Day549.kafka生产调优手册 -kafka
Posted 阿昌喜欢吃黄桃
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Day549.kafka生产调优手册 -kafka相关的知识,希望对你有一定的参考价值。
kafka生产调优手册
一、Kafka 硬件 配置选择
1、场景说明

2、服务器台数选择

3、磁盘选择

4、内存选择
Kafka 内存组成:堆内存 + 页缓存
1)Kafka 堆内存建议每个节点:10g ~ 15g
在 kafka-server-start.sh 中修改
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
export KAFKA_HEAP_OPTS="-Xmx10G -Xms10G"
fi
查看 Kafka 进程号:
[atguigu@hadoop102 kafka]$ jps
2321 Kafka
5255 Jps
1931 QuorumPeerMain
根据 Kafka 进程号,查看 Kafka 的 GC 情况:
jstat -gc 2321 1s 10
新生代GC次数


根据 Kafka 进程号,查看 Kafka 的堆内存:
[atguigu@hadoop102 kafka]$ jmap -heap 2321
Attaching to process ID 2321, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 25.212-b10
using thread-local object allocation.
Garbage-First (G1) GC with 8 thread(s)
Heap Configuration:
MinHeapFreeRatio = 40
MaxHeapFreeRatio = 70
MaxHeapSize = 2147483648 (2048.0MB)
NewSize = 1363144 (1.2999954223632812MB)
MaxNewSize = 1287651328 (1228.0MB)
OldSize = 5452592 (5.1999969482421875MB)
NewRatio = 2
SurvivorRatio = 8
MetaspaceSize = 21807104 (20.796875MB)
CompressedClassSpaceSize = 1073741824 (1024.0MB)
MaxMetaspaceSize = 17592186044415 MB
G1HeapRegionSize = 1048576 (1.0MB)
Heap Usage:
G1 Heap:
regions = 2048
capacity = 2147483648 (2048.0MB)
used = 246367744 (234.95458984375MB)
free = 1901115904 (1813.04541015625MB)
11.472392082214355% used
G1 Young Generation:
Eden Space:
regions = 83
capacity = 105906176 (101.0MB)
used = 87031808 (83.0MB)
free = 18874368 (18.0MB)
82.17821782178218% used
Survivor Space:
regions = 7
capacity = 7340032 (7.0MB)
used = 7340032 (7.0MB)
free = 0 (0.0MB)
100.0% used
G1 Old Generation:
regions = 147
capacity = 2034237440 (1940.0MB)
used = 151995904 (144.95458984375MB)
free = 1882241536 (1795.04541015625MB)
7.471886074420103% used
13364 interned Strings occupying 1449608 bytes.
页缓存:页缓存是 Linux 系统服务器的内存。
我们只需要保证 1 个 segment(1g)中25%的数据在内存中就好。

