客快物流大数据项目(六十三):快递单主题
Posted Lansonli
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了客快物流大数据项目(六十三):快递单主题相关的知识,希望对你有一定的参考价值。
目录
快递单主题
一、背景介绍
快递单量的统计主要是从多个不同的维度计算快递单量,从而监测快递公司业务运营情况。
二、指标明细
| 指标列表 | 维度 |
| 快递单数 | 总快递单数 |
| 最大快递单数 | 各类客户最大快递单数 |
| 各渠道最大快递单数 | |
| 各网点最大快递单数 | |
| 各终端最大快递单数 | |
| 最小快递单数 | 各类客户最小快递单数 |
| 各渠道最小快递单数 | |
| 各网点最小快递单数 | |
| 各终端最小快递单数 | |
| 平均快递单数 | 各类客户平均快递单数 |
| 各渠道平均快递单数 | |
| 各网点平均快递单数 | |
| 各终端平均快递单数 |
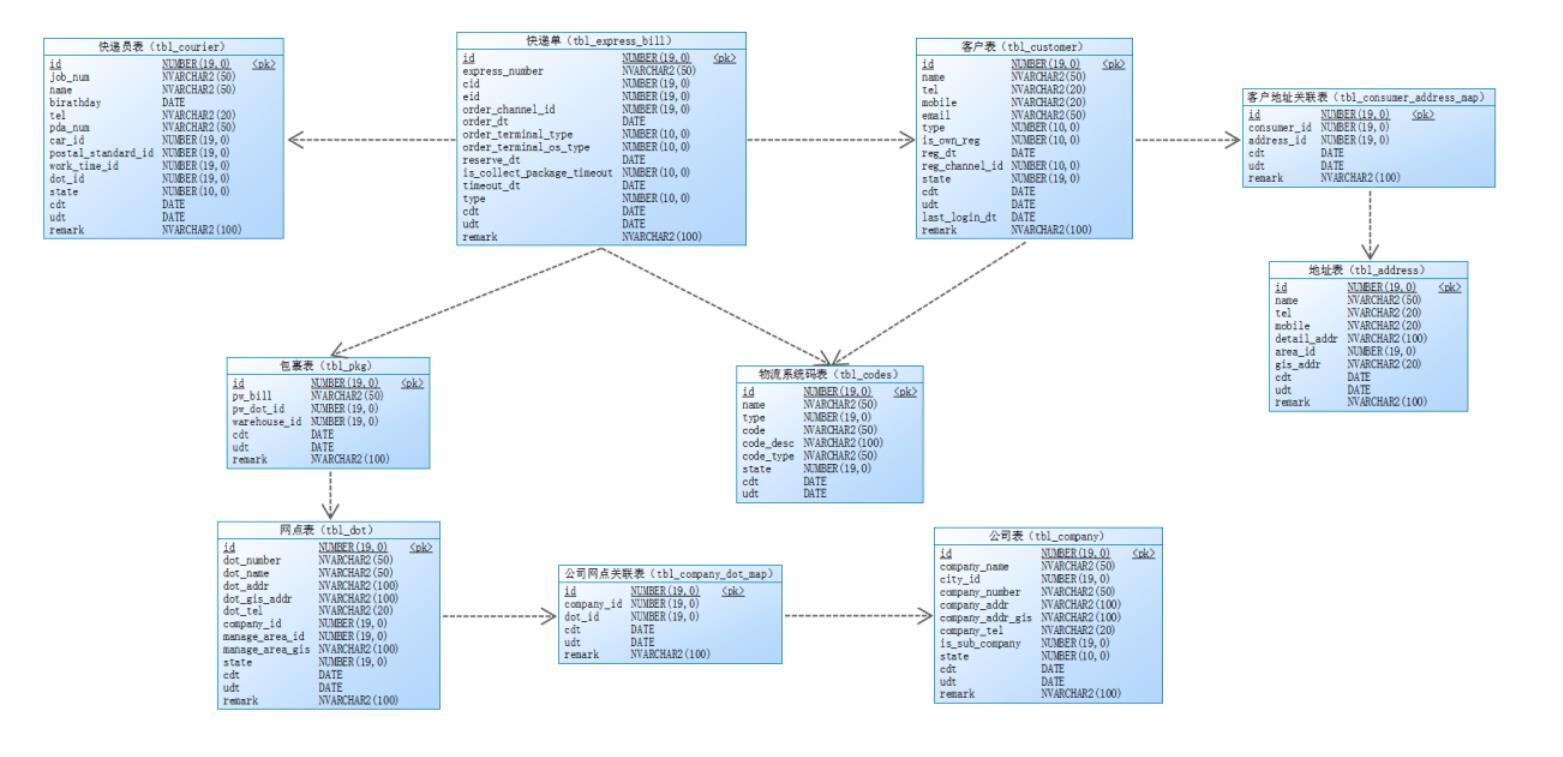
三、表关联关系
1、事实表
| 表名 | 描述 |
| tbl_express_bill | 快递单据表 |
2、 维度表
| 表名 | 描述 |
| tbl_consumer | 客户表 |
| tbl_courier | 快递员表 |
| tbl_pkg | 包裹表 |
| tbl_areas | 区域表 |
| tbl_dot | 网点表 |
| tbl_company_dot_map | 公司网点关联表 |
| tbl_company | 公司表 |
| tbl_consumer_address_map | 客户地址关联表 |
| tbl_address | 客户地址表 |
| tbl_codes | 字典表 |
3、关联关系
快递单表与维度表的关联关系如下:
四、快递单数据拉宽开发
1、拉宽后的字段
| 表 | 字段名 | 别名 | 字段描述 |
| tbl_express_bill | id | id | 快递单id |
| tbl_express_bill | expressNumber | express_number | 快递单编号 |
| tbl_express_bill | cid | cid | 客户ID |
| tbl_customer | name | cname | 客户名字 |
| tbl_address | detailAddr | caddress | 详细地址 |
| tbl_express_bill | eid | eid | 员工ID |
| tbl_courier | name | ename | 快递员姓名 |
| tbl_dot | id | dot_id | 网点ID |
| tbl_dot | dotName | dot_name | 网点名称 |
| tbl_company | companyName | company_name | 公司名字 |
| tbl_express_bill | orderChannelId | order_channel_id | 下单渠道ID |
| tbl_codes | channelTypeName | order_channel_name | 下单渠道名称 |
| tbl_express_bill | orderDt | order_dt | 下单时间 |
| tbl_express_bill | orderTerminalType | order_terminal_type | 下单设备类型ID |
| tbl_codes | orderTypeName | order_terminal_type_name | 下单设备类型名称 |
| tbl_express_bill | orderTerminalOsType | order_terminal_os_type | 下单设备操作系统ID |
| tbl_express_bill | reserveDt | reserve_dt | 预约取件时间 |
| tbl_express_bill | isCollectPackageTimeout | is_collect_package_timeout | 是否取件超时 |
| tbl_express_bill | timeoutDt | timeout_dt | 超时时间 |
| tbl_customer | type | ctype | 客户类别id |
| tbl_codes | code_desc | ctype_name | 客户类别名称 |
| tbl_express_bill | cdt | cdt | 创建时间 |
| tbl_express_bill | udt | udt | 修改时间 |
| tbl_express_bill | remark | remark | 备注 |
| tbl_express_bill | yyyyMMdd(cdt) | day | 创建时间 年月日格式 |
2、SQL语句
SELECT EBILL."id" ,
EBILL ."express_number" ,
EBILL ."cid" ,
CUSTOMER."name" AS cname,
ADDRESS ."detail_addr" AS caddress,
EBILL."eid" ,
COURIER ."name" AS ename,
