FLinkFlink SQL代码生成与UDF重复调用的优化
Posted 九师兄
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了FLinkFlink SQL代码生成与UDF重复调用的优化相关的知识,希望对你有一定的参考价值。

1.概述
2. 代码生成简介
代码生成(code generation)是当今各种数据库和数据处理引擎广泛采用的物理执行层技术之一。通过代码生成,可以将原本需要解释执行的算子逻辑转为编译执行(二进制代码),充分利用JIT编译的优势,克服传统Volcano模型虚函数调用过多、对寄存器不友好的缺点,在CPU-bound场景下可以获得大幅的性能提升。
在大数据领域,看官最为熟知的代码生成应用可能就是Spark 2.x的全阶段代码生成(whole-stage code generation)机制,它也是笔者两年前介绍过的Tungsten Project的一部分。以常见的FILTER -> JOIN -> AGGREGATE流程为例,全阶段代码生成只需2个Stage,而传统Volcano模型则需要9次虚函数调用,如下图所示。
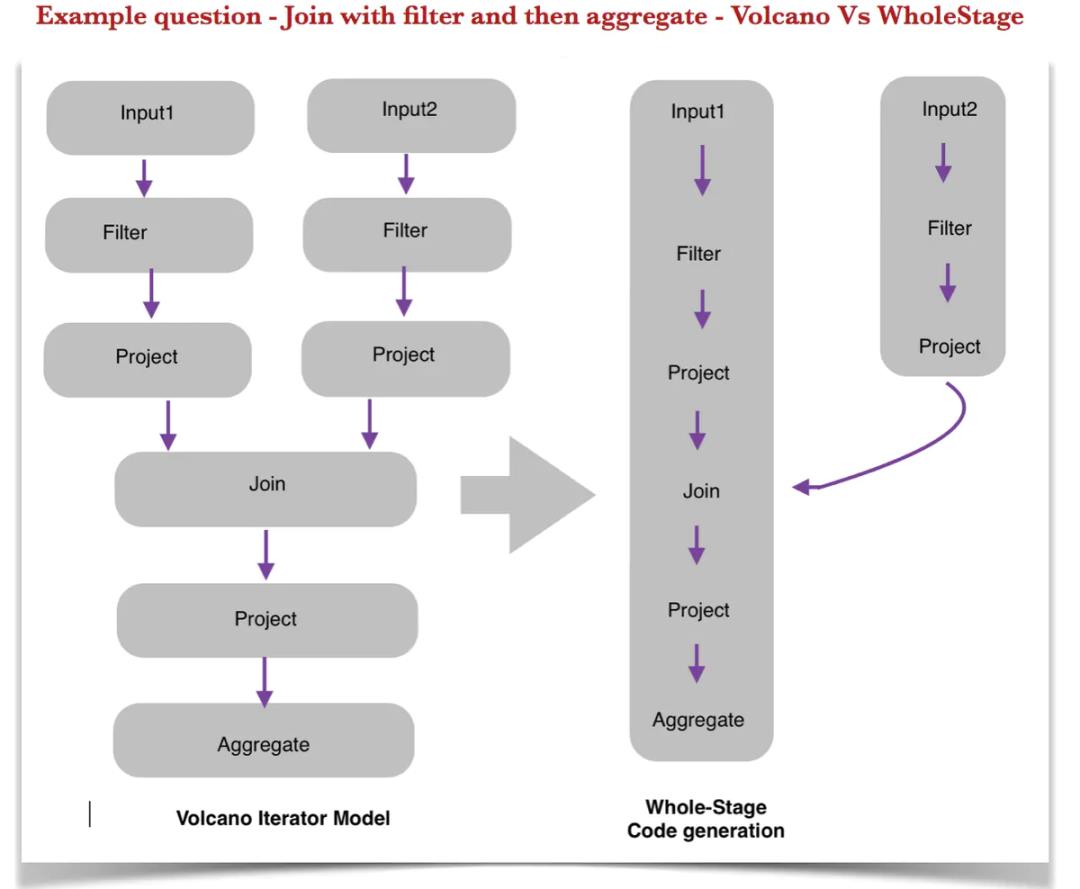
关于Spark的代码生成,可以参考其源码或DataBricks的说明文章,不再赘述。而Flink作为后起之秀,在Flink SQL (Blink Planner)中也采用了类似的思路。本文就来做个quick tour,并提出一个小而有用的优化。
3.Flink SQL Codegen三要素
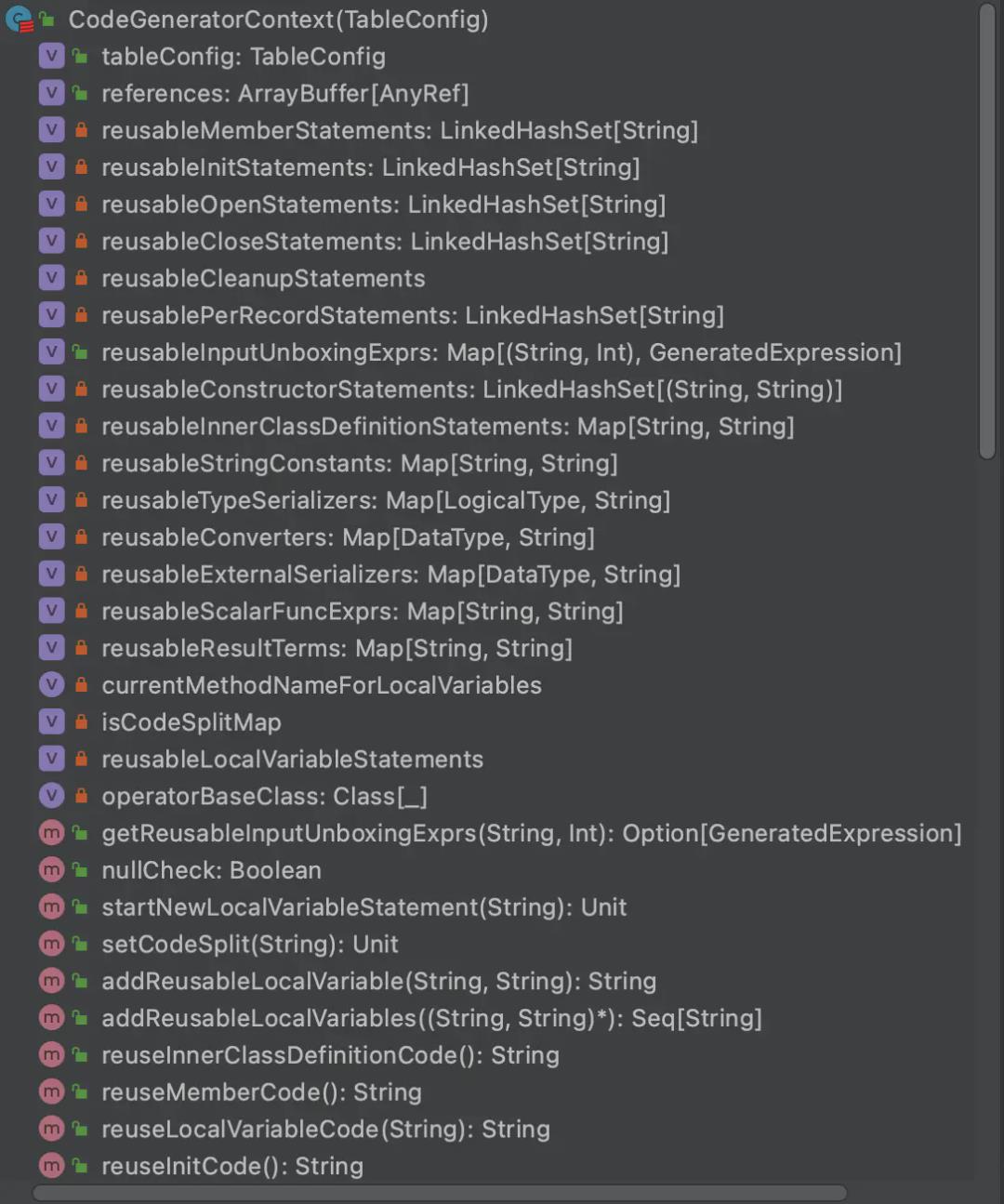
3.1 CodeGeneratorContext
顾名思义,CodeGeneratorContext就是代码生成器的上下文,且同一个CodeGeneratorContext实例在相互有关联的代码生成器之间可以共享。它的作用就是维护代码生成过程中的各种能够重复使用的逻辑,包括且不限于:
对象引用
构造代码、初始化代码
常量、成员变量、局部变量、时间变量
函数体(即Flink Function)及其配套(open()/close()等等)
类型序列化器
etc.
