Hive开窗函数总结
Posted YaoYong_BigData
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hive开窗函数总结相关的知识,希望对你有一定的参考价值。
一、介绍
分析函数用于计算基于组的某种聚合值,它和聚合函数的不同之处是:对于每个组返回多行,而聚合函数对于每个组只返回一行。
开窗函数指定了分析函数工作的数据窗口大小,这个数据窗口大小可能会随着行的变化而变化!到底什么是数据窗口?后面举例会详细讲到!
Window Function又称为窗口函数、分析函数。
窗口函数与聚合函数类似,但是每一行数据都生成一个结果。
聚合函数(比如sum、avg、max等)可以将多行数据按照规定聚合为一行,一般来讲聚集后的行数要少于聚集前的行数。但是有时我们想要既显示聚集前的数据,又要显示聚集后的数据,这时便引入了窗口函数。
窗口函数是在select时执行的,位于order by之前。
1. 基础结构:
分析函数(如:sum(),max(),row_number()...) + 窗口子句(over函数)
2. over函数写法:
over(partition by cookieid order by createtime) 先根据cookieid字段分区,相同的cookieid分为一区,每个分区内根据createtime字段排序(默认升序)
注:不加 partition by 的话则把整个数据集当作一个分区,不加 order by的话会对某些函数统计结果产生影响,如sum()。
二、测试数据
-- 建表
create table student_scores(
id int,
studentId int,
language int,
math int,
english int,
classId string,
departmentId string
);
-- 写入数据
insert into table student_scores values
(1,111,68,69,90,'class1','department1'),
(2,112,73,80,96,'class1','department1'),
(3,113,90,74,75,'class1','department1'),
(4,114,89,94,93,'class1','department1'),
(5,115,99,93,89,'class1','department1'),
(6,121,96,74,79,'class2','department1'),
(7,122,89,86,85,'class2','department1'),
(8,123,70,78,61,'class2','department1'),
(9,124,76,70,76,'class2','department1'),
(10,211,89,93,60,'class1','department2'),
(11,212,76,83,75,'class1','department2'),
(12,213,71,94,90,'class1','department2'),
(13,214,94,94,66,'class1','department2'),
(14,215,84,82,73,'class1','department2'),
(15,216,85,74,93,'class1','department2'),
(16,221,77,99,61,'class2','department2'),
(17,222,80,78,96,'class2','department2'),
(18,223,79,74,96,'class2','department2'),
(19,224,75,80,78,'class2','department2'),
(20,225,82,85,63,'class2','department2');三、聚合开窗函数
count开窗函数
-- count 开窗函数
select studentId,math,departmentId,classId,
-- 以符合条件的所有行作为窗口
count(math) over() as count1,
-- 以按classId分组的所有行作为窗口
count(math) over(partition by classId) as count2,
-- 以按classId分组、按math排序的所有行作为窗口
count(math) over(partition by classId order by math) as count3,
-- 以按classId分组、按math排序、按 当前行+往前1行+往后2行的行作为窗口
count(math) over(partition by classId order by math rows between 1 preceding and 2 following) as count4
from student_scores where departmentId='department1';
结果
studentid math departmentid classid count1 count2 count3 count4
111 69 department1 class1 9 5 1 3
113 74 department1 class1 9 5 2 4
112 80 department1 class1 9 5 3 4
115 93 department1 class1 9 5 4 3
114 94 department1 class1 9 5 5 2
124 70 department1 class2 9 4 1 3
121 74 department1 class2 9 4 2 4
123 78 department1 class2 9 4 3 3
122 86 department1 class2 9 4 4 2
结果解释:
studentid=115,count1为所有的行数9,count2为分区class1中的行数5,count3为分区class1中math值<=93的行数4,
count4为分区class1中math值向前+1行向后+2行(实际只有1行)的总行数3。sum开窗函数
-- sum开窗函数
select studentId,math,departmentId,classId,
-- 以符合条件的所有行作为窗口
sum(math) over() as sum1,
-- 以按classId分组的所有行作为窗口
sum(math) over(partition by classId) as sum2,
-- 以按classId分组、按math排序后、按到当前行(含当前行)的所有行作为窗口
sum(math) over(partition by classId order by math) as sum3,
-- 以按classId分组、按math排序后、按当前行+往前1行+往后2行的行作为窗口
sum(math) over(partition by classId order by math rows between 1 preceding and 2 following) as sum4
from student_scores where departmentId='department1';
结果
studentid math departmentid classid sum1 sum2 sum3 sum4
111 69 department1 class1 718 410 69 223
113 74 department1 class1 718 410 143 316
112 80 department1 class1 718 410 223 341
115 93 department1 class1 718 410 316 267
114 94 department1 class1 718 410 410 187
124 70 department1 class2 718 308 70 222
121 74 department1 class2 718 308 144 308
123 78 department1 class2 718 308 222 238
122 86 department1 class2 718 308 308 164
结果解释:
窗口函数和聚合函数的不同,sum()函数可以根据每一行的窗口返回各自行对应的值,有多少行记录就有多少个sum值,而group by只能计算每一组的sum,每组只有一个值!
