kafka的副本同步机制---关于高水位和Leader Epoch
Posted YaoYong_BigData
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了kafka的副本同步机制---关于高水位和Leader Epoch相关的知识,希望对你有一定的参考价值。
一、何为高水位
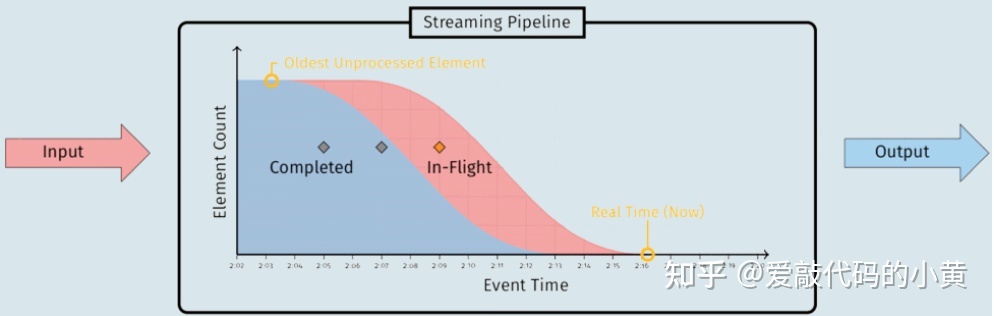
日常生活中,我们一般把什么叫做水位呢?
- 经典教科书
- 在时刻
T,任意创建时间(Event Time)为T',且T'<=T的所有事件都已经到达,那么T就被定义为水位
- 《Streaming System》
- 水位是一个单调增加且表征最早未完成工作的时间戳
- 如上图所示,标注为
Completed的蓝色区域代表已经完成的工作,而标注为In-Flight的红色区域代表未完成(正在进行)的工作,两边的交界线就是水位线。 - 在 kafka 中,水位不是时间戳,而是与位置信息绑定的,即用 消息位移(offset)来表征水位。
- 当然,kafka 中也有低水位(Low Watermark),与 kafka的删除消息有关,不在我们本篇文章的讨论范围之内。
二、高水位的作用
在 kafka 中,高水位的作用主要是 2 个
- 定义消息可见性,既用来告诉我们的消费者哪些消息是可以进行消费的;
- 帮助 kafka 完成副本机制的同步。
Kafka 分区下有可能有很多个副本用于实现冗余,从而进一步实现高可用。副本根据角色的不同可分为3种
- leader 副本:相应 clients 端读写请求的副本;
- Follower 副本:被动的备注 leader 副本的内容,不能相应 clients 端读写请求;
- ISR 副本: 包含了 leader 副本和所有与 leader 副本保持同步的 Followerer 副本。
每个 kafka 副本对象都有两个重要的属性:LEO 和 HW。注意是所有的副本(leader + Follower)
- LEO:当前日志末端的位移(log end offset),记录了该副本底层日志(log)中下一条消息的位移值。
- HW:高水位值(High Watermark),对于同一个副本对象,其 HW 的值不会超越 LEO。
我们假设下图是某个分区 leader 副本的高水位图:
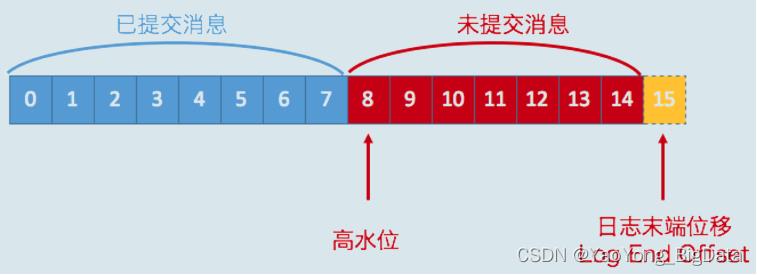
在高水位线之下的为 已提交消息,在水位线之上的为 未提交消息,对于 已提交消息,我们的消费者可以进行消费,也就是图中 0-7 下标的消息。需要关注的是,位移值等于高水位的消息也属于未提交消息。也就是说,高水位上的消息是不能被消费者消费的。
图中的日志末端位置,既我们所说的 LEO,他表示副本写入下一条消息的位移值。我们可以发现,位移值 15 的地方为虚框,这表示我们当前副本只有15条消息,位移值是从 0 到 14,下一条新消息的位移是 15。
我们总说consumer无法消费未提交消息。这句话如果用以上名词来解读的话,应该表述为:consumer无法消费分区下leader副本中位移值大于分区HW的任何消息。这里需要特别注意分区HW就是leader副本的HW值。
观察得知,对于同一个副本,我们的高水位值不会超越其 LEO 值。
三、高水位更新机制
通过上面的讲述,我们知道每个副本对象都保存了一组 HW 和 LEO。
但实际上,在 leader 副本所在的 Broker0 上,还保存了其他 Follower 副本的 LEO 值,这些 Follower 副本又被称为远程副本(Remote Replica)