具体代码暂时不贴,以下是该类的部分结构。
3.2 CodeGenerator
Blink Planner的代码生成器并没有统一的基类。它们的共同点就是类名大多以CodeGenerator为后缀,并且绝大多数都要与CodeGeneratorContext打交道。它们的类名也都比较self-explanatory,如下图所示。注意笔者使用的是Flink 1.13版本,所以其中还混杂着少量Old Planner的内容,可以无视之。

挑选几个在流计算场景下比较重点的,稍微解释一下。
AggsHandlerCodeGenerator——负责生成普通聚合函数
AggsHandleFunction与带命名空间(即窗口语义)的聚合函数NamespaceAggsHandleFunction。注意它们与DataStream API中的聚合函数AggregateFunction不是一回事,但大致遵循同样的规范。
CollectorCodeGenerator——负责生成Collector,即算子内将流数据向下游发射的组件。看官用过DataStream API的话会很熟悉。
ExprCodeGenerator——负责根据Calcite RexNode生成各类表达式,Planner内部用GeneratedExpression来表示。由于RexNode很多变(字面量、变量、函数调用等等),它巧妙地利用了RexVisitor通过访问者模式来将不同类型的RexNode翻译成对应的代码。
FunctionCodeGenerator——负责根据SQL逻辑生成各类函数,目前支持的有RichMapFunction、RichFlatMapFunction、RichFlatJoinFunction、RichAsyncFunction和ProcessFunction。
OperatorCodeGenerator——负责生成OneInputStreamOperator和TwoInputStreamOperator。
代码生成器一般会在物理执行节点(即ExecNode)内被调用,但不是所有的Flink SQL逻辑都会直接走代码生成,例如不久前讲过的Window TVF的切片化窗口以及内置的Top-N。
3.3 GeneratedClass
GeneratedClass用来描述代码生成器生成的各类实体,如函数、算子等,它们都位于Runtime层,类图如下。
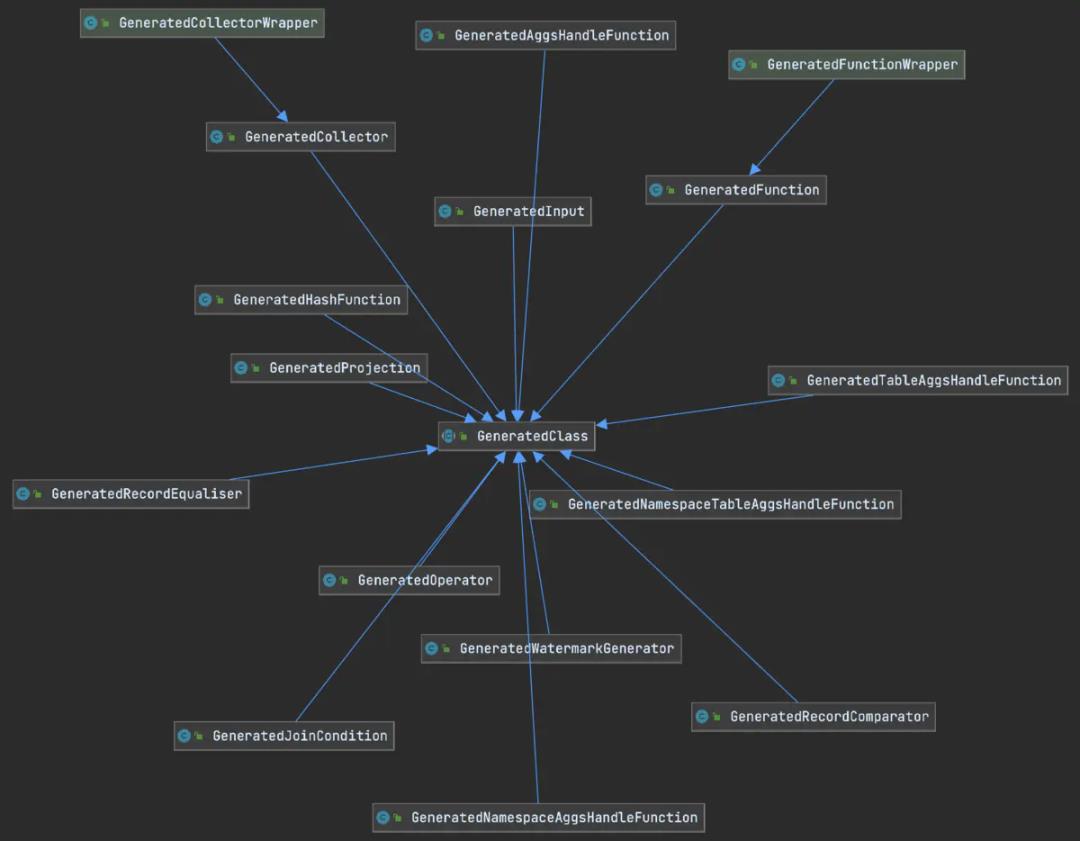
注意这其中并不包括GeneratedExpression,因为表达式的概念仅在Planner层存在。
4.代码生成示例
笔者仅用一条极简的SQL语句
SELECT COUNT(orderId) FROM rtdw_dwd.kafka_order_done_log
WHERE mainSiteId = 10029
来简单走一下流程。
观察该语句生成的物理执行计划:
== Optimized Execution Plan ==
GroupAggregate(select=[COUNT(orderId) AS EXPR$0])
+- Exchange(distribution=[single])
+- Calc(select=[orderId], where=[(mainSiteId = 10029:BIGINT)])
+- TableSourceScan(table=[[hive, rtdw_dwd, kafka_order_done_log]], fields=[ts, tss, tssDay, orderId, /* ... */])
在这四个ExecNode中,StreamExecCalc和StreamExecGroupAggregate会涉及代码生成。篇幅所限,本文只分析StreamExecCalc,它的主要代码由CalcCodeGenerator#generateProcessCode()方法生成,该方法全文如下。
private[flink] def generateProcessCode(
ctx: CodeGeneratorContext,
inputType: RowType,
