大数据物流项目中CM的安装与运用
Posted Maynor学长
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据物流项目中CM的安装与运用相关的知识,希望对你有一定的参考价值。
文章目录
大数据服务器之CM安装架构及目录
针对整个物流项目来说,1台虚拟机安装部署大数据环境:
基于CM6.2.1安装CDH6.2.1。

提供虚拟机【
node2.itcast.cn】解压后,导入VMWare 软件中,启动虚拟机即可(选择我已移动该虚拟机)
- 1)、启动之前,设置node2.itcast.cn内存:
4GB或者6GB或者8GB即可- 2)、第一次启动虚拟机时,很慢很慢很慢,由于启动所有服务(CM安装CDH服务),时间5分钟以上
- 浏览器登录:http://node2.itcast.cn:7180/cmf/,
admin/admin- 将所有服务关闭:各个框架服务和CMS服务,而且CMS服务永远给关闭
- 3)、测试时,需要什么服务,启动什么服务,不要全部启动(耗内存,耗性能,没有任何意义)

架构原理:CM如何安装CDH框架,原理架构是什么?????
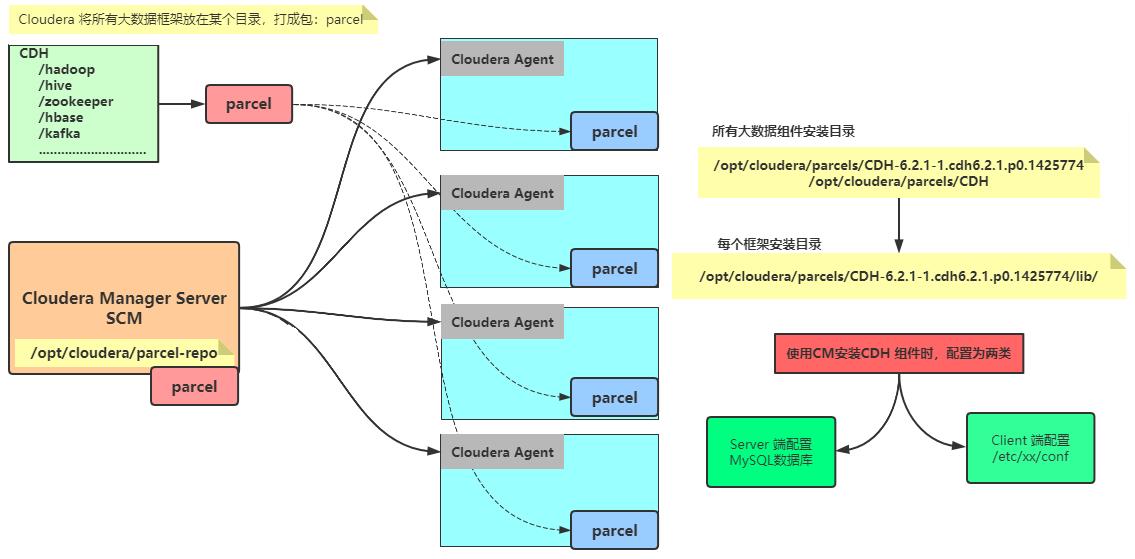
1)、CM安装CDH集群时,架构属于主从分布式架构(Master/Slaves)
主节点(老大):CMS(ClouderaManagerServer),在一台机器上运行
从节点(小弟):安装服务(Cloudera Agent),所有大数据集群机器

2)、Cloudera 将所有大数据框架放在某个目录,
打成包:parcel
- 首先parcel包,存储在CMServer主机的目录:
/opt/cloudera/parcel-repo

3)、CMServer服务,将parcel包,分发给所有大数据集群机器:Cloudera Agent
- 当所有集群机器下载parcel包以后,解压:
/opt/cloudera/parcels
- 每个框架安装目录:
/opt/cloudera/parcels/CDH/lib/框架名称
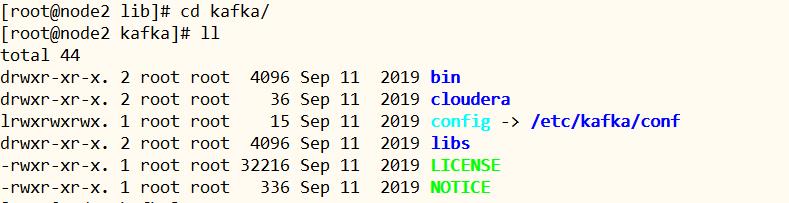
- 进入Kafka软件安装目录:
/opt/cloudera/parcels/CDH/lib/kafka


