解读现代数据技术栈关键能力 | DEEPNOVA技术荟系列公开课第二期
Posted CSDN资讯
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了解读现代数据技术栈关键能力 | DEEPNOVA技术荟系列公开课第二期相关的知识,希望对你有一定的参考价值。

IT 从互联网、移动互联网已经发展到了 5G、IoT 时代。数字化浪潮下,高密度数据应用场景爆发增长,数据需要在不同的数据应用系统中快速流转、处理与分析,以支撑各类业务层创新的需求。
现在,结合了数据仓库与数据湖优势的“湖仓一体”,实现了数据在数仓与数据湖之间的无缝流转,打通了数据存储和计算层,兼顾数据湖的灵活性和数据仓库的成长性,将二者有效结合起来为用户实现更低的总体拥有成本。
为了帮助数据分析相关的业务与技术人员更深入了解湖仓一体,数据智能服务商滴普科技联合 CSDN,发起了 DEEPNOVA 技术荟系列公开课。在之前第一期《DEEPNOVA 技术荟系列公开课回顾:释放海量数据价值,尽显数据智能之美》主题公开课中,滴普科技 FastData 产品线总裁杨磊已经初步介绍高数据密度场景下所面临的技术新问题与挑战,以及滴普科技流批一体、湖仓一体数据智能平台 FastData 的产品功能与特性。在第二期公开课中,滴普科技首席程序员吴小前与滴普科技 DLink 产品总经理冯森梳理了现代数据技术栈发展历程,以及其中关键技术点,并与网友互动讨论。
数据技术栈发展:从寒武纪到爆发
现代数据技术栈 Modern Data Stack(以下简称 MDS),是与数据分析相关的技术栈,并具有云原生的特性。MDS 与传统技术栈不同点在于,十几年数据技术栈产品的模式是 All-In-One,一个产品实现多个功能,而 MDS 基于模块化、可组装的技术栈,其中的产品都可以在云上获得服务,并在云上通过连接,共同执行完成一项任务。
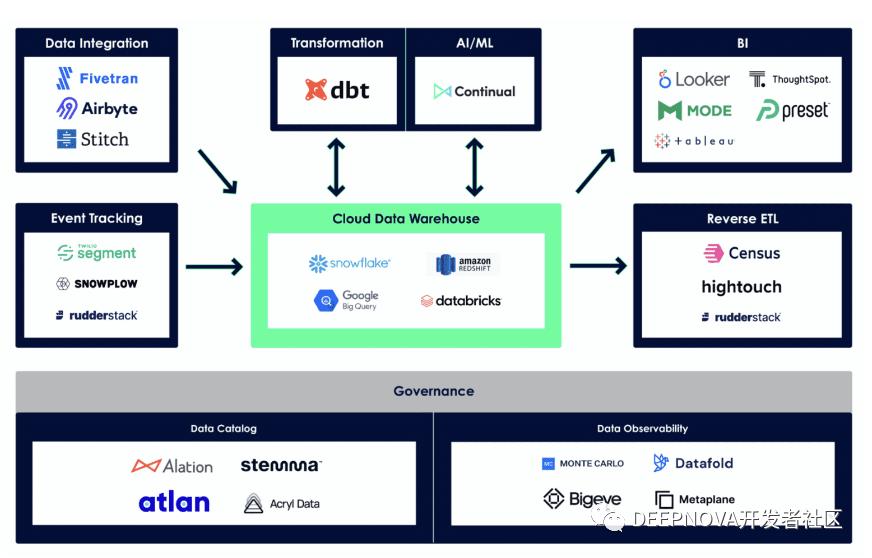
现代数据技术栈 Modern Data Stack
传统数仓经历了三十多年的发展,数据服务则有十多年的发展经历,在现代数据栈发展的第一阶段,2012 年到 2016 年,出现了众多的产品,就像寒武纪时代突然出现很多生物物种一样,因此这个时期被称作寒武纪时代。这个时期出现的数据类产品:
Chartio: 2010 年
Looker: 2011 年
Mode: 2012 年
Periscope: 2012 年
Fivetran: 2012 年
Metabase: 2014 年
Stitch: 2015 年
Redash: 2015 年
dbt: 2016 年
Amazon Redshift 2012 年