5、CPU 选择


6、网络选择

二、Kafka 生产者

1、Kafka 生产者核心参数配置



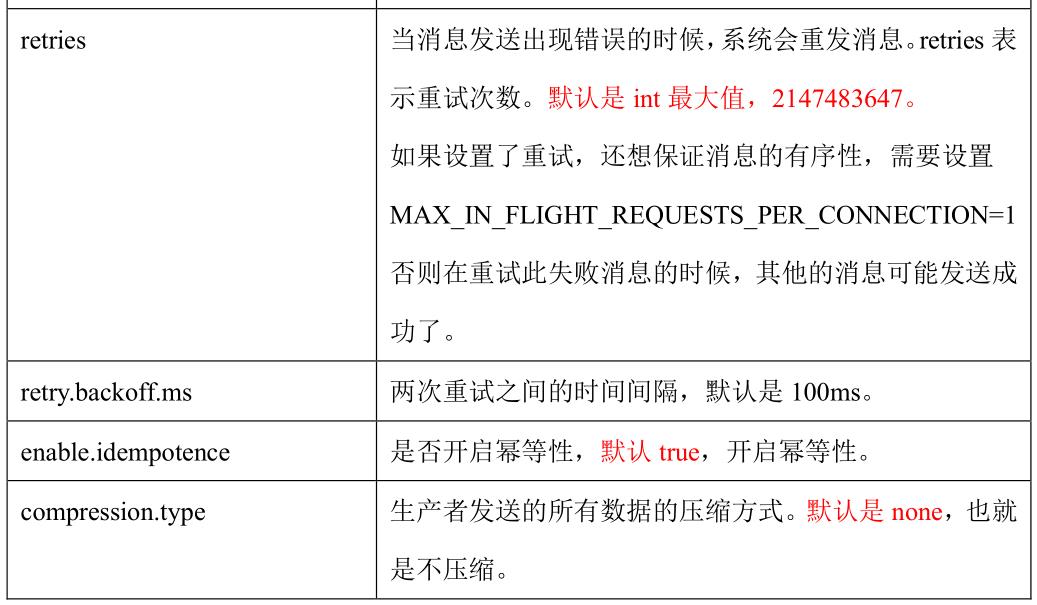

2、生产者如何提高吞吐量

3、数据可靠性
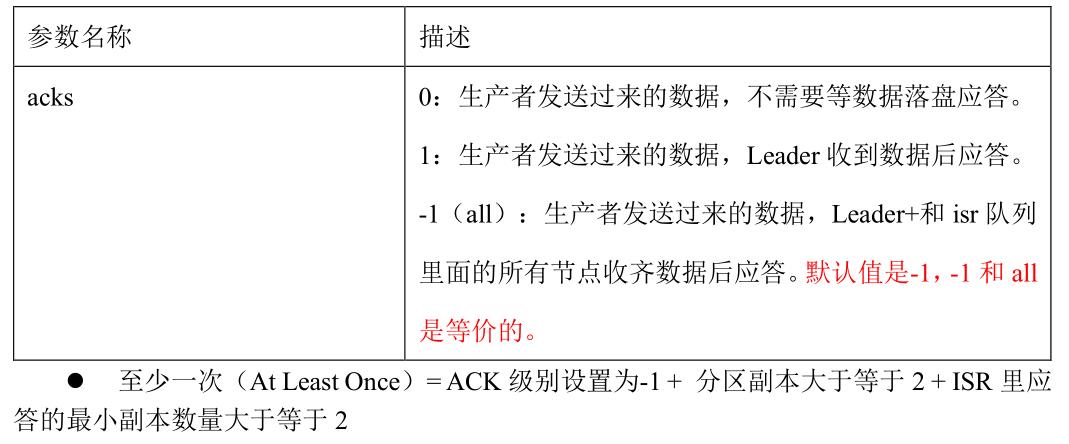
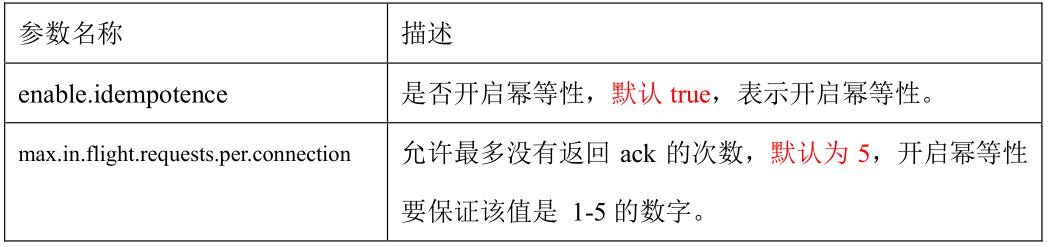
4、数据去重


5、数据有序
单分区内,有序(有条件的,不能乱序);
多分区,分区与分区间无序;
6、数据 乱序
三、Kafka Broker
1、Broker 核心参数配置


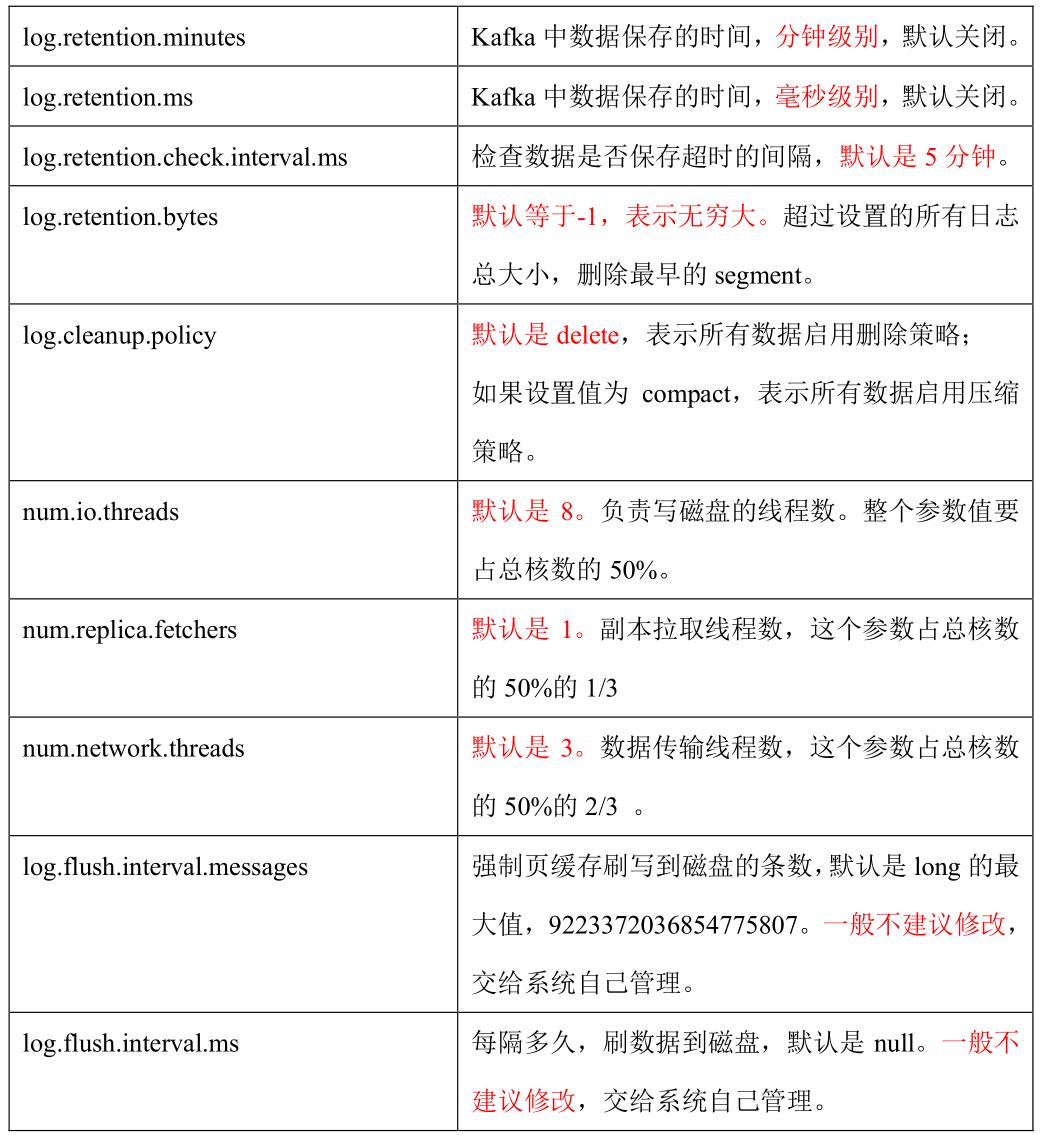
2、服役新节点/ 退役旧节点
(1)创建一个要均衡的主题。
[atguigu@hadoop102 kafka]$ vim topics-to-move.json
"topics": [
"topic": "first"
],
"version": 1
(2)生成一个负载均衡的计划。
bin/kafka-reassign-partitions.sh --bootstrap-server hadoop102:9092 --topics-to-move-json-file topics-to-move.json --broker-list "0,1,2,3" --generate
(3)创建副本存储计划(所有副本存储在 broker0、broker1、broker2、broker3 中)。
vim increase-replication-factor.json
(4)执行副本存储计划。
bin/kafka-reassign-partitions.sh --bootstrap-server hadoop102:9092 --reassignment-json-file increase-replication-factor.json --execute
(5)验证副本存储计划。
bin/kafka-reassign-partitions.sh --bootstrap-server hadoop102:9092 --reassignment-json-file increase-replication-factor.json --verify
3、增加分区
修改分区数(注意:分区数只能增加,不能减少)
bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --alter --topic first --partitions 3
4、增加副本因子
1)创建 topic
bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --create --partitions 3 --replication-factor 1 --topic four
2)手动增加副本存储

