Atlas部署并集成HIVE
Posted 小基基o_O
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Atlas部署并集成HIVE相关的知识,希望对你有一定的参考价值。
文章目录
- 01、概述
- 02、集群规划、版本、环境变量
- 03、Solr集群部署
- 04、安装Atlas服务
- 05、配置Atlas存储到外部HBase
- 06、Atlas集成Solr
- 07、Atlas集成Kafka
- 08、Atlas集成Hive
- 09、启动Atlas
- 10、Hive元数据初次导入
- 11、Atlas服务密码修改
- 12、附录
01、概述
- Atlas:提供元数据管理和治理的服务
企业可以对 自己Hadoop生态的数据资产 构建目录,进行分类和治理 - 主要功能:元数据分类、元数据检索、血缘依赖(表到表、字段到字段)
官网:https://atlas.apache.org
Atlas架构图(待补充)
atlas服务、图(边、节点、节点注释)、solr、Kafka、HIVE、hook……

02、集群规划、版本、环境变量
-
Atlas自带的HBase、Solr等,本文是集成外部的,预装JDK、Zookeeper、Kafka、HBase、Hive
-
集群规划
https://yellow520.blog.csdn.net/article/details/115536550 -
环境变量
https://blog.csdn.net/Yellow_python/article/details/112692486
03、Solr集群部署
- Apache SolrTM是 建立在Apache LuceneTM之上的 开源的企业搜索平台
- 在此处,Solr的作用是:加快元数据的搜索
- 下载地址:https://solr.apache.org/
在每个节点创建名为Solr的系统用户
useradd solr
echo solr | passwd --stdin solr
解压、修改户主
tar -zxvf solr-7.7.3.tgz
mv solr-7.7.3 solr
chown -R solr:solr solr
mv solr $B_HOME/solr
修改配置文件
vim $B_HOME/solr/bin/solr.in.sh
ZK_HOST="hadoop102:2181,hadoop103:2181,hadoop104:2181"
分发到每个节点
rsync.py $B_HOME/solr
在每个节点,使用solr用户来启动Solr(前提是ZooKeeper在运行)
sudo -i -u solr $B_HOME/solr/bin/solr start
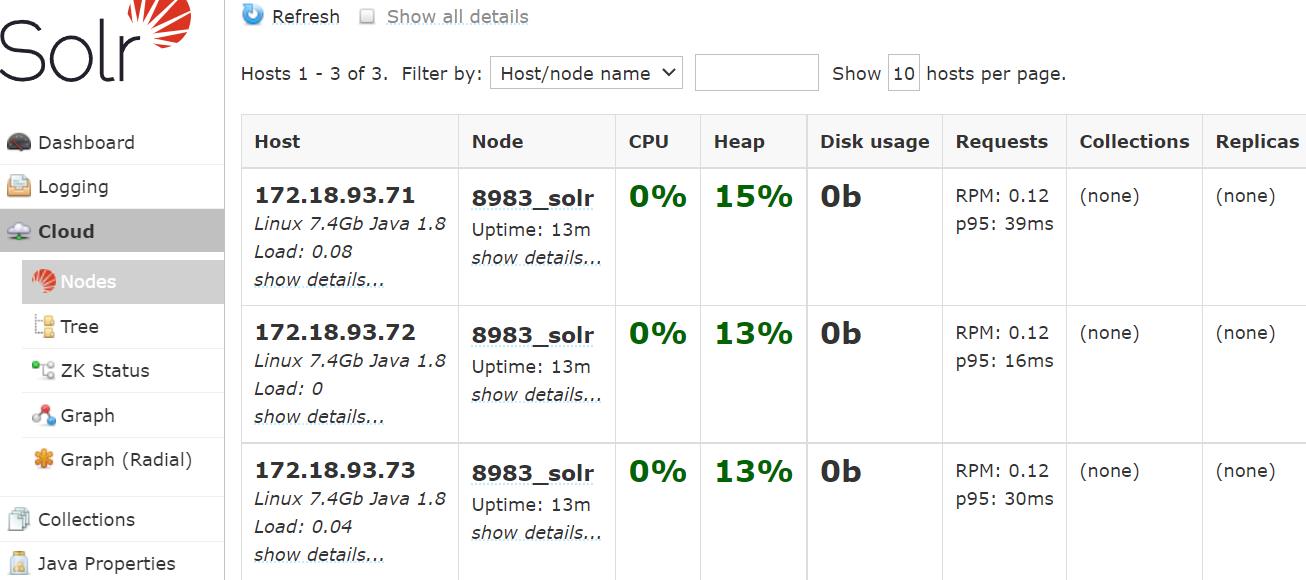
Web端口为8983,任意节点都可
注意Cloud菜单栏
关闭Solr的命令(每台机执行)
sudo -i -u solr $B_HOME/solr/bin/solr stop
04、安装Atlas服务
下载编译好的Atlas:
https://download.csdn.net/download/Yellow_python/79106345
解压、改名
tar -zxvf apache-atlas-2.1.0-server.tar.gz
mv apache-atlas-2.1.0 $ATLAS_HOME
配置
vim $ATLAS_HOME/conf/atlas-application.properties
######### Server Properties #########
atlas.rest.address=http://hadoop102:21000
# If enabled and set to true, this will run setup steps when the server starts
atlas.server.run.setup.on.start=false
######### Entity Audit Configs #########
atlas.audit.hbase.zookeeper.quorum=hadoop102:2181,hadoop103:2181,hadoop104:2181
05、配置Atlas存储到外部HBase
修改图的存储地址(Zookeeper地址,HBase集群依赖ZooKeeper)
vim $ATLAS_HOME/conf/atlas-application.properties
atlas.graph.storage.hostname=hadoop102:2181,hadoop103:2181,hadoop104:2181
告诉Atlas,外部HBase配置的路径
vim $ATLAS_HOME/conf/atlas-env.sh
export HBASE_CONF_DIR=$HBASE_HOME/conf
06、Atlas集成Solr
vim $ATLAS_HOME/conf/atlas-application.properties
atlas.graph.index.search.backend=solr
atlas.graph.index.search.solr.mode=cloud
atlas.graph.index.search.solr.zookeeper-url=hadoop102:2181,hadoop103:2181,hadoop104:2181
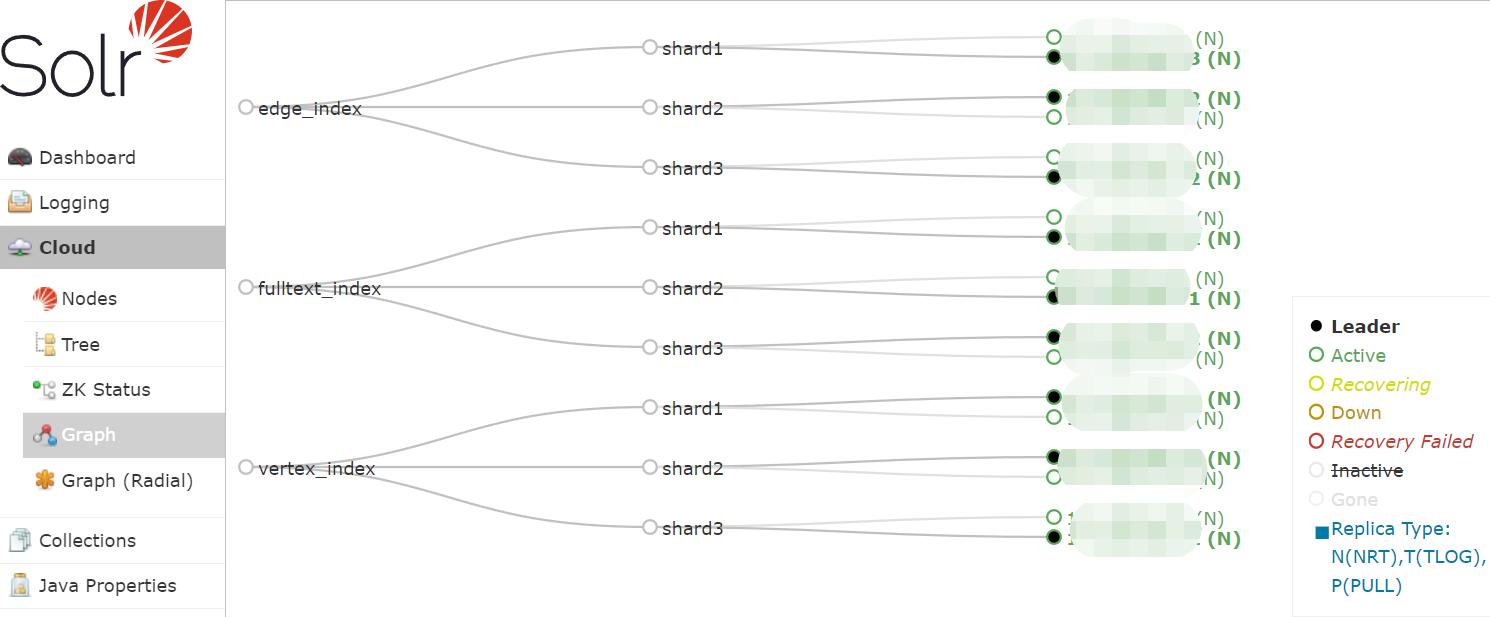
Solr创建collection(图的 顶点、边、全文)
sudo -i -u solr $B_HOME/solr/bin/solr create -c vertex_index -d $ATLAS_HOME/conf/solr -shards 3 -replicationFactor 2
sudo -i -u solr $B_HOME/solr/bin/solr create -c edge_index -d $ATLAS_HOME/conf/solr -shards 3 -replicationFactor 2
