大数据-kafka学习—— 生产调优硬件配置选择
Posted 机智兵
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据-kafka学习—— 生产调优硬件配置选择相关的知识,希望对你有一定的参考价值。
目录
一、场景说明
100万日活,每人每天100条日志,每天总共的日志条数上100万*100条=1亿条
1亿/24小时/60分/60秒=1150条/每分钟
每条日志大小:0.5K-2K(取1K)
1150条/每分钟*1K≈ 1m/s
高峰期每分钟:1150条*20倍 = 23000条。
每秒多少数据量:20MB/s。
二、服务器台数选择
服务器台数 = 2*(生产者峰值生产速率*副本/100)+1
= 2*(20m/s * 2/100)+1 = 3 (台)
三、磁盘选择
Kafka按照顺序读写,机械硬盘和固态硬盘 顺序读写速度差不多
建议选择普通的机械硬盘
1亿条 * 1K = 100G
100G*2个副本*3天/0.7 = 1T
建议三台服务器总的磁盘大小 大于1T
四、 内存选择
1)堆内存:Kafka堆内存建议每个节点:10G~15G
1、在kafka-server-start.sh中修改
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"
fi2、查看kafka进程号 JPS
jps
73639 SpringbootKafkaApplication
72966 Kafka
73638 Launcher
21591 ZooKeeperMain3、根据kafka进程号,查看Kafka的GC情况
jstat -gc 75638 1s 10
S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT
0.0 7168.0 0.0 7168.0 48128.0 9216.0 993280.0 154109.0 48636.0 43913.9 6396.0 5806.5 7 0.162 0 0.000 0.162
0.0 7168.0 0.0 7168.0 48128.0 9216.0 993280.0 154109.0 48636.0 43913.9 6396.0 5806.5 7 0.162 0 0.000 0.162
0.0 7168.0 0.0 7168.0 48128.0 9216.0 993280.0 154109.0 48636.0 43913.9 6396.0 5806.5 7 0.162 0 0.000 0.162
0.0 7168.0 0.0 7168.0 48128.0 9216.0 993280.0 154109.0 48636.0 43913.9 6396.0 5806.5 7 0.162 0 0.000 0.162
0.0 7168.0 0.0 7168.0 48128.0 9216.0 993280.0 154109.0 48636.0 43913.9 6396.0 5806.5 7 0.162 0 0.000 0.162