DOT ."id" AS dot_id,
DOT ."dot_name" AS dot_name,
COMPANY ."company_name" AS company_name,
EBILL."order_channel_id" ,
code1."name" AS "order_channel_name",
ebill."order_dt",
ebill."order_terminal_type",
code2."name" AS order_terminal_type_name,
ebill."order_terminal_os_type" ,
ebill."reserve_dt" ,
ebill."is_collect_package_timeout" ,
ebill."timeout_dt" ,
CUSTOMER."type" ,
ebill."cdt" ,
ebill."udt" ,
ebill."remark"
FROM "tbl_express_bill" EBILL
LEFT JOIN "tbl_courier" courier ON EBILL."eid" = courier."id"
LEFT JOIN "tbl_customer" customer ON ebill."cid" = CUSTOMER ."id"
LEFT JOIN "tbl_codes" code1 ON code1."type" =18 AND ebill."order_channel_id" =code1."code"
LEFT JOIN "tbl_codes" code2 ON code2."type" =17 AND ebill."order_terminal_type" =code2."code"
LEFT JOIN "tbl_consumer_address_map" address_map ON CUSTOMER."id" = address_map."consumer_id"
LEFT JOIN "tbl_address" address ON address_map."address_id" = ADDRESS."id"
LEFT JOIN "tbl_pkg" pkg ON EBILL."express_number" = pkg."pw_bill"
LEFT JOIN "tbl_dot" dot ON PKG ."pw_dot_id"=dot."id"
LEFT JOIN "tbl_company_dot_map" companydot ON dot."id" =COMPANYDOT ."dot_id"
LEFT JOIN "tbl_company" company ON COMPANY ."id"=companydot."company_id" 3、Spark实现
实现步骤:
- 在dwd目录下创建 ExpressBillDWD 单例对象,继承自OfflineApp特质
- 初始化环境的参数,创建SparkSession对象
- 获取快递单表(tbl_express_bill)数据,并缓存数据(缓存两份数据,生产环境中肯定是多台服务器,为了避免数据丢失缓存2份数据,测试环境只有一台服务器,按照生产环境进行开发)
- 判断是否是首次运行,如果是首次运行的话,则全量装载数据(含历史数据)
- 获取客户表(tbl_customer)数据,并缓存数据
- 获取快递员表(tbl_courier)数据,并缓存数据
- 获取包裹表(tbl_pkg)数据,并缓存数据
- 获取网点表(tbl_dot)数据,并缓存数据
- 获取区域表(tbl_areas)数据,并缓存数据
- 获取公司网点关联表(tbl_company_dot_map)数据,并缓存数据
- 获取公司表(tbl_company)数据,并缓存数据
- 获取客户地址关联表(tbl_consumer_address_map)数据,并缓存数据
- 获取客户地址表(tbl_address)数据,并缓存数据
- 获取字典表(tbl_codes)数据,并缓存数据
- 根据以下方式拉宽快递单明细数据
- 根据客户id,在客户表中获取客户数据
- 根据快递员id,在快递员表中获取快递员数据
- 根据客户id,在客户地址表中获取客户地址数据
- 根据快递单号,在包裹表中获取包裹数据
- 根据包裹的发货网点id,获取到网点数据
- 根据网点id, 获取到公司数据
- 创建快递单明细宽表(若存在则不创建)
- 将快递单明细宽表数据写入到kudu数据表中
- 删除缓存数据
初始化环境变量
- 初始化快递单明细拉宽作业的环境变量
package cn.it.logistics.offline.dwd
import cn.it.logistics.common.CodeTypeMapping, Configuration, OfflineTableDefine, SparkUtils
import cn.it.logistics.offline.OfflineApp
import org.apache.spark.SparkConf
import org.apache.spark.sql.DataFrame, SparkSession
import org.apache.spark.storage.StorageLevel
import org.apache.spark.sql.functions._
