湖上建仓全解析:如何打造湖仓一体数据平台 | DEEPNOVA技术荟系列公开课第四期
Posted CSDN资讯
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了湖上建仓全解析:如何打造湖仓一体数据平台 | DEEPNOVA技术荟系列公开课第四期相关的知识,希望对你有一定的参考价值。

如今,面对数字化快速发展带来的挑战,现代化企业需要打破以往数据的孤岛,让数据从采集、加工、管理到应用,是统一的数据存储和数据处理,甚至是作为全栈式的湖仓一体数据平台,以支撑各类数据赋能业务,进而创造更多价值。
为了帮助数据分析相关的业务与技术人员更深入地了解湖仓一体,数据智能服务商滴普科技联合 CSDN,发起了 DEEPNOVA 技术荟系列公开课。第四期公开课中,滴普科技 DataFacts 产品负责人刘波在上一期数据入湖技术解析之后,进一步为开发者分享湖仓一体架构设计与湖上建仓技术实践。
湖仓一体技术架构与建仓流程
在数据智能时代,湖仓一体是否会成为每个企业构建大数据栈的必要选项?答案几乎是肯定的。对于高速增长的企业来说,选择湖仓一体架构来替代传统的数据仓和数据湖,将成为不可逆转的趋势。
刘波首先分享了滴普科技的湖仓一体技术架构,分为存储层、数据管理与加速层、计算层与资源管理、数据应用层四部分。
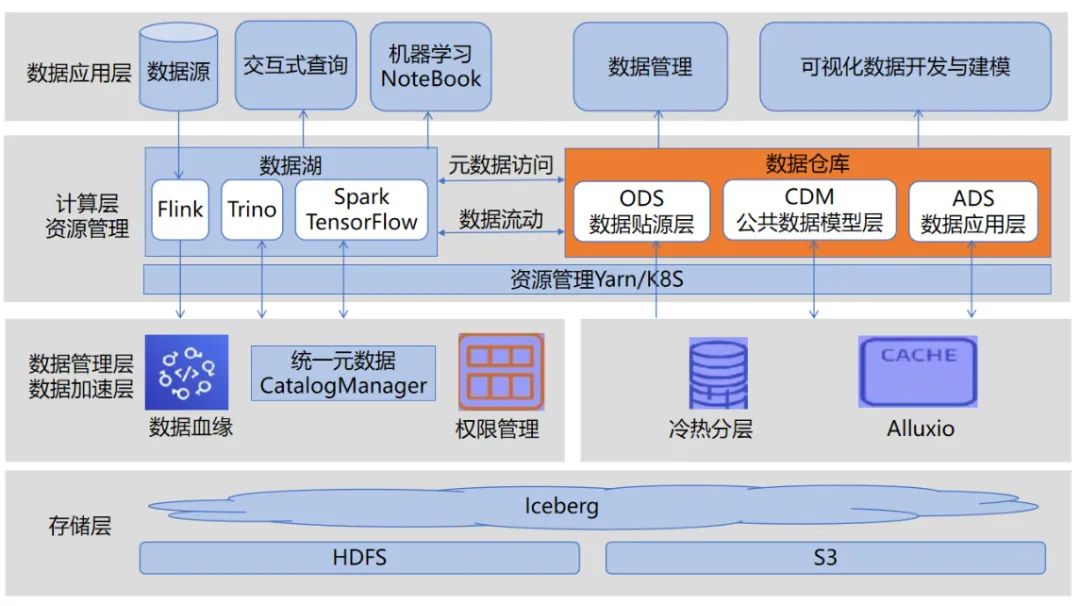
湖仓一体架构图
其中,数据存储层支持 OSS、S3、Minio 等对象存储和 Hadoop HDFS。对象存储存储非结构化、原始数据、冷数据,提供高性价比,HDFS 存储结构化数据,提供高性能存储。使用 Iceberg、Hudi、Delta 作为数据存储中间层,能够基于 HDFS、对象存储等底层存储,支持 ACID 语义、实现快速更新能力;通过 Alluxio 进行数据缓存,加速 Spark、Flink、Trino(原 Presto)等计算引擎对数据湖的读写。
