Hive开窗函数
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hive开窗函数相关的知识,希望对你有一定的参考价值。
参考技术A first_value:取分组内排序后,截止到当前行,第一个值;last_value:取分组内排序后,截止到当前行,最后一个值;
lead(col, n, default):用于统计窗口内往下第n行值。第一个参数为列名,第二个参数为往下第n行(可选,默认为1),第三个参数为默认值(当往下第n行为null时,取默认值,如不指定则为null);
lag(col, n, default):与lead相反,用于统计窗口内往上第n行值。第一个参数为列名,第二个参数为往上第n行(可选,默认为1),第三个参数为默认值(当往上第n行为null时,取默认值,如不指定,则为null)。
1)使用标准的聚合函数 count、sum、min、max、avg
2)使用 partition by 语句,使用一个或多个原始列
3)使用 partition by 与 order by 语句,使用一个或多个分区或者排序列
4)使用窗口规范,窗口规范支持以下格式:
当 ORDER BY 后面缺少窗口从句条件,窗口规范默认是 RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW .
当 ORDER BY 和窗口从句都缺失, 窗口规范默认是 ROW BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING .
OVER 从句支持以下函数, 但是并不支持和窗口一起使用它们。
Ranking 函数: Rank, NTile, DenseRank, CumeDist, PercentRank .
Lead 和 Lag 函数.
row_number() :从1开始,按照顺序生成组内记录的序列,比如按照pv降序排列生成分组内的pv排名;获取分组内的top1记录;获取一个session内的第一条记录等等。
rank() :生成数据项在分组内的排名,排名相等会在名次中留下空位。
dense_rank() :生成数据项在分组内的排名,排名相对不会在名次中留下空位。
cume_dist :小于等于当前值的行数/分组内总行数。比如,统计小于等于当前薪资的人数占总人数的比例。
percent_rank : (分组内当前行的rank值-1)/(分组内总行数-1)。
ntile(n) :用于将分组数据按照顺序切分成n片,返回当前切片值,如果切片不均匀,默认增加第一个切片的分布。 ntile 不支持 rows between ,比如 ntile(2) over(partition by cookieied order by createtime rows between 3 preceding and current row) 。
4、测试数据集
Hive——窗口函数(开窗函数)
创建好文件:
vim business.txt
数据准备:
jack,2017-01-01,10
tony,2017-01-02,15
jack,2017-02-03,23
tony,2017-01-04,29
jack,2017-01-05,46