其中sum3计算的是分区内排序后一个个叠加的值,和order by有关!
可以看到,如果没有order by,sum2计算的math是整个分区的math。min开窗函数
-- min 开窗函数
select studentId,math,departmentId,classId,
-- 以符合条件的所有行作为窗口
min(math) over() as min1,
-- 以按classId分组的所有行作为窗口
min(math) over(partition by classId) as min2,
-- 以按classId分组、按math排序后、按到当前行(含当前行)的所有行作为窗口
min(math) over(partition by classId order by math) as min3,
-- 以按classId分组、按math排序后、按当前行+往前1行+往后2行的行作为窗口
min(math) over(partition by classId order by math rows between 1 preceding and 2 following) as min4
from student_scores where departmentId='department1';
结果
studentid math departmentid classid min1 min2 min3 min4
111 69 department1 class1 69 69 69 69
113 74 department1 class1 69 69 69 69
112 80 department1 class1 69 69 69 74
115 93 department1 class1 69 69 69 80
114 94 department1 class1 69 69 69 93
124 70 department1 class2 69 70 70 70
121 74 department1 class2 69 70 70 70
123 78 department1 class2 69 70 70 74
122 86 department1 class2 69 70 70 78
结果解释:
同count开窗函数max开窗函数
-- max 开窗函数
select studentId,math,departmentId,classId,
-- 以符合条件的所有行作为窗口
max(math) over() as max1,
-- 以按classId分组的所有行作为窗口
max(math) over(partition by classId) as max2,
-- 以按classId分组、按math排序后、按到当前行(含当前行)的所有行作为窗口
max(math) over(partition by classId order by math) as max3,
-- 以按classId分组、按math排序后、按当前行+往前1行+往后2行的行作为窗口
max(math) over(partition by classId order by math rows between 1 preceding and 2 following) as max4
from student_scores where departmentId='department1';
结果
studentid math departmentid classid max1 max2 max3 max4
111 69 department1 class1 94 94 69 80
113 74 department1 class1 94 94 74 93
112 80 department1 class1 94 94 80 94
115 93 department1 class1 94 94 93 94
114 94 department1 class1 94 94 94 94
124 70 department1 class2 94 86 70 78
121 74 department1 class2 94 86 74 86
123 78 department1 class2 94 86 78 86
122 86 department1 class2 94 86 86 86
结果解释:
同count开窗函数avg开窗函数
-- avg 开窗函数
select studentId,math,departmentId,classId,
-- 以符合条件的所有行作为窗口
avg(math) over() as avg1,
-- 以按classId分组的所有行作为窗口
avg(math) over(partition by classId) as avg2,
-- 以按classId分组、按math排序后、按到当前行(含当前行)的所有行作为窗口
avg(math) over(partition by classId order by math) as avg3,
-- 以按classId分组、按math排序后、按当前行+往前1行+往后2行的行作为窗口
avg(math) over(partition by classId order by math rows between 1 preceding and 2 following) as avg4
from student_scores where departmentId='department1';
结果
studentid math departmentid classid avg1 avg2 avg3 avg4
111 69 department1 class1 79.77777777777777 82.0 69.0 74.33333333333333
113 74 department1 class1 79.77777777777777 82.0 71.5 79.0
112 80 department1 class1 79.77777777777777 82.0 74.33333333333333 85.25
115 93 department1 class1 79.77777777777777 82.0 79.0 89.0
114 94 department1 class1 79.77777777777777 82.0 82.0 93.5
124 70 department1 class2 79.77777777777777 77.0 70.0 74.0
