渲染出3D视频,单像素点实时渲染
Posted 人工智能博士
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了渲染出3D视频,单像素点实时渲染相关的知识,希望对你有一定的参考价值。
点上方人工智能算法与Python大数据获取更多干货
在右上方 ··· 设为星标 ★,第一时间获取资源
仅做学术分享,如有侵权,联系删除
转载于 :机器之心
合成视频达到了新的高度,来自德国埃尔朗根 - 纽伦堡大学的研究者提出了一种新的场景合成方法,使合成视频更接近现实。
合成逼真的虚拟环境是计算机图形学和计算机视觉中研究最多的主题之一,它们所面临是一个重要问题是 3D 形状应该如何编码和存储在内存中。用户通常在三角形网格、体素网格、隐函数和点云之间进行选择。每种表示法都有不同的优点和缺点。为了有效渲染不透明表面,通常会选择三角形网格,体素网格常用于体绘制,而隐函数可用于精确描述非线性分析表面,另一方面,点云具有易于使用的优点,因为不必考虑拓扑。
近日,来自国埃尔朗根 - 纽伦堡大学视觉计算实验室的研究者提出了一种新颖的基于点的、可微的神经渲染 pipeline,可用于场景细化和新颖的视图合成。
我们先来看下该研究的效果:


有网友表示,这是电子游戏制作人的梦想。

「这种效果是由 2D 图像生成的,输出是如此平滑,令人疯狂,给人印象非常深刻。」DeepMind 产品经理 Alexandre Moufarek 表示。

「如果你对这项研究感到困惑,不明白它为什么令人印象深刻,它实际上不是一个视频,它是由一组照片制作而成(顺便说一下,不是平滑的照片)。该研究发布的流畅视频是用神经技术渲染的,效果非常自然。为制作者点赞。」有网友总结道。

具体来讲,该研究的输入是点云和相机参数的初始估计,输出是由任意相机姿态合成的图像。点云渲染由使用多分辨率单像素点栅格化的可微渲染器执行。离散栅格化的空间梯度由 ghost 几何近似。渲染后,神经图像金字塔通过一个深度神经网络进行着色计算和孔填充(hole-filling)。然后,可微、基于物理的色调映射器(tonemapper)将中间输出转换为目标图像。由于 pipeline 的所有阶段都是可微的,该研究优化了所有场景参数,即相机模型、相机姿态、点位置、点颜色、环境映射、渲染网络权重、晕影、相机响应函数、每张图像曝光和每张图像白平衡。
该研究表明所提出的系统能够合成比现有方法更清晰、更一致的新视图,因为在训练期间就对初始重建进行了优化。高效的每像素点栅格化允许研究者使用任意相机模型并实时显示超过 1 亿点的场景。

论文地址:https://arxiv.org/pdf/2110.06635.pdf
源代码会在之后进行发布。
技术细节
该研究提出的方法在 Aliev 等人的 pipeline 上构建,并通过多种方式进行了改进。具体地,研究者添加了一个物理可微的相机模型和一个可微的色调映射器,并提供了一个更好地逼近单像素点栅格化的空间梯度的公式。
这种可微的 pipeline 不仅可以优化神经点特征,而且在训练阶段能够纠正不精确的输入。因此,该系统基于神经渲染网络的视觉损失调整相机姿态和相机模型,并结合晕影模型和每个相机的传感器响应曲线估计每个图像的曝光和白平衡值。
下图 1 为这种方法的示意图:
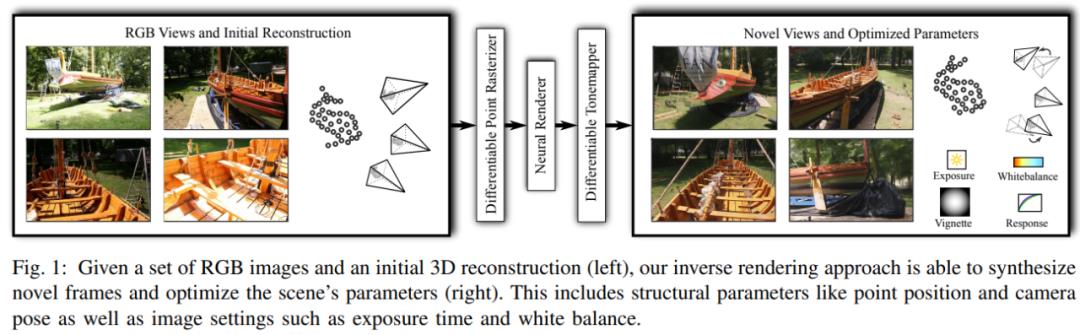
完整的端到端可训练神经渲染 pipeline 如下图 2 所示,其中输入为新帧的相机参数、一个点云(每个点被分配给可学得的神经描述器)和一个环境图,输出为给定新视点的 LDR 场景图像。由于所有步骤都是可微的,因此可以同时对场景结构、网络参数和传感器模型进行优化:

具体地,该 pipeline 的第一个步骤是可微的栅格化单元(图 2 左),通过使用相机参数将每个点映射到图像空间,进而将该点渲染为单像素大小的 splat;
神经渲染器(图 2 中)使用多分辨率神经图像来生成单个 HDR 输出图像,它包含一个具有跳跃连接的四层全卷积 UNet,其中更低像素的输入图像连接到中间特征向量;
该 pipeline 的最后一个步骤(图 2 右)是可学得的色调映射操作器,它将渲染的 HDR 图像转换为 LDR。这个色调映射器模拟了数码相机的物理镜头和传感器特性,因此最适合智能手机、DSL 相机和摄像机的 LDR 图像捕捉。
可微的单像素点渲染
如上所述,可微的栅格化单元使用单像素大小的 splat 对多分辨率的变形点云进行渲染。形式上来讲,神经图像 I 的分辨率层 l ϵ 0,1...,L−1 的是渲染器函数Φ_l 的输出,如下公式(1)所示:

点栅格化的前向传递可以分解为三个主要步骤,分别是映射、遮挡检查和混合。下图 3 展示了使用单像素点栅格化方法渲染的两张彩色图像的示意图:

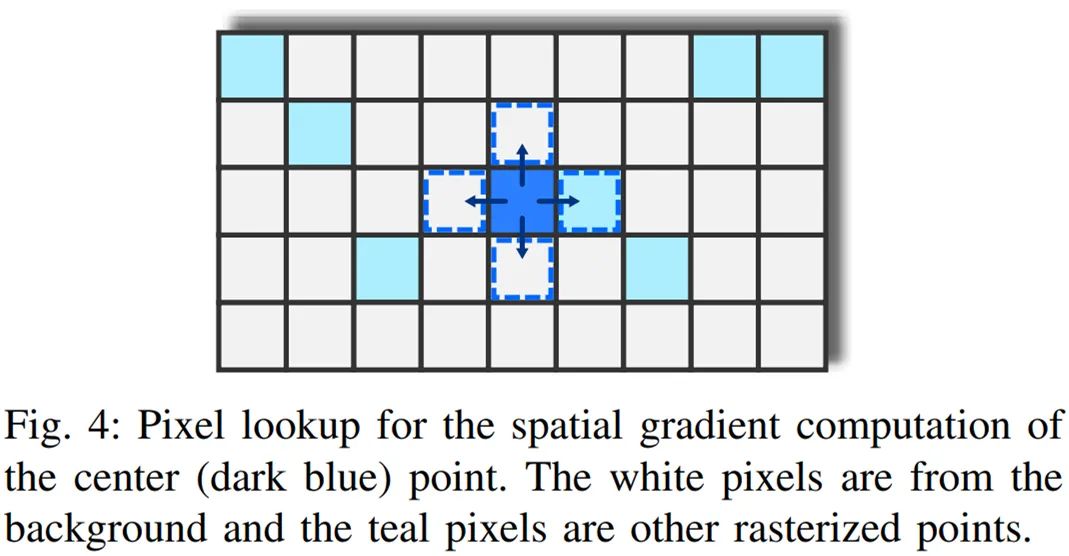
点栅格化单元的后向传递首先计算参数相关的渲染器函数(1)的偏导数,如下公式(8)所示。使用链式法则,研究者可以计算损失梯度并传递到优化器。