5、手动调整分区副本存储
(1)创建副本存储计划(所有副本都指定存储在 broker0、broker1 中)。
vim increase-replication-factor.json
输入如下内容:
"version":1,
"partitions":["topic":"three","partition":0,"replicas":[0,1],
"topic":"three","partition":1,"replicas":[0,1],
"topic":"three","partition":2,"replicas":[1,0],
"topic":"three","partition":3,"replicas":[1,0]]
(2)执行副本存储计划。
bin/kafka-reassign-partitions.sh --bootstrap-server hadoop102:9092 --reassignment-json-file increase-replication-factor.json --execute
(3)验证副本存储计划。
bin/kafka-reassign-partitions.sh --bootstrap-server hadoop102:9092 --reassignment-json-file increase-replication-factor.json --verify
6、Leader Partition 负载 平衡

7、自动创建主题

1)向一个没有提前创建 five 主题发送数据
bin/kafka-console-producer.sh --bootstrap-server hadoop102:9092 --topic five
>hello world
2)查看 five 主题的详情
bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --describe --topic five
四、 Kafka 消费者
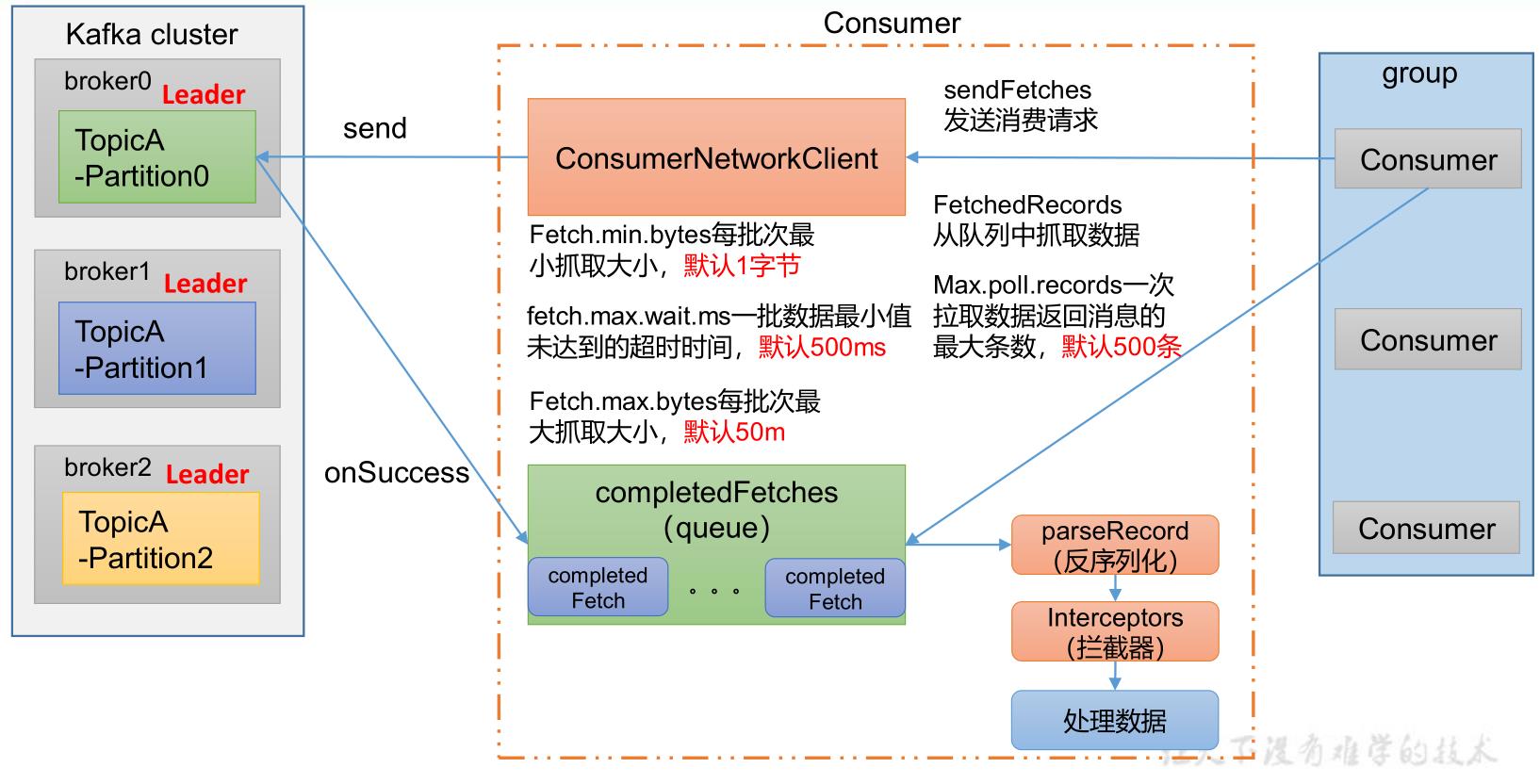
1、Kafka 消费者核心参数配置
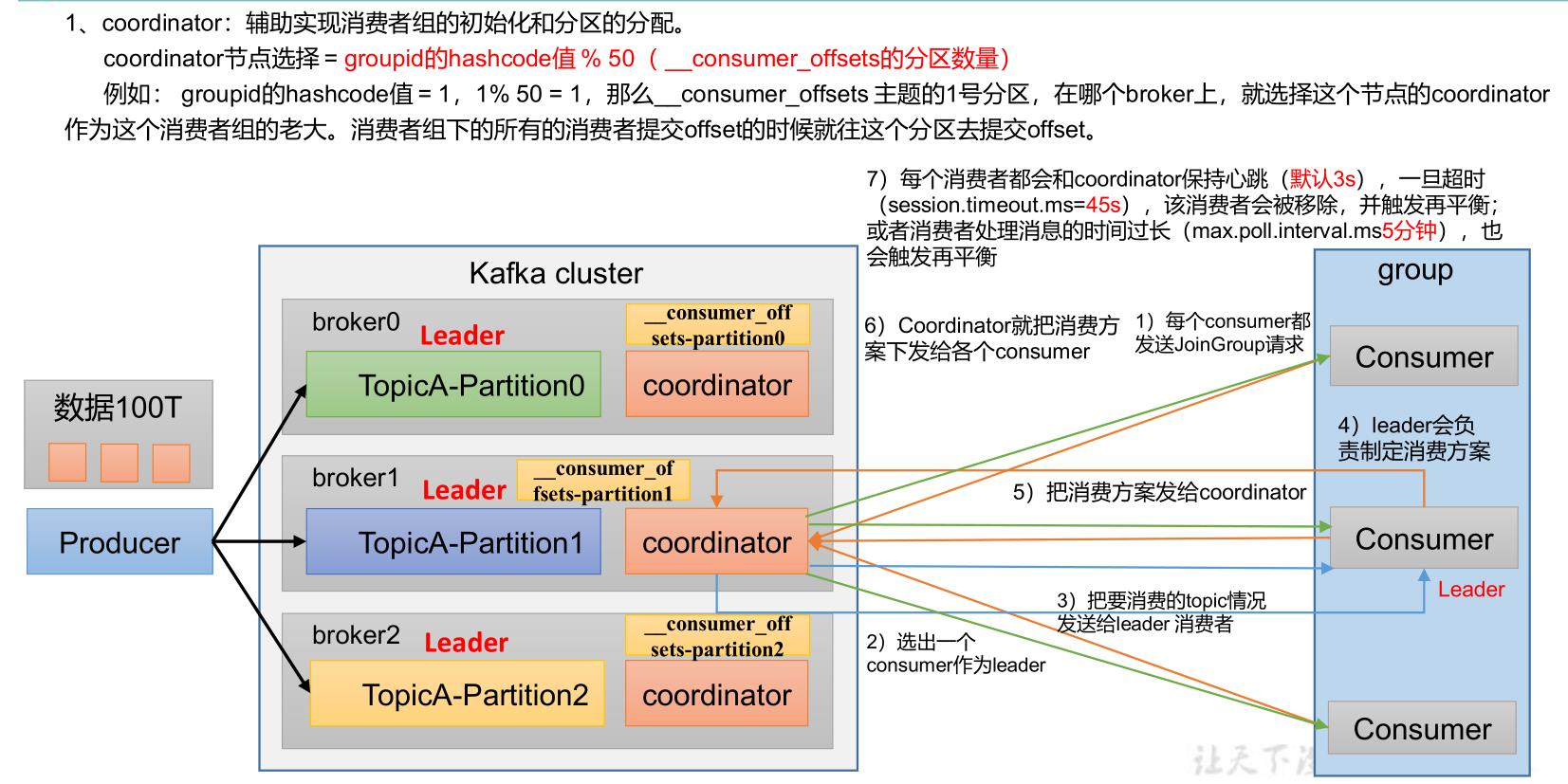