接下来的 2016 到 2020 年,则是数据栈发展的成熟期。随着云原生、云数仓的发展,数据服务的能力越来越强,与数据存储、处理与分析相关的产品,以及周边产品如 BI 分析、数据转换等,都随之发展起来。从 2021 年开始,到 2025 年,则将是 MDS 爆发的时期。产品逐渐成熟,并走向普及。在 MDS 中,数据治理、即时/实时分析、反向 ETL、平民化数据探索、垂直(领域)分析经验等能力都将增强。
产品之外,从技术架构角度,MDS 之前的“史前架构”,数据要分别进行数据导入、存储/计算、处理分析,而当时 All-In-One 的思想,每个部门都希望各自解决问题,因此形成了数据孤岛,各产品直接难以集成,TCO 非常高。2012 年随着以 AWS Redshift 为标志的产品,以存算分离、列存等技术解决成本和计算能力的问题,而引发了 MDS 的爆发式发展。现在,技术人员不再需要非常高深的技术能力,只需使用 SQL,就能实现数据的分析。
现代数据技术栈关键技术解析
在 MDS 之中的关键技术,首先是 Gartner 早先提出的数据编织。现在企业已有交易型数据库、数据仓库、数据湖、云端数据存储等众多数据源,Gartner 提出了数据编织,为企业“织”起一张虚拟的网,对企业所有数据虚拟化,在场景中利用知识图谱处理元数据。
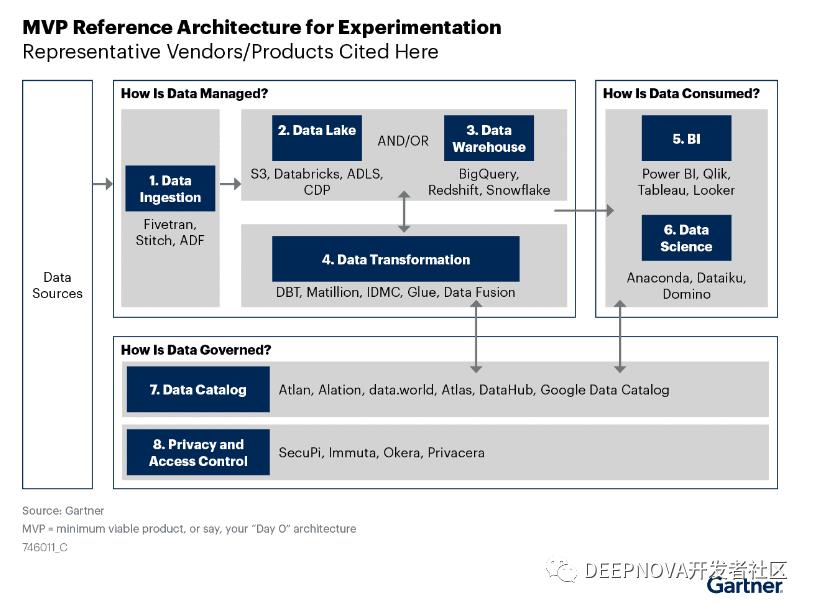
Garnter 主推数据编织 data fabric MVP 版本
另外,结合 Databricks 能够看到湖仓一体的特性,首先是支持事务 ACID,在企业当中,数据需为业务提供高性能的并发读写,支持事务 ACID 可确保在 SQL 访问模式下的并发读写一致性。第二,湖仓一体支持各种数据类型的实现与转变,并保证数据完整性,具有健全的数据治理与审计机制。第三,湖仓一体架构中 BI 直连数据源,提升数据分析效率,降低分析延迟与成本。第四,湖仓一体支持存算分离架构,赋予系统扩展性、提升计算的高并发,并且底层存储具有了弹性扩充能力。另外,湖仓一体开放性,支持各类计算与分析引擎,以及 Parquet、ORC 等数据格式,以及异构数据存存储,以及机器学习、SQL 查询、数据科学、数据分析等各类负载,以及支持端到端的数据流。
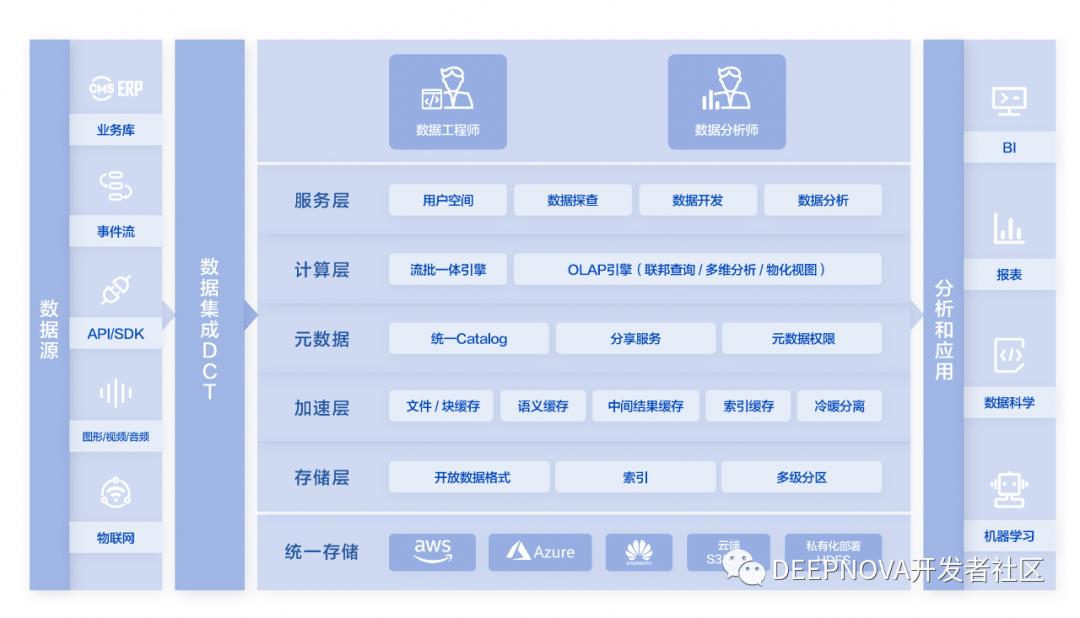
滴普科技 DLink 架构
互动问答:事务一致性、Catalog 与 Iceberg
在本期公开课中,滴普科技首席程序员吴小前与滴普科技 DLink 产品总经理冯森也对在线提问做出了回答:
湖仓一体如何保证事务一致性?
答:对象存储不支持文件原地更新,新的记录以 append 的方式写入新文件,即使对文件中的一行记录进行更改,也要重写整个文件,并且多线程并发读写也可能造成数据不一致。湖仓一体通过多版本的方式保证事务读写并发不冲突,通过将修改记录在 change file 中通过合并 base 文件的方式提升记录更改效率。