如下图 4 所示,研究者通过在每个方向上将 p = (u, v) 移动一个像素来计算近似值。
在下图 5 中,在混合阶段前插入一个 dropout 层,该层将点云分割为两个集。第一个集正常地混合,并生成输入图像;第二个集,研究者称之为假性触控点(ghost point),不在前向传递中使用。

通过进一步的性能分析,研究者发现即使在小的分辨率层,数百个点也可以通过单个像素的模糊深度测试。为了将这一数字降低到合理的范围,研究者采用了类似于 [72] 的随机点丢弃方法。随机丢弃的效果如下图 6 所示,其中基于渲染点的数量对每个像素进行上色。

实验展示
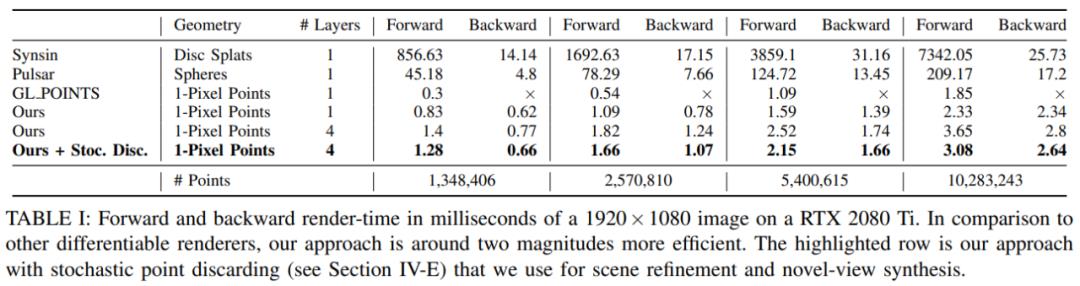
在实验部分,研究者首先针对前向和后向单像素点栅格化的运行时(runtime)与其他可微渲染系统进行了比较。下表 1 展示了自己的方法与 Synsin、Pulsar、使用 GL POINTS 方法的 OpenGL 默认点渲染的 GPU 帧时间的度量结果,计时时仅包含栅格化本身,不包括神经网络和色调映射器。可以看到,研究者的方法在所有指标上均优于其他方法。
研究者提出了用于可微单像素点渲染的假性梯度(ghost gradient),并表示假性梯度在场景细化过程中可以提升梯度准确性和增强稳健性。他们通过一个消融实验来确认这一说法。实验结果如下图 7 所示,图(上)展示了姿态优化前后合成图像和真值之间的像素误差。可以清楚地看到,在添加位置和旋转噪声之前,使用假性梯度可以使感知损失收敛到初始解。

新视角合成。除了场景细化外,该方法还可以在多视角立体数据集上合成新的视图。下图 8 展示了合成的两个测试帧。比较结果可以发现 Synsin、NPBG 和该研究所用方法可以很好地合成参考帧,而 Pulsar 和 NRW 的输出稍差。

该研究还在下表 II 中提供了定量评估。该表显示了所有测试图像的平均 VGG 损失、LPIPS 损失 [87] 和峰值信噪比 (PSNR)。所有方法都是通过最小化 VGG 损失来训练的。

HDR 神经渲染。出于评估目的,该研究从训练集中删除了 20 个随机选择的帧,并让系统从估计的姿势中合成它们。存储在图像元数据中的测试帧的曝光值传递给色调映射器(tone mapper)。下图 11 显示了一些测试帧,左列是真实情况,中间是合成视图,右列是每像素误差图。

优化的色调映射器 (TM) 类似于捕获过程中使用的数码相机的物理和光学特性。在推理时替换 TM 的结果如下图 12 所示:

---------♥---------
声明:本内容来源网络,版权属于原作者
图片来源网络,不代表本公众号立场。如有侵权,联系删除
AI博士私人微信,还有少量空位


点个在看支持一下吧

 创作挑战赛
创作挑战赛
 新人创作奖励来咯,坚持创作打卡瓜分现金大奖
新人创作奖励来咯,坚持创作打卡瓜分现金大奖
以上是关于渲染出3D视频,单像素点实时渲染的主要内容,如果未能解决你的问题,请参考以下文章
假3D场景逼真到火爆外网!超1亿像素无死角,被赞AI渲染新高度