数据治理:Atlas集成Hive
Posted Lansonli
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据治理:Atlas集成Hive相关的知识,希望对你有一定的参考价值。
目录
三、 复制$ATLAS_HOME/conf/atlas-application.properties文件到$HIVE_HOME/conf下,并追加内容
Atlas集成Hive
Atlas可以针对多个不同的数据源,统一采用kafka作为中间消息传递队列,使元数据源与服务端采用异步方式进行沟通,减少元数据采集对正常业务效率的影响,但是目前的Atlas版本监控Hive中数据操作比较完善,但是监控Sqoo(目前只支持hive import)、Spark等支持不好。
我们可以使用Atlas监控Hive中的元数据,这时需要配置Hive Hook(钩子),在Hive中做的任何操作,都会被钩子所感应到,并以事件的形式发布到kafka,然后,Atlas的Ingest模块会消费到Kafka中的消息,并解析生成相应的Atlas元数据写入底层的Janus图数据库来存储管理,其原理如下图示:
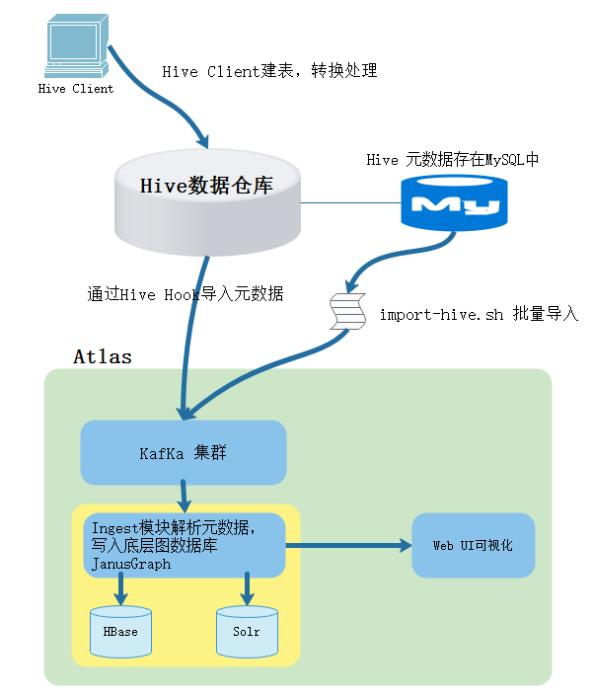
atlas安装之前,hive中已存在的表,钩子是不会自动感应并生成相关元数据的,可以通过atlas的工具脚本来对已存在的hive库或表进行元数据导入,步骤如下:
一、配置hive-site.xml
在node3 Hive客户端$HIVE_HOME/conf/hive-site.xml中追加写入:
<!-- 配置hook 钩子类 -->
<property>
<name>hive.exec.post.hooks</name>
<value>org.apache.atlas.hive.hook.HiveHook</value>
</property>二、修改Hive-env.sh
[root@node3 ~]# cd /software/hive-3.1.2/conf
[root@node3 conf]# cp hive-env.sh.template hive-env.sh
[root@node3 conf]# vim hive-env.sh
export HIVE_AUX_JARS_PATH=/software/apache-atlas-2.1.0/hook/hive/三、 复制$ATLAS_HOME/conf/atlas-application.properties文件到$HIVE_HOME/conf下,并追加内容
#复制atlas-application.properties文件到$HIVE_HOME/conf下
[root@node3 ~]# cp /software/apache-atlas-2.1.0/conf/atlas-application.properties /software/hive-3.1.2/conf/四、复制导入Hive元数据必须的jar包