jack,2017-04-06,42
tony,2017-01-07,50
jack,2017-01-08,55
mart,2017-04-08,62
mart,2017-04-09,68
neil,2017-05-10,12
mart,2017-04-11,75
neil,2017-06-12,80
mart,2017-04-13,94
创建新表:
create table business(
name string,
orderdate string,
cost int
) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
加载数据:
load data local inpath "/opt/module/data/business.txt" into table
business;
需求:查询在2017年4月份购买过的顾客及总人数。
先查询一下在2017年四月份购买过的人有哪些。
select
*
from
business
where substring(orderdate,0,7) = '2017-04';
select
name,
count(*) over()
from
business
where substring(orderdate,0,7) = '2017-04'
group by name;
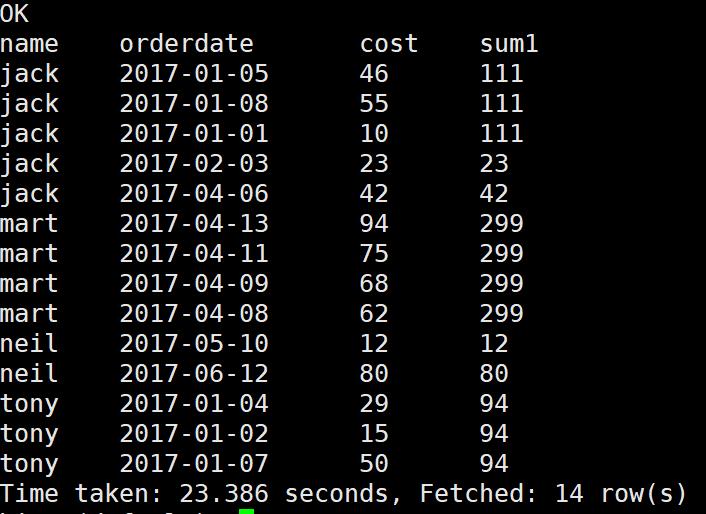
需求:查询顾客的购买明细及月购买总额。
select
name,
orderdate,
cost,
sum(cost) over(partition by name,month(orderdate)) sum1
from
business;
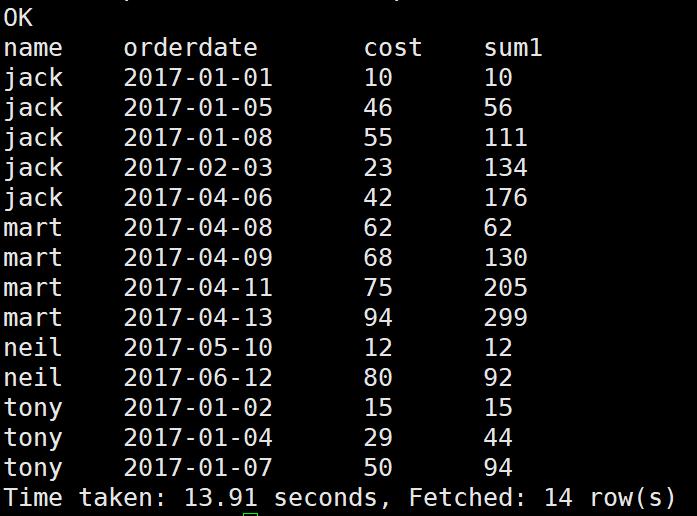
需求:上述的场景,将每个顾客的cost按照日期进行累加。
select
name,
orderdate,
cost,
sum(cost) over(partition by name order by orderdate) sum1
from
business;
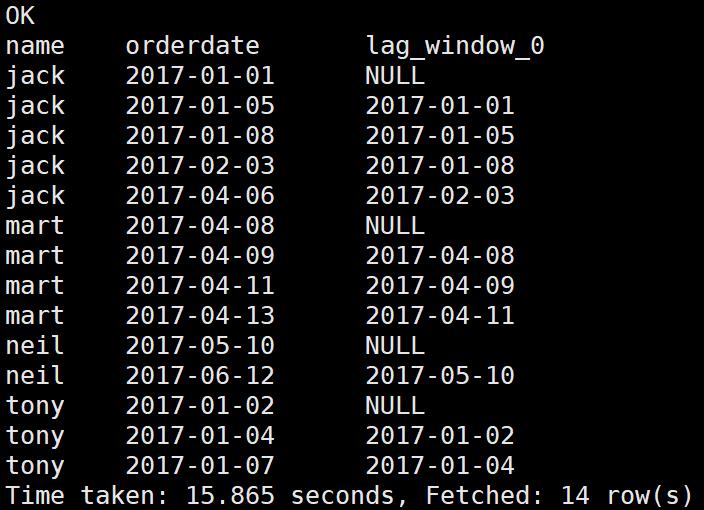
需求:查询用户上次的购买日期
select
name,
orderdate,
lag(orderdate,1) over(partition by name order by orderdate)
from
business;
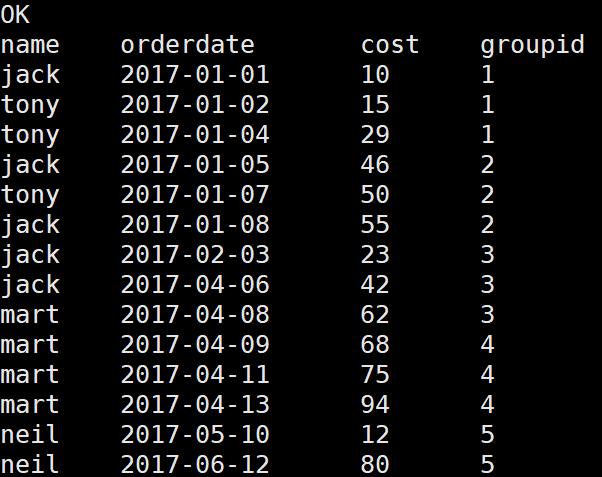
需求:查询前20%时间的订单信息
select
name,
orderdate,
cost,
ntile(5) over(order by orderdate) groupID
from
business;t1
select
name,
orderdate,
cost
from
(select
name,
orderdate,
cost,
ntile(5) over(order by orderdate) groupID
from
business)t1
where groupID = 1;
以上是关于Hive开窗函数的主要内容,如果未能解决你的问题,请参考以下文章