import org.apache.spark.sql.types.IntegerType
/**
* 快递单主题开发
* 将快递单事实表的数据与相关维度表的数据进行关联,然后将拉宽后的数据写入到快递单宽表中
* 采用DSL语义实现离线计算程序
*
* 最终离线程序需要部署到服务器,每天定时执行(azkaban定时调度)
*/
object ExpressBillDWD extends OfflineApp
//定义应用的名称
val appName = this.getClass.getSimpleName
/**
* 入口函数
* @param args
*/
def main(args: Array[String]): Unit =
/**
* 实现步骤:
* 1)初始化sparkConf对象
* 2)创建sparkSession对象
* 3)加载kudu中的事实表和维度表的数据(将加载后的数据进行缓存)
* 4)定义维度表与事实表的关联
* 5)将拉宽后的数据再次写回到kudu数据库中(DWD明细层)
* 5.1:创建快递单明细宽表的schema表结构
* 5.2:创建快递单宽表(判断宽表是否存在,如果不存在则创建)
* 5.3:将数据写入到kudu中
* 6):将缓存的数据删除掉
*/
//1)初始化sparkConf对象
val sparkConf: SparkConf = SparkUtils.autoSettingEnv(
SparkUtils.sparkConf(appName)
)
//2)创建sparkSession对象
val sparkSession: SparkSession = SparkUtils.getSparkSession(sparkConf)
sparkSession.sparkContext.setLogLevel(Configuration.LOG_OFF)
//数据处理
execute(sparkSession)
/**
* 数据处理
*
* @param sparkSession
*/
override def execute(sparkSession: SparkSession): Unit =
sparkSession.stop()
加载快递单相关的表数据并缓存
- 加载快递单表的时候,需要指定日期条件,因为快递单主题最终需要Azkaban定时调度执行,每天执行一次增量数据,因此需要指定日期。
- 判断是否是首次运行,如果是首次运行的话,则全量装载数据(含历史数据)
//3.1:加载快递单事实表的数据
val expressBillDF: DataFrame = getKuduSource(sparkSession, TableMapping.expressBill, Configuration.isFirstRunnable)
.persist(StorageLevel.DISK_ONLY_2) //将数据缓存两个节点的磁盘目录,避免单机故障导致的缓存数据丢失
//3.2:加载快递员维度表的数据
val courierDF: DataFrame = getKuduSource(sparkSession, TableMapping.courier, true).persist(StorageLevel.DISK_ONLY_2)
//3.2:加载客户维度表的数据
val customerDF: DataFrame = getKuduSource(sparkSession, TableMapping.customer, true).persist(StorageLevel.DISK_ONLY_2)
//3.4:加载物流码表的数据
val codesDF: DataFrame = getKuduSource(sparkSession, TableMapping.codes, true).persist(StorageLevel.DISK_ONLY_2)
//3.5:客户地址关联表的数据
val addressMapDF: DataFrame = getKuduSource(sparkSession, TableMapping.consumerAddressMap, true).persist(StorageLevel.DISK_ONLY_2)
//3.6:加载地址表的数据
val addressDF: DataFrame = getKuduSource(sparkSession, TableMapping.address, true).persist(StorageLevel.DISK_ONLY_2)
//3.7:加载包裹表的数据
val pkgDF: DataFrame = getKuduSource(sparkSession, TableMapping.pkg, true).persist(StorageLevel.DISK_ONLY_2)
//3.8:加载网点表的数据
val dotDF: DataFrame = getKuduSource(sparkSession, TableMapping.dot, true).persist(StorageLevel.DISK_ONLY_2)
//3.9:加载公司网点表的数据
val companyDotMapDF: DataFrame = getKuduSource(sparkSession, TableMapping.companyDotMap, true).persist(StorageLevel.DISK_ONLY_2)