计算层支持多引擎,Spark、Trino、Flink 等均实现 Serverless 化,跑在 K8S 中,即开即用,满足不同查询场景,并可以通过 K8S、Yarn 进行统一资源访问/调度。
滴普科技湖仓一体架构中最重要的一个设计——智能元数据,是基于特定的规则,可以智能识别结构化、半结构化文件的元数据,构建数据目录,并转化成内置存储中的一个Hive表,统一进行元数据管理,提供类HiveMeta API针对不同计算引擎访问底层数据。
另外,架构中统一了编程模型,使用 Apache Beam 作为统一的编程模型,提供统一的 IDE,统一流和批,抽象出统一的 API 接口,并且生成的数据处理任务应该能够在各个计算引擎上执行,使得用户可以自由切换数据处理任务的执行引擎与执行环境。
湖仓一体另一个重要的实现方案是以 Hive 外部表的形式。数据源的数据被采集到对象存储如 S3、OSS、OBS 中,然后创建 Hive 外部表,与对象存储建立连接,通过 Spark SQL 读取 Hive 外部表的数据,写入湖中。通过 Spark SQL 读取湖的数据,按照贴源层的规范,写入 Hive 外部表,最后通过 Hive SQL 或者 Spark SQL 进行数据仓库与数据集市数据的加工,以 Hive 外部表的方式进行管理。
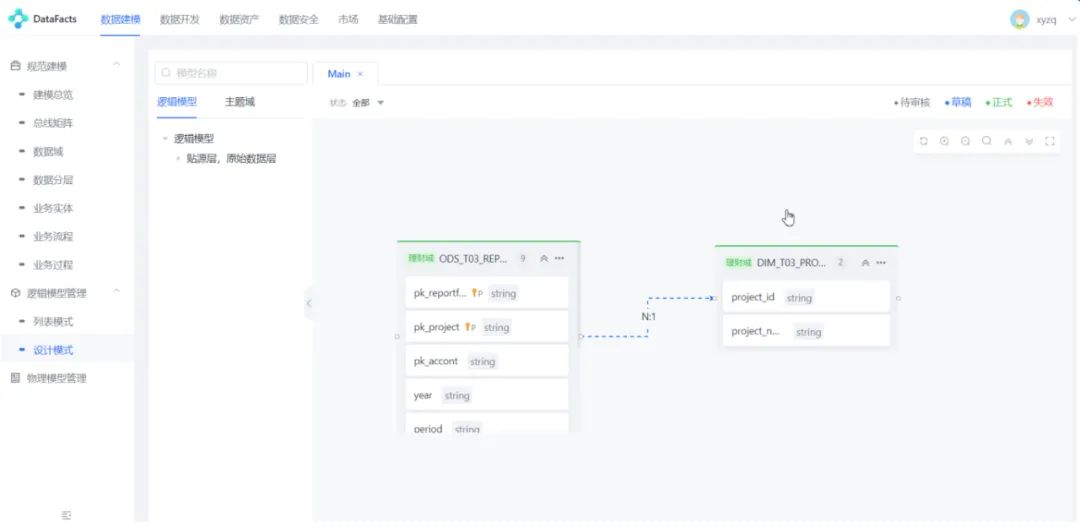
流程示意图:第二步数据模型设计
滴普科技的 DataFacts 平台进行湖上建仓的流程分为基础配置、数据模型设计、项目配置、ETL 工程开发、发布与运维、数据服务开发。
-
首先,进行数据开发之前,用户需先完成计算、存储引擎配置及连通性测试,以及相关账号与权限的配置工作。
-
接下来,需要进行数据模型设计,包括模型分层、所属主题、模型数据、模型关系等信息的逻辑数据模型设计,以及数据库类型、表物理参数,创建的数据源等的物理数据模型设计。
-