2、消费者再平衡
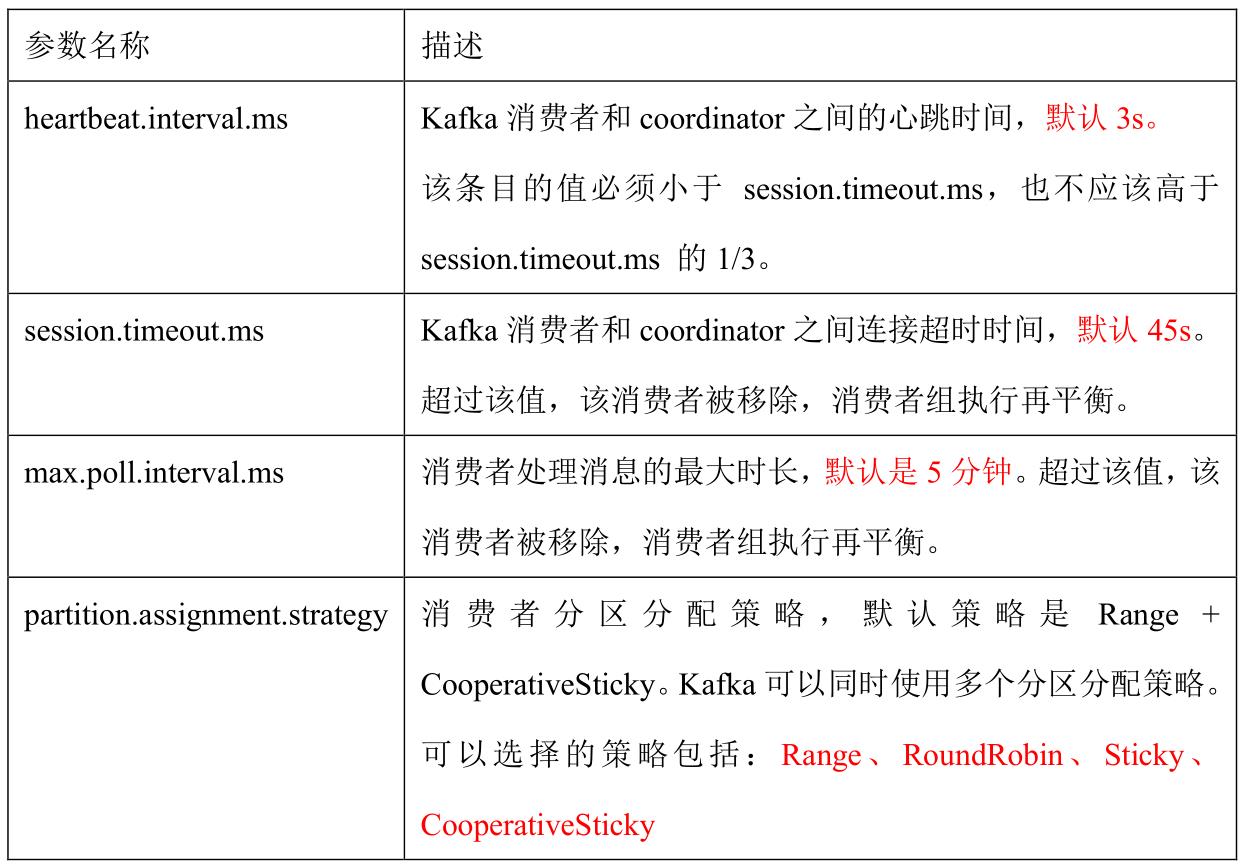
3、指定 Offset 消费
kafkaConsumer.seek(topic, 1000);
4、指定 时间 消费
HashMap<TopicPartition, Long> timestampToSearch = new HashMap<>();
timestampToSearch.put(topicPartition, System.currentTimeMillis() - 1 * 24 * 3600 * 1000);
kafkaConsumer.offsetsForTimes(timestampToSearch);
5、消费者如何提高吞吐量
增加分区数;
bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --alter --topic first --partitions 3

