大淘宝技术斩获NTIRE视频增强和超分比赛冠军(内含夺冠方案)
Posted 阿里巴巴淘系技术团队官网博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大淘宝技术斩获NTIRE视频增强和超分比赛冠军(内含夺冠方案)相关的知识,希望对你有一定的参考价值。

近日,NTIRE比赛结果公布,大淘宝技术视频增强算法团队STaoVideo表现出色,获得视频超分辨率与质量增强挑战赛两个赛道冠军🎉。
NTIRE赛事介绍
2022年CVPR NTIRE比赛结果公布,大淘宝音视频算法与基础技术团队表现出色,在视频超分与质量增强比赛的三个赛道获得两个赛道冠军一个赛道亚军。
▐ 视频增强和2倍超分冠军
近日,2022年NTIRE视频增强和超分比赛成绩揭晓。在三个赛道中,淘宝音视频算法与基础技术团队取得Track1视频增强赛道冠军、Track2视频2倍超分增强赛道冠军、Track3视频4倍超分增强亚军的成绩。CVPR NTIRE(New Trends in Image Restoration and Enhancement workshop and challenges on image and video processing)是全球图像视频增强方面的顶级竞赛。继在MSU世界编码器比赛夺魁后,团队再次在音视频的核心方向的权威比赛中折桂。
我们提出方法在NTIRE 2022压缩视频超分辨率和质量增强挑战赛的三个赛道表现如表1所示。
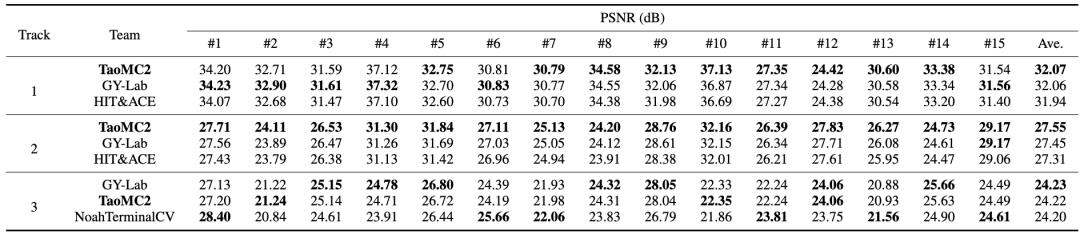
表1 淘宝音视频算法(TaoMC2)在NTIRE 2022挑战赛中的成绩
▐ NTIRE比赛:压缩视频增强超分benchmark
NTIRE压缩视频超分和增强比赛预期建立压缩视频增强和超分的benchmark。比赛采用了包含动物、城市、室内、公园等多种场景的视频,帧率从24fps到60fps,视频精心挑选了4k无明显压缩噪声原视频,所以这些都是为了让视频更接近真实应用场景。
三个赛道分别是:
Track1是针对包括视频编码中(如采用HEVC)的高压缩比带来的失真的视频恢复问题。
Track2在Track1的基础上,增加挑战性,要求参赛者同时处理高压缩和2倍超分问题。
Track3在Track2的基础上进一步探索4倍超分和增强问题。
Track1的视频增强和Track2的2倍超分增强已经非常接近实际的应用场景。视频增强和2倍超分目前是工业界均有应用,将视频还原到理想视频的质量能够大幅提升人眼感官,吸引人们更愿意观看视频。
今年的NTIRE比赛视频增强和超分比赛云集了国内外十几支参赛团队,包括腾讯、字节、华为等知名科技企业,中科院、北大、港中文、ETH等科研机构都有参赛,其中很多比赛者都有多年的参赛经验,竞争激烈。
NTIRE本次发布了正式比赛报告:https://arxiv.org/abs/2204.09314
经过激烈的角逐,大淘宝技术的音视频算法与基础技术团队最终取得了两冠一亚的成绩。
团队方法(TaoMC2)在Track1赛道上超第二名0.01dB、第三名0.13dB,且在15个测试集中的9个视频上表现最佳,说明方法具有较好的泛化性。同时,团队方法(TaoMC2)在Track2赛道上超过第二名0.1dB,以绝对优势超出其他队伍,在Track3赛道上仅次于第一名0.01dB。
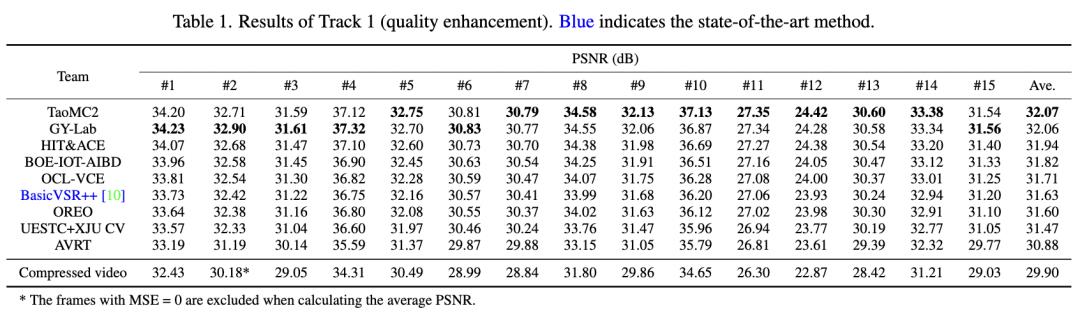
表2 NTIRE 2022挑战赛Track1(视频增强赛道)各赛队PSNR 对比
对比
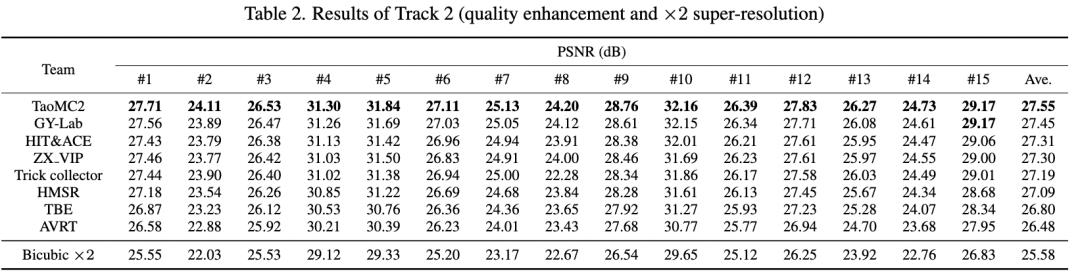
表3 NTIRE 2022挑战赛Track2(视频增强与2倍超分赛道)各赛队PSNR 对比
对比
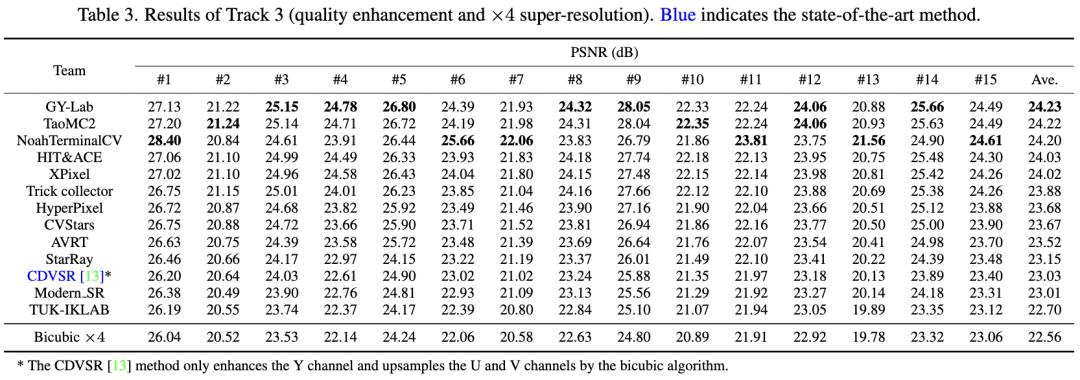
表4 NTIRE 2022挑战赛Track3(视频增强与4倍超分赛道)各赛队PSNR 对比
对比
后文我们分享具体的方案——
项目摘要
视频恢复是一个具有广泛应用场景的问题,其目标是对含有噪声、模糊和压缩伪影等问题的低画质视频进行增强。视频超分和视频去压缩伪影是实际应用中最重要的两种视频恢复任务。循环神经网络(Recurrent Neural Network, RNN)和全自注意力网络(Transformer)具有很好的序列建模特性,近年来在视频恢复领域受到了广泛的关注。然而RNN和Transformer的训练开销巨大,训练过程中也容易出现梯度消失和梯度爆炸问题,导致模型难以收敛。针对这些问题,我们提出一个包含多帧RNN和单帧Transformer的两阶段网络,同时使用迁移学习和预训练来缩短训练时间,利用渐进式训练方法进一步提升模型性能。基于上述先进性技术,此方案在NTIRE2022视频超分与压缩伪影增强挑战赛中获得了两项冠军和一项亚军的成绩。