//3.10:加载公司表的数据
val companyDF: DataFrame = getKuduSource(sparkSession, TableMapping.company, true).persist(StorageLevel.DISK_ONLY_2)
//导入隐式转换
import sparkSession.implicits._
//获取终端类型码表数据
val orderTerminalTypeDF: DataFrame = codesDF.where($"type" === CodeTypeMapping.OrderTerminalType)
.select($"code".as("OrderTerminalTypeCode"), $"codeDesc".as("OrderTerminalTypeName"))
//获取下单终端类型码表数据
val orderChannelTypeDF: DataFrame = codesDF.where($"type" === CodeTypeMapping.OrderChannelType)
.select($"code".as("OrderChannelTypeCode"), $"codeDesc".as("OrderChannelTypeName"))定义表的关联关系
- 为了在DWS层任务中方便的获取每日增量快递单数据(根据日期),因此在DataFrame基础上动态增加列(day),指定日期格式为yyyyMMdd
代码如下:
//TODO 4)定义维度表与事实表的关联
val joinType = "left_outer"
val expressBillDetailDF: DataFrame = expressBillDF
.join(courierDF, expressBillDF("eid") === courierDF("id") ,joinType) //快递单表与快递员表进行关联
.join(customerDF, expressBillDF("cid") === customerDF("id"), joinType) //快递单表与客户表进行关联
.join(orderChannelTypeDF, orderChannelTypeDF("OrderChannelTypeCode") === expressBillDF("orderChannelId"), joinType) //下单渠道表与快递单表关联
.join(orderTerminalTypeDF, orderTerminalTypeDF("OrderTerminalTypeCode") === expressBillDF("orderTerminalType"), joinType) //终端类型表与快递单表关联
.join(addressMapDF, addressMapDF("consumerId") === customerDF("id"), joinType) //客户地址关联表与客户表关联
.join(addressDF, addressDF("id") === addressMapDF("addressId"), joinType) //地址表与客户地址关联表关联
.join(pkgDF, pkgDF("pwBill") === expressBillDF("expressNumber"), joinType) //包裹表与快递单表关联
.join(dotDF, dotDF("id") === pkgDF("pwDotId"), joinType) //网点表与包裹表关联
.join(companyDotMapDF, companyDotMapDF("dotId") === dotDF("id"), joinType) //公司网点关联表与网点表关联
.join(companyDF, companyDF("id") === companyDotMapDF("companyId"), joinType) //公司网点关联表与公司表关联
.withColumn("day", date_format(expressBillDF("cdt"), "yyyyMMdd"))//虚拟列,可以根据这个日期列作为分区字段,可以保证同一天的数据保存在同一个分区中
.sort(expressBillDF.col("cdt").asc) //根据快递单的创建时间顺序排序
.select(
expressBillDF("id"), //快递单id
expressBillDF("expressNumber").as("express_number"), //快递单编号
expressBillDF("cid"), //客户id
customerDF("name").as("cname"), //客户名称
addressDF("detailAddr").as("caddress"), //客户地址
expressBillDF("eid"), //员工id
courierDF("name").as("ename"), //员工名称
dotDF("id").as("dot_id"), //网点id
dotDF("dotName").as("dot_name"), //网点名称
companyDF("companyName").as("company_name"),//公司名称