五、Kafka 总体
1、如何提升吞吐量

2、数据精准一次
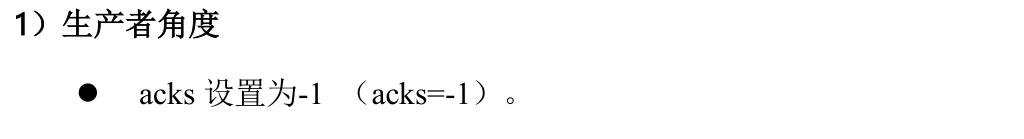

3、合理设置 分区数

4、单条日志大于 1m
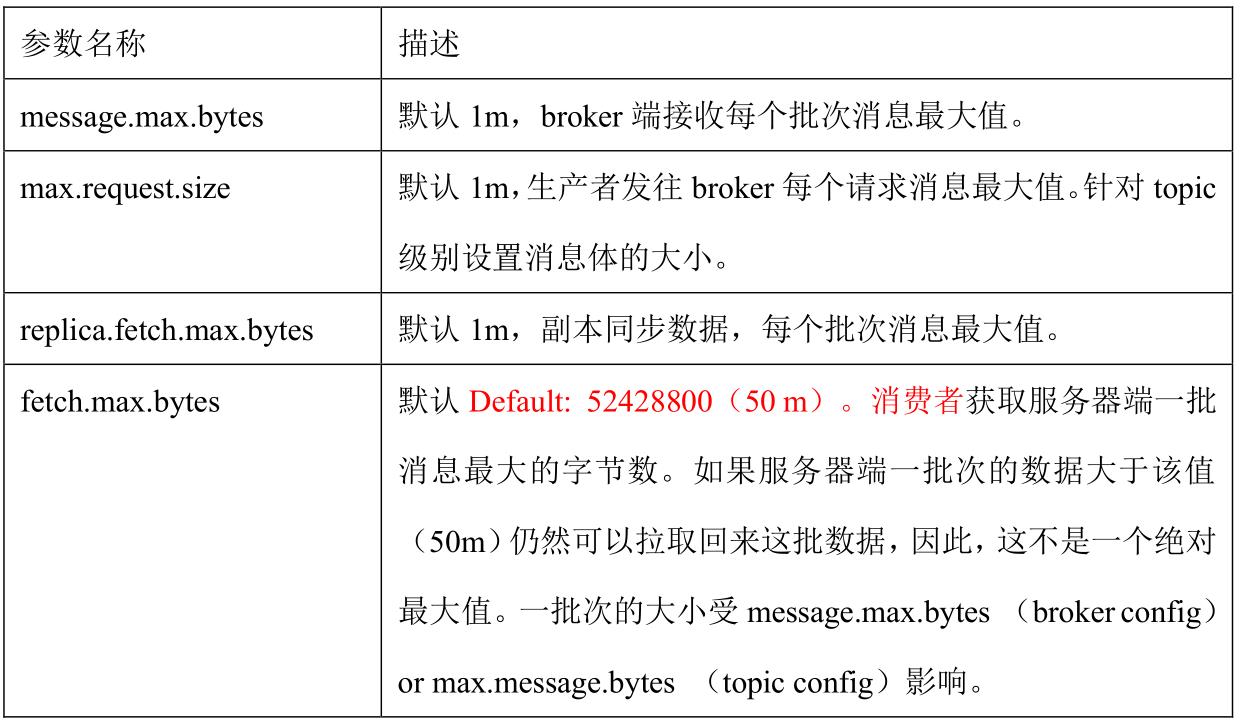
5、服务器挂了

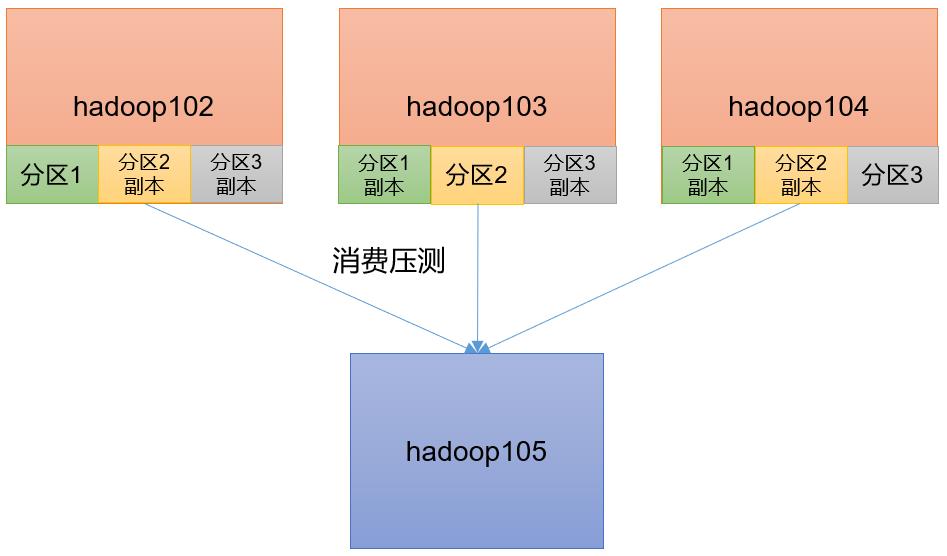
6、集群压力测试
1 )Kafka 压测
用 Kafka 官方自带的脚本,对 Kafka 进行压测。
⚫ 生产者压测:kafka-producer-perf-test.sh
⚫ 消费者压测:kafka-consumer-perf-test.sh
2 )Kafka Producer 压力测试
创建一个 test topic,设置为 3 个分区 3 个副本
bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --create --replication-factor 3 --partitions 3 --topic test
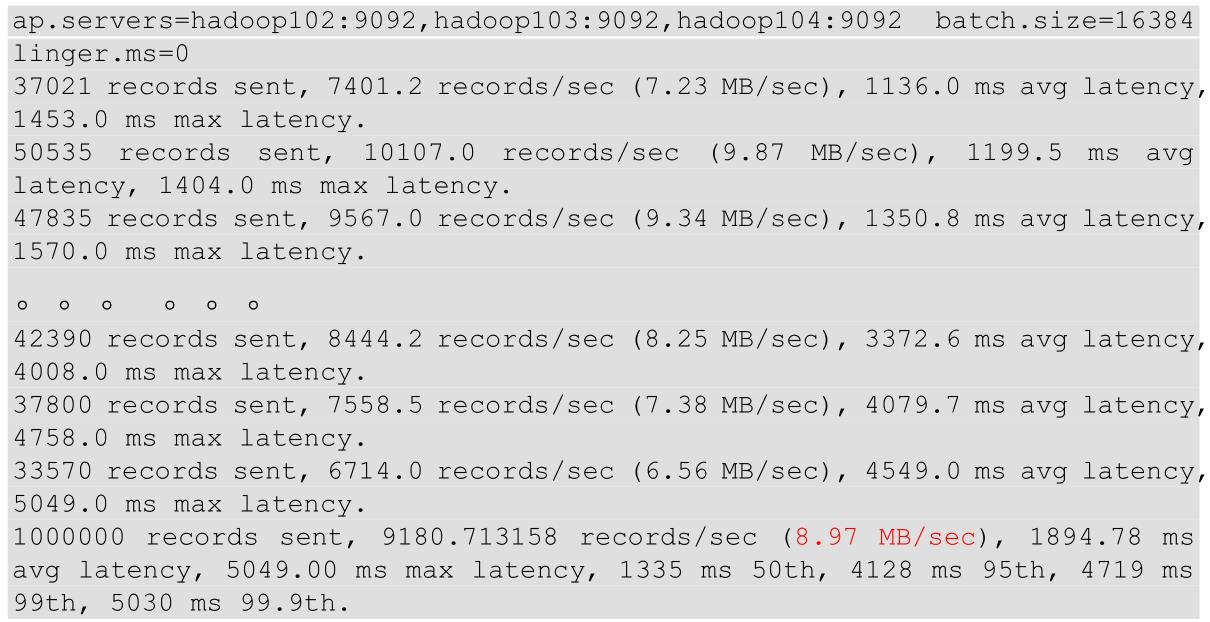
在/opt/module/kafka/bin 目录下面有这两个文件。我们来测试一下
bin/kafka-producer-perf-test.sh --topic test --record-size 1024 --num-records 1000000 --throughput 10000 --producer-props bootstrap.servers=hadoop102:9092,hadoop103:9092,hadoop104:9092 batch.size=16384 linger.ms=0
参数说明:

输出结果:
(3)调整 batch.size 大小
①batch.size 默认值是 16k。本次实验 batch.size 设置为32k。
bin/kafka-producer-perf-test.sh --topic test --record-size 1024 --num-records 1000000 --throughput 10000 --producer-props bootstrap.servers=hadoop102:9092,hadoop103:9092,hadoop104:9092 batch.size=32768 linger.ms=0
输出结果:

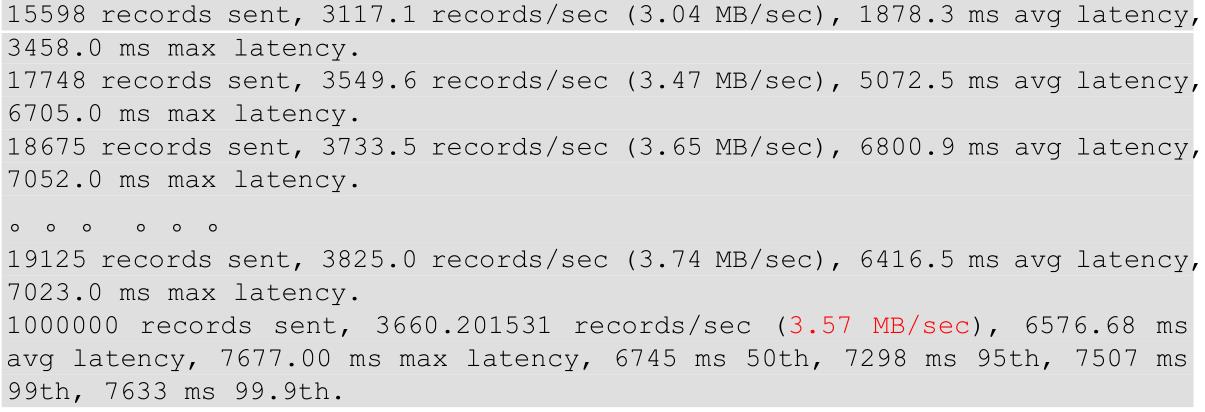
②batch.size 默认值是 16k。本次实验 batch.size 设置为 4k。
bin/kafka-producer-perf-test.sh -- topic test --record-size 1024 --num-records 1000000 --throughput 10000
bootstrap.servers=hadoop102:9092,hadoop103:9092,hadoop104:9092 batch.size=4096 linger.ms=0
输出结果:
(4)调整 linger.ms 时间
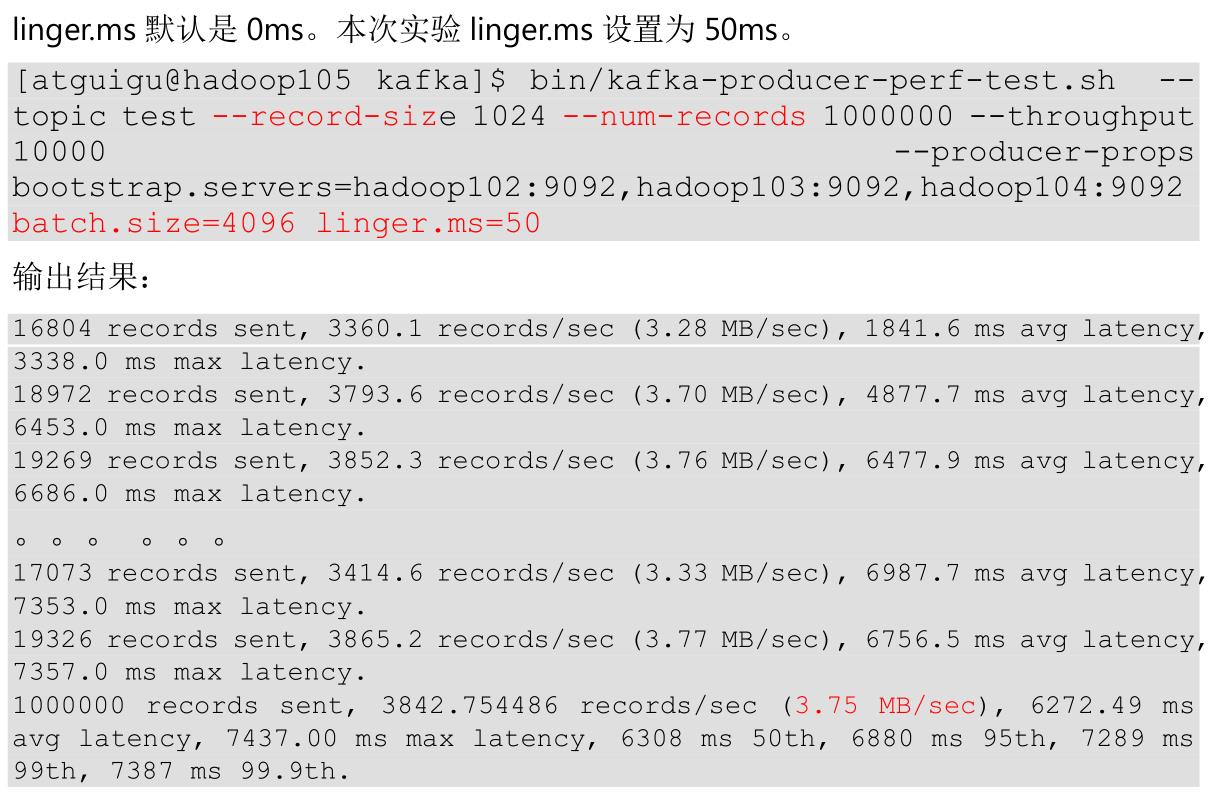
(5)调整压缩方式
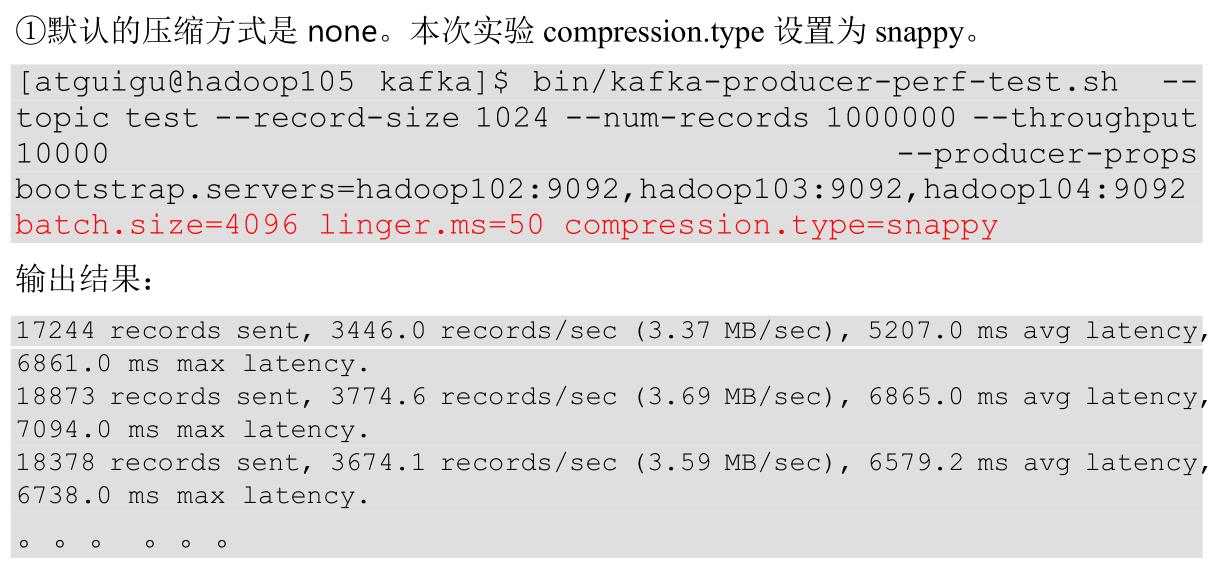