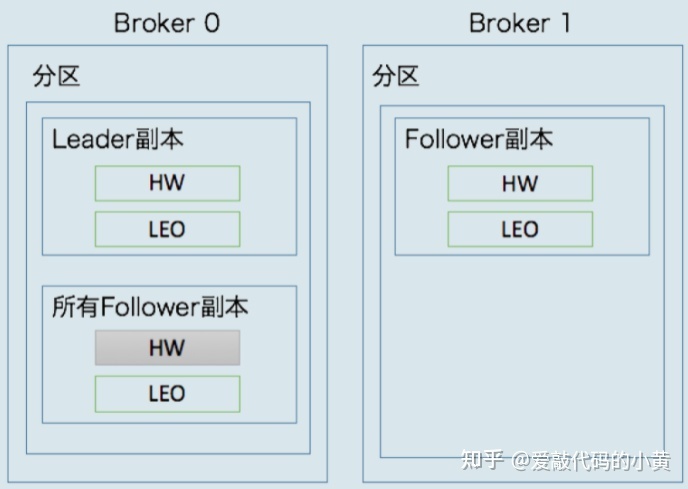
kafka 副本机制在运行过程中:
- 更新
- Broker1 上 Follower 副本的高水位和 LEO 值;
- Broker0 上 leader 副本的高水位和 LEO 以及所有 Follower 副本的 LEO。
- 不会更新
- 所有 Follower 副本的 HW,既图中标记为灰色的部分。
这里可能你会有疑问了,为什么我们要在 Broker0 上保存这些 Follower 副本呢?
- 帮助 leader 副本确定其高水位,也就是分区高水位。
1.更新时机
| 更新对象 | 更新时机 |
|---|---|
| Borker0 上Leader副本的LEO | Leader副本接收到生产者发送的消息,写入到本地磁盘后,会更新其LEO值 |
| Broker 1上Follower副本的LEO | Follower副本从Leader副本拉取消息,写入本地磁盘后,会更新其LEO值 |
| Broker0上远程副本的LEO | Follower副本从Leader副本拉取消息,会告诉Leader副本从哪个位移开始拉取,Leader副本会使用这个位移来更新远程副本的LEO |
| Broker0上Leader副本的高水位 | 两个更新时机:一个是Leader副本更新其LEO之后,一个是更新完远程副本LEO后,具体算法:取Leader副本和所有与Leader同步的远程副本LEO的最小值 |
| Broker 1上Follower副本的高水位 | Follower副本更新完LEO后,会比较LEO与leader副本发来的高水位值,并用两者的较少值去更新自己的高水位 |
- Follower 副本与 Leader 副本保持同步,需要满足两个条件
- Follower 副本在 ISR 中;
- Follower 副本 LEO 值落后 Leader 副本 LEO 值的时间不超过参数
replica.lag.time.max.ms,默认是 10 秒。
这两个条件好像是一回事,因为某个副本能否进入 ISR 就是靠第 2 个条件判断的。
但有些时候,会发生这样的情况:即 Follower 副本已经“追上”了 Leader 的进度,却不在 ISR 中,比如某个刚刚重启回来的副本。如果 Kafka 只判断第 1 个条件的话,就可能出现某些副本具备了“进入 ISR”的资格,但却尚未进入到 ISR 中的情况。此时,分区高水位值就可能超过 ISR 中副本 LEO,而高水位 > LEO 的情形是不被允许的。
2.leader 副本和 Follower 副本
Leader 副本
处理生产者请求的逻辑如下:
1、写入消息到本地磁盘。
2、更新分区高水位值。
i.获取 Leader 副本所在 Broker 端保存的所有远程副本 LEO 值(LEO-1,LEO-2,……,LEO-n)。
ii: 获取 Leader 副本高水位值:currentHW。
iii: 更新 currentHW = maxcurrentHW, min(LEO-1, LEO-2, ……,LEO-n)。
处理 Follower 副本拉取消息的逻辑如下:
1、读取磁盘(或页缓存)中的消息数据。
2、使用 Follower 副本发送请求中的位移值更新远程副本 LEO 值。
3、更新分区高水位值(具体步骤与处理生产者请求的步骤相同)。
Follower 副本
从 Leader 拉取消息的处理逻辑如下:
1、写入消息到本地磁盘。
2、更新 LEO 值。
3、更新高水位值。