方案背景
近年来,互联网视频数据呈爆炸式增长。与此同时,视频的分辨率也越来越高,以满足人们对视频体验质量(Quality of Experience, QoE)日益增长的需求。但是,由于带宽的限制,网络传输视频通常会被降采样和压缩,这不可避免地会导致视频质量的下降。因此,超分辨率、压缩伪影增强等视频恢复任务在计算机视觉领域受到了广泛的关注。
视频恢复任务需要从视频序列中多个高度相关但并未对齐的低质量帧中提取信息,具有较高的挑战性。现有的视频恢复方法大多将其视为时空序列预测问题,主要可分为两类:滑动窗口方法[9,15,32,35,42]和循环方法[4,5,19]。例如, BasicVSR++[5]提出了一种二阶网格传播网络来更好地挖掘时空信息。它展示了循环方法的有效性,并赢得了NTIRE 2021高压缩伪影视频质量增强挑战赛的冠军。然而,循环方法在时间顺序上对视频进行逐帧串行处理,计算效率不高。最近一些工作[2,23]尝试利用Transformer来并行计算,但循环方法和Transformer的计算复杂度都是序列长度和图像大小的平方,整体计算复杂度为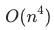 。由于这些网络巨大的显存开销,即使是在英伟达A100 GPU上,每次训练也无法加载16帧以上的输入序列,导致在REDs数据集[27]上性能不如BasicVSR++方法。除了GPU内存消耗较大外,像Transformer这样复杂的模型也比较难以训练和调优。此外,“大”模型也更容易出现过拟合,导致不同视频增强效果的质量波动。
。由于这些网络巨大的显存开销,即使是在英伟达A100 GPU上,每次训练也无法加载16帧以上的输入序列,导致在REDs数据集[27]上性能不如BasicVSR++方法。除了GPU内存消耗较大外,像Transformer这样复杂的模型也比较难以训练和调优。此外,“大”模型也更容易出现过拟合,导致不同视频增强效果的质量波动。
针对上述问题,我们提出了一种基于循环网络和Transformer的两阶段视频恢复框架。具体来说,第一阶段用于粗恢复视频帧,并减少帧间质量波动。第二阶段对第一阶段的恢复结果进行逐帧精调,可以有效恢复受损严重的区域。第一阶段网络基于BasicVSR++进行改进,第二阶段采用SwinIR[24]作为骨干网络。这两个模型分别进行训练,以节省内存资源,进一步提高精度。此外,在这两个阶段的训练过程中采用了迁移学习和渐进训练策略,不仅加快了收敛速度,还提高了最终的视频恢复性能。
综上所述,我们的贡献如下:
提出了一个两阶段的视频恢复框架,以同时消除压缩伪影和缓解帧间质量波动。
引入了一种渐进式模型训练方案,以稳定模型训练并提高最终性能。
引入了迁移学习和预训练方案,以缩短模型训练时间。
我们提出的方法在增强性能和模型复杂度之间实现了很好的权衡,并赢得了NTIRE2022视频超分与压缩伪影增强挑战赛。
相关工作
▐ 视频恢复
压缩视频质量增强作为视频恢复的主要研究方向之一,在过去的几年里得到了的广泛研究[11,15,35,41,42]。其中,现有的方法大多是基于单帧的质量增强[11,35,41]。观察到压缩后的视频帧之间存在明显的质量波动,MFQE[42]及其扩展版本MFQE 2.0[15]提出利用邻近的高质量帧对待增强帧进行补偿。这两个方法采用时序融合方案,利用显示光流预测来进行运动补偿。STDF[9]利用可变形卷积,同样考虑了时序信息补偿,并避免了显式光流估计不准可能导致的对齐问题。
视频超分
除了压缩视频质量增强,视频超分辨率(VSR)也是视频恢复的一个主要研究方向。VSR通过提高视频帧的分辨率来恢复视频质量,与单张图像超分辨率(single image super resolution, SISR)不同,VSR可以利用相邻帧信息来重建高分辨率序列。现有的VSR方法可分为两类:基于滑动窗口的方法[22,32,36,43]和循环方法[4,5,18,19]。其中,EDVR[32]采用可变形卷积[8,46]来对齐相邻帧。与EDVR类似,D3DNet[43]利用可变形的3D卷积挖掘视频时空信息。BasicVSR[4]对VSR方法中的传播、对齐、聚合、上采样等基本组件进行了梳理,并提出一个简洁有效的基线方法。在BasicVSR基础上,BasicVSR++[5]通过双向传播策略和光流引导的可变形卷积对齐进一步提高了性能。
我们采用BasicVSR++作为第一阶段的骨干模型。
▐ 视觉Transformer