expressBillDF("orderChannelId").as("order_channel_id"), //下单渠道id
orderChannelTypeDF("OrderChannelTypeName").as("order_channel_name"), //下单渠道id
expressBillDF("orderDt").as("order_dt"),//下单时间
orderTerminalTypeDF("OrderTerminalTypeCode").as("order_terminal_type"), //下单设备类型id
orderTerminalTypeDF("OrderTerminalTypeName").as("order_terminal_type_name"), //下单设备类型id
expressBillDF("orderTerminalOsType").as("order_terminal_os_type"),//下单设备操作系统
expressBillDF("reserveDt").as("reserve_dt"),//预约取件时间
expressBillDF("isCollectPackageTimeout").as("is_collect_package_timeout"),//是否取件超时
expressBillDF("timeoutDt").as("timeout_dt"),//超时时间
customerDF("type"),//客户类型
expressBillDF("cdt"),//创建时间
expressBillDF("udt"),//修改时间
expressBillDF("remark"),//备注
$"day"
)创建快递单明细宽表并将快递单明细数据写入到宽表中
快递单宽表数据需要保存到kudu中,因此在第一次执行快递单明细拉宽操作时,快递单明细宽表是不存在的,因此需要实现自动判断宽表是否存在,如果不存在则创建
实现步骤:
- 在ExpressBillDWD 单例对象中调用父类save方法
- 判断宽表是否存在,如果不存在则创建宽表
- 将明细数据写入到宽表中
参考代码:
//TODO 5)将拉宽后的数据再次写回到kudu数据库中(DWD明细层)
save(expressBillDetailDF, OfflineTableDefine.expressBillDetail)删除缓存数据
为了释放资源,快递单明细宽表数据计算完成以后,需要将缓存的源表数据删除。
//TODO 6) 将缓存的数据删除掉
expressBillDF.unpersist()
courierDF.unpersist()
customerDF.unpersist()
orderChannelTypeDF.unpersist()
orderTerminalTypeDF.unpersist()
addressMapDF.unpersist()
addressDF.unpersist()
pkgDF.unpersist()
dotDF.unpersist()
companyDotMapDF.unpersist()
companyDF.unpersist()完整代码
package cn.it.logistics.offline.dwd
import cn.it.logistics.common.CodeTypeMapping, Configuration, OfflineTableDefine, SparkUtils
import cn.it.logistics.offline.OfflineApp
import org.apache.spark.SparkConf
import org.apache.spark.sql.DataFrame, SparkSession
import org.apache.spark.storage.StorageLevel
import org.apache.spark.sql.functions._
import org.apache.spark.sql.types.IntegerType
/**
* 快递单主题开发
* 将快递单事实表的数据与相关维度表的数据进行关联,然后将拉宽后的数据写入到快递单宽表中
* 采用DSL语义实现离线计算程序
*
* 最终离线程序需要部署到服务器,每天定时执行(azkaban定时调度)
*/
object ExpressBillDWD extends OfflineApp
//定义应用的名称
val appName = this.getClass.getSimpleName
/**
* 入口函数
* @param args
*/
def main(args: Array[String]): Unit =
/**
* 实现步骤:
* 1)初始化sparkConf对象
* 2)创建sparkSession对象
* 3)加载kudu中的事实表和维度表的数据(将加载后的数据进行缓存)
* 4)定义维度表与事实表的关联
* 5)将拉宽后的数据再次写回到kudu数据库中(DWD明细层)
* 5.1:创建快递单明细宽表的schema表结构
* 5.2:创建快递单宽表(判断宽表是否存在,如果不存在则创建)
* 5.3:将数据写入到kudu中
* 6):将缓存的数据删除掉
*/
//1)初始化sparkConf对象
val sparkConf: SparkConf = SparkUtils.autoSettingEnv(