第三步,创建项目空间实现权限隔离,项目空间中可配置项目基础信息、开发环境&生产环境、成员管理、权限管理、数据源信息等。
-
第四步,进入项目空间进行 ETL 工程开发,产品具备离线/实时开发能力,适配多种任务类型(Spark SQL、Hive SQL、Impala SQL、Flink SQL、Python、Jar 包等),支持资源管理、函数管理、变量管理等功能。ETL 工程在开发环境完成开发及测试后,可通过“发布”功能经过审核后,提交至生产环境。在运行中,DataFacts 平台在运维模块对生产环境任务进行运维、监控、错误重试、补数据、流程管理、告警配置等自动化运维操作。
-
最后,用户进行数据服务的开发工作时,DataFacts 平台为企业上层应用提供统一的、标准的数据共享接口,提高数据利用效率和质量。
FastData湖仓一体关键技术
作为一个新兴的数据架构,湖仓一体正成为兵家必争之地。滴普科技通过技术架构的融合与创新,让湖仓一体化的技术优势在应用中得到了充分体现。这也是滴普科技的技术“杀手锏”。
在整体的架构设计介绍之后,刘波重点介绍了 DataFacts 中重要的技术思路与实现方法。
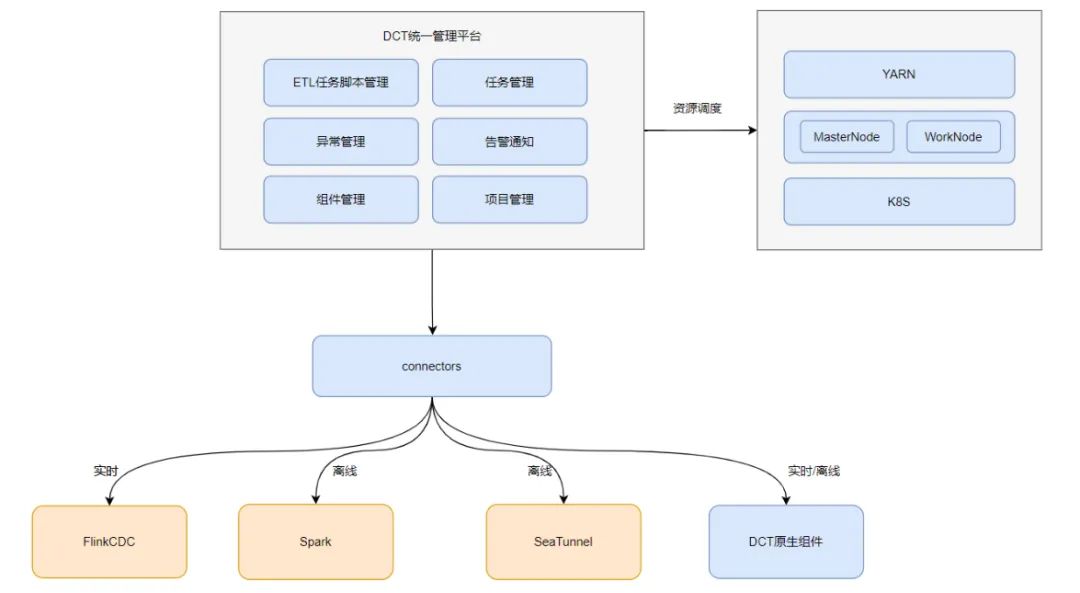
DataFacts 数据集成模块
在数据入湖中,DataFacts数据集成模块,包含 ETL 任务脚本、任务管理、告警、项目管理、组件管理,组件管理可以通过自定义灵活使用,资源调度管理目前支持 Yarn、K8S,还可以本地化的资源调度管理方式,通过 MasterNode、WorkNode 去实现资源调度管理。在平台完成配置后,通过 Connectors 组件,例如通过 Flink CDC 抓取日志,实时采集数据,采用Spark 或复用 SeeTunnel 的Connector 离线采集数据,还可以集成自研的组件,支持实时和离线的数据采集。
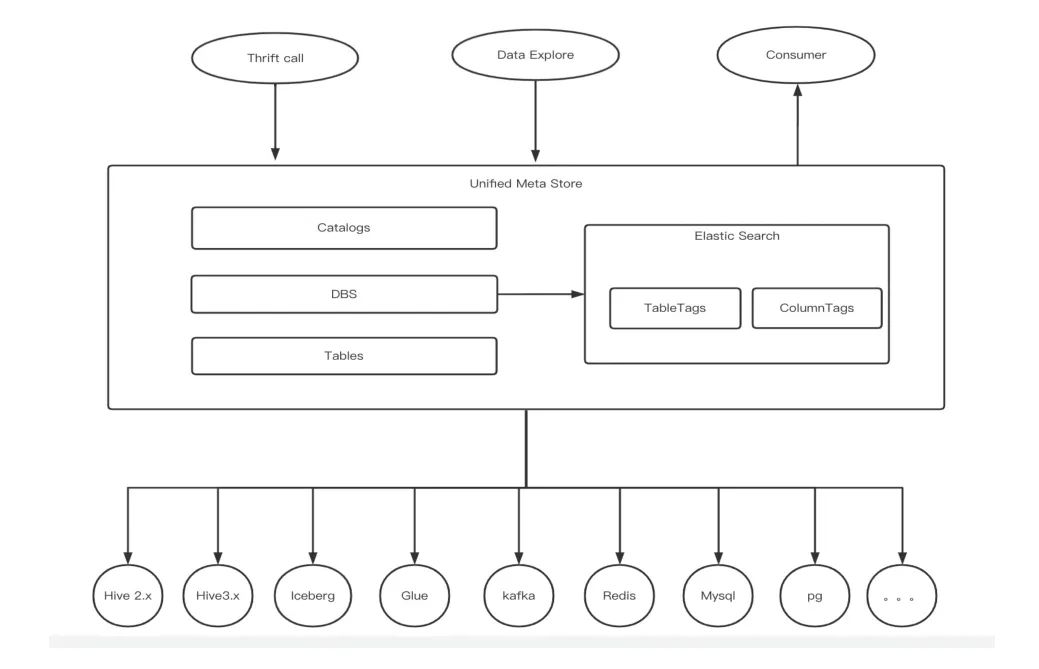
