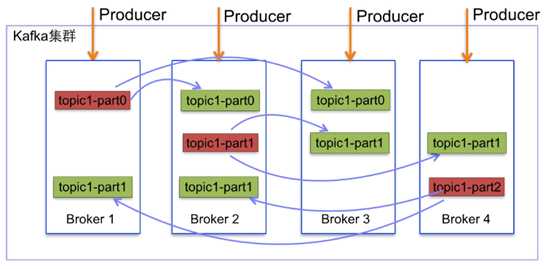
如下图所示,Kafka集群中有4个broker, 某topic有3个partition,且复制因子即副本个数也为3:
Kafka提供了数据复制算法保证,如果leader发生故障或挂掉,一个新leader被选举并被接受客户端的消息成功写入。Kafka确保从同步副本列表中选举一个副本为leader,或者说follower追赶leader数据。leader负责维护和跟踪ISR(In-Sync Replicas的缩写,表示副本同步队列,具体可参考下节)中所有follower滞后的状态。当producer发送一条消息到broker后,leader写入消息并复制到所有follower。消息提交之后才被成功复制到所有的同步副本。消息复制延迟受最慢的follower限制,重要的是快速检测慢副本,如果follower“落后”太多或者失效,leader将会把它从ISR中删除。
副本同步队列(ISR)
所谓同步,必须满足如下两个条件:
默认情况下Kafka对应的topic的replica数量为1,即每个partition都有一个唯一的leader,为了确保消息的可靠性,通常应用中将其值(由broker的参数offsets.topic.replication.factor指定)大小设置为大于1,比如3。 所有的副本(replicas)统称为Assigned Replicas,即AR。ISR是AR中的一个子集,由leader维护ISR列表,follower从leader同步数据有一些延迟。任意一个超过阈值都会把follower剔除出ISR, 存入OSR(Outof-Sync Replicas)列表,新加入的follower也会先存放在OSR中。AR=ISR+OSR。
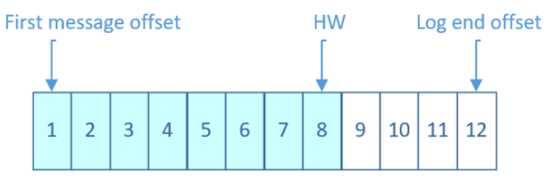
上一节中的HW俗称高水位,是HighWatermark的缩写,取一个partition对应的ISR中最小的LEO作为HW,consumer最多只能消费到HW所在的位置。另外每个replica都有HW,leader和follower各自负责更新自己的HW的状态。对于leader新写入的消息,consumer不能立刻消费,leader会等待该消息被所有ISR中的replicas同步后更新HW,此时消息才能被consumer消费。这样就保证了如果leader所在的broker失效,该消息仍然可以从新选举的leader中获取。对于来自内部broKer的读取请求,没有HW的限制。
下图详细的说明了当producer生产消息至broker后,ISR以及HW和LEO的流转过程:
由此可见,Kafka的复制机制既不是完全的同步复制,也不是单纯的异步复制。事实上,同步复制要求所有能工作的follower都复制完,这条消息才会被commit,这种复制方式极大的影响了吞吐率。而异步复制方式下,follower异步的从leader复制数据,数据只要被leader写入log就被认为已经commit,这种情况下如果follower都还没有复制完,落后于leader时,突然leader宕机,则会丢失数据。而Kafka的这种使用ISR的方式则很好的均衡了确保数据不丢失以及吞吐率。
副本不同步的异常情况
broker 分配的任何一个 partition 都是以 Replica 对象实例的形式存在,而 Replica 在 Kafka 上是有两个角色: leader 和 follower,只要这个 Replica 是 follower,它便会向 leader 进行数据同步。
反映在 ReplicaManager 上就是如果 Broker 的本地副本被选举为 follower,那么它将会启动副本同步线程,其具体实现如下所示:
简单来说,makeFollowers() 的处理过程如下:
关于第6步,并不一定会为每一个 partition 都启动一个 fetcher 线程,对于一个目的 broker,只会启动 num.replica.fetchers 个线程,具体这个 topic-partition 会分配到哪个 fetcher 线程上,是根据 topic 名和 partition id 进行计算得到,实现所示:
如上所示,在 ReplicaManager 调用 makeFollowers() 启动 replica fetcher 线程后,它实际上是通过 ReplicaFetcherManager 实例进行相关 topic-partition 同步线程的启动和关闭,其启动过程分为下面两步:
addFetcherForPartitions() 的具体实现如下所示:
这个方法其实是做了下面这几件事:
ReplicaFetcherManager 创建 replica Fetcher 线程的实现如下:
replica fetcher 线程在启动之后就开始进行正常数据同步流程了,这个过程都是在 ReplicaFetcherThread 线程中实现的。
ReplicaFetcherThread 的 doWork() 方法是一直在这个线程中的 run() 中调用的,实现方法如下:
在 doWork() 方法中主要做了两件事:
processFetchRequest() 这个方法的作用是发送 Fetch 请求,并对返回的结果进行处理,最终写入到本地副本的 Log 实例中,其具体实现:
其处理过程简单总结一下:
fetch() 方法作用是发送 Fetch 请求,并返回相应的结果,其具体的实现,如下:
processPartitionData
这个方法的作用是,处理 Fetch 请求的具体数据内容,简单来说就是:检查一下数据大小是否超过限制、将数据追加到本地副本的日志文件中、更新本地副本的 hw 值。
在副本同步的过程中,会遇到哪些异常情况呢?
大家一定会想到关于 offset 的问题,在 Kafka 中,关于 offset 的处理,无论是 producer 端、consumer 端还是其他地方,offset 似乎都是一个形影不离的问题。在副本同步时,关于 offset,会遇到什么问题呢?下面举两个异常的场景:
以上两种情况都是 offset OutOfRange 的情况,只不过:一是 Fetch Offset 超过了 leader 的 LEO,二是 Fetch Offset 小于 leader 最小的 offset
在介绍 Kafka 解决方案之前,我们先来自己思考一下这两种情况应该怎么处理?
上面是我们比较容易想出的解决方案,而在 Kafka 中,其解决方案也很类似,不过遇到情况比上面我们列出的两种情况多了一些复杂,其解决方案如下:
针对第一种情况,在 Kafka 中,实际上还会发生这样一种情况,1 在收到 OutOfRange 错误时,这时去 leader 上获取的 LEO 值与最小的 offset 值,这时候却发现 leader 的 LEO 已经从 800 变成了 1100(这个 topic-partition 的数据量增长得比较快),再按照上面的解决方案就不太合理,Kafka 这边的解决方案是:遇到这种情况,进行重试就可以了,下次同步时就会正常了,但是依然会有上面说的那个问题。
replica fetcher 线程关闭的条件,在三种情况下会关闭对这个 topic-partition 的拉取操作:
这里直接说线程关闭,其实不是很准确,因为每个 replica fetcher 线程操作的是多个 topic-partition,而在关闭的粒度是 partition 级别,只有这个线程分配的 partition 全部关闭后,这个线程才会真正被关闭。
stopReplica
StopReplica 的请求实际上是 Controller 发送过来的,这个在 controller 部分会讲述,它触发的条件有多种,比如:broker 下线、partition replica 迁移等等。
makeLeaders
makeLeaders() 方法的调用是在 broker 上这个 partition 的副本被设置为 leader 时触发的,其实现如下:
调用 ReplicaFetcherManager 的 removeFetcherForPartitions() 删除对这些 topic-partition 的副本同步设置,这里在实现时,会遍历所有的 replica fetcher 线程,都执行 removePartitions() 方法来移除对应的 topic-partition 集合。
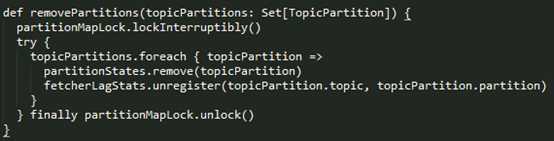
removePartitions
这个方法的作用是:ReplicaFetcherThread 将这些 topic-partition 从自己要拉取的 partition 列表中移除。
ReplicaFetcherThread的关闭
前面介绍那么多,似乎还是没有真正去关闭,那么 ReplicaFetcherThread 真正关闭是哪里操作的呢?