121 74 department1 class2 79.77777777777777 77.0 72.0 77.0
123 78 department1 class2 79.77777777777777 77.0 74.0 79.33333333333333
122 86 department1 class2 79.77777777777777 77.0 77.0 82.0
结果解释:
同count开窗函数first_value开窗函数
-- first_value 开窗函数:返回分区中的第一个值。
select studentId,math,departmentId,classId,
-- 以符合条件的所有行作为窗口
first_value(math) over() as first_value1,
-- 以按classId分组的所有行作为窗口
first_value(math) over(partition by classId) as first_value2,
-- 以按classId分组、按math排序后、按到当前行(含当前行)的所有行作为窗口
first_value(math) over(partition by classId order by math) as first_value3,
-- 以按classId分组、按math排序后、按当前行+往前1行+往后2行的行作为窗口
first_value(math) over(partition by classId order by math rows between 1 preceding and 2 following) as first_value4
from student_scores where departmentId='department1';
结果
studentid math departmentid classid first_value1 first_value2 first_value3 first_value4
111 69 department1 class1 69 69 69 69
113 74 department1 class1 69 69 69 69
112 80 department1 class1 69 69 69 74
115 93 department1 class1 69 69 69 80
114 94 department1 class1 69 69 69 93
124 70 department1 class2 69 74 70 70
121 74 department1 class2 69 74 70 70
123 78 department1 class2 69 74 70 74
122 86 department1 class2 69 74 70 78
结果解释:
studentid=124 first_value1:第一个值是69,first_value2:classId=class1分区 math的第一个值是69。last_value开窗函数
-- last_value 开窗函数:返回分区中的最后一个值。
select studentId,math,departmentId,classId,
-- 以符合条件的所有行作为窗口
last_value(math) over() as last_value1,
-- 以按classId分组的所有行作为窗口
last_value(math) over(partition by classId) as last_value2,
-- 以按classId分组、按math排序后、按到当前行(含当前行)的所有行作为窗口
last_value(math) over(partition by classId order by math) as last_value3,
-- 以按classId分组、按math排序后、按当前行+往前1行+往后2行的行作为窗口
last_value(math) over(partition by classId order by math rows between 1 preceding and 2 following) as last_value4
from student_scores where departmentId='department1';
结果
studentid math departmentid classid last_value1 last_value2 last_value3 last_value4
111 69 department1 class1 70 93 69 80
113 74 department1 class1 70 93 74 93
112 80 department1 class1 70 93 80 94
115 93 department1 class1 70 93 93 94
114 94 department1 class1 70 93 94 94
124 70 department1 class2 70 70 70 78
121 74 department1 class2 70 70 74 86
123 78 department1 class2 70 70 78 86
122 86 department1 class2 70 70 86 86lag开窗函数
lag(col,n,default) 用于统计窗口内往上第n个值。
col:列名
n:往上第n行
default:往上第n行为NULL时候,取默认值,不指定则取NULL
-- lag 开窗函数
select studentId,math,departmentId,classId,
--窗口内 往上取第二个 取不到时赋默认值60
lag(math,2,60) over(partition by classId order by math) as lag1,
--窗口内 往上取第二个 取不到时赋默认值NULL
lag(math,2) over(partition by classId order by math) as lag2
from student_scores where departmentId='department1';
结果
studentid math departmentid classid lag1 lag2
111 69 department1 class1 60 NULL
113 74 department1 class1 60 NULL
