Hive实战 —— 利用Hive进行数据分析并将分析好的数据导出到mysql数据库中
Posted it春和
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hive实战 —— 利用Hive进行数据分析并将分析好的数据导出到mysql数据库中相关的知识,希望对你有一定的参考价值。
🙆♂️🙆♂️ 写在前面
🏠 个人主页:csdn春和
📚 推荐专栏:更多专栏尽在主页!
JavaWeb专栏(从入门到实战超详细!!!)
SSM专栏 (更新中…)
📖 本期文章:Hive实战 —— 利用Hive进行数据分析并将分析好的数据导出到mysql数据库中
如果对您有帮助还请三连支持,定会一 一回访!🙋🏻♂️
📌本文目录
📍 写在前面
本次文章记录自己的一次实验过程,详细实验请参考尚硅谷的Hive教程
hive实战
一、需求分析
统计热门视频Top10 (以播放数作为参考标准) 简单需求
将统计结果导出到mysql中
✔️ 目的为了熟悉各种操作过程
二、数据准备
2.1、查看原始数据
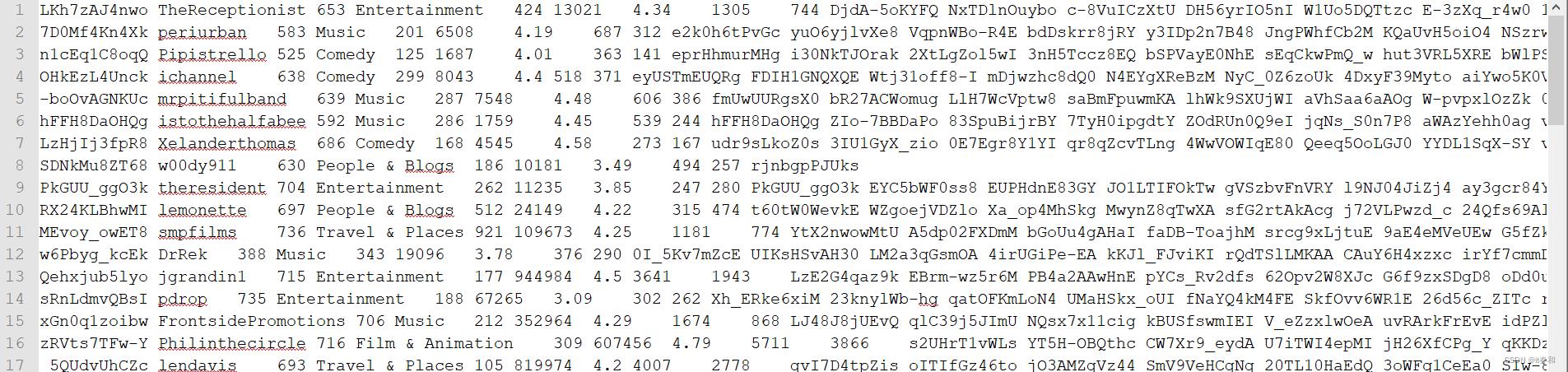
2.2、表的数据结构
| 字段 | 备注 | 详细描述 |
|---|---|---|
| videoId | 视频唯一id(String) | 11位字符串 |
| uploader | 视频上传者(String) | 上传视频的用户名String |
| age | 视频年龄(int) | 视频在平台上的整数天 |
| category | 视频类别(Array) | 上传视频指定的视频分类 |
| length | 视频长度(Int) | 整形数字标识的视频长度 |
| views | 观看次数(Int) | 视频被浏览的次数 |
| rate | 视频评分(Double) | 满分5分 |
| Ratings | 流量(Int) | 视频的流量,整型数字 |
| conments | 评论数(Int) | 一个视频的整数评论数 |
| relatedId | 相关视频id(Array) | 相关视频的id,最多20个 |
2.3、数据清洗
通过观察原始数据形式,可以发现,视频可以有多个所属分类,每个所属分类用&符号分割,且分割的两边有空格字符,同时相关视频也是可以有多个相关视频,多个相关视频又用“\\t”进行分割。为了分析数据时方便对存在多个子元素的数据进行操作,我们首先进行数据重组清洗操作。
即:
将所有的类别用“&”分割,同时去掉两边空格,多个相关视频id也使用“&”进行分割。
我们使用过MapReduce进行数据清理
新建一个module 导入依赖
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
</dependencies>
【1】封装工具类
package com.itch.video.etl;
/**
* @author it春和
* @create 2022-05-09 22:29
*/
public class EtlUtils
// 工具类
/**
* 数据清洗的方法
* @param srcData 原始数据
* @return
*/
public static String etlData(String srcData)
StringBuffer resultData = new StringBuffer();
//1. 先将数据通过\\t 切割
String[] datas = srcData.split("\\t");
//2. 判断长度是否小于9
if(datas.length <9)
return null ;
//3. 将数据中的视频类别的空格去掉
datas[3]=datas[3].replaceAll(" ",""); // 将所有空格替换成空串
//4. 将数据中的关联视频id通过&拼接
for (int i = 0; i < datas.length; i++)
if(i < 9)
//4.1 没有关联视频的情况
if(i == datas.length-1)
resultData.append(datas[i]);
else
resultData.append(datas[i]).append("\\t");
else
//4.2 有关联视频的情况
if(i == datas.length-1)
resultData.append(datas[i]);
else
resultData.append(datas[i]).append("&");
return resultData.toString();
测试:
public static void main(String[] args)
// 测试方法
// 有相关视频