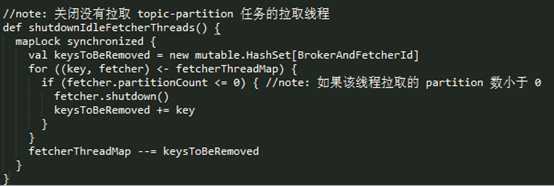
实际上 ReplicaManager 每次处理完 LeaderAndIsr 请求后,都会调用 ReplicaFetcherManager 的 shutdownIdleFetcherThreads() 方法,如果 fetcher 线程要拉取的 topic-partition 集合为空,那么就会关闭掉对应的 fetcher 线程。
replica副本同步机制
replica副本同步机制
1 前言
Kafka的流行归功于它设计和操作简单、存储系统高效、充分利用磁盘顺序读写等特性、非常适合在线日志收集等高吞吐场景。
Kafka特性之一是它的复制协议。复制协议是保障kafka高可靠性的关键。对于单个集群中每个Broker不同工作负载情况下,如何自动调优Kafka副本的工作方式是比较有挑战的。它的挑战之一是要知道如何避免follower进入和退出同步副本列表(即ISR)。从用户的角度来看,如果生产者发送一大批海量消息,可能会引起Kafka Broker很多警告。这些警报表明一些topics处于“under replicated”状态,这些副本处于同步失败或失效状态,更意味着数据没有被复制到足够数量Broker从而增加数据丢失的概率。因此Kafka集群中处于“under replicated”中Partition数要密切监控。这个警告应该来自于Broker失效,减慢或暂停等状态而不是生产者写不同大小消息引起的。
2 Kafka的副本机制
Kafka中主题的每个Partition有一个预写式日志文件,每个Partition都由一系列有序的、不可变的消息组成,这些消息被连续的追加到Partition中,Partition中的每个消息都有一个连续的序列号叫做offset, 确定它在分区日志中唯一的位置。
Kafka每个topic的partition有N个副本,其中N是topic的复制因子。Kafka通过多副本机制实现故障自动转移,当Kafka集群中一个Broker失效情况下仍然保证服务可用。在Kafka中发生复制时确保partition的预写式日志有序地写到其他节点上。N个replicas中。其中一个replica为leader,其他都为follower,leader处理partition的所有读写请求,与此同时,follower会被动定期地去复制leader上的数据。
如下图所示,Kafka集群中有4个broker, 某topic有3个partition,且复制因子即副本个数也为3:
Kafka提供了数据复制算法保证,如果leader发生故障或挂掉,一个新leader被选举并被接受客户端的消息成功写入。Kafka确保从同步副本列表中选举一个副本为leader,或者说follower追赶leader数据。leader负责维护和跟踪ISR(In-Sync Replicas的缩写,表示副本同步队列,具体可参考下节)中所有follower滞后的状态。当producer发送一条消息到broker后,leader写入消息并复制到所有follower。消息提交之后才被成功复制到所有的同步副本。消息复制延迟受最慢的follower限制,重要的是快速检测慢副本,如果follower“落后”太多或者失效,leader将会把它从ISR中删除。
副本同步队列(ISR)
所谓同步,必须满足如下两个条件:
- 副本节点必须能与zookeeper保持会话(心跳机制)
- 副本能复制leader上的所有写操作,并且不能落后太多。(卡住或滞后的副本控制是由 replica.lag.time.max.ms 配置)