SparkUtils.sparkConf(appName)
)
//2)创建sparkSession对象
val sparkSession: SparkSession = SparkUtils.getSparkSession(sparkConf)
sparkSession.sparkContext.setLogLevel(Configuration.LOG_OFF)
//数据处理
execute(sparkSession)
/**
* 数据处理
*
* @param sparkSession
*/
override def execute(sparkSession: SparkSession): Unit =
//TODO 3)加载kudu中的事实表和维度表的数据(将加载后的数据进行缓存)
//3.1:加载快递单事实表的数据
val expressBillDF: DataFrame = getKuduSource(sparkSession, "tbl_express_bill", Configuration.isFirstRunnable)
.persist(StorageLevel.DISK_ONLY_2) //将数据缓存两个节点的磁盘目录,避免单机故障导致的缓存数据丢失
//3.2:加载快递员维度表的数据
val courierDF: DataFrame = getKuduSource(sparkSession, "tbl_courier", true).persist(StorageLevel.DISK_ONLY_2)
//3.2:加载客户维度表的数据
val customerDF: DataFrame = getKuduSource(sparkSession, "tbl_customer", true).persist(StorageLevel.DISK_ONLY_2)
//3.4:加载物流码表的数据
val codesDF: DataFrame = getKuduSource(sparkSession, "tbl_codes", true).persist(StorageLevel.DISK_ONLY_2)
//3.5:客户地址关联表的数据
val addressMapDF: DataFrame = getKuduSource(sparkSession, "tbl_consumer_address_map", true).persist(StorageLevel.DISK_ONLY_2)
//3.6:加载地址表的数据
val addressDF: DataFrame = getKuduSource(sparkSession, "tbl_address", true).persist(StorageLevel.DISK_ONLY_2)
//3.7:加载包裹表的数据
val pkgDF: DataFrame = getKuduSource(sparkSession, "tbl_pkg", true).persist(StorageLevel.DISK_ONLY_2)
//3.8:加载网点表的数据
val dotDF: DataFrame = getKuduSource(sparkSession, "tbl_dot", true).persist(StorageLevel.DISK_ONLY_2)
//3.9:加载公司网点表的数据
val companyDotMapDF: DataFrame = getKuduSource(sparkSession, "tbl_company_dot_map", true).persist(StorageLevel.DISK_ONLY_2)
//3.10:加载公司表的数据
val companyDF: DataFrame = getKuduSource(sparkSession, "tbl_company", true).persist(StorageLevel.DISK_ONLY_2)
//导入隐式转换
import sparkSession.implicits._
//获取终端类型码表数据
val orderTerminalTypeDF: DataFrame = codesDF.where($"type" === CodeTypeMapping.OrderTerminalType)
.select($"code".as("OrderTerminalTypeCode"), $"codeDesc".as("OrderTerminalTypeName"))
//获取下单终端类型码表数据
val orderChannelTypeDF: DataFrame = codesDF.where($"type" === CodeTypeMapping.OrderChannelType)
.select($"code".as("OrderChannelTypeCode"), $"codeDesc".as("OrderChannelTypeName"))
//TODO 4)定义维度表与事实表的关联
val joinType = "left_outer"
val expressBillDetailDF: DataFrame = expressBillDF
.join(courierDF, expressBillDF("eid") === courierDF("id") ,joinType) //快递单表与快递员表进行关联