0.0 7168.0 0.0 7168.0 48128.0 9216.0 993280.0 154109.0 48636.0 43913.9 6396.0 5806.5 7 0.162 0 0.000 0.162
0.0 7168.0 0.0 7168.0 48128.0 9216.0 993280.0 154109.0 48636.0 43913.9 6396.0 5806.5 7 0.162 0 0.000 0.162
0.0 7168.0 0.0 7168.0 48128.0 10240.0 993280.0 154109.0 48636.0 43913.9 6396.0 5806.5 7 0.162 0 0.000 0.162
0.0 7168.0 0.0 7168.0 48128.0 10240.0 993280.0 154109.0 48636.0 43913.9 6396.0 5806.5 7 0.162 0 0.000 0.162
0.0 7168.0 0.0 7168.0 48128.0 10240.0 993280.0 154109.0 48636.0 43913.9 6396.0 5806.5 7 0.162 0 0.000 0.162S0C:第一个幸存区的大小 S1C: 第二个幸存区的大小
S0U: 第一个幸存区的使用大小 S1U:第二个幸存区的使用大小
EC:伊甸园区的大小 EU:伊甸园区的使用大小
OC: 老年代大小 OU:老年代使用大小
MC: 方法区大小 MU:方法区使用大小
CCSC:压缩类空间大小 CCSU:压缩类空间使用大小
YGC:年轻代垃圾回收次数 YGCT:年轻代垃圾回收消耗时间
FGC: 老年代垃圾回收次数 FGCT:老年代垃圾回收消耗时间
GCT: 垃圾回收消耗总时间
4、根据Kafka进程号,查看Kafka的堆内存
jmap -heap 75638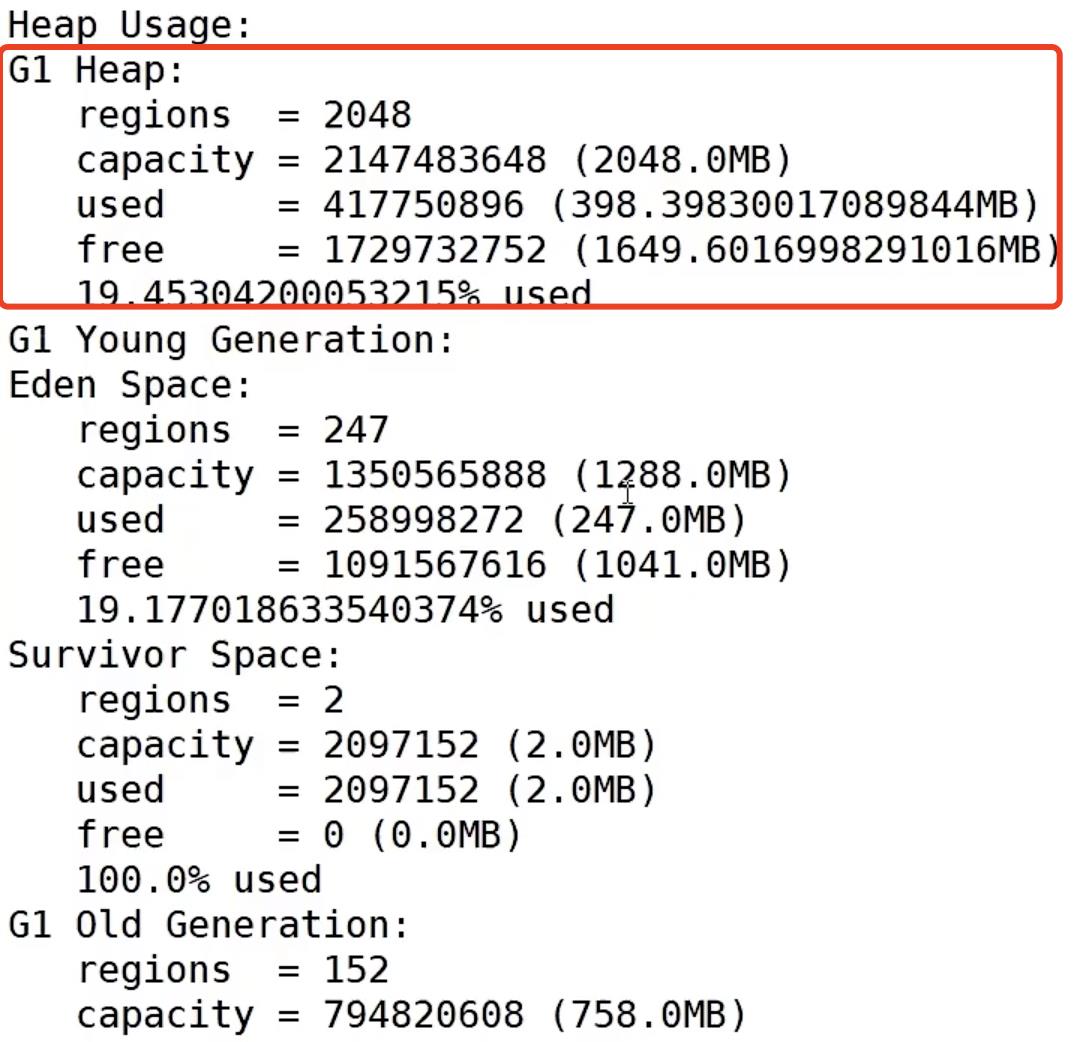
2)页缓存:
页缓存上Linux系统服务器的内存,我们只需要保证1个segment(1g)中25%的数据在内存中就好。
每个节点页缓存大小=(分区数*1g*25%)/节点数。
例如10个分区,页缓存大小=(分区数Leader(10)*1g*25%)/3≈ 1g
一台服务器 10g+1g
建议服务器内存大于等于11G。
五、 CPU选择
num.io.threads=8 负责写磁盘的线程数,整个参数值要占到总核数的50%。
num.replica.fetchers=1 副本拉取线程数,这个参数占总核数的50%的1/3。
num.network.threads=3 数据传输线程数,这个线程占总核数的50%的2/3。
建议32个CPU CORE
六、网络选择
网络带宽=峰值吞吐量≈ 20MB/s。选择千兆网卡即可。
100Mbps单位数bit;10M/s单位数byte ; 1byte = 8bit,100Mbps/8= 12.5M/s
一般的百兆的网卡(100Mbps)、千兆的网卡(1000Mbps)、万兆的网卡(10000Mbps)。
以上是关于大数据-kafka学习—— 生产调优硬件配置选择的主要内容,如果未能解决你的问题,请参考以下文章