String line1 = "RX24KLBhwMI\\tlemonette\\t697\\tPeople & Blogs\\t512\\t24149\\t4.22\\t315\\t474\\tt60tW0WevkE\\tWZgoejVDZlo\\tXa_op4MhSkg\\tMwynZ8qTwXA\\tsfG2rtAkAcg\\tj72VLPwzd_c\\t24Qfs69Al3U\\tEGWutOjVx4M\\tKVkseZR5coU\\tR6OaRcsfnY4\\tdGM3k_4cNhE\\tai-cSq6APLQ\\t73M0y-iD9WE\\t3uKOSjE79YA\\t9BBu5N0iFBg\\t7f9zwx52xgA\\tncEV0tSC7xM\\tH-J8Kbx9o68\\ts8xf4QX1UvA\\t2cKd9ERh5-8";
// 没有相关视频
String line2 = "RX24KLBhwMI\\tlemonette\\t697\\tPeople & Blogs\\t512\\t24149\\t4.22\\t315\\t474";
// 不合法数据 字段小于9个
String line3 = "RX24KLBhwMI\\tlemonette\\t697\\tPeople & Blogs\\t512\\t24149\\t4.22\\t315";
String res1 = etlData(line1);
String res2 = etlData(line2);
String res3 = etlData(line3);
System.out.println(res1);
System.out.println(res2);
System.out.println(res3);

【2】编写mapper
package com.itch.video.etl;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* @author it春和
* @create 2022-05-09 22:28
*/
public class EtlMapper extends Mapper<LongWritable, Text, Text, NullWritable>
private Text k = new Text();
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, NullWritable>.Context context) throws IOException, InterruptedException
//获取一行
String line = value.toString();
//清洗
String resultData = EtlUtils.etlData(line);