112 80 department1 class1 69 69
115 93 department1 class1 74 74
114 94 department1 class1 80 80
124 70 department1 class2 60 NULL
121 74 department1 class2 60 NULL
123 78 department1 class2 70 70
122 86 department1 class2 74 74
结果解释:
第3行 lag1:窗口内(69 74 80) 当前行80 向上取第二个值为69
倒数第3行 lag2:窗口内(70 74) 当前行74 向上取第二个值为NULLlead开窗函数
lead(col,n,default) 用于统计窗口内往下第n个值。
col:列名
n:往下第n行
default:往下第n行为NULL时候,取默认值,不指定则取NULL
-- lead开窗函数
select studentId,math,departmentId,classId,
--窗口内 往下取第二个 取不到时赋默认值60
lead(math,2,60) over(partition by classId order by math) as lead1,
--窗口内 往下取第二个 取不到时赋默认值NULL
lead(math,2) over(partition by classId order by math) as lead2
from student_scores where departmentId='department1';
结果
studentid math departmentid classid lead1 lead2
111 69 department1 class1 80 80
113 74 department1 class1 93 93
112 80 department1 class1 94 94
115 93 department1 class1 60 NULL
114 94 department1 class1 60 NULL
124 70 department1 class2 78 78
121 74 department1 class2 86 86
123 78 department1 class2 60 NULL
122 86 department1 class2 60 NULL
结果解释:
第4行lead1 窗口内向下第二个值为空,赋值60cume_dist开窗函数
计算某个窗口或分区中某个值的累积分布。假定升序排序,则使用以下公式确定累积分布:
小于等于当前值x的行数 / 窗口或partition分区内的总行数。其中,x 等于 order by 子句中指定的列的当前行中的值。
-- cume_dist 开窗函数
select studentId,math,departmentId,classId,
-- 统计小于等于当前分数的人数占总人数的比例
cume_dist() over(order by math) as cume_dist1,
-- 统计大于等于当前分数的人数占总人数的比例
cume_dist() over(order by math desc) as cume_dist2,
-- 统计分区内小于等于当前分数的人数占总人数的比例
cume_dist() over(partition by classId order by math) as cume_dist3
from student_scores where departmentId='department1';
结果
studentid math departmentid classid cume_dist1 cume_dist2 cume_dist3
111 69 department1 class1 0.1111111111111111 1.0 0.2
113 74 department1 class1 0.4444444444444444 0.7777777777777778 0.4
112 80 department1 class1 0.6666666666666666 0.4444444444444444 0.6
115 93 department1 class1 0.8888888888888888 0.2222222222222222 0.8
114 94 department1 class1 1.0 0.1111111111111111 1.0
124 70 department1 class2 0.2222222222222222 0.8888888888888888 0.25
121 74 department1 class2 0.4444444444444444 0.7777777777777778 0.5
123 78 department1 class2 0.5555555555555556 0.5555555555555556 0.75
122 86 department1 class2 0.7777777777777778 0.3333333333333333 1.0
结果解释:
第三行:
cume_dist1=小于等于80的人数为6/总人数9=0.6666666666666666
cume_dist2=大于等于80的人数为4/总人数9=0.4444444444444444
cume_dist3=分区内小于等于80的人数为3/分区内总人数5=0.6
四、排序开窗函数
rank开窗函数
rank 开窗函数基于 over 子句中的 order by 确定一组值中一个值的排名。如果存在partition by ,则为每个分区组中的每个值排名。排名可能不是连续的。例如,如果两个行的排名为 1,则下一个排名为 3。
-- rank 开窗函数
select *,
-- 对全部学生按数学分数排序
rank() over(order by math) as rank1,
-- 对院系 按数学分数排序
rank() over(partition by departmentId order by math) as rank2,
-- 对每个院系每个班级 按数学分数排序
rank() over(partition by departmentId,classId order by math) as rank3
from student_scores;
结果