默认情况下Kafka对应的topic的replica数量为1,即每个partition都有一个唯一的leader,为了确保消息的可靠性,通常应用中将其值(由broker的参数offsets.topic.replication.factor指定)大小设置为大于1,比如3。 所有的副本(replicas)统称为Assigned Replicas,即AR。ISR是AR中的一个子集,由leader维护ISR列表,follower从leader同步数据有一些延迟。任意一个超过阈值都会把follower剔除出ISR, 存入OSR(Outof-Sync Replicas)列表,新加入的follower也会先存放在OSR中。AR=ISR+OSR。
上一节中的HW俗称高水位,是HighWatermark的缩写,取一个partition对应的ISR中最小的LEO作为HW,consumer最多只能消费到HW所在的位置。另外每个replica都有HW,leader和follower各自负责更新自己的HW的状态。对于leader新写入的消息,consumer不能立刻消费,leader会等待该消息被所有ISR中的replicas同步后更新HW,此时消息才能被consumer消费。这样就保证了如果leader所在的broker失效,该消息仍然可以从新选举的leader中获取。对于来自内部broKer的读取请求,没有HW的限制。
下图详细的说明了当producer生产消息至broker后,ISR以及HW和LEO的流转过程:
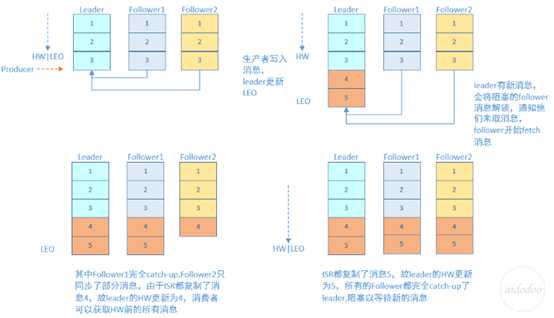
由此可见,Kafka的复制机制既不是完全的同步复制,也不是单纯的异步复制。事实上,同步复制要求所有能工作的follower都复制完,这条消息才会被commit,这种复制方式极大的影响了吞吐率。而异步复制方式下,follower异步的从leader复制数据,数据只要被leader写入log就被认为已经commit,这种情况下如果follower都还没有复制完,落后于leader时,突然leader宕机,则会丢失数据。而Kafka的这种使用ISR的方式则很好的均衡了确保数据不丢失以及吞吐率。
- Controller来维护:Kafka集群中的其中一个Broker会被选举为Controller,主要负责Partition管理和副本状态管理,也会执行类似于重分配partition之类的管理任务。在符合某些特定条件下,Controller下的LeaderSelector会选举新的leader,ISR和新的leader_epoch及controller_epoch写入Zookeeper的相关节点中。同时发起LeaderAndIsrRequest通知所有的replicas。
- leader来维护:leader有单独的线程定期检测ISR中follower是否脱离ISR, 如果发现ISR变化,则会将新的ISR的信息返回到Zookeeper的相关节点中。
副本不同步的异常情况
- 慢副本:在一定周期时间内follower不能追赶上leader。最常见的原因之一是I / O瓶颈导致follower追加复制消息速度慢于从leader拉取速度。
- 卡住副本:在一定周期时间内follower停止从leader拉取请求。follower replica卡住了是由于GC暂停或follower失效或死亡。
- 新启动副本:当用户给主题增加副本因子时,新的follower不在同步副本列表中,直到他们完全赶上了leader日志。
3 Follower向leader拉取数据的过程
3.1 replica fetcher 线程何时启动
broker 分配的任何一个 partition 都是以 Replica 对象实例的形式存在,而 Replica 在 Kafka 上是有两个角色: leader 和 follower,只要这个 Replica 是 follower,它便会向 leader 进行数据同步。
反映在 ReplicaManager 上就是如果 Broker 的本地副本被选举为 follower,那么它将会启动副本同步线程,其具体实现如下所示:
简单来说,makeFollowers() 的处理过程如下:
- 先从本地记录 leader partition 的集合中将这些 partition 移除,因为这些 partition 已经被选举为了 follower;
- 将这些 partition 的本地副本设置为 follower,后面就不会接收关于这个 partition 的 Produce 请求了,如果依然有 client 在向这台 broker 发送数据,那么它将会返回相应的错误;
- 先停止关于这些 partition 的副本同步线程(如果本地副本之前是 follower 现在还是 follower,先关闭的原因是:这个 partition 的 leader 发生了变化,如果 leader 没有发生变化,那么 makeFollower方法返回的是 False,这个 Partition 就不会被添加到 partitionsToMakeFollower 集合中),这样的话可以保证这些 partition 的本地副本将不会再有新的数据追加;
- 对这些 partition 本地副本日志文件进行截断操作并进行 checkpoint 操作;
- 完成那些延迟处理的 Produce 和 Fetch 请求;
- 如果本地的 broker 没有掉线,那么向这些 partition 新选举出来的 leader 启动副本同步线程。
关于第6步,并不一定会为每一个
partition 都启动一个 fetcher 线程,对于一个目的 broker,只会启动 num.replica.fetchers 个线程,具体这个
topic-partition 会分配到哪个 fetcher 线程上,是根据
topic 名和 partition id 进行计算得到,实现所示:

3.2 replica fetcher 线程启动
如上所示,在 ReplicaManager 调用 makeFollowers() 启动 replica fetcher 线程后,它实际上是通过 ReplicaFetcherManager 实例进行相关 topic-partition 同步线程的启动和关闭,其启动过程分为下面两步:
- ReplicaFetcherManager 调用 addFetcherForPartitions() 添加对这些 topic-partition 的数据同步流程;
- ReplicaFetcherManager 调用 createFetcherThread() 初始化相应的 ReplicaFetcherThread 线程。
addFetcherForPartitions() 的具体实现如下所示:
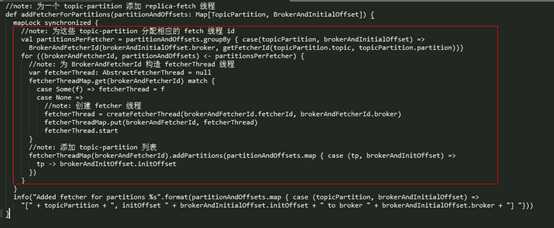
这个方法其实是做了下面这几件事:
- 先计算这个 topic-partition 对应的 fetcher id;
- 根据 leader 和 fetcher id 获取对应的 replica fetcher 线程,如果没有找到,就调用 createFetcherThread() 创建一个新的 fetcher 线程;
- 如果是新启动的 replica fetcher 线程,那么就启动这个线程;
- 将 topic-partition 记录到 fetcherThreadMap 中,这个变量记录每个 replica fetcher 线程要同步的 topic-partition 列表。
ReplicaFetcherManager 创建 replica Fetcher 线程的实现如下:
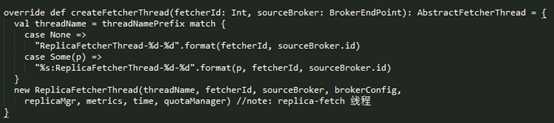
3.3 replica fetcher 线程处理过程
replica fetcher 线程在启动之后就开始进行正常数据同步流程了,这个过程都是在 ReplicaFetcherThread 线程中实现的。