DLink统一元数据管理架构设计
FastData一个重要的技术点是统一元数据管理,保证数据湖与数仓数据的互通。详细来说,元数据的交互流程和管理分为:
1. 创建 Catalog
客户端通过 rpc 调用统一元数据服务,提供 Catalog 名称、租户、数据源连接地址等信息,元数据服务持久 Catalog 名称、租户、数据源连接地址等信息到 Catalogs 表。(对于 HMS,需额外提供版本号;对于 HMS 3.x,除了在 Catalogs 表中插入记录,还需要在 HMS 的 CTLGS 表中插入记录,目的是在一个 HMS 实例中细化到 database 的权限隔离。)
2. 创建数据库
客户端通过 rpc 调用统一元数据服务,提供 Catalog 名称、租户、数据库等信息,元数据服务在已经创建 Catalog 的基础上,将数据库信息持久化到 DBS 表,同时调用相应的底层数据源创建数据库。由于创建的数据库信息跟 Catalog 关联,因此权限隔离能够细化到数据库级别。
3. 查询元数据
客户端通过 rpc 调用统一元数据服务,提供租户信息,元数据服务根据请求可以返回:租户拥有的 Catalogs;指定 Catalog 下的相关 databases;指定 Catalog 和 database 下的相关 tables;指定标签的数据(表、字段等)。如果自定义表结构中不存在相关信息,比如 HMS 表的分区等信息,则需要查询对应底层支持的元数据(如 HMS)。
在统一管理平台、元数据设计思路之后,刘波还介绍了其他一些关键技术,如 CDH 与 DLink 跨 Catalog 数仓过渡、Iceberg 表维护、DLink 兼容 Hive 与 Spark 的设计、DataFacts 数据集成模块优化、Trino Catalog 热加载、Trino 服务暴露、Trino 支持 K8S 亲和性调度。
解决传统Lambda架构痛点:增量计算新架构