if (resultData != null)
//写出
k.set(resultData);
context.write(k, NullWritable.get());
【3】编写Driver
package com.itch.video.etl;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* @author it春和
* @create 2022-05-09 22:28
*/
public class EtlDriver
public static void main(String[] args) throws Exception
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(EtlDriver.class);
job.setMapperClass(EtlMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
job.setNumReduceTasks(0);
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
job.waitForCompletion(true);
【4】将程序打包

【5】将jar包上传到linux

【6】进行数据清理
1️⃣ 在hdfs上新建目录用于存放原始数据和清洗后的数据

2️⃣ 将原始数据上传到hdfs

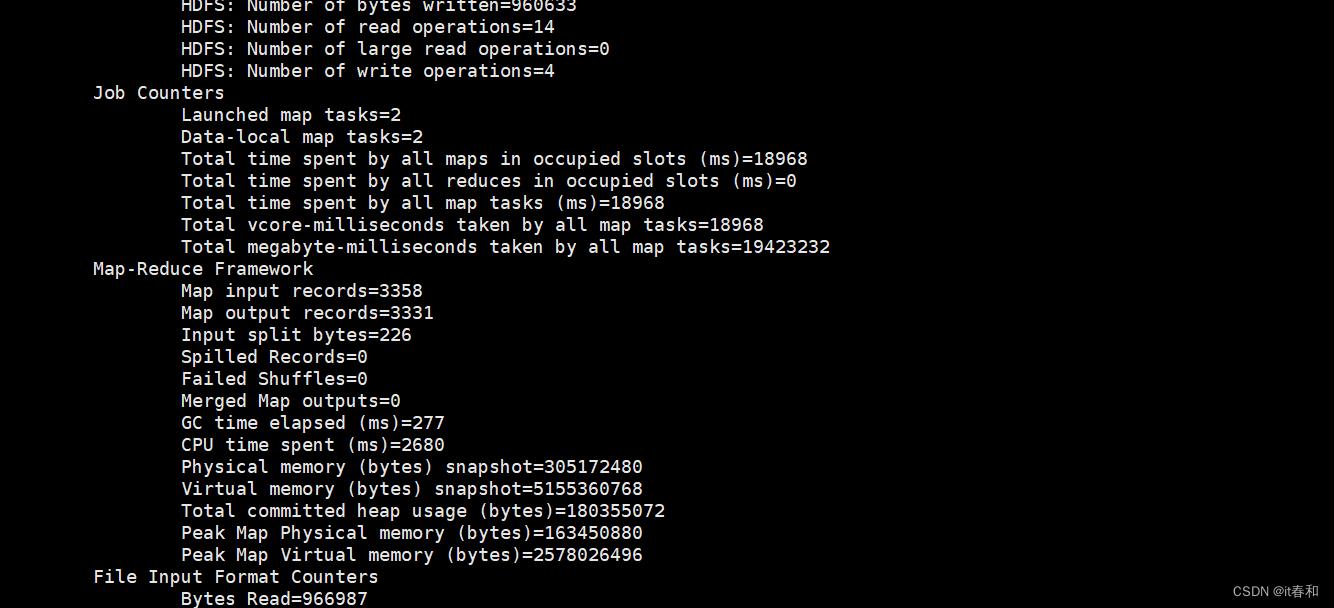
3️⃣ 跑MapReduce进行数据清洗
hadoop jar 打包上传到linux的jar包 Driver的全限定名 输入目录 输出目录
2.4、准备hive表
✔️ 创建表
create table video(
videoId string,
uploader string,
age int,
category array<string>,
length int,
views int,
rate float,
ratings int,
comments int,
relatedId array<string>)
row format delimited fields terminated by "\\t"
collection items terminated by "&"
stored as textfile;