近年来,起源于自然语言处理 (Natural Language Processing, NLP)的Transformer网络在许多视觉任务中表现优异,包括图像分类、目标检测、语义分割、人体姿态估计和视频分类[1,3,12,16,26,26,34,34,44]。具体地,Swin Transformer[26]提出了一种具有滑动窗口机制的层级Transformer结构,既有CNN的归纳偏置,又有Transformer具有长程注意力的优点。
也有工作尝试将Transformer应用到底层视觉任务中[6,7,20,24,33,37,45]。例如,SwinIR[24]提出了基于Swin Transformer的图像恢复模型,它不仅能够很好地处理局部相关性,还能有效地捕获长程依赖关系。Uformer[33]提出了一种通用的基于UNet的Transformer结构,在真实场景图像降噪任务中表现出了杰出的性能。
Transformer也被用于视频恢复任务[2,13,23]。VSRT[2]利用Transformer的并行计算能力来并行化相邻帧特征对齐。VRT[23]提出了时序交互自注意模块,用于更好地挖掘时空信息。但是由于这些方法模型训练消耗巨大的显存资源,目前还无法实现较长的输入视频帧训练。
我们采用SwinIR作为第二阶段的骨干模型。
方法
▐ 两阶段网络框架
我们提出的两阶段视频恢复框架如图2所示。其中,第一阶段(Stage I)网络基于BasicVSR++,在其基础上将二阶补偿替换为峰值质量帧(Peak Quality Frames, PQF)[15,42],此外,将BasicVSR++[5]的重建模块从5个残差模块加深到55个残差模块。第二阶段(Stage II)利用SwinIR[24]去除严重的压缩伪影,并进一步提高视频帧质量,SwinIR是当前图像恢复领域最先进的网络之一。最后,将第一阶段和第二阶段的网络进行级联,并生成最终的视频增强结果。具体来说,首先将连续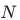 张带有压缩伪影的原始视频帧
张带有压缩伪影的原始视频帧 输入第一阶段模型,再将第一阶段的输出
输入第一阶段模型,再将第一阶段的输出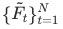 逐帧输入第二阶段,第二阶段的输出
逐帧输入第二阶段,第二阶段的输出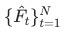 作为最终的增强结果,并拼接成增强后的视频。
作为最终的增强结果,并拼接成增强后的视频。
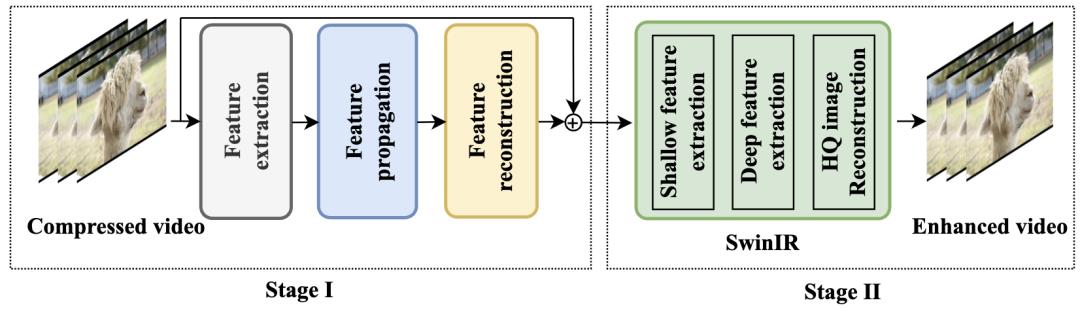
图2 两阶段网络框架
▐ 第一阶段网络与渐进式训练
如图3所示,第一阶段网络主要包含三个模块:特征提取、传播和图像重建。给定一个输入视频,首先利用两个步长为2的卷积和五个残差模块提取输入视频帧空间特征,同时使用双三次滤波器对输入帧进行4倍下采样,并输入SpyNet[29]计算前、后向光流。接下来,对于第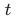 帧,将其相邻帧
帧,将其相邻帧 、
、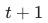 以及前后两个最近的PQF帧进行特征聚合。对于进行特征聚合的每一帧,利用其光流辅助特征对齐与传播。最后,利用55个残差模块对特征进行重建。具体地,在结构上使用PixelShuffle[30]算子来恢复视频分辨率,利用全局残差[17]来降低模型的学习难度。
以及前后两个最近的PQF帧进行特征聚合。对于进行特征聚合的每一帧,利用其光流辅助特征对齐与传播。最后,利用55个残差模块对特征进行重建。具体地,在结构上使用PixelShuffle[30]算子来恢复视频分辨率,利用全局残差[17]来降低模型的学习难度。

图3 第一阶段网络结构
如前所述,重建模块包含55个残差模块,如此大规模的网络是比较难以训练的,因此,我们采用渐进式训练[14,28]策略训练第一阶段网络。具体地,分6次对模型进行训练,每次训练分别使用其前5、15、25、35、45和55个残差模块进行图像重建。用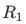 、
、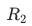 、...
、... 表示第1~5、6~15、... 46-55组残差模块,
表示第1~5、6~15、... 46-55组残差模块,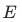 和
和 表示特征提取和特征传播模块,
表示特征提取和特征传播模块, 和