outRowType: RowType,
outRowClass: Class[_ <: RowData],
projection: Seq[RexNode],
condition: Option[RexNode],
inputTerm: String = CodeGenUtils.DEFAULT_INPUT1_TERM,
collectorTerm: String = CodeGenUtils.DEFAULT_OPERATOR_COLLECTOR_TERM,
eagerInputUnboxingCode: Boolean,
retainHeader: Boolean = false,
outputDirectly: Boolean = false,
allowSplit: Boolean = false): String =
// according to the SQL standard, every table function should also be a scalar function
// but we don't allow that for now
projection.foreach(_.accept(ScalarFunctionsValidator))
condition.foreach(_.accept(ScalarFunctionsValidator))
val exprGenerator = new ExprCodeGenerator(ctx, false)
.bindInput(inputType, inputTerm = inputTerm)
val onlyFilter = projection.lengthCompare(inputType.getFieldCount) == 0 &&
projection.zipWithIndex.forall case (rexNode, index) =>
rexNode.isInstanceOf[RexInputRef] && rexNode.asInstanceOf[RexInputRef].getIndex == index
def produceOutputCode(resultTerm: String): String = if (outputDirectly)
s"$collectorTerm.collect($resultTerm);"
else
s"$OperatorCodeGenerator.generateCollect(resultTerm)"
def produceProjectionCode: String =
val projectionExprs = projection.map(exprGenerator.generateExpression)
val projectionExpression = exprGenerator.generateResultExpression(
projectionExprs,
outRowType,
outRowClass,
allowSplit = allowSplit)
val projectionExpressionCode = projectionExpression.code
val header = if (retainHeader)
s"$projectionExpression.resultTerm.setRowKind($inputTerm.getRowKind());"
else
""
s"""
|$header
|$projectionExpressionCode
|$produceOutputCode(projectionExpression.resultTerm)
|""".stripMargin
if (condition.isEmpty && onlyFilter)
throw new TableException("This calc has no useful projection and no filter. " +
"It should be removed by CalcRemoveRule.")