i. 获取 Leader 发送的高水位值:currentHW。
ii. 获取步骤 2 中更新过的 LEO 值:currentLEO。
iii. 更新高水位为 min(currentHW, currentLEO)。
3.副本同步机制
我来举一个实际的例子,说明一下 Kafka 副本同步的全流程。该例子使用一个单分区且有两个副本的主题。
当生产者发送一条消息时,Leader 和 Follower 副本的高水位是怎么被更新的
首先是初始状态,这里的 Remote LEO 代表之前我们 Broker0 中的远程副本的 LEO,我们的 Follower 副本通过 FETCH 请求不断与 Leader 副本进行数据同步。

3.1 第一次同步
当生产者给我们的主题分区发送一条消息后,状态变更为:
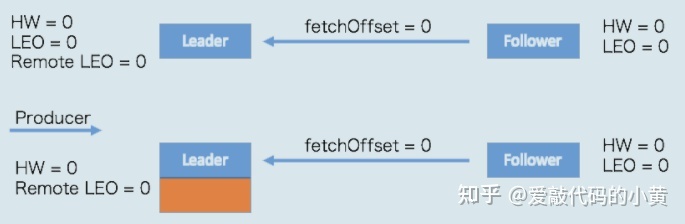
我们上面讲过,关于 Leader 副本处理生产者的逻辑
- 写入磁盘,更新
LEO = 1 - 更新高水位
- 当前的高水位为:0
- 当前远程副本的LEO为:0
- 所以:
HW = Math.max(0,0) = 0

Follow 副本尝试从 Leader 拉取消息,和之前不同的是,这次有消息可以拉取了,因此状态进一步变更为:

我们上面讲过,Leader 副本处理 Follower 副本拉取消息的逻辑
- 读取磁盘(页缓存)中的消息数据
- 使用 Follower 副本发送消息请求中的位移值更新远程副本 LEO 值(Remote LEO)
Remote LEO = fetchOffset = 0
- 更新分区高水位值(无变化、省略)
我们上面讲到,Follower 副本从 Leader 拉取消息的处理逻辑
- 写入消息到本地磁盘,更新 LEO 值为 1
- 更新高水位
- 获取 Leader 发送的高水位值:
currentHW = 0 - 获取步骤 2 中更新的 LEO 值:
currentLEO = 1 - 更新高水位为:
HW = 0
- 获取 Leader 发送的高水位值:
经过这一次拉取,我们的 Leader 和 Follower 副本的 LEO 都是 1,各自的高水位依然是0,没有被更新。
3.2 第二次同步
它们需要在下一轮的拉取中被更新,如下图所示:

Leader 副本处理 Follower 副本拉取消息的逻辑
- 读取磁盘(页缓存)中的消息数据
- 使用 Follower 副本发送消息请求中的位移值更新远程副本 LEO 值(Remote LEO)
Remote LEO = fetchOffset = 1
- 更新分区高水位值
- LEO 值:
Remote LEO = 1 - Leader 高水位值:
currentHW = 0 - 高水位值:
HW = Math.max(0,1) = 1
- LEO 值:
Follower 副本从 Leader 拉取消息的处理逻辑
- 写入消息到本地磁盘,更新 LEO 值(无变化)
- 更新高水位
- 获取 Leader 发送的高水位值:
currentHW = 1 - 获取步骤 2 中更新的 LEO 值:
currentLEO = 1 - 更新高水位为:
HW = Math.min(1,1) = 1
- 获取 Leader 发送的高水位值:
至此,一次完整的消息同步周期就结束了。事实上,Kafka 就是利用这样的机制,实现了 Leader 和 Follower 副本之间的同步。
四、Leader Epoch登场
依托于高水位,我们不仅向外界定义了消息的可见性,又实现了副本的同步机制。
我们需要思考思考,这种副本同步机制会有什么危害呢?