和 表示第一阶段网络最后的PixelShuffle层和全局残差连接。给定输入帧
表示第一阶段网络最后的PixelShuffle层和全局残差连接。给定输入帧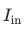 可通过如下渐进式训练过程得到最终的增强帧:
可通过如下渐进式训练过程得到最终的增强帧:
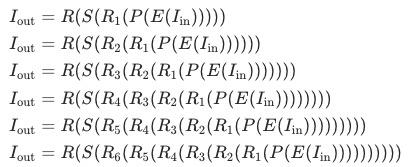
对于第一次训练,使用BasicVSR++开源模型初始化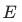 、
、 、
、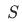 和
和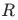 的权重,对于后续的第
的权重,对于后续的第 次训练,加载第
次训练,加载第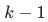 次训练收敛的模型
次训练收敛的模型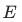 、
、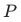 、
、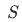 、
、 以及
以及 模块的权重进行初始化。需要注意的是,图3所示特征传播模块包含时序信息,为了简洁起见,在上述公式中省略了该信息。
模块的权重进行初始化。需要注意的是,图3所示特征传播模块包含时序信息,为了简洁起见,在上述公式中省略了该信息。
▐ 第二阶段网络与迁移学习
尽管BasicVSR++单模型拥有业界领先的视频恢复能力,但其对严重压缩伪影区域的恢复效果还有提升空间。为此,我们设计了第二阶段网络来进一步提升第一阶段网络增强后的视频帧,类似于参考文献[32]中的两阶段恢复策略。与[32]不同的是,实验证明,级连两个BasicVSR++模型带来的提升极其微小,为此,我们在第二阶段使用单帧增强模型,来进一步提高视频增强质量。
SwinIR[24]是当前业界最佳图像增强方案之一,我们使用该网络作为第二阶段模型,用于进一步增强第一阶段恢复后的视频帧。SwinIR网络结构基于Transformer,需要大规模数据进行训练,为此,我们采用迁移学习方法调优第二阶段网络。具体地,我们使用[24]开源的RGB去噪网络对第二阶段网络进行权重初始化,再使用视频增强数据集对其进一步调优。
实验
▐ 数据集
我们使用两个数据集来训练提出的两阶段网络,其一是NTIRE 2022挑战赛官方发布的LDV数据集[39]。它包含240个qHD序列,包含10类场景,分别为动物、城市、特写、时尚、人、室内、公园、风景、运动和车辆。此外,我们构建了一套包含870段视频的大规模数据集,包含LDV数据集中的10个场景,每个场景87段视频,均为YouTube网站下载的4K分辨率视频序列。我们参考NTIRE 2021报告[38]中描述的数据处理程序,将4K序列转换为qHD序列。并进一步去除压缩序列中的重复帧和原始序列中的对应帧。
为了验证模型性能,从上述十个场景中,每个场景选择一个序列来构建线下验证集。这10个序列分别为LDV数据集中的030、056、102、106、109、119、124、125、158和189。此方法最终使用的训练集为1100个视频,验证集为上述10个视频。
▐ 实施细节
对于第一阶段,首先加载开源BasicVSR++模型,并使用Charbonnier损失函数进行300K迭代次数微调。训练采用Adam优化器,初始学习率为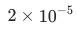 ,学习率调度策略为带warmup的余弦退火,退火周期为300K次迭代,在前10%次迭代中,学习率线性增加。此外,利用渐进式训练,将图像重建部分的残差模块从5个增加到55个,逐步使模型达到收敛。最后使用均方误差(Mean Squared Error, MSE)损失函数对模型进行100K次迭代微调。
,学习率调度策略为带warmup的余弦退火,退火周期为300K次迭代,在前10%次迭代中,学习率线性增加。此外,利用渐进式训练,将图像重建部分的残差模块从5个增加到55个,逐步使模型达到收敛。最后使用均方误差(Mean Squared Error, MSE)损失函数对模型进行100K次迭代微调。
对于第二阶段,首先加载开源图像去噪任务SwinIR模型,并使用Charbonnier损失函数进行微调。然后在自建数据集和LDV训练数据集上,使用均方损失函数对模型进行进一步微调,初始学习率为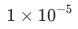 。值得注意的是,第二阶段为单帧模型,训练数据并非全部视频帧,我们对每个视频进行8取1抽样作为训练集。