else if (condition.isEmpty) // only projection
val projectionCode = produceProjectionCode
s"""
|$if (eagerInputUnboxingCode) ctx.reuseInputUnboxingCode() else ""
|$projectionCode
|""".stripMargin
else
val filterCondition = exprGenerator.generateExpression(condition.get)
// only filter
if (onlyFilter)
s"""
|$if (eagerInputUnboxingCode) ctx.reuseInputUnboxingCode() else ""
|$filterCondition.code
|if ($filterCondition.resultTerm)
| $produceOutputCode(inputTerm)
|
|""".stripMargin
else // both filter and projection
val filterInputCode = ctx.reuseInputUnboxingCode()
val filterInputSet = Set(ctx.reusableInputUnboxingExprs.keySet.toSeq: _*)
// if any filter conditions, projection code will enter an new scope
val projectionCode = produceProjectionCode
val projectionInputCode = ctx.reusableInputUnboxingExprs
.filter(entry => !filterInputSet.contains(entry._1))
.values.map(_.code).mkString("\\n")
s"""
|$if (eagerInputUnboxingCode) filterInputCode else ""
|$filterCondition.code
|if ($filterCondition.resultTerm)
| $if (eagerInputUnboxingCode) projectionInputCode else ""
| $projectionCode
|
|""".stripMargin
从中可以看出明显的模拟拼接手写代码的过程。之前讲过,Calc就是Project和Filter的结合,该方法的入参中恰好包含了对应的RexNode:
-
projection——类型为RexInputRef,值为$3,即源表中index为3的列orderId。 -
condition——类型为RexCall,值为=($32, 10029),即mainSiteId = 10029的谓词。
接下来调用ExprCodeGenerator.generateExpression()方法,先生成condition对应的GeneratedExpression。借助访问者模式,会转到ExprCodeGenerator#visitCall()方法,最终生成带空值判断的完整代码。部分调用栈如下:
generateCallWithStmtIfArgsNotNull:98, GenerateUtils$ (org.apache.flink.table.planner.codegen)
generateCallIfArgsNotNull:67, GenerateUtils$ (org.apache.flink.table.planner.codegen)
generateOperatorIfNotNull:2323, ScalarOperatorGens$ (org.apache.flink.table.planner.codegen.calls)
generateComparison:577, ScalarOperatorGens$ (org.apache.flink.table.planner.codegen.calls)
generateEquals:429, ScalarOperatorGens$ (org.apache.flink.table.planner.codegen.calls)
generateCallExpression:630, ExprCodeGenerator (org.apache.flink.table.planner.codegen)
visitCall:529, ExprCodeGenerator (org.apache.flink.table.planner.codegen)
visitCall:56, ExprCodeGenerator (org.apache.flink.table.planner.codegen)
accept:174, RexCall (org.apache.calcite.rex)
generateExpression:155, ExprCodeGenerator (org.apache.flink.table.planner.codegen)
generateProcessCode:173, CalcCodeGenerator$ (org.apache.flink.table.planner.codegen)
generateCalcOperator:50, CalcCodeGenerator$ (org.apache.flink.table.planner.codegen)
generateCalcOperator:-1, CalcCodeGenerator (org.apache.flink.table.planner.codegen)
translateToPlanInternal:94, CommonExecCalc (org.apache.flink.table.planner.plan.nodes.exec.common)
结果如下。其中resultTerm是表达式结果字段,nullTerm是表达式是否为空的boolean字段。后面的编号是内置计数器的值,防止重复。
GeneratedExpression(resultTerm = result$3, nullTerm = isNull$2, code =
isNull$2 = isNull$1 || false;
result$3 = false;
if (!isNull$2)
result$3 = field$1 == ((long) 10029L);
, resultType = BOOLEAN, literalValue = None)
看官可能会觉得生成的代码比较冗长,有些东西没必要写。但是代码生成器的设计目标是兼顾通用性和稳定性,因此必须保证生成的代码在各种情况下都可以正确地运行。另外JVM也可以通过条件编译、公共子表达式消除、方法内联等优化手段生成最优的字节码,不用过于担心。
话说回来,上文中过滤条件的输入filterInputCode是如何通过CodeGeneratorContext#reuseInputUnboxingCode()重用的呢?别忘了$32也是一个RexInputRef,所以递归visit到它时会调用GenerateUtils#generateInputAccess()方法生成对应的代码,即:
isNull$1 = in1.isNullAt(32);
field$1 = -1L;
if (!isNull$1)
field$1 = in1.getLong(32);
将它拼在filterCondition的前面,完成。处理projection的流程类似,看官可套用上面的思路自行追踪,不再废话了。
主处理逻辑生成之后,还需要将它用Function或者Operator承载才能生效。Calc节点在执行层对应的是一个OneInputStreamOperator,由OperatorCodeGenerator#generateOneInputStreamOperator()负责。从它的代码可以看到更清晰的轮廓,如下。
def generateOneInputStreamOperator[IN <: Any, OUT <: Any](
ctx: CodeGeneratorContext,
name: String,
processCode: String,
inputType: LogicalType,
inputTerm: String = CodeGenUtils.DEFAULT_INPUT1_TERM,
endInputCode: Option[String] = None,
lazyInputUnboxingCode: Boolean = false,
converter: String => String = a => a): GeneratedOperator[OneInputStreamOperator[IN, OUT]] =
addReuseOutElement(ctx)
val operatorName = newName(name)
val abstractBaseClass = ctx.getOperatorBaseClass
val baseClass = classOf[OneInputStreamOperator[IN, OUT]]
val inputTypeTerm = boxedTypeTermForType(inputType)
val (endInput, endInputImpl) = endInputCode match
case None => ("", "")
case Some(code) =>
(s"""
|@Override
|public void endInput() throws Exception
| $ctx.reuseLocalVariableCode()
| $code
|
""".stripMargin, s", $className[BoundedOneInput]")
val operatorCode =
j"""
public class $operatorName extends $abstractBaseClass.getCanonicalName
implements $baseClass.getCanonicalName$endInputImpl
private final Object[] references;
$ctx.reuseMemberCode()
public $operatorName(
Object[] references,
$className[StreamTask[_, _]] task,
$className[StreamConfig] config,
$className[Output[_]] output,
$className[ProcessingTimeService] processingTimeService) throws Exception
this.references = references;
$ctx.reuseInitCode()
this.setup(task, config, output);
if (this instanceof $className[AbstractStreamOperator[_]])
(($className[AbstractStreamOperator[_]]) this)
.setProcessingTimeService(processingTimeService);
@Override
public void open() throws Exception
super.open();
$ctx.reuseOpenCode()
@Override
public void processElement($STREAM_RECORD $ELEMENT) throws Exception
$inputTypeTerm $inputTerm = ($inputTypeTerm) $converter(s"$ELEMENT.getValue()");
$ctx.reusePerRecordCode()
$ctx.reuseLocalVariableCode()
$if (lazyInputUnboxingCode) "" else ctx.reuseInputUnboxingCode()
$processCode
$endInput
@Override
public void close() throws Exception
super.close();
$ctx.reuseCloseCode()
$ctx.reuseInnerClassDefinitionCode()
""".stripMargin
LOG.debug(s"Compiling OneInputStreamOperator Code:\\n$name")
new GeneratedOperator(operatorName, operatorCode, ctx.references.toArray)
仍然注意那些能够通过CodeGeneratorContext复用的内容,例如processElement()方法中的本地变量声明部分,可以通过reuseLocalVariableCode()取得。最终的生成结果比较冗长,看官可通过Pastebin的传送门查看,并与上面的框架对应。
https://pastebin.com/sYKKGr5Q
另外,如果不想每次都通过Debug查看生成的代码,可在Log4j配置文件内加入以下两行。
logger.codegen.name = org.apache.flink.table.runtime.generated
logger.codegen.level = DEBUG
这样,在生成代码被编译的时候,就会输出其内容。当GeneratedClass被首次实例化时,就会调用Janino进行动态编译,并将结果缓存在一个内部Cache中,避免重复编译。可通过查看o.a.f.table.runtime.generated.CompileUtils及其上下文获得更多信息。
5.UDF表达式重用(FLINK-21573)
UDF重复调用的问题在某些情况下可能会对Flink SQL用户造成困扰,例如下面的SQL语句:
SELECT
mp['eventType'] AS eventType,
mp['fromType'] AS fromType,
mp['columnType'] AS columnType
-- A LOT OF other columns...