id studentid language math english classid departmentid rank1 rank2 rank3
1 111 68 69 90 class1 department1 1 1 1
3 113 90 74 75 class1 department1 3 3 2
2 112 73 80 96 class1 department1 9 6 3
5 115 99 93 89 class1 department1 15 8 4
4 114 89 94 93 class1 department1 17 9 5
9 124 76 70 76 class2 department1 2 2 1
6 121 96 74 79 class2 department1 3 3 2
8 123 70 78 61 class2 department1 7 5 3
7 122 89 86 85 class2 department1 14 7 4
15 216 85 74 93 class1 department2 3 1 1
14 215 84 82 73 class1 department2 11 5 2
11 212 76 83 75 class1 department2 12 6 3
10 211 89 93 60 class1 department2 15 8 4
12 213 71 94 90 class1 department2 17 9 5
13 214 94 94 66 class1 department2 17 9 5
18 223 79 74 96 class2 department2 3 1 1
17 222 80 78 96 class2 department2 7 3 2
19 224 75 80 78 class2 department2 9 4 3
20 225 82 85 63 class2 department2 13 7 4
16 221 77 99 61 class2 department2 20 11 5dense_rank开窗函数
dense_rank与rank有一点不同,当排名一样的时候,接下来的行是连续的。如两个行的排名为 1,则下一个排名为 2。
-- dense_rank 开窗函数
select *,
-- 对全部学生按数学分数排序
dense_rank() over(order by math) as dense_rank1,
-- 对院系 按数学分数排序
dense_rank() over(partition by departmentId order by math) as dense_rank2,
-- 对每个院系每个班级 按数学分数排序
dense_rank() over(partition by departmentId,classId order by math) as dense_rank3
from student_scores;
结果:
id studentid language math english classid departmentid dense_rank1 dense_rank2 dense_rank3
1 111 68 69 90 class1 department1 1 1 1
3 113 90 74 75 class1 department1 3 3 2
2 112 73 80 96 class1 department1 5 5 3
5 115 99 93 89 class1 department1 10 7 4
4 114 89 94 93 class1 department1 11 8 5
9 124 76 70 76 class2 department1 2 2 1
6 121 96 74 79 class2 department1 3 3 2
8 123 70 78 61 class2 department1 4 4 3
7 122 89 86 85 class2 department1 9 6 4
15 216 85 74 93 class1 department2 3 1 1
14 215 84 82 73 class1 department2 6 4 2
11 212 76 83 75 class1 department2 7 5 3
10 211 89 93 60 class1 department2 10 7 4
12 213 71 94 90 class1 department2 11 8 5
13 214 94 94 66 class1 department2 11 8 5
18 223 79 74 96 class2 department2 3 1 1
17 222 80 78 96 class2 department2 4 2 2
19 224 75 80 78 class2 department2 5 3 3
20 225 82 85 63 class2 department2 8 6 4
16 221 77 99 61 class2 department2 12 9 5ntile开窗函数
将分区中已排序的行划分为大小尽可能相等的指定数量的排名的组,并返回给定行所在的组的排名。
NTILE(n),用于将分组数据按照顺序切分成n片,返回当前切片值。
注1:如果切片不均匀,默认增加第一个切片的分布;
注2:NTILE不支持ROWS BETWEEN。
-- ntile 开窗函数
select *,
-- 对分区内的数据分成两组
ntile(2) over(partition by departmentid order by math) as ntile1,
-- 对分区内的数据分成三组
ntile(3) over(partition by departmentid order by math) as ntile2
from student_scores;
结果
id studentid language math english classid departmentid ntile1 ntile2
1 111 68 69 90 class1 department1 1 1
9 124 76 70 76 class2 department1 1 1
6 121 96 74 79 class2 department1 1 1
3 113 90 74 75 class1 department1 1 2
8 123 70 78 61 class2 department1 1 2