大数据服务器之CDH框架安装细节
当使用CM安装CDH集群以后,可以通过CM界面UI,管理整个集群服务和查看监控运行状态。
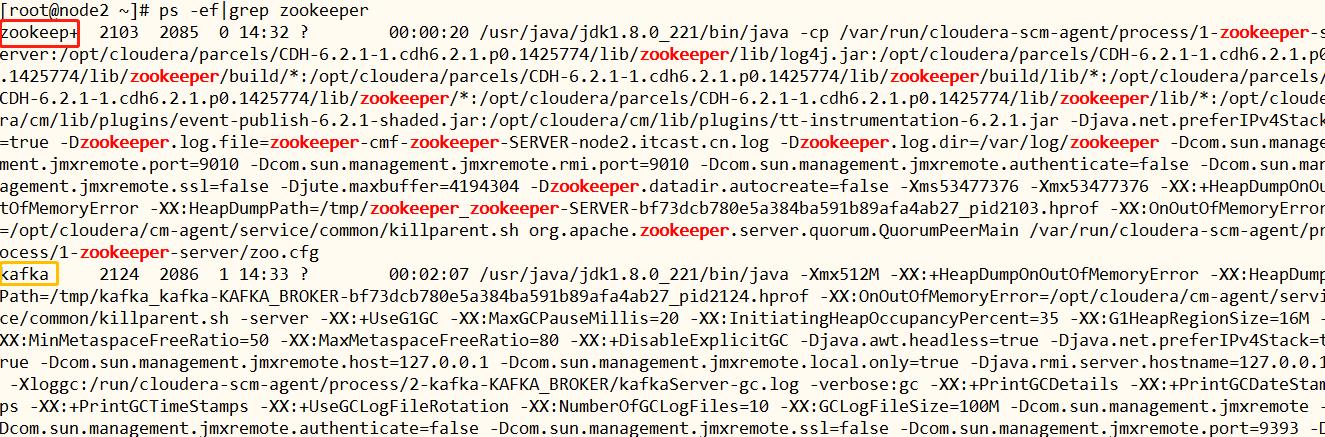
- 第一、框架用户,实际项目中按照大数据各个框架时,不建议使用root用户,创建普通用户。
使用CM安装CDH集群时,针对每个框架(比如,HDFS、MAPREDUCE、YARN等)创建用户,不可以被用于登录操作系统。
以框架名称创建用户,所有用户名为框架名称。
第一点:linux系统:
/etc/passwd
第二点:启动服务,所使使用用户

- 第二、服务配置
使用CM安装CDH组件时,配置分为2类:
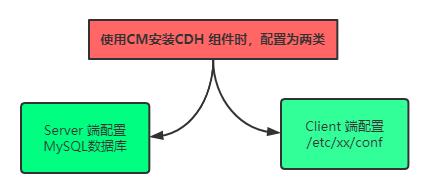
第一类、服务端Server配置,启动服务Server时加载配置文件
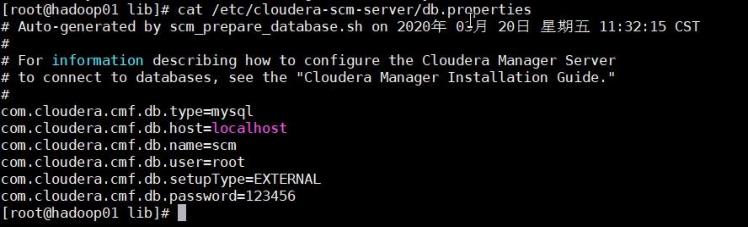
- 存储在数据库中,物流项目中配置的是mysql数据库:
scm
第二类、客户端Client配置,客户端连接服务时配置信息
- 存储在配置文件,在系统目录:
/etc/xx/conf,其中xx表示框架名称- 以Kafka框架为例:

- 第三、服务日志
使用CM安装CDH组件时,默认启动服务时,日志文件存储目录:
/var/log/xx/

- 第四、切换用户
由于每个框架都有自己用户,所以有时候对框架进行操作时,需要切换到框架用户,比如在HDFS文件系统上创建目录,使用
hdfs用户,如下所示切换用户:
# root切换框架用户方式
sudo -u userName
# 举例说明:
[root@node2 ~]# sudo -u hdfs hdfs dfs -mkdir -p /datas
[root@node2 ~]# sudo -u hdfs hdfs dfs -ls

以上是关于大数据物流项目中CM的安装与运用的主要内容,如果未能解决你的问题,请参考以下文章