ReplicaFetcherThread
的 doWork() 方法是一直在这个线程中的 run() 中调用的,实现方法如下:
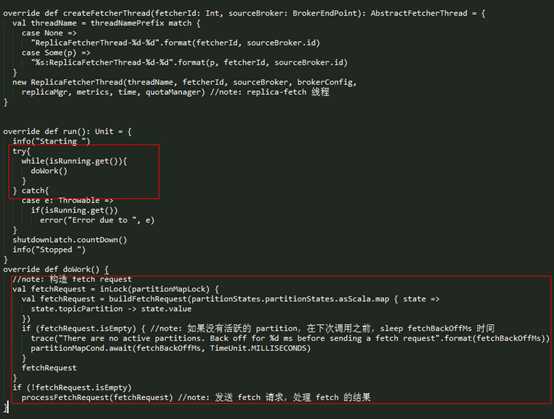
在 doWork() 方法中主要做了两件事:
- 构造相应的 Fetch 请求(buildFetchRequest());
- 通过 processFetchRequest() 方法发送 Fetch 请求,并对其结果进行相应的处理。
processFetchRequest() 这个方法的作用是发送
Fetch 请求,并对返回的结果进行处理,最终写入到本地副本的 Log 实例中,其具体实现:
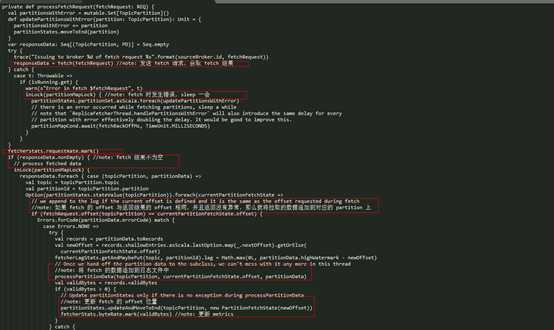
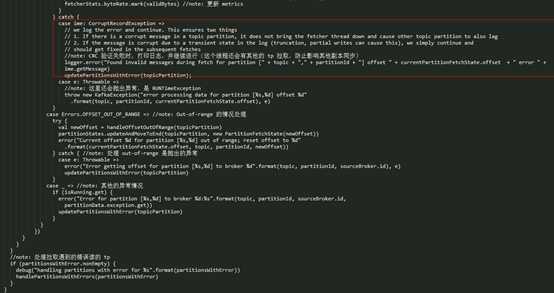
其处理过程简单总结一下:
- 通过 fetch() 方法,发送 Fetch 请求,获取相应的 response(如果遇到异常,那么在下次发送 Fetch 请求之前,会 sleep 一段时间再发);
- 如果返回的结果 不为空,并且 Fetch 请求的 offset 信息与返回结果的 offset 信息对得上,那么就会调用 processPartitionData() 方法将拉取到的数据追加本地副本的日志文件中,如果返回结果有错误信息,那么就对相应错误进行相应的处理;
- 对在 Fetch 过程中遇到异常或返回错误的 topic-partition,会进行 delay 操作,下次 Fetch 请求的发生至少要间隔 replica.fetch.backoff.ms 时间。
fetch() 方法作用是发送 Fetch 请求,并返回相应的结果,其具体的实现,如下:
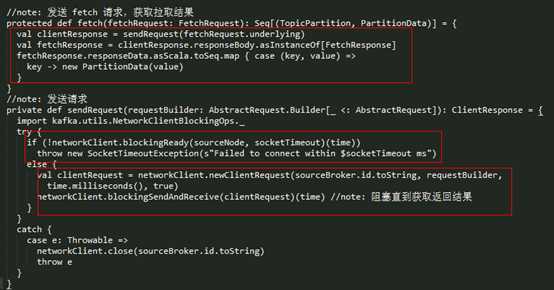
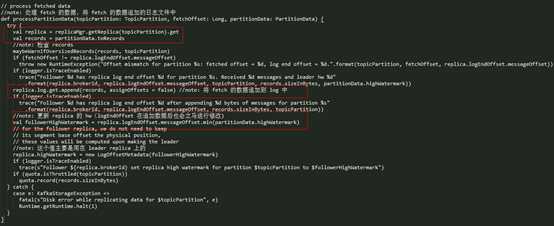
processPartitionData
这个方法的作用是,处理 Fetch 请求的具体数据内容,简单来说就是:检查一下数据大小是否超过限制、将数据追加到本地副本的日志文件中、更新本地副本的 hw 值。
3.3 副本同步异常情况的处理
在副本同步的过程中,会遇到哪些异常情况呢?
大家一定会想到关于 offset 的问题,在 Kafka 中,关于 offset 的处理,无论是 producer 端、consumer 端还是其他地方,offset 似乎都是一个形影不离的问题。在副本同步时,关于 offset,会遇到什么问题呢?下面举两个异常的场景:
- 假如当前本地(id:1)的副本现在是 leader,其 LEO 假设为1000,而另一个在 isr 中的副本(id:2)其 LEO 为800,此时出现网络抖动,id 为1 的机器掉线后又上线了,但是此时副本的 leader 实际上已经变成了 2,而2的 LEO 为800,这时候1启动副本同步线程去2上拉取数据,希望从 offset=1000 的地方开始拉取,但是2上最大的 offset 才是800,这种情况该如何处理呢?
- 假设一个 replica (id:1)其 LEO 是10,它已经掉线好几天,这个 partition leader 的 offset 范围是 [100, 800],那么 1 重启启动时,它希望从 offset=10 的地方开始拉取数据时,这时候发生了 OutOfRange,不过跟上面不同的是这里是小于了 leader offset 的范围,这种情况又该怎么处理?
以上两种情况都是 offset OutOfRange 的情况,只不过:一是 Fetch Offset 超过了 leader 的 LEO,二是 Fetch Offset 小于 leader 最小的 offset
在介绍 Kafka 解决方案之前,我们先来自己思考一下这两种情况应该怎么处理?