2 112 73 80 96 class1 department1 2 2
7 122 89 86 85 class2 department1 2 3
5 115 99 93 89 class1 department1 2 3
4 114 89 94 93 class1 department1 2 3
18 223 79 74 96 class2 department2 1 1
15 216 85 74 93 class1 department2 1 1
17 222 80 78 96 class2 department2 1 1
19 224 75 80 78 class2 department2 1 1
14 215 84 82 73 class1 department2 1 2
11 212 76 83 75 class1 department2 1 2
20 225 82 85 63 class2 department2 2 2
10 211 89 93 60 class1 department2 2 2
12 213 71 94 90 class1 department2 2 3
13 214 94 94 66 class1 department2 2 3
16 221 77 99 61 class2 department2 2 3
结果解释:
第8行
ntile1:对分区的数据均匀分成2组后,当前行的组排名为2
ntile2:对分区的数据均匀分成3组后,当前行的组排名为3row_number开窗函数
-- row_number 开窗函数
select studentid,departmentid,classid,math,
-- 对分区departmentid,classid内的数据按math排序
row_number() over(partition by departmentid,classid order by math) as row_number
from student_scores;
结果
studentid departmentid classid math row_number
111 department1 class1 69 1
113 department1 class1 74 2
112 department1 class1 80 3
115 department1 class1 93 4
114 department1 class1 94 5
124 department1 class2 70 1
121 department1 class2 74 2
123 department1 class2 78 3
122 department1 class2 86 4
216 department2 class1 74 1
215 department2 class1 82 2
212 department2 class1 83 3
211 department2 class1 93 4
213 department2 class1 94 5
214 department2 class1 94 6
223 department2 class2 74 1
222 department2 class2 78 2
224 department2 class2 80 3
225 department2 class2 85 4
221 department2 class2 99 5
结果解释:
同一分区,相同值,不同序。如studentid=213 studentid=214 值都为94 排序为5,6。percent_rank开窗函数
计算给定行的百分比排名。可以用来计算超过了百分之多少的人。
(当前行的rank值-1)/(分组内的总行数-1)
-- percent_rank 开窗函数
select studentid,departmentid,classid,math,
row_number() over(partition by departmentid,classid order by math) as row_number,
percent_rank() over(partition by departmentid,classid order by math) as percent_rank
from student_scores;
结果
studentid departmentid classid math row_number percent_rank
111 department1 class1 69 1 0.0
113 department1 class1 74 2 0.25
112 department1 class1 80 3 0.5
115 department1 class1 93 4 0.75
114 department1 class1 94 5 1.0
124 department1 class2 70 1 0.0
121 department1 class2 74 2 0.3333333333333333
123 department1 class2 78 3 0.6666666666666666
122 department1 class2 86 4 1.0
216 department2 class1 74 1 0.0
215 department2 class1 82 2 0.2
212 department2 class1 83 3 0.4
211 department2 class1 93 4 0.6
213 department2 class1 94 5 0.8
214 department2 class1 94 6 0.8
223 department2 class2 74 1 0.0
222 department2 class2 78 2 0.25
224 department2 class2 80 3 0.5
225 department2 class2 85 4 0.75
221 department2 class2 99 5 1.0
结果解释:
studentid=115,percent_rank=(4-1)/(5-1)=0.75
studentid=123,percent_rank=(3-1)/(4-1)=0.6666666666666666
五、窗口函数 GROUPING SETS,CUBE,ROLLUP
这几个分析函数通常用于OLAP中。
数据准备 :
2018-03,2018-03-10,cookie1
