Flinkflink的table api 和sql开发
Posted 星欲冷hx
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flinkflink的table api 和sql开发相关的知识,希望对你有一定的参考价值。
目录
Table API和SQL介绍
为什么要Table API和SQL
Table API是一种类似于SQL的API,SQL作为一种声明式语言,可以不用关心底层的实习即可以进行数据的处理。
Apache Flink 1.12 Documentation: 概念与通用 API
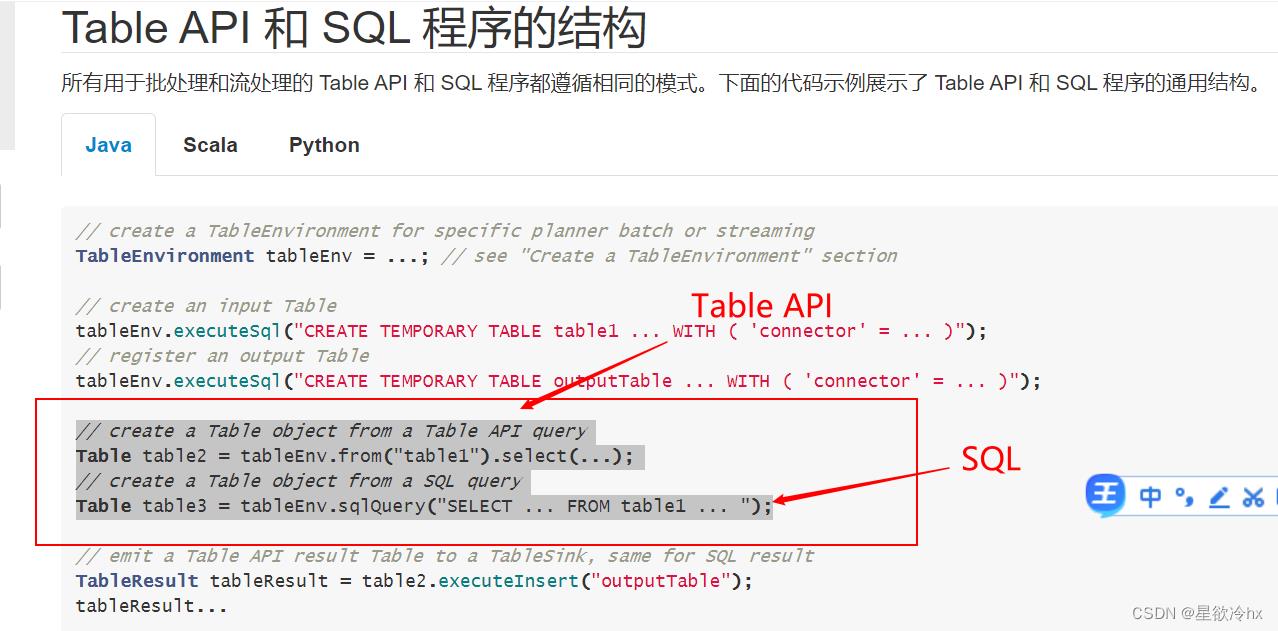
API
- 创建表
- 查询表
- 输出表
案例
将DataStream注册为Table和view并进行SQL统计
导入pom依赖
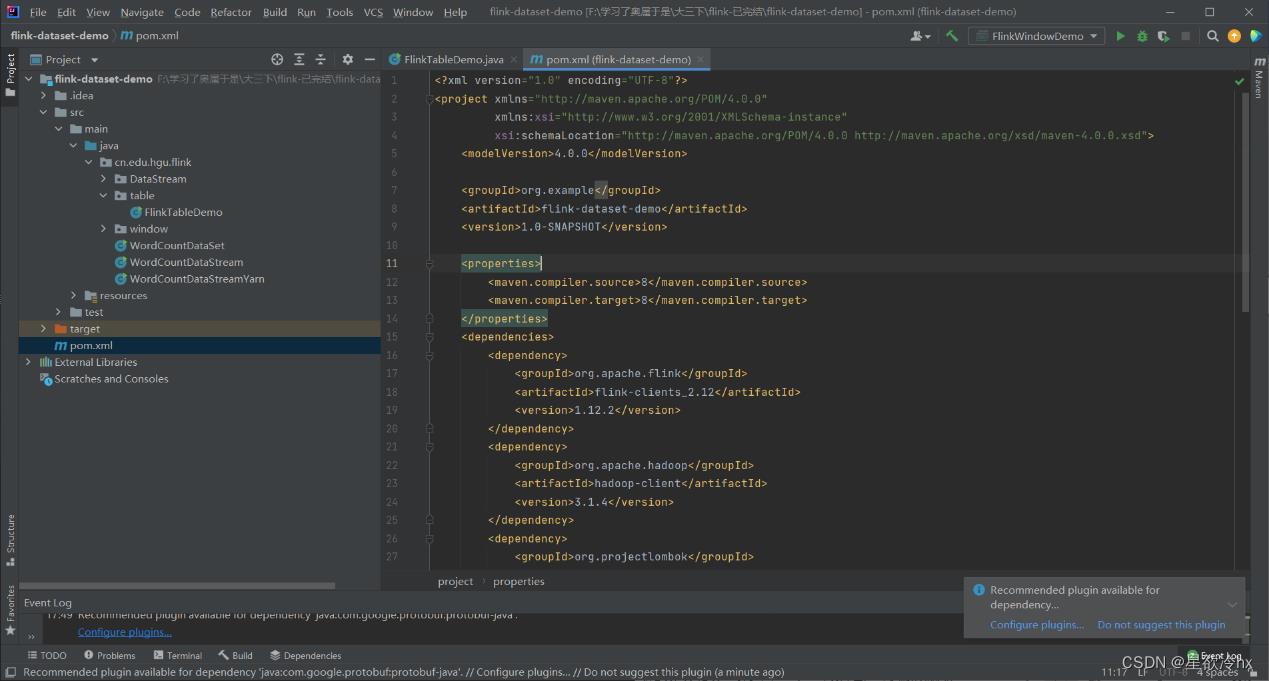
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>flink-dataset-demo</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.12</artifactId>
<version>1.12.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.4</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>RELEASE</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.47</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_2.12</artifactId>
<version>1.12.2</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_2.12</artifactId>