1.数据丢失
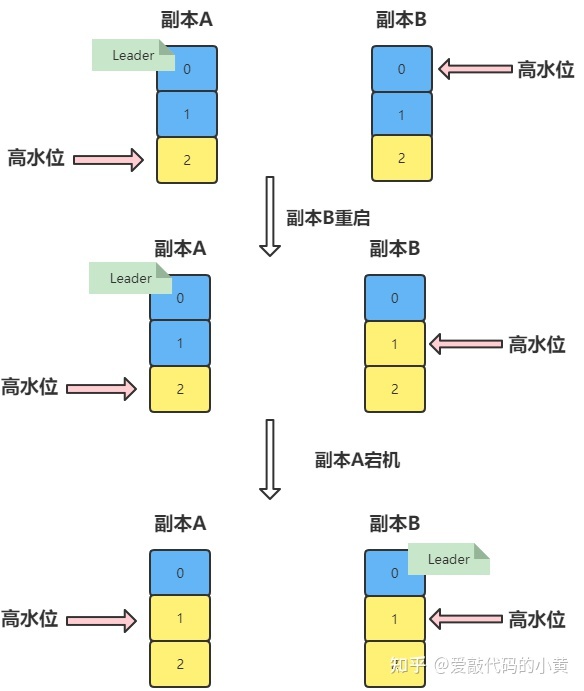
- 蓝色:已落磁盘的数据
- 黄色:无任何数据
当我们的副本进行第二次同步时,假如在 Follower 副本从 Leader 拉取消息的处理逻辑 这里,我们的副本B重启了机器。
等到 副本B 重启成功后,副本B 会执行日志截断操作(根据高水位的数值进行截断),将 LEO 值调整为之前的高水位值,也就是 1。位移值为 1 的那条消息被副本 B 从磁盘中删除,此时副本 B 的底层磁盘文件中只保存有 1 条消息,即位移值为 0 的那条消息。
当执行完截断日志的操作后,副本B开始从副本A拉取消息,进行正常的消息同步。这时候副本A重启了,我们会让我们的副本B成为 Leader。
当副本A重启成功时,会自动向 Leader 看齐,此时,当 A 回来后,需要执行相同的日志截断操作,即将高水位调整为与 B 相同的值,也就是 1。
这样操作之后,位移值为 1 的那条消息就从这两个副本中被永远地抹掉了,这就是这张图要展示的数据丢失场景。
2.数据不一致
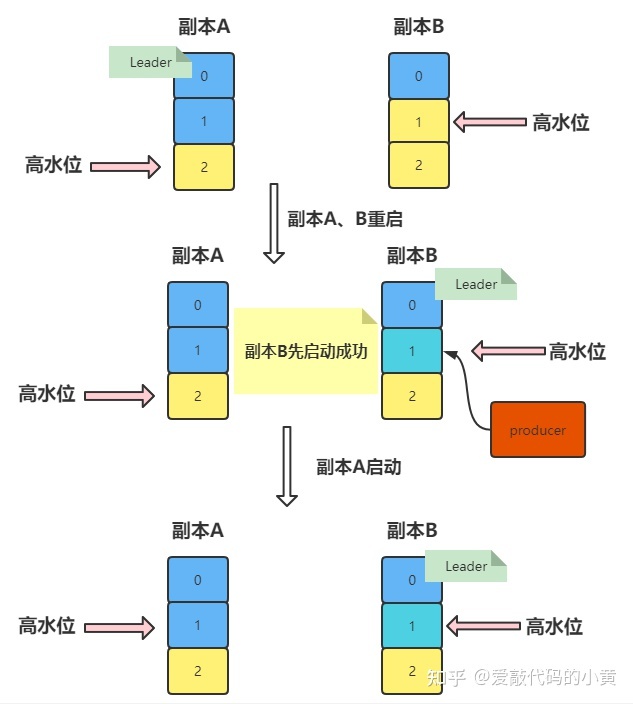
当我们的副本B想要同步副本A的消息时,这个时候,副本A和副本B都发生了重启的操作。
我们的副本B先启动成功,成功当选 Leader,这个时候我们的生产者会将数据发送到副本B中,也就是图中的 1。
等到副本A启动成功时,会与 Leader 副本进行同步,发现 Leader副本的 LEO 和 HW 都为1,这个时候,副本A不需要进行任何操作。
我们观察结果,可以看到,我们副本A的数据和副本2的数据发生了不一致的现象。
3.Leader Epoch
造成上述两个问题的根本原因在于HW值被用于衡量副本备份的成功与否以及在出现failture时作为日志截断的依据,但HW值的更新是异步延迟的,特别是需要额外的FETCH请求处理流程才能更新,故这中间发生的任何崩溃都可能导致HW值的过期。鉴于这些原因,Kafka 0.11引入了leader epoch来取代HW值。Leader端多开辟一段内存区域专门保存leader的epoch信息,这样即使出现上面的两个场景也能很好地规避这些问题。