.join(customerDF, expressBillDF("cid") === customerDF("id"), joinType) //快递单表与客户表进行关联
.join(orderChannelTypeDF, orderChannelTypeDF("OrderChannelTypeCode") === expressBillDF("orderChannelId"), joinType) //下单渠道表与快递单表关联
.join(orderTerminalTypeDF, orderTerminalTypeDF("OrderTerminalTypeCode") === expressBillDF("orderTerminalType"), joinType) //终端类型表与快递单表关联
.join(addressMapDF, addressMapDF("consumerId") === customerDF("id"), joinType) //客户地址关联表与客户表关联
.join(addressDF, addressDF("id") === addressMapDF("addressId"), joinType) //地址表与客户地址关联表关联
.join(pkgDF, pkgDF("pwBill") === expressBillDF("expressNumber"), joinType) //包裹表与快递单表关联
.join(dotDF, dotDF("id") === pkgDF("pwDotId"), joinType) //网点表与包裹表关联
.join(companyDotMapDF, companyDotMapDF("dotId") === dotDF("id"), joinType) //公司网点关联表与网点表关联
.join(companyDF, companyDF("id") === companyDotMapDF("companyId"), joinType) //公司网点关联表与公司表关联
.withColumn("day", date_format(expressBillDF("cdt"), "yyyyMMdd"))//虚拟列,可以根据这个日期列作为分区字段,可以保证同一天的数据保存在同一个分区中
.sort(expressBillDF.col("cdt").asc) //根据快递单的创建时间顺序排序
.select(
expressBillDF("id"), //快递单id
expressBillDF("expressNumber").as("express_number"), //快递单编号
expressBillDF("cid"), //客户id
customerDF("name").as("cname"), //客户名称
addressDF("detailAddr").as("caddress"), //客户地址
expressBillDF("eid"), //员工id
courierDF("name").as("ename"), //员工名称
dotDF("id").as("dot_id"), //网点id
dotDF("dotName").as("dot_name"), //网点名称
companyDF("companyName").as("company_name"),//公司名称
expressBillDF("orderChannelId").as("order_channel_id"), //下单渠道id
orderChannelTypeDF("OrderChannelTypeName").as("order_channel_name"), //下单渠道id
expressBillDF("orderDt").as("order_dt"),//下单时间
orderTerminalTypeDF("OrderTerminalTypeCode").as("order_terminal_type"), //下单设备类型id
orderTerminalTypeDF("OrderTerminalTypeName").as("order_terminal_type_name"), //下单设备类型id
expressBillDF("orderTerminalOsType").as("order_terminal_os_type"),//下单设备操作系统
expressBillDF("reserveDt").as("reserve_dt"),//预约取件时间
expressBillDF("isCollectPackageTimeout").as("is_collect_package_timeout"),//是否取件超时
expressBillDF("timeoutDt").as("timeout_dt"),//超时时间
customerDF("type"),//客户类型
expressBillDF("cdt"),//创建时间
expressBillDF("udt"),//修改时间
expressBillDF("remark"),//备注
$"day"
)
//TODO 5)将拉宽后的数据再次写回到kudu数据库中(DWD明细层)
save(expressBillDetailDF, OfflineTableDefine.expressBillDetail)
//TODO 6) 将缓存的数据删除掉