sudo -i -u solr $B_HOME/solr/bin/solr create -c fulltext_index -d $ATLAS_HOME/conf/solr -shards 3 -replicationFactor 2
创建后
07、Atlas集成Kafka
vim $ATLAS_HOME/conf/atlas-application.properties
atlas.kafka.data=Kafka数据存放位置
atlas.notification.embedded=false
atlas.kafka.data=/opt/module/kafka/data
atlas.kafka.zookeeper.connect=hadoop102:2181,hadoop103:2181,hadoop104:2181/kafka
atlas.kafka.bootstrap.servers=hadoop102:9092,hadoop103:9092,hadoop104:9092
08、Atlas集成Hive
解压hook
tar -zxvf apache-atlas-2.1.0-hive-hook.tar.gz
把hook复制到Atlas安装路径
cp -r apache-atlas-hive-hook-2.1.0/* $ATLAS_HOME/
HIVE环境添加HIVE-hook的jar路径
cd $HIVE_HOME/conf
mv hive-env.sh.template hive-env.sh
vim hive-env.sh
export HIVE_AUX_JARS_PATH=$ATLAS_HOME/hook/hive
HIVE配置添加Hook
vim $HIVE_HOME/conf/hive-site.xml
<property>
<name>hive.exec.post.hooks</name>
<value>org.apache.atlas.hive.hook.HiveHook</value>
</property>
加入Atlas的HIVE-Hook配置
vim $ATLAS_HOME/conf/atlas-application.properties
######### HIVE Hook Configs #######
atlas.hook.hive.synchronous=false
atlas.hook.hive.numRetries=3
atlas.hook.hive.queueSize=10000
atlas.cluster.name=primary
将Atlas配置文件atlas-application.properties拷贝到HIVE
cp $ATLAS_HOME/conf/atlas-application.properties $HIVE_HOME/conf/
09、启动Atlas
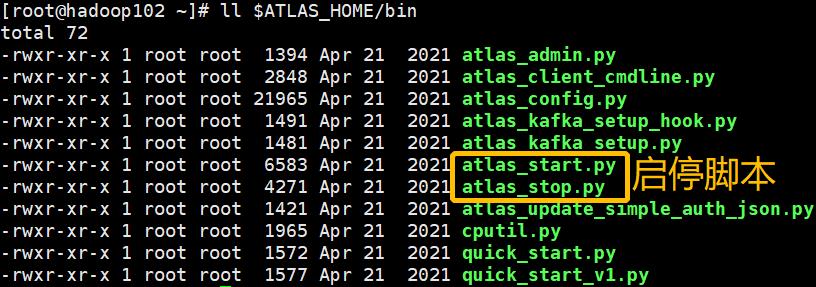
$ATLAS_HOME/bin/atlas_start.py
浏览器访问
hadoop102:21000
端口:21000
账号:admin
密码:admin

10、Hive元数据初次导入
$ATLAS_HOME/hook-bin/import-hive.sh
输入用户名和密码admin