所谓leader epoch实际上是一对值:(epoch,offset)。epoch表示leader的版本号,从0开始,当leader变更过1次时epoch就会+1,而offset则对应于该epoch版本的leader写入第一条消息的位移。因此假设有两对值:
(0, 0)则表示leader从位移0开始写入消息;共写了120条[0, 119]。
(1, 120)则表示leader版本号是1,从位移120处开始写入消息。
leader broker中会保存这样的一个缓存,并定期地写入到一个checkpoint文件中。
当leader写底层log时它会尝试更新整个缓存——如果这个leader首次写消息,则会在缓存中增加一个条目;否则就不做更新。而每次副本重新成为leader时会查询这部分缓存,获取出对应leader版本的位移,这就不会发生数据不一致和丢失的情况。
下面我们依然使用图的方式来说明下利用leader epoch如何规避上述两种情况:
3.1 规避数据丢失
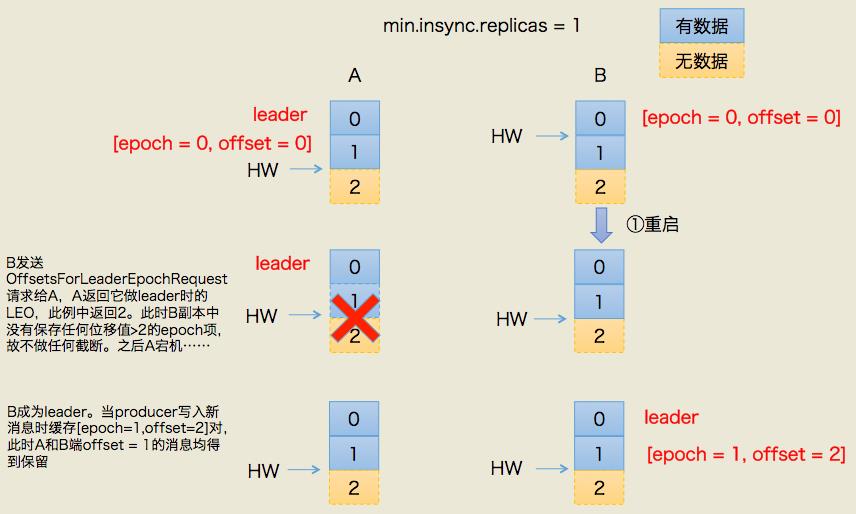
上图左半边已经给出了简要的流程描述,这里不详细展开具体的leader epoch实现细节(比如OffsetsForLeaderEpochRequest的实现),我们只需要知道每个副本都引入了新的状态来保存自己当leader时开始写入的第一条消息的offset以及leader版本。这样在恢复的时候完全使用这些信息而非水位来判断是否需要截断日志。
3.2 规避数据不一致
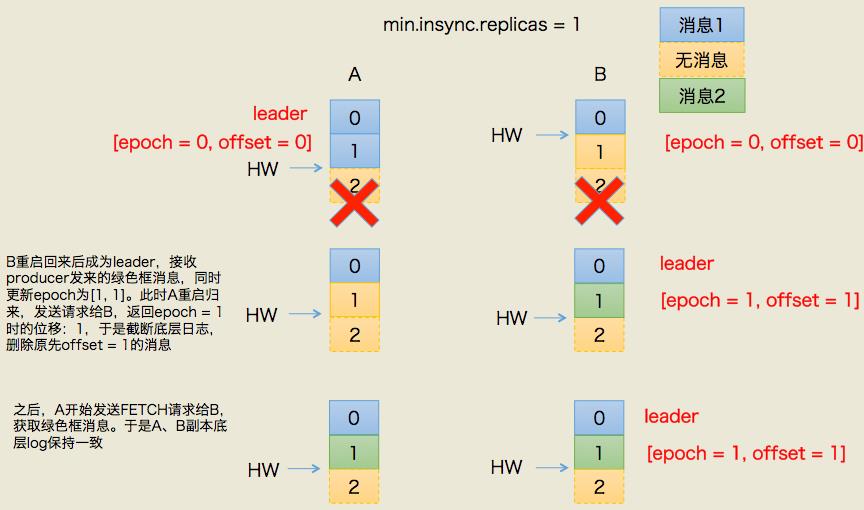
同样的道理,依靠leader epoch的信息可以有效地规避数据不一致的问题。
以上是关于kafka的副本同步机制---关于高水位和Leader Epoch的主要内容,如果未能解决你的问题,请参考以下文章