。值得注意的是,第二阶段为单帧模型,训练数据并非全部视频帧,我们对每个视频进行8取1抽样作为训练集。
所有实验均在英伟达4卡V100上进行训练。
▐ 客观表现
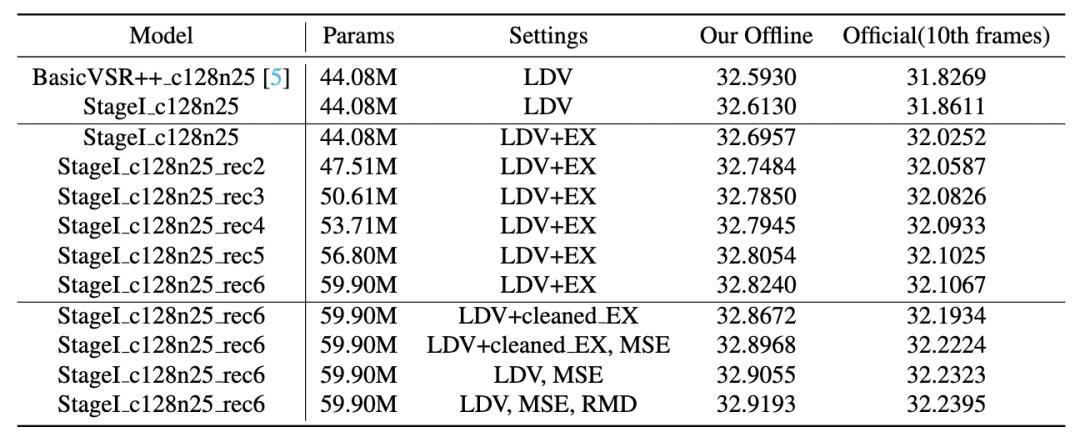
表5 第一阶段模型在Track 1赛道PSNR 表现
表现
其中,LDV表示230个官方训练集,EX表示870个YouTube采集训练集,cleaned_EX表示清洗后的YouTube采集训练集,MSE指均方误差损失函数,RMD指删除重复帧预测策略。
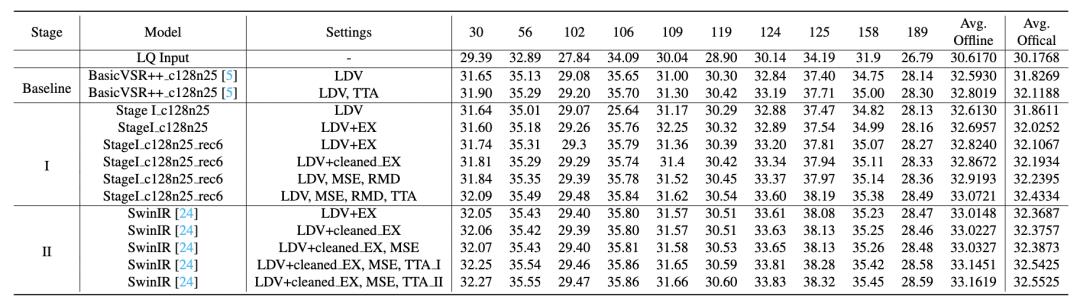
表6 两阶段网络在Track 1赛道线下10个验证集视频对PSNR 表现
表现
其中,TTA表示测试时集成方法,TTA_I和TTA_II分别指在第一阶段和第二阶段进行测试时集成。
峰值信噪比(Peak Signal-to-Noise Ratio, PSNR)可用于量化视频增强性能。本节展示提出方法在Track 1赛道两个数据集上的性能:一是我们自选的10个视频序列线下验证集,二是官方提供的15个视频序列线上验证集。
如表3所示,第一阶段整体取得了0.326dB的PSNR增益。特别地,额外数据训练提高了0.083dB PSNR值,对该数据进行清洗可进一步提升0.043dB。渐进式训练方法将PSRN提高了0.128dB,同时增加了15.82M模型参数量。使用均方误差损失函数微调和删除重复帧预测分别带来0.028dB和0.014dB的PSNR收益。
表4展示了两个模型在线下验证集上每个视频的PSNR值,第二阶段将单模型PSNR提升了0.11dB,进行测试时集成(Test Time Asemble, TTA)后,PSNR提升了0.13dB,并在最终的线下测试集上达到了33.16dB的成绩,与基线方法BasicVSR++相比,整体提升了0.36dB。说明第二阶段可以提升视频恢复性能,也验证了两阶段方法在视频恢复任务中的有效性。
▐ 主观表现
图1展示了我们方法在NTIRE 2022挑战赛官方测试集上的增强效果,图4展示了我们方法在自选线下验证集上的增强效果。从图中可以看出,我们的方法可以对压缩视频中对模糊区域恢复出丰富的细节,此外能够减少压缩视频中的运动模糊,同时提高物体边缘的清晰度。

图4 线下验证集主观效果
▐ 消融实验
表7展示了第二阶段网络迁移学习的消融实验结果。相比从头开始训练的方法,使用迁移学习后,第二阶段网络的PSNR提升了0.04dB,说明将图像去噪知识迁移到压缩视频增强任务中可以取得较好的效果。此外采用迁移学习可以有效缩短训练时间,从66小时减少到29小时,验证了迁移学习训练的优势。

表7 第二阶段迁移学习消融实验
NTIRE22
我们提出方法在NTIRE 2022压缩视频超分辨率和质量增强挑战赛的三个赛道表现如表8所示。在三个赛道中,均使用了测试时集成方法[31,32],其中Track 3赛道还使用了模型融合方法。具体地,对于Track 1、2,对输入视频帧进行翻转和旋转,为每个样本生成8个增强副本,然后分别送入第一阶段和第二阶段网络,最终计算第二阶段网络的8种预测平均值。对于Track 3,除了Track 1、2中的8种增强手段外,还在第一阶段进行了模型集成,即对两个模型的16种预测计算平均值,并将该平均值用作第二阶段模型的输入。
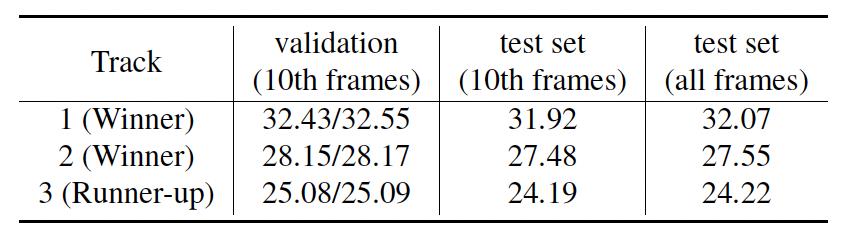
表8 我们的方法在NTIRE 2022挑战赛中的PSNR 表现
表现
结论
我们提出了一个两阶段视频增强框架,用于同时去除压缩伪影和缓解视频帧间质量波动,引入了渐进式训练和迁移学习策略,用以稳定训练过程、缩短训练时间,并最终提高视频增强性能,在增强性能和模型复杂度之间取得了良好的平衡,并在NTIRE2022视频超分与压缩伪影增强挑战赛中获得了两项冠军和一项亚军。
团队介绍
代表阿里巴巴参加本届NTIRE比赛夺魁的参赛团队,出自大淘宝技术内容团队,负责音视频算法和相关基础技术。
团队同时支持大淘宝内容业务,致力于打造业界领先的音视频体验,尤其是视频画质和流畅度,通过视频编码器S265、视频增强方案STaoVideo,以及媒体处理系统TMPS,为直播和短视频提供核心技术。相关算法技术目前服务于包括直播、逛逛、点淘、首猜等大淘宝业务并可被集团其它业务复用。通过持续的技术打磨和算法创新力求高质量、低成本赋能淘宝内容业务。团队在视频增强STaoVideo方面引入差异化的智美高清和普惠高清算子,分别针对高热视频和大盘视频提升画质并降低转码过程中的算力成本开销。团队既关注人眼主观体验,同时积极探索能够提升客观指标的方法。此次比赛的冠军方案:渐进式训练的两阶段视频恢复方法就是团队同学在日常业务研发中探索出的新方法。