FROM (
SELECT SplitQueryParamsAsMap(query_string) AS mp
FROM rtdw_ods.kafka_analytics_access_log_app
WHERE CHAR_LENGTH(query_string) > 1
);
假设从Map中取N个key对应的value,自定义函数SplitQueryParamsAsMap就会被调用N次,这显然是不符合常理的——对于一个确定的输入query_string,该UDF的输出就是确定的,没有必要每次都调用。如果UDF包含计算密集型的逻辑,整个作业的性能就会受到很大影响。
如何解决呢?通过挖掘代码,可以得知源头在于Calcite重写查询时不会考虑函数的确定性(determinism),也就是说FunctionDefinition#isDeterministic()没有起到应有的作用。考虑到直接改动Calcite难度较大且容易引起兼容性问题,我们考虑在SQL执行前的最后一步——也就是代码生成阶段来施工。
观察调用UDF生成的代码,如下。
externalResult$8 = (java.util.Map) function_com$sht$bigdata$rt$udf$scalar$SplitQueryParamsAsMap$5cccfdc891a58463898db753288ed577
.eval(isNull$0 ? null : ((java.lang.String) converter$7.toExternal((org.apache.flink.table.data.binary.BinaryStringData) field$2)));
isNull$10 = externalResult$8 == null;
result$10 = null;
if (!isNull$10)
result$10 = (org.apache.flink.table.data.MapData) converter$9.toInternalOrNull((java.util.Map) externalResult$8);
// ......
externalResult$24 = (java.util.Map) function_com$sht$bigdata$rt$udf$scalar$SplitQueryParamsAsMap$5cccfdc891a58463898db753288ed577
.eval(isNull$0 ? null : ((java.lang.String) converter$7.toExternal((org.apache.flink.table.data.binary.BinaryStringData) field$2)));
isNull$25 = externalResult$24 == null;
result$25 = null;
if (!isNull$25)
result$25 = (org.apache.flink.table.data.MapData) converter$9.toInternalOrNull((java.util.Map) externalResult$24);
因此,我们可以在UDF满足确定性的前提下,重用UDF表达式产生的结果,即形如externalResult$8的term。思路比较直接,首先在CodeGeneratorContext中添加可重用的UDF表达式及其result term的容器,以及对应的方法。代码如下。
private val reusableScalarFuncExprs: mutable.Map[String, String] =
mutable.Map[String, String]()
private val reusableResultTerms: mutable.Map[String, String] =
mutable.Map[String, String]()
def addReusableScalarFuncExpr(code: String, term: String): Unit =
if (!reusableScalarFuncExprs.contains(code))
reusableScalarFuncExprs.put(code, term)
def addReusableResultTerm(term: String, originalTerm: String): Unit =
if (!reusableResultTerms.contains(term))
reusableResultTerms.put(term, originalTerm);
def reuseScalarFuncExpr(code: String) : String =
reusableScalarFuncExprs.getOrElse(code, code)
def reuseResultTerm(term: String) : String =
reusableResultTerms.getOrElse(term, term)
注意在保存UDF表达式时,是以生成的代码为key,result term为value。保存result term的映射时,是以新的为key,旧的为value。
然后从ExprCodeGenerator入手(函数调用都属于RexCall),找到UDF代码生成的方法,即BridgingFunctionGenUtil#generateScalarFunctionCall(),做如下改动。
private def generateScalarFunctionCall(
ctx: CodeGeneratorContext,
functionTerm: String,
externalOperands: Seq[GeneratedExpression],
outputDataType: DataType,
isDeterministic: Boolean)
: GeneratedExpression =
// result conversion
val externalResultClass = outputDataType.getConversionClass
val externalResultTypeTerm = typeTerm(externalResultClass)
// Janino does not fully support the JVM spec:
// boolean b = (boolean) f(); where f returns Object
// This is not supported and we need to box manually.
val externalResultClassBoxed = primitiveToWrapper(externalResultClass)
val externalResultCasting = if (externalResultClass == externalResultClassBoxed以上是关于FLinkFlink SQL代码生成与UDF重复调用的优化的主要内容,如果未能解决你的问题,请参考以下文章