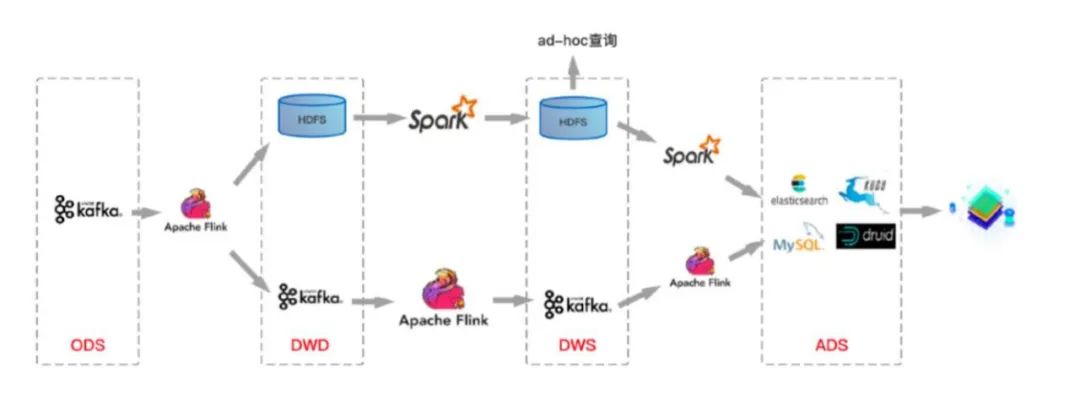
传统 Lambda 架构,数据无法更新、增加
以往湖上建仓,采用传统的 Lambda 架构,实际使用中,开发者会遇到种种问题与痛点。例如传统 Lambda 架构不支持 ACID,因此 Upsert 场景数据无法更新,不支持 Row-level delete,数据修正成本高。另外,传统 Lambda 架构的数据难以保证准实时可见,无法增量读取,无法实现存储层面的流批统一,无法支持分钟级延迟的数据分析场景。第三,传统 Lambda 架构中 Table Evolution,写入型 Schema,对 Schema 变更支持不够,对 Partition Spec 变更支持不友好。
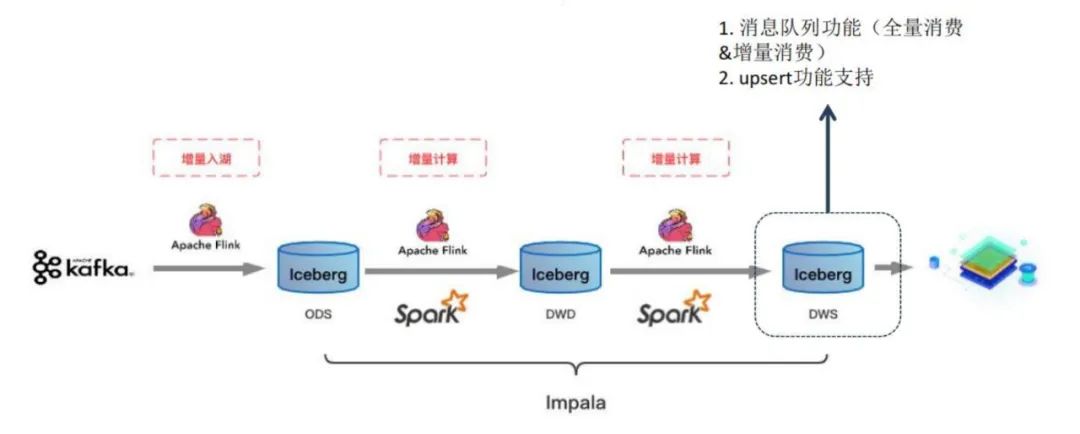
FastData采用增量计算新架构,解决 Lambda 架构痛点
针对这些问题,FastData采用了增加计算的设计,数据源在 Kafka 中,采用增量入湖,通过 Flink 把数据写到 Iceberg 里(Iceberg 支持行级别数据删除和更新)。从 ODS 到 DWS 层,还可以采用 Impala 4.1 及以上版本,读写 Iceberg 数据,类似于消息队列,满足全量和增量的消费,并支持行级别数据的删除和更新。
通过以上设计,FastData可支持 ACID 语义,避免读到不完整的 Commit;基于乐观锁支持并发 Commit;Row-level delete,支持 Upsert。FastData还具备增量快照机制,Commit 后数据即可见(分钟级),可回溯历史快照。FastData支持开放的表格式,如数据格式 parquet、orc、avro;多种计算引擎如 Spark、Flink、Hive、Trino/Presto,以及支持数据的流、批读取和写入。