团队负责人认为大淘宝内容业务足够复杂,包含多样化的真实场景,为算法同学提供了持续迭代技术,实时赋能业务,创造价值的舞台,团队亦可籍此沉淀技术领先性。依托当前技术储备,适当投入高水平的国际赛事,对团队来说是一个很好的练兵和面向业界前沿学习和交流的机会。
内容化正在驱动互联网进入新周期,音视频技术是其中重要的技术板块。此次在NTIRE取得出色成绩,是大淘系技术长期以来对音视频领域的持续投入和不断创新的阶段性成果。随着以淘宝直播、逛逛、点淘为代表的内容化业务的发展,内容场和电商场的双重复杂度不断叠加,未来不仅是音视频技术,大淘系技术在多模态、3D XR、认知计算与知识图谱等技术领域的迭代长期都会处在加速状态。
参考文献
[1] Anurag Arnab, Mostafa Dehghani, Georg Heigold, ChenSun, Mario LuˇciÅLc, and Cordelia Schmid. Vivit: A video vision transformer. In International Conference on Computer Vision (ICCV), 2021. 3
[2] Jiezhang Cao, Yawei Li, Kai Zhang, and Luc Van Gool. Video super-resolution transformer. arXiv, 2021. 2, 3
[3] Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to-end object detection with transformers. CoRR, abs/2005.12872, 2020. 3
[4] Kelvin C. K. Chan, Xintao Wang, Ke Yu, Chao Dong, and Chen Change Loy. Basicvsr: The search for essential components in video super-resolution and beyond. CoRR, abs/2012.02181, 2020. 2
[5] Kelvin C. K. Chan, Shangchen Zhou, Xiangyu Xu, and Chen Change Loy. Basicvsr++: Improving video superresolution with enhanced propagation and alignment. CoRR, abs/2104.13371, 2021. 2, 3, 5
[6] Hanting Chen, YunheWang, Tianyu Guo, Chang Xu, Yiping Deng, Zhenhua Liu, Siwei Ma, Chunjing Xu, Chao Xu, andWen Gao. Pre-trained image processing transformer, 2021.3
[7] Manri Cheon, Sung-Jun Yoon, Byungyeon Kang, and Junwoo Lee. Perceptual image quality assessment with transformers. CoRR, abs/2104.14730, 2021. 3
[8] Jifeng Dai, Haozhi Qi, Yuwen Xiong, Yi Li, Guodong Zhang, Han Hu, and Yichen Wei. Deformable convolutional networks. CoRR, abs/1703.06211, 2017. 2
[9] Jianing Deng, Li Wang, Shiliang Pu, and Cheng Zhuo. Spatio-temporal deformable convolution for compressed video quality enhancement. Proceedings of the AAAI Conference on Artificial Intelligence, 34(07):10696–10703, Apr. 2020. 2