2018-03,2018-03-10,cookie5
2018-03,2018-03-12,cookie7
2018-04,2018-04-12,cookie3
2018-04,2018-04-13,cookie2
2018-04,2018-04-13,cookie4
2018-04,2018-04-16,cookie4
2018-03,2018-03-10,cookie2
2018-03,2018-03-10,cookie3
2018-04,2018-04-12,cookie5
2018-04,2018-04-13,cookie6
2018-04,2018-04-15,cookie3
2018-04,2018-04-15,cookie2
2018-04,2018-04-16,cookie1
CREATE TABLE t5 (
month STRING,
day STRING,
cookieid STRING
) ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
stored as textfile;
加载数据:
load data local inpath '/root/hivedata/t5.dat' into table t5;GROUPING SETS
grouping sets是一种将多个group by 逻辑写在一个sql语句中的便利写法。
等价于将不同维度的GROUP BY结果集进行UNION ALL。
GROUPING__ID,表示结果属于哪一个分组集合。
SELECT
month,
day,
COUNT(DISTINCT cookieid) AS uv,
GROUPING__ID
FROM t5
GROUP BY month,day
GROUPING SETS (month,day)
ORDER BY GROUPING__ID;
grouping_id表示这一组结果属于哪个分组集合,
根据grouping sets中的分组条件month,day,1是代表month,2是代表day
等价于
SELECT month,NULL,COUNT(DISTINCT cookieid) AS uv,1 AS GROUPING__ID FROM t5 GROUP BY month UNION ALL
SELECT NULL as month,day,COUNT(DISTINCT cookieid) AS uv,2 AS GROUPING__ID FROM t5 GROUP BY day;输出结果:
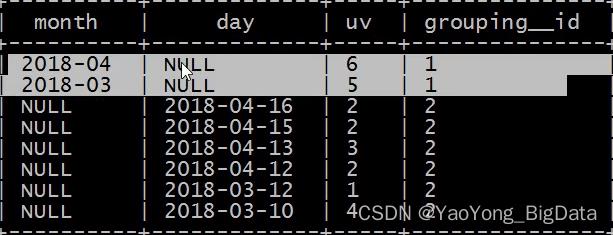
再如:
SELECT
month,
day,
COUNT(DISTINCT cookieid) AS uv,
GROUPING__ID
FROM t5
GROUP BY month,day
GROUPING SETS (month,day,(month,day))
ORDER BY GROUPING__ID;
等价于
SELECT month,NULL,COUNT(DISTINCT cookieid) AS uv,1 AS GROUPING__ID FROM t5 GROUP BY month
UNION ALL
SELECT NULL,day,COUNT(DISTINCT cookieid) AS uv,2 AS GROUPING__ID FROM t5 GROUP BY day
UNION ALL
SELECT month,day,COUNT(DISTINCT cookieid) AS uv,3 AS GROUPING__ID FROM t5 GROUP BY month,day;CUBE(立方体 数据立方体 多维数据分析)
举个栗子:某个事情有A、B、C三个维度,根据这三个维度进行组合分析,共有多少种情况?
这些情况加起来就是所谓多维分析中数据立方体。
没有维度:[]
一个维度:[A] [B] [C]
两个维度:[AB] [AC] [BC]
三个维度:[ABC]
共有8个结果。规律:假如有n个维度 所有的维度组合情况是2的n次方
根据GROUP BY的维度的所有组合进行聚合。
SELECT
month,
day,
COUNT(DISTINCT cookieid) AS uv,
GROUPING__ID
FROM t5
GROUP BY month,day
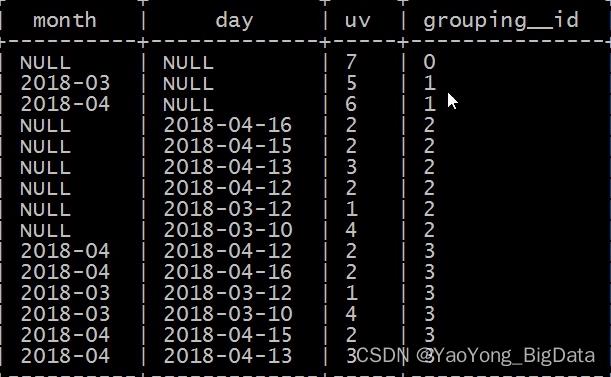
WITH CUBE
ORDER BY GROUPING__ID;
等价于
SELECT NULL,NULL,COUNT(DISTINCT cookieid) AS uv,0 AS GROUPING__ID FROM t5
UNION ALL
SELECT month,NULL,COUNT(DISTINCT cookieid) AS uv,1 AS GROUPING__ID FROM t5 GROUP BY month
UNION ALL
SELECT NULL,day,COUNT(DISTINCT cookieid) AS uv,2 AS GROUPING__ID FROM t5 GROUP BY day
UNION ALL
SELECT month,day,COUNT(DISTINCT cookieid) AS uv,3 AS GROUPING__ID FROM t5 GROUP BY month,day;输出结果:
ROLLUP
是CUBE的子集,以最左侧的维度为主,从该维度进行层级聚合。
比如,以month维度进行层级聚合:
SELECT
month,
day,
COUNT(DISTINCT cookieid) AS uv,
GROUPING__ID
FROM t5
GROUP BY month,day
WITH ROLLUP
ORDER BY GROUPING__ID;
输出结果:

--把month和day调换顺序,则以day维度进行层级聚合:
SELECT
day,
month,
COUNT(DISTINCT cookieid) AS uv,
GROUPING__ID
FROM t5
GROUP BY day,month
WITH ROLLUP
ORDER BY GROUPING__ID;
(这里,根据天和月进行聚合,和根据天聚合结果一样,因为有父子关系,如果是其他维度组合的话,就会不一样)
以上是关于Hive开窗函数总结的主要内容,如果未能解决你的问题,请参考以下文章