此外,刘波也分享了针对 Kafka、Iceberg 等存在的功能欠缺,FastData的大量实践经验,以实现统一存储的准实时数仓。
FastData帮助客户构建数据湖&湖仓一体完整架构
通过架构设计与研发工作,滴普科技为多家客户提供了湖仓一体的技术与服务。公开课中,刘波分享了某零售企业如何利用 FastData构建湖仓一体的完整案例。
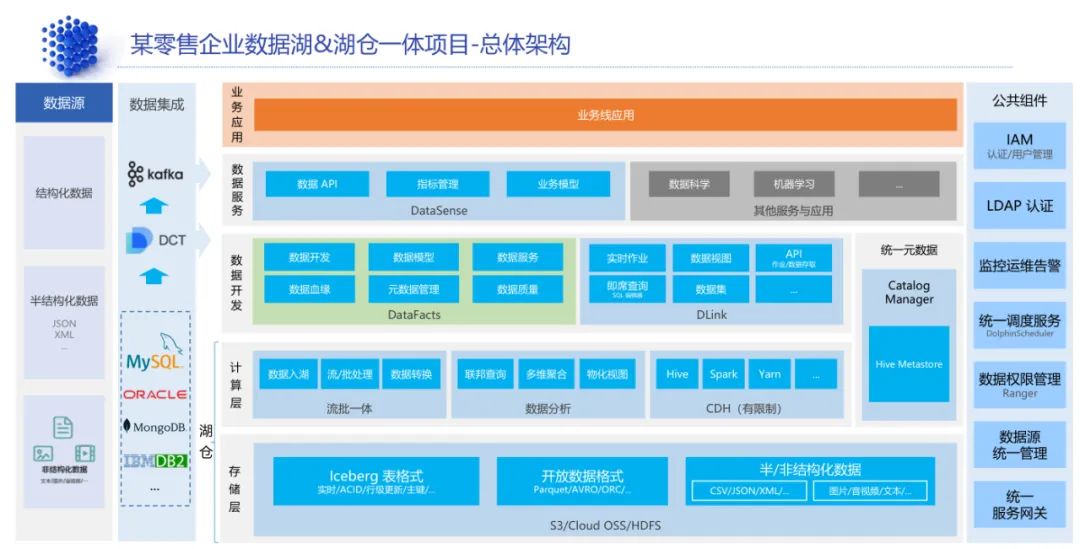
客户基于DataFacts与 CDH 6.0.0 构建数据中台之后,采用 FastData实现从数据建模到开发、发布、运维、资产、数据质量、数据安全、数据服务等全部功能,将数据中台升级为数据湖&湖仓一体平台。
方案实现了结构化数据的单表数据实时入湖和离线数据入湖、实时整库数据入湖、历史数据入湖,同时提供数据归档、实时采集任务迁移、离线任务与实时任务衔接,以及 Iceberg 快速迁移。对于半结构化和非结构化数据入湖,例如静态大文件与通过 Kafka 过来的 JSON、XML、日志等流式文件,并由滴普科技的 DLink API 提供流量控制以保护底层的数据存储。同时,DataFacts 还提供了数据建模、湖上建仓、数据治理等功能。
写在最后
从第四期的公开课内容我们能看到,滴普科技 FastData积累了从架构流程的完整方案,到其中关键技术实践,再到解决传统架构痛点的设计等扎实的开发经验与产品。凭借这些技术积累与实践,滴普科技正在为更多头部行业的用户构建湖仓一体数据平台,公开课也详细介绍了其中一些典型的客户场景与案例。
另外,DEEPNOVA 开发者社区作为面向技术开发者的交流学习、生态共创平台,未来,DEEPNOVA 会继续以建立技术生态,合作共赢为宗旨,持续激发社区创新力,为开发者们提供更加前沿的技术思想及技术内容,促进圈层交流,学习互助,开拓技术视野。
以上是关于湖上建仓全解析:如何打造湖仓一体数据平台 | DEEPNOVA技术荟系列公开课第四期的主要内容,如果未能解决你的问题,请参考以下文章