<version>1.12.2</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>1.12.2</version>
</dependency>
</dependencies>
</project>
代码实现
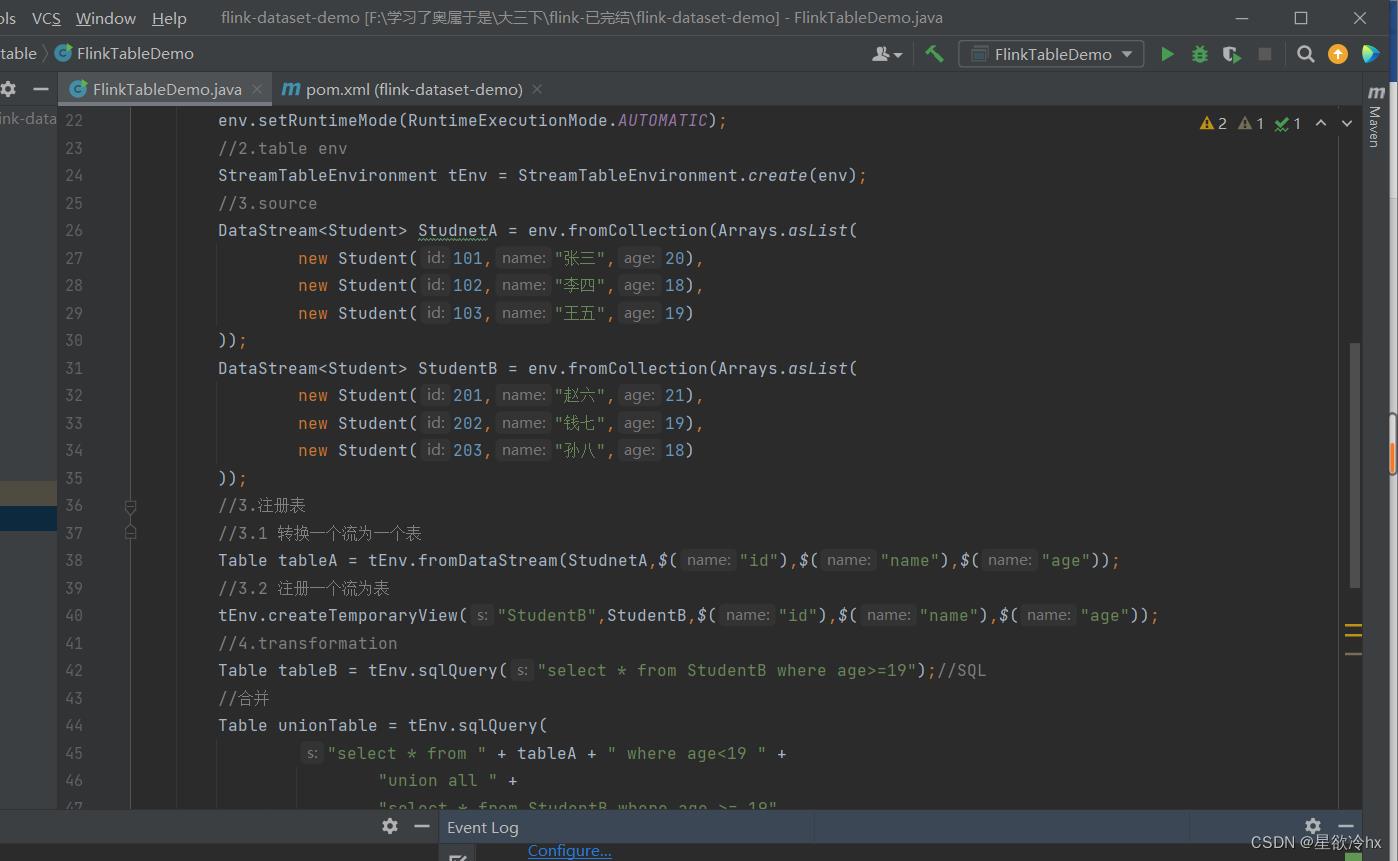
package cn.edu.hgu.flink.table;
import cn.edu.hgu.flink.DataStream.model.Student;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import java.util.Arrays;
import static org.apache.flink.table.api.Expressions.$;
/**
* flink的table API和 SQL演示
*/
public class FlinkTableDemo
public static void main(String[] args) throws Exception
//1.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//2.table env
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
//3.source
DataStream<Student> StudnetA = env.fromCollection(Arrays.asList(
new Student(101,"张三",20),
new Student(102,"李四",18),
new Student(103,"王五",19)
));
DataStream<Student> StudentB = env.fromCollection(Arrays.asList(
new Student(201,"赵六",21),
new Student(202,"钱七",19),
new Student(203,"孙八",18)
));
//3.注册表