[root@node3 ~]# cp /software/apache-atlas-2.1.0/server/webapp/atlas/WEB-INF/lib/jackson-jaxrs-base-2.9.9.jar /software/apache-atlas-2.1.0/hook/hive/atlas-hive-plugin-impl/
[root@node3 ~]# cp /software/apache-atlas-2.1.0/server/webapp/atlas/WEB-INF/lib/jackson-jaxrs-json-provider-2.9.9.jar /software/apache-atlas-2.1.0/hook/hive/atlas-hive-plugin-impl/
[root@node3 ~]# cp /software/apache-atlas-2.1.0/server/webapp/atlas/WEB-INF/lib/jackson-module-jaxb-annotations-2.9.9.jar /software/apache-atlas-2.1.0/hook/hive/atlas-hive-plugin-impl/五、执行同步Hive 元数据脚本
#这里同步的是Hive中已有数据的元数据,可以通过此脚本同步过来
[root@node3 ~]# cd /software/apache-atlas-2.1.0/bin/
#执行脚本导入元数据,期间需要输入atlas的用户名和密码:admin/admin
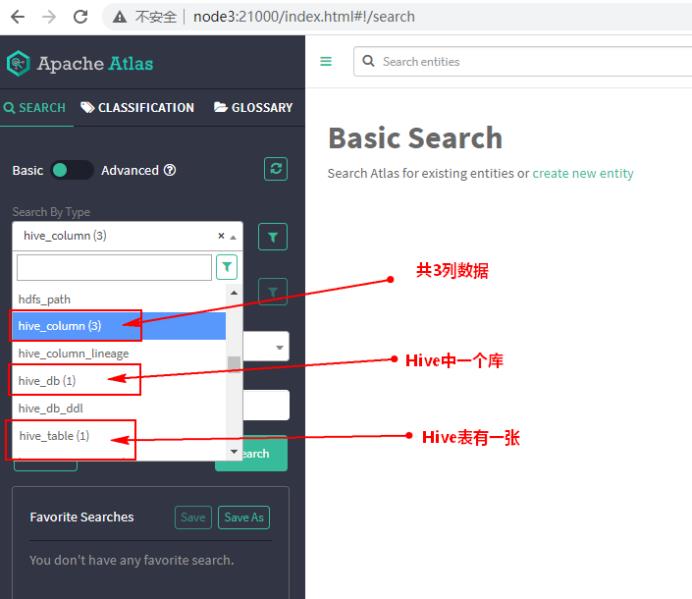
[root@node3 bin]# import-hive.sh 六、以上导入元数据成功后,可以在Atlas页面中查看
七、在Hive中创建数据表,查看是否能被Atlas监控
hive> create table personinfo(id int ,name string,age int) row format delimited fields terminated by '\\t';
#需要准备 person.txt文件
hive> load data local inpath '/root/test/person.txt' into table personinfo;
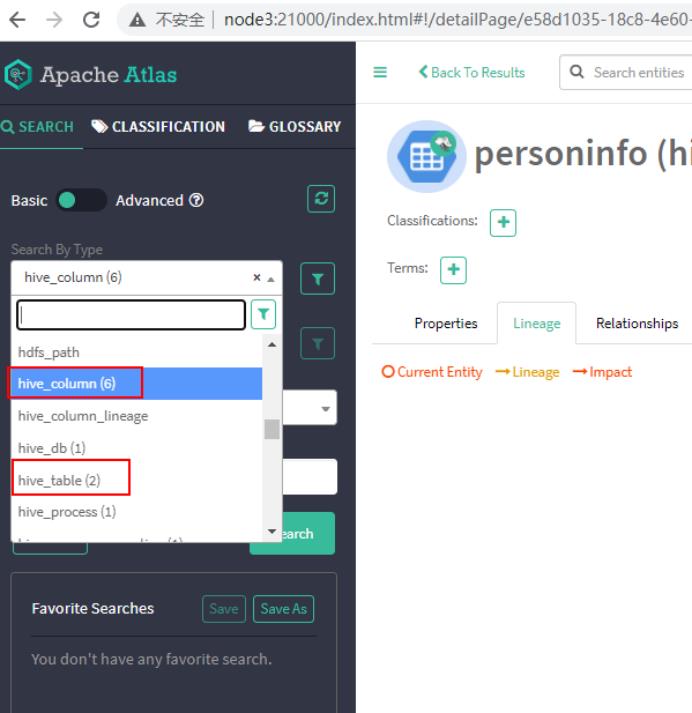
八、刷新Atlas页面,可以看到数据被同步
- 📢博客主页:https://lansonli.blog.csdn.net
- 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
- 📢本文由 Lansonli 原创,首发于 CSDN博客🙉
- 📢大数据系列文章会每天更新,停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨
以上是关于数据治理:Atlas集成Hive的主要内容,如果未能解决你的问题,请参考以下文章