Kylin的入门实战
Posted Maynor学长
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kylin的入门实战相关的知识,希望对你有一定的参考价值。
1. 基于Kylin的预警分析
1.1. Kylin简介
- Kylin的诞生背景
1.Kylin 是一款大数据OLAP引擎,由ebay-中国团队研发的,是第一个真正由中国人自己主导、从零开始、自主研发、并成为Apache顶级开源项目
2.Hive的性能比较慢,支持SQL灵活查询
3.HBase的性能快,原生不支持SQL
4.Kylin是将先将数据进行预处理,将预处理的结果放在HBase中。效率很高
1.2. 为什么要使用Kylin
Kylin 是一个 Hadoop 生态圈下的 MOLAP 系统,是 ebay 大数据部门从2014 年开始研发的支持 TB 到 PB 级别数据量的分布式 Olap 分析引擎。其特点包括:
1.可扩展的超快的 OLAP 引擎
2.提供 ANSI-SQL 接口
3.交互式查询能力
4.MOLAP Cube 的概念(立方体)
5.与 BI 工具可无缝整合
1.3. Kylin的应用场景
Kylin 典型的应用场景如下:
1.用户数据存在于Hadoop HDFS中,利用Hive将HDFS文件数据以关系数据方式存取,数据量巨大,在500G以上
2.每天有数G甚至数十G的数据增量导入
3.有10个以内较为固定的分析维度
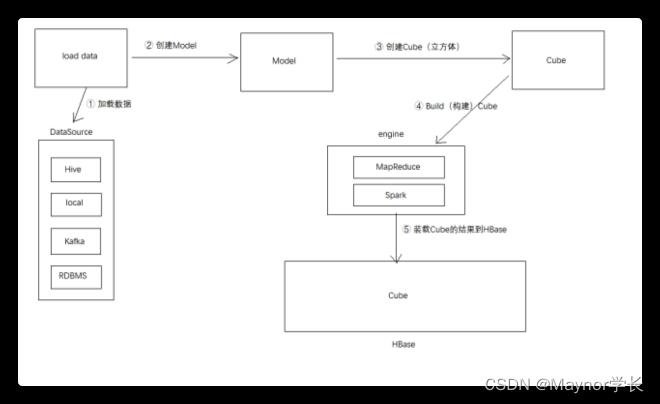
Kylin 的核心思想是利用空间换时间,在数据 ETL 导入 OLAP 引擎时提前计算各维度的聚合结果并持久化保存

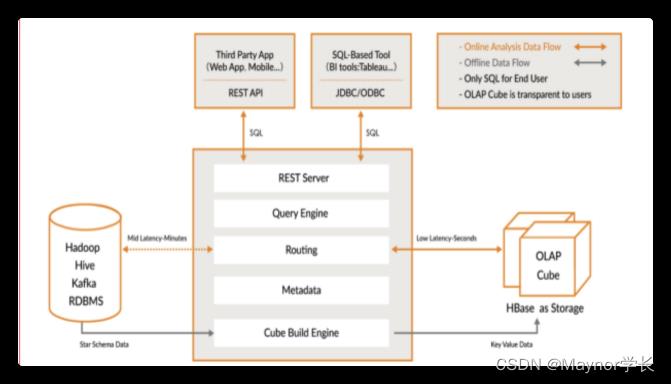
1.4. Kylin的总体架构
Kylin 依赖于 Hadoop、Hive、Zookeeper 和 Hbase
2. Kylin启动
2.1. 启动集群
1、启动zookeeper
(1) zkServer.sh start
2、启动HDFS
(1) start-all.sh
3、启动YARN集群
4、启动HBase集群
start-hbase.sh
5、启动 metastore
nohup hive --service metastore &
6、启动 hiverserver2
nohup hive --service hiveserver2 &
7、启动Yarn history server
mr-jobhistory-daemon.sh start historyserver
8、启动spark history server【可选】
sbin/start-history-server.sh
9、启动kylin
./kylin.sh start
10、登录Kylin
| url | http://IP:7070/kylin |
|---|---|
| 默认用户名 | ADMIN |
| 默认密码 | KYLIN |
用户名和密码都必须是大写
3. Kylin实战 - 使用Kylin进行OLAP分析
3.1. 测试数据表结构介绍
1、(事实表)dw_sales
| 列名 | 列类型 | 说明 |
|---|---|---|
| id | string | 订单id |
| date1 | string | 订单日期 |
| channelid | string | 订单渠道(商场、京东、天猫) |
| productid | string | 产品id |
| regionid | string | 区域名称 |
| amount | int | 商品下单数量 |
| price | double | 商品金额 |
2、(维度表_渠道方式)dim_channel
| 列名 | 列类型 | 说明 |
|---|---|---|
| channelid | string | 渠道id |
| channelname | string | 渠道名称 |
3、(维度表_产品名称)dim_product
| 列名 | 列类型 | 说明 |
|---|---|---|
| productid | string | 产品id |
| productname | string | 产品名称 |
4、(维度表_区域)dim_region
| 列名 | 类类型 | 说明 |
|---|---|---|
| regionid | string | 区域id |
| regionname | string | 区域名称 |
3.2. 导入测试数据
为了方便后续学习Kylin的使用,需要准备一些测试表、测试数据。
1.Hive中创建表
2.将数据从本地文件导入到Hive
操作步骤
1、使用 beeline 连接Hive
!connect jdbc:hive2://node01:10000
2、创建并切换到 itcast_dw 数据库
create database itcast_dw;use itcast_dw;
3、创建测试数据文件夹,并将测试数据文件上传到该文件夹中
mkdir -p /export/servers/tmp/kylin
将“4.资料> 02.Kylin> 4.kylin_实战_hive_建表语句> 数据文件”中的数据上传至此目录
4、找到资料中的“4.资料> Kylin> 4.kylin_实战_hive_建表语句> hive.sql”文件,执行sql、创建测试表,并导入数据到表中
– 查看表是否创建成功show tables;
5、执行一条SQL语句,确认数据是否已经成功导入
select from dw_sales;
3.3. 按照日期统计订单总额/总数量(Hive方式)
操作步骤:
1、使用beeline连接Hive
2、切换到itcast_dw数据库
3、编写SQL语句
操作步骤:
1、使用beeline连接Hive
2、切换到itcast_dw数据库
use itcast_dw;
2、在代码目录中创建sql文件,编写SQL语句
select date1, sum(price) as total_money, sum(amount) as total_amount from dw_sales group by date1;
以上是关于Kylin的入门实战的主要内容,如果未能解决你的问题,请参考以下文章