- 如果 fetch offset 超过 leader 的 offset,这时候副本应该是回溯到 leader 的 LEO 位置(超过这个值的数据删除),然后再去进行副本同步,当然这种解决方案其实是无法保证 leader 与 follower 数据的完全一致,再次发生 leader 切换时,可能会导致数据的可见性不一致,但既然用户允许了脏选举的发生,其实我们是可以认为用户是可以接收这种情况发生的;
- 这种就比较容易处理,首先清空本地的数据,因为本地的数据都已经过期了,然后从 leader 的最小 offset 位置开始拉取数据。
上面是我们比较容易想出的解决方案,而在 Kafka 中,其解决方案也很类似,不过遇到情况比上面我们列出的两种情况多了一些复杂,其解决方案如下:

针对第一种情况,在 Kafka 中,实际上还会发生这样一种情况,1 在收到 OutOfRange 错误时,这时去 leader 上获取的 LEO 值与最小的 offset 值,这时候却发现 leader 的 LEO 已经从 800 变成了 1100(这个 topic-partition 的数据量增长得比较快),再按照上面的解决方案就不太合理,Kafka 这边的解决方案是:遇到这种情况,进行重试就可以了,下次同步时就会正常了,但是依然会有上面说的那个问题。
3.4 replica fetcher 线程的关闭
replica fetcher 线程关闭的条件,在三种情况下会关闭对这个 topic-partition 的拉取操作:
- stopReplica():broker 收到了 controller 发来的 StopReplica 请求,这时会开始关闭对指定 topic-partition 的同步线程;
- makeLeaders:这些 partition 的本地副本被选举成了 leader,这时候就会先停止对这些 topic-partition 副本同步线程;
- makeFollowers():前面已经介绍过,这里实际上停止副本同步,然后再开启副本同步线程,因为这些 topic-partition 的 leader 可能发生了切换。
这里直接说线程关闭,其实不是很准确,因为每个 replica fetcher 线程操作的是多个 topic-partition,而在关闭的粒度是 partition 级别,只有这个线程分配的 partition 全部关闭后,这个线程才会真正被关闭。
stopReplica
StopReplica 的请求实际上是 Controller 发送过来的,这个在 controller 部分会讲述,它触发的条件有多种,比如:broker 下线、partition replica 迁移等等。
makeLeaders
makeLeaders() 方法的调用是在 broker 上这个 partition 的副本被设置为 leader 时触发的,其实现如下:
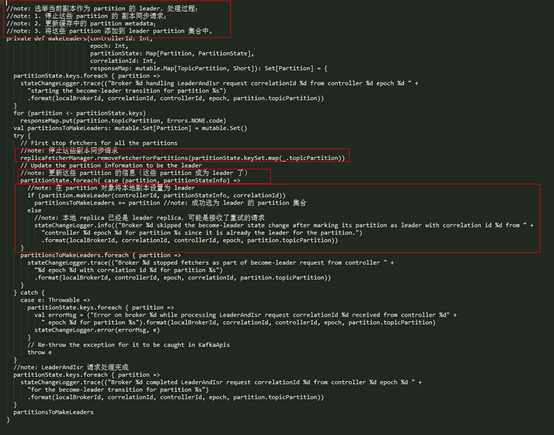
调用 ReplicaFetcherManager 的 removeFetcherForPartitions() 删除对这些 topic-partition 的副本同步设置,这里在实现时,会遍历所有的 replica fetcher 线程,都执行 removePartitions() 方法来移除对应的 topic-partition 集合。

removePartitions
这个方法的作用是:ReplicaFetcherThread 将这些 topic-partition 从自己要拉取的 partition 列表中移除。
ReplicaFetcherThread 的关闭
前面介绍那么多,似乎还是没有真正去关闭,那么 ReplicaFetcherThread 真正关闭是哪里操作的呢?
实际上 ReplicaManager 每次处理完 LeaderAndIsr 请求后,都会调用 ReplicaFetcherManager 的 shutdownIdleFetcherThreads() 方法,如果 fetcher 线程要拉取的 topic-partition 集合为空,那么就会关闭掉对应的 fetcher 线程。
参考资料:
https://www.cnblogs.com/aidodoo/p/8873163.html
https://juejin.im/post/5bf6b0acf265da612d18e931
https://www.infoq.cn/article/depth-interpretation-of-kafka-data-reliability
以上是关于kafka:replica副本同步机制的主要内容,如果未能解决你的问题,请参考以下文章
Kafka——一致性重要机制之ISR(kafka replica)
副本机制与副本同步------《Designing Data-Intensive Applications》读书笔记6
kafka的副本同步机制---关于高水位和Leader Epoch