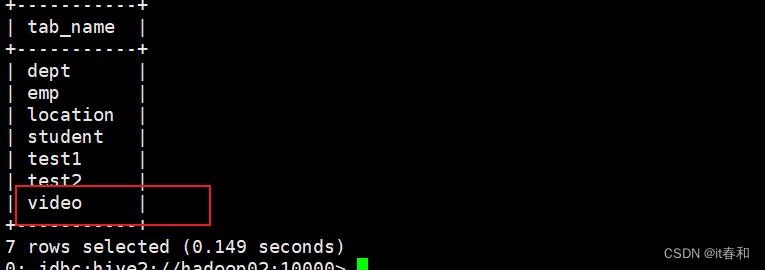
✔️ 向表中装载数据
三、实现业务需求
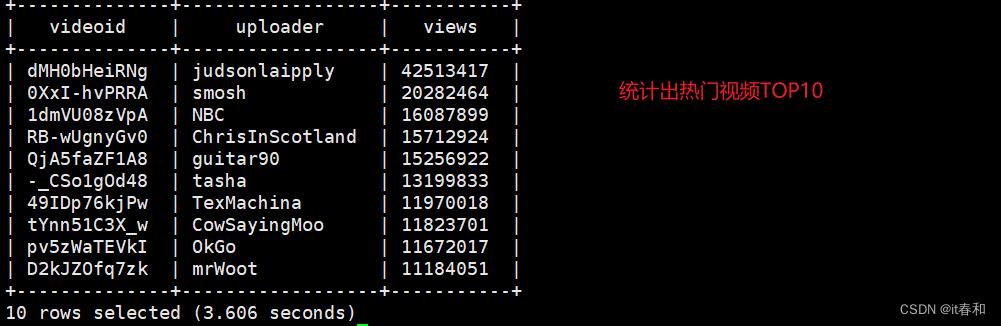
3.1、统计视频观看数Top10
-- 使用order by按照views字段做一个全局排序即可,同时我们设置只显示前10条。
select
videoId,
uploader,
views
from
video
order by
views desc
limit 10;
✔️ 首先开启本地模式
开启本地模式可以优化hive的性能

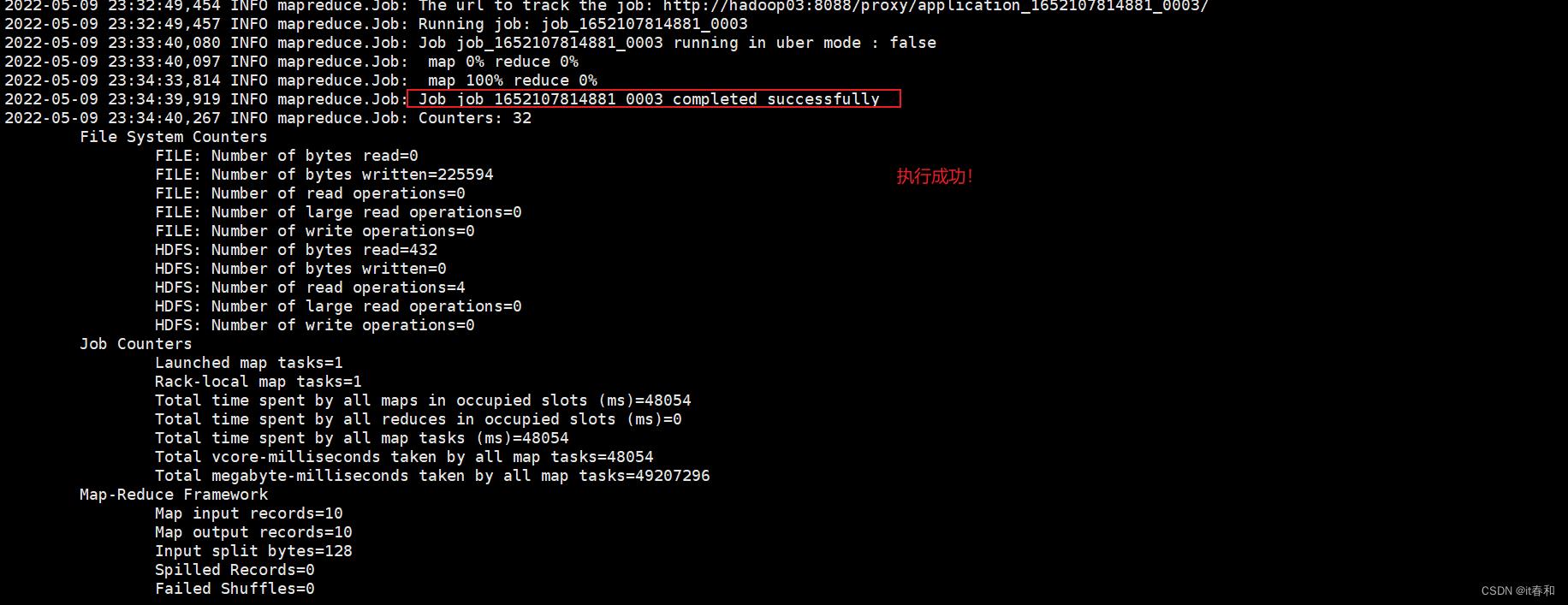
✔️ 执行sql
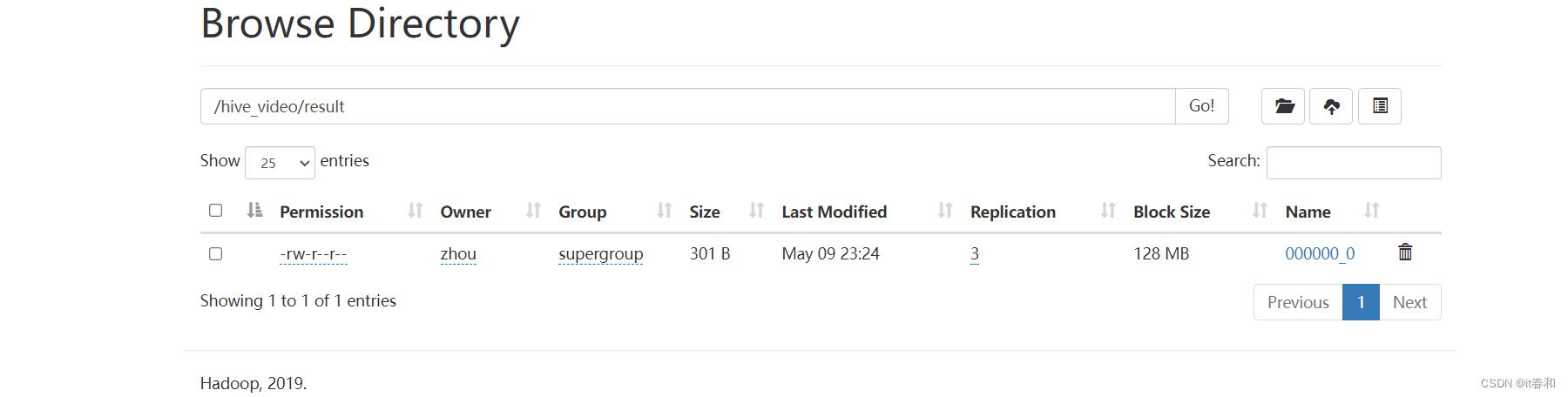
3.2、将查询结果导出到hdfs上
insert overwrite directory '/hive_video/result' -- 存放在hdfs的目录
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\\t'
select
videoId,
uploader,
views
from
video
order by
views desc
limit 10;
3.3、将分析好的数据导出Mysql
1️⃣ 在mysql中创建一张表
创建表的时候注意对应字段
CREATE TABLE hive_res1(
videoId VARCHAR(50),
uploader VARCHAR(50),
views INT
);
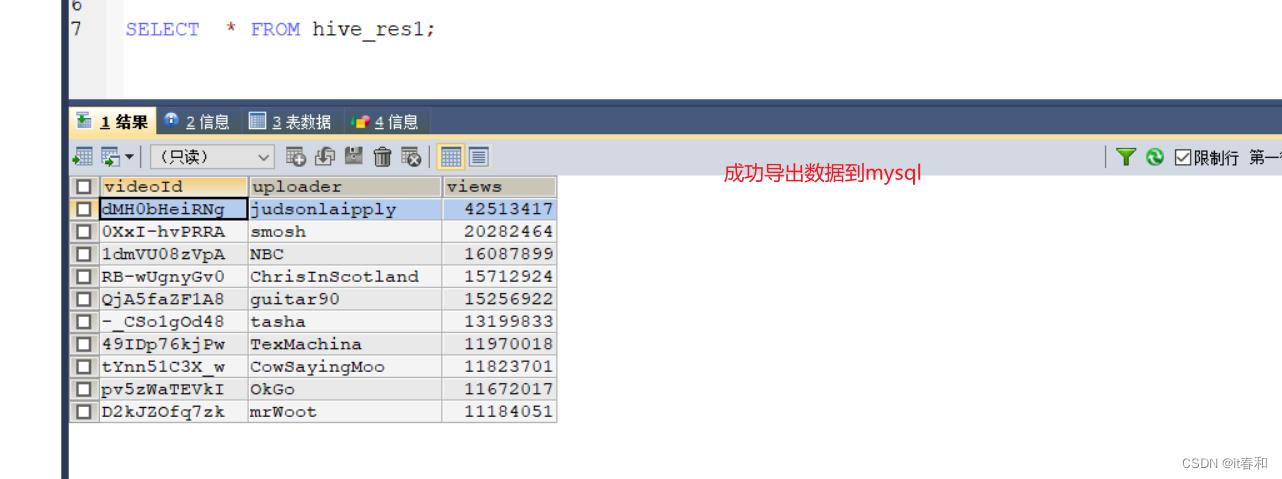
SELECT * FROM hive_res1;
2️⃣ 使用sqoop从hdfs上将分析好的数据导出到mysql中
bin/sqoop export \\
--connect jdbc:mysql://hadoop02:3306/study \\
--username root \\
--password 123456 \\
--table hive_res1 \\
--export-dir /hive_video/result \\
--input-fields-terminated-by "\\t" \\
--num-mappers 1
3️⃣ 查看mysql中是否有数据
以上是关于Hive实战 —— 利用Hive进行数据分析并将分析好的数据导出到mysql数据库中的主要内容,如果未能解决你的问题,请参考以下文章