如何解决湖仓一体中的 catalog 问题?
答:湖仓一体中的 Catalog 是统一的元数据目录,它可以帮助我们让数据发现变的更简单,更加快速的查找到你想要的数据,同时提供面向多引擎(Hive Spark flink trino 等)的公共元数据存储和统一元数据服务。
Hadoop 体系 Table catalog 的黄金标准是 Hive Metastore,但在大数据量下元数据进行 list 操作会出现 namenode 性能瓶颈,解决的方式是通过将元数据和数据文件存放在一起形成表格式,通过在元数据文件中保存数据文件地址的方式实现快速文件检索。
Iceberg 作为湖仓一体的解决方案,有哪些优势?
答:
1.查询性能优化
隐藏分区(Hidden partition):用户不需要知道 iceberg 表是如何分区的,分区布局可以根据需要进行变更。用户的查询 SQL 不需要指定分区键,iceberg 根据 partition 的统计信息做 partition prune 即可实现分区过滤。隐藏分区的功能可以防止用户写的 SQL 有问题而导致的长时间查询不到结果的报错,防止用户写的 SQL 查询特别慢。
分区裁剪(Partition prune):元数据中包含分区统计信息,支持对分区进行过滤。
谓词下推(Predicate pushdown):Iceberg 元数据中包含丰富的列级的统计信息,如:value_counts,null_value_counts,以及列级的 Min/Max 信息等用于过滤文件。
2.数据安全
文件加密/解密(Encryption):支持文件级别的加密和解密功能。
3.机器学习
支持 Python:基于 iceberg 的数据湖可以做机器学习领域开发。
4.易扩展,灵活性
Schema 变更:Iceberg 抽象了自己的 schema,不绑定任何计算引擎的 schema。
开放的表格式:不绑定任何计算引擎和文件存储格式,更容易扩展。
DEEPNOVA 开发者社区作为面向技术开发者的交流学习、生态共创平台,未来,DEEPNOVA会继续以建立技术生态,合作共赢为宗旨,持续激发社区创新力,为开发者们提供更加前沿的技术思想及技术内容,促进圈层交流,学习互助,开拓技术视野。
以上是关于解读现代数据技术栈关键能力 | DEEPNOVA技术荟系列公开课第二期的主要内容,如果未能解决你的问题,请参考以下文章
湖上建仓全解析:如何打造湖仓一体数据平台 | DEEPNOVA技术荟系列公开课第四期
[深入研究4G/5G/6G专题-33]: URLLC-4-中国移动《面向 URLLC 场景的无线网络能力》解读-2-关键技术与演进路线