expressBillDF.unpersist()
courierDF.unpersist()
customerDF.unpersist()
orderChannelTypeDF.unpersist()
orderTerminalTypeDF.unpersist()
addressMapDF.unpersist()
addressDF.unpersist()
pkgDF.unpersist()
dotDF.unpersist()
companyDotMapDF.unpersist()
companyDF.unpersist()
sparkSession.stop()
4、测试验证
实现步骤:
- 在ExpressBillDWD 单例对象中读取快递单明细宽表的数据
- 输出展示
实现过程:
- 在ExpressBillDWD 单例对象中读取快递单明细宽表的数据
// 检查今日数据
spark.read
.format(Configure.SPARK_KUDU_FORMAT)
.options(Map("kudu.master" -> Configure.kuduRpcAddress, "kudu.table" -> table))
.load
.show- 输出展示

五、快递单数据指标计算开发
1、计算的字段
| 字段名 | 字段描述 |
| id | 数据产生时间 |
| totalExpressBillCount | 总快递单数 |
| maxTypeExpressBillTotalCount | 各类客户最大快递单数 |
| minTypeExpressBillTotalCount | 各类客户最小快递单数 |
| avgTypeExpressBillTotalCount | 各类客户平均快递单数 |
| maxDotExpressBillTotalCount | 各网点最大快递单数 |
| minDotExpressBillTotalCount | 各网点最小快递单数 |
| avgDotExpressBillTotalCount | 各网点平均快递单数 |
| maxChannelExpressBillTotalCount | 各渠道最大快递单数 |
| minChannelExpressBillTotalCount | 各渠道最小快递单数 |
| avgChannelExpressBillTotalCount | 各渠道平均快递单数 |
| maxTerminalExpressBillTotalCount | 各终端最大快递单数 |
| minTerminalExpressBillTotalCount | 各终端最小快递单数 |
| avgTerminalExpressBillTotalCount | 各终端平均快递单数 |
2、Spark实现
实现步骤:
- 在dws目录下创建 ExpressBillDWS 单例对象,继承自OfflineApp特质
- 初始化环境的参数,创建SparkSession对象
- 根据指定的日期获取拉宽后的快递单宽表(tbl_express_bill_detail)增量数据,并缓存数据
- 判断是否是首次运行,如果是首次运行的话,则全量装载数据(含历史数据)
- 指标计算
- 计算总快递单数
- 各类客户快递单数
- 各类客户最大快递单数
- 各类客户最小快递单数
- 各类客户平均快递单数
- 各网点快递单数
- 各网点最大快递单数
- 各网点最小快递单数
- 各网点平均快递单数
- 各渠道快递单数
- 各渠道最大快递单数
- 各渠道最小快递单数
- 各渠道平均快递单数
- 各终端快递单数
- 各终端最大快递单数
- 各终端最小快递单数
- 各终端平均快递单数
- 获取当前时间yyyyMMddHH
- 构建要持久化的指标数据(需要判断计算的指标是否有值,若没有需要赋值默认值)
- 通过StructType构建指定Schema
- 创建快递单指标数据表(若存在则不创建)
- 持久化指标数据到kudu表
初始化环境变量
package cn.it.logistics.offline.dws
import cn.it.logistics.common.Configuration, SparkUtils
import cn.it.logistics.offline.OfflineApp
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
object ExpressBillDWS extends OfflineApp
//定义应用程序的名称
val appName = this.getClass.getSimpleName
/**
* 入口函数
* @param args
*/
def main(args: Array[String]): Unit =
/**
* 实现步骤:
* 1)创建SparkConf对象
* 2)创建SparkSession对象
* 3)读取快递明细宽表的数据
* 4)对快递明细宽表的数据进行指标的计算
* 5)将计算好的指标数据写入到kudu数据库中
* 5.1:定义指标结果表的schema信息
* 5.2:组织需要写入到kudu表的数据
* 5.3:判断指标结果表是否存在,如果不存在则创建
* 5.4:将数据写入到kudu表中
* 6)删除缓存数据
* 7)停止任务,退出sparksession
*/
//TODO 1)创建