11、Atlas服务密码修改
Atlas配置里,有个用户凭证
cd $ATLAS_HOME/conf
cat users-credentials.properties
文件原本内容如下
#username=group::sha256-password
admin=ADMIN::a4a88c0872bf652bb9ed803ece5fd6e82354838a9bf59ab4babb1dab322154e1
rangertagsync=RANGER_TAG_SYNC::0afe7a1968b07d4c3ff4ed8c2d809a32ffea706c66cd795ead9048e81cfaf034
admin=ADMIN::后面是SHA256算法加密后的密文
把密码修改为123456的方法如下:
1、生成密文
echo -n 123456 | sha256sum

2、替换ADMIN::后面的密文,可直接在原文件上替换,本文是复制一个新文件
cp users-credentials.properties users-credentials-2.properties
vim users-credentials-2.properties
admin=ADMIN::8d969eef6ecad3c29a3a629280e686cf0c3f5d5a86aff3ca12020c923adc6c92
3、修改atlas-application.properties中的身份验证
(如果密文是直接在users-credentials.properties上替换,则省略此步)
vim $ATLAS_HOME/conf/atlas-application.properties
atlas.authentication.method.file=true
atlas.authentication.method.file.filename=$sys:atlas.home/conf/users-credentials-2.properties
4、重启Atlas
$ATLAS_HOME/bin/atlas_stop.py
$ATLAS_HOME/bin/atlas_start.py
12、附录
| en | 🔉 | cn |
|---|---|---|
| atlas | ˈætləs | n. 地图册;第一颈椎 |
| hook | hʊk | n. 钩 |
| backend | 'bæk,ɛnd | n. 后端 |
| vertex | ˈvɜːrteks | n. 顶点 |
| synchronous | ˈsɪŋkrənəs | adj. 同步的;同时的 |
| embedded | ɪmˈbedɪd | adj. 嵌入(或插入、埋入)……之中的;v. 使嵌入 |
| SHA | Secure Hash Algorithm | 安全散列算法 |
| credential | krəˈdenʃl | n. 资格;文凭;v. 给……提供证书 |
血缘展示样例
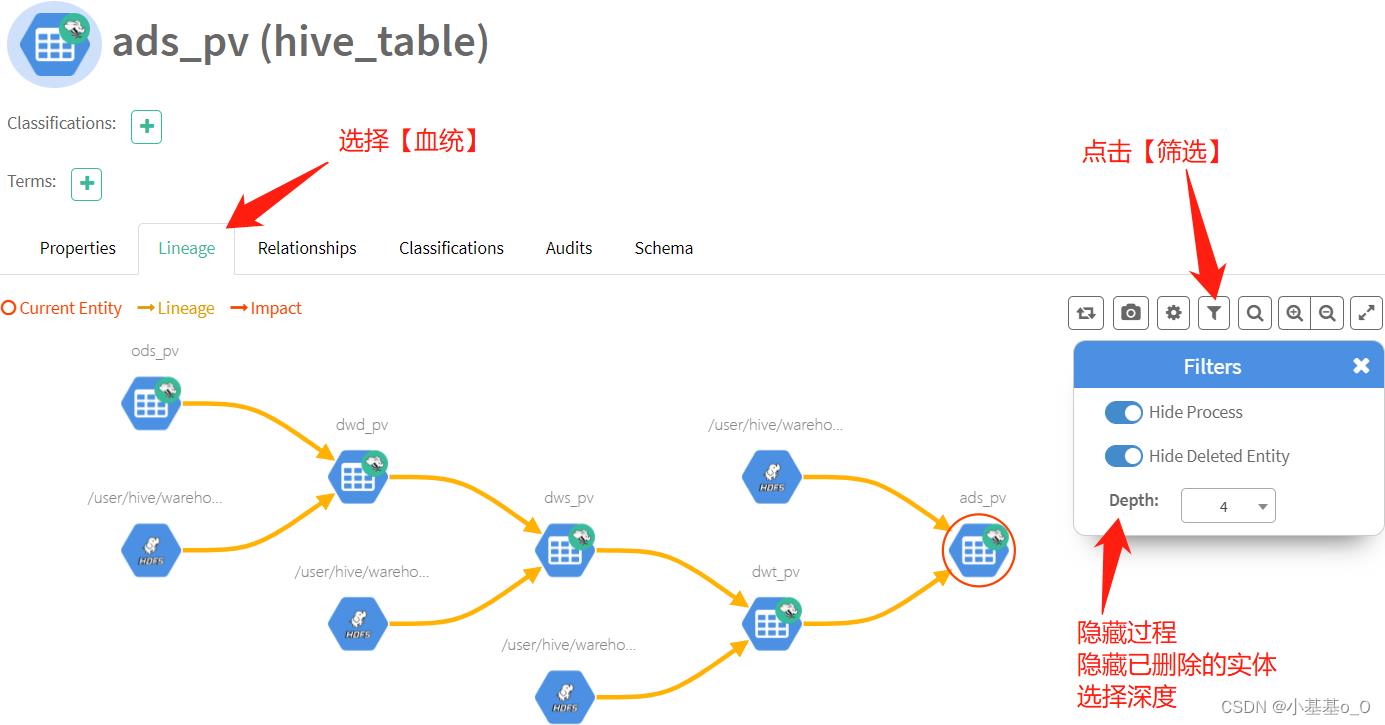
以上是关于Atlas部署并集成HIVE的主要内容,如果未能解决你的问题,请参考以下文章