[10] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: pre-training of deep bidirectional transformers for language understanding. CoRR, abs/1810.04805, 2018. 2
[11] Chao Dong, Yubin Deng, Chen Change Loy, and Xiaoou Tang. Compression artifacts reduction by a deep convolutional network. CoRR, abs/1504.06993, 2015. 2
[12] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. CoRR, abs/2010.11929, 2020. 3
[13] Dario Fuoli, Martin Danelljan, Radu Timofte, and Luc Van Gool. Fast online video super-resolution with deformable attention pyramid, 2022. 3
[14] Dario Fuoli, Zhiwu Huang, Martin Danelljan, Radu Timofte, Hua Wang, Longcun Jin, Dewei Su, Jing Liu, Jaehoon Lee, Michal Kudelski, Lukasz Bala, Dmitry Hrybov, Marcin Mozejko, Muchen Li, Siyao Li, Bo Pang, Cewu Lu, Chao Li, Dongliang He, Fu Li, and Shilei Wen. Ntire 2020 challenge on video quality mapping: Methods and results, 2020. 3
[15] Zhenyu Guan, Qunliang Xing, Mai Xu, Ren Yang, Tie Liu, and Zulin Wang. Mfqe 2.0: A new approach for multiframe quality enhancement on compressed video. IEEE transactions on pattern analysis and machine intelligence, 43(3):949–963, 2019. 2, 3
[16] Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr DollÅLar, and Ross B. Girshick. Masked autoencoders are scalable vision learners. CoRR, abs/2111.06377, 2021. 3
[17] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016. 3
[18] Takashi Isobe, Xu Jia, Shuhang Gu, Songjiang Li, Shengjin Wang, and Qi Tian. Video super-resolution with recurrent structure-detail network. CoRR, abs/2008.00455, 2020. 2
[19] Lielin Jiang, NaWang, Qingqing Dang, Rui Liu, and Baohua Lai. PP-MSVSR: multi-stage video super-resolution. CoRR, abs/2112.02828, 2021. 2
[20] Yifan Jiang, Shiyu Chang, and Zhangyang Wang. Transgan: Two pure transformers can make one strong gan, and that can scale up. Advances in Neural Information Processing
Systems, 34, 2021. 3
[21] Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, and Radu Soricut. ALBERT: A lite BERT for self-supervised learning of language representations.