//3.1 转换一个流为一个表
Table tableA = tEnv.fromDataStream(StudnetA,$("id"),$("name"),$("age"));
//3.2 注册一个流为表
tEnv.createTemporaryView("StudentB",StudentB,$("id"),$("name"),$("age"));
//4.transformation
Table tableB = tEnv.sqlQuery("select * from StudentB where age>=19");//SQL
//合并
Table unionTable = tEnv.sqlQuery(
"select * from " + tableA + " where age<19 " +
"union all " +
"select * from StudentB where age >= 19"
);
//5.sink
//把表转换为流
DataStream<Student> resultA = tEnv.toAppendStream(tableA,Student.class);
DataStream<Student> resultB = tEnv.toAppendStream(tableB,Student.class);
DataStream<Student> resultUnion = tEnv.toAppendStream(unionTable,Student.class);
// tableA.printSchema();
// tableB.printSchema();
// resultA.print();
// resultB.print();
resultUnion.print();
//6.execute
env.execute();
运行,查看结果
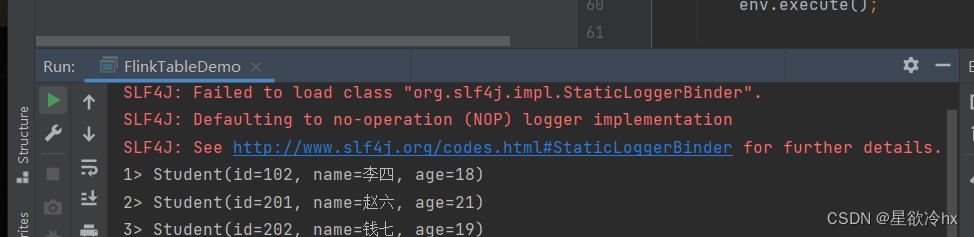
表的合并操作

下一章介绍的是flink的四大基石
以上是关于Flinkflink的table api 和sql开发的主要内容,如果未能解决你的问题,请参考以下文章