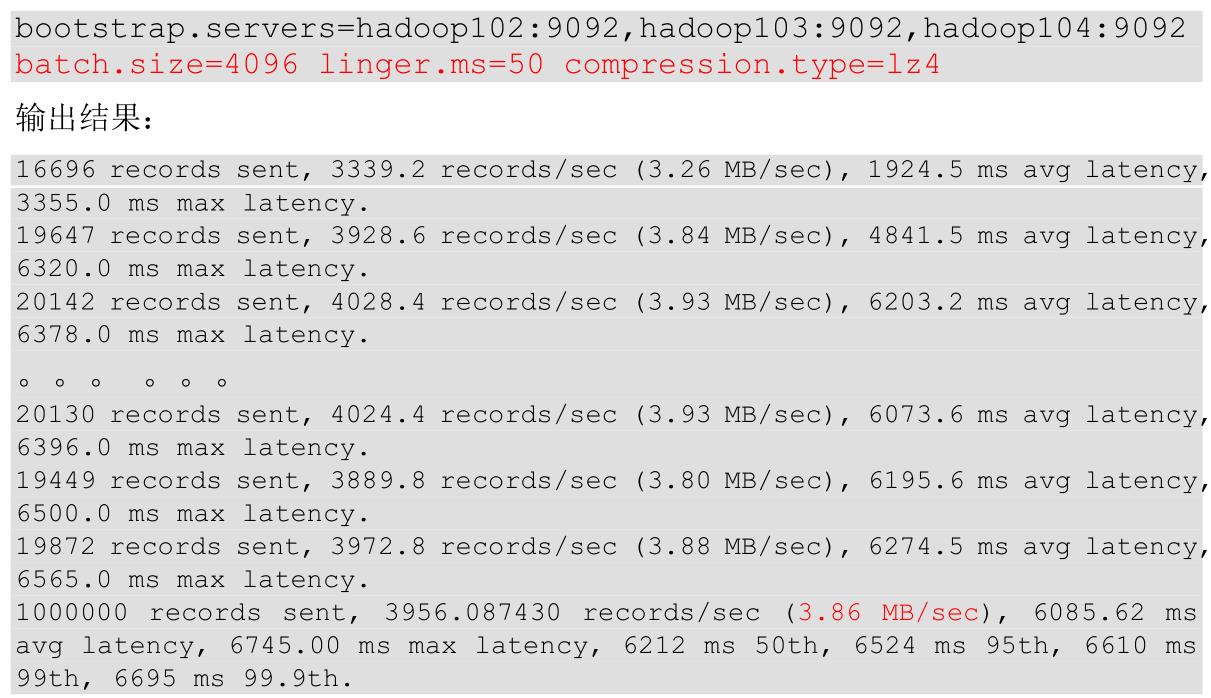
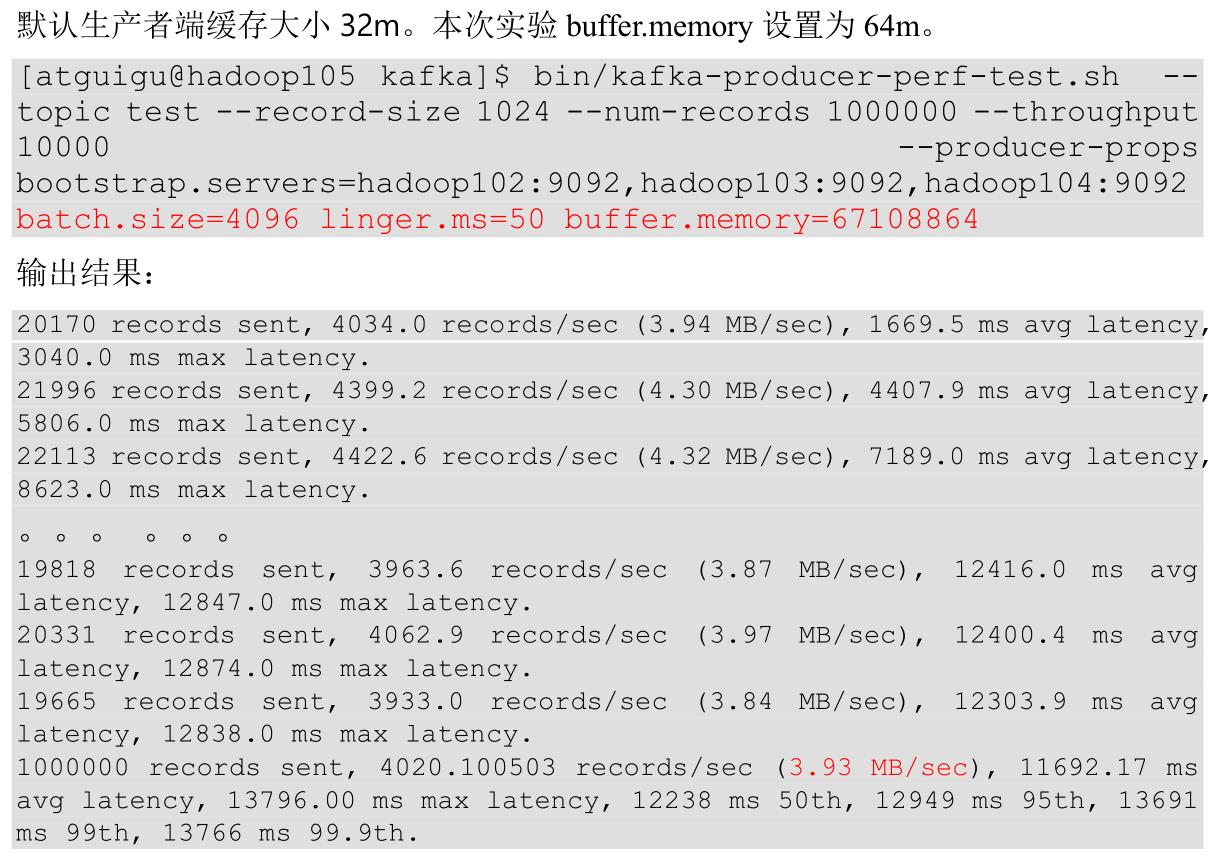
(6)调整缓存大小
3 )Kafka Consumer 压力测试

参数说明:

(3)一次拉取条数为 2000

(4)调整 fetch.max.bytes 大小为 100m

以上是关于Day549.kafka生产调优手册 -kafka的主要内容,如果未能解决你的问题,请参考以下文章