CoRR, abs/1909.11942, 2019. 2
[22] Wenbo Li, Xin Tao, Taian Guo, Lu Qi, Jiangbo Lu, and Jiaya Jia. Mucan: Multi-correspondence aggregation network for video super-resolution. CoRR, abs/2007.11803, 2020. 2
[23] Jingyun Liang, Jiezhang Cao, Yuchen Fan, Kai Zhang, Rakesh Ranjan, Yawei Li, Radu Timofte, and Luc Van Gool. Vrt: A video restoration transformer. arXiv preprint arXiv:2201.12288, 2022. 2, 3
[24] Jingyun Liang, Jiezhang Cao, Guolei Sun, Kai Zhang, Luc Van Gool, and Radu Timofte. Swinir: Image restoration using swin transformer. In IEEE International Conference on Computer Vision Workshops, 2021. 2, 3, 4, 5
[25] Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. Roberta: A robustly optimized BERT pretraining approach. CoRR, abs/1907.11692, 2019. 2
[26] Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. CoRR, abs/2103.14030, 2021. 3
[27] Seungjun Nah, Sungyong Baik, Seokil Hong, Gyeongsik Moon, Sanghyun Son, Radu Timofte, and Kyoung Mu Lee. Ntire 2019 challenge on video deblurring and superresolution: Dataset and study. In CVPR Workshops, June 2019. 2
[28] Yali Peng, Yue Cao, Shigang Liu, Jian Yang, andWangmeng Zuo. Progressive training of multi-level wavelet residual networks for image denoising, 2020. 3
[29] Anurag Ranjan and Michael J Black. Optical flow estimation using a spatial pyramid network. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 4161–4170, 2017. 3
[30] Wenzhe Shi, Jose Caballero, Ferenc HuszÅLar, Johannes Totz, Andrew P Aitken, Rob Bishop, Daniel Rueckert, and Zehan Wang. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1874–1883, 2016. 3
[31] Radu Timofte, Rasmus Rothe, and Luc Van Gool. Seven ways to improve example-based single image super resolution. CoRR, abs/1511.02228, 2015. 7
[32] Xintao Wang, Kelvin C. K. Chan, Ke Yu, Chao Dong, and Chen Change Loy. EDVR: video restoration with enhanced deformable convolutional networks. CoRR, abs/1905.02716, 2019. 2, 4, 7
[33] Zhendong Wang, Xiaodong Cun, Jianmin Bao, and Jianzhuang Liu. Uformer: A general u-shaped transformer for image restoration. CoRR, abs/2106.03106, 2021. 3
[34] Zhuofan Xia, Xuran Pan, Shiji Song, Li Erran Li, and Gao Huang. Vision transformer with deformable attention, 2022. 3
[35] Qunliang Xing, Mai Xu, Tianyi Li, and Zhenyu Guan. Early exit or not: Resource-efficient blind quality enhancement for compressed images. In European Conference on Computer
Vision, pages 275–292. Springer, 2020. 2
[36] Tianfan Xue, Baian Chen, Jiajun Wu, Donglai Wei, and William T. Freeman. Video enhancement with task-oriented flow. CoRR, abs/1711.09078, 2017. 2
[37] Fuzhi Yang, Huan Yang, Jianlong Fu, Hongtao Lu, and Baining Guo. Learning texture transformer network for image super-resolution. In CVPR, June 2020. 3
[38] Ren Yang. Ntire 2021 challenge on quality enhancement of compressed video: Dataset and study. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 667–676, 2021. 4
[39] Ren Yang and Radu Timofte. Ntire 2021 challenge on quality enhancement of compressed video: Dataset and study, 2021. 4
[40] Ren Yang, Radu Timofte, et al. NTIRE 2022 challenge on super-resolution and quality enhancement of compressed video: Dataset, methods and results. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, 2022. 2
[41] Ren Yang, Mai Xu, and Zulin Wang. Decoder-side hevc quality enhancement with scalable convolutional neural network. In 2017 IEEE International Conference on Multimedia and Expo (ICME), pages 817–822, 2017. 2
[42] Ren Yang, Mai Xu, Zulin Wang, and Tianyi Li. Multi-frame quality enhancement for compressed video. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6664–6673, 2018. 2, 3
[43] Xinyi Ying, Longguang Wang, Yingqian Wang, Weidong Sheng, Wei An, and Yulan Guo. Deformable 3d convolution for video super-resolution. IEEE Signal Processing Letters, 27:1500–1504, 2020. 2
[44] Yuhui Yuan, Rao Fu, Lang Huang, Weihong Lin, Chao Zhang, Xilin Chen, and Jingdong Wang. Hrformer:
High-resolution transformer for dense prediction. CoRR, abs/2110.09408, 2021. 3
[45] Syed Waqas Zamir, Aditya Arora, Salman H. Khan, Munawar Hayat, Fahad Shahbaz Khan, and Ming-Hsuan Yang. Restormer: Efficient transformer for high-resolution image restoration. CoRR, abs/2111.09881, 2021. 3
[46] Xizhou Zhu, Han Hu, Stephen Lin, and Jifeng Dai. Deformable convnets v2: More deformable, better results. CoRR, abs/1811.11168, 2018. 2
✿ 拓展阅读


作者|涵璋
编辑|橙子君
出品|阿里巴巴新零售淘系技术


以上是关于大淘宝技术斩获NTIRE视频增强和超分比赛冠军(内含夺冠方案)的主要内容,如果未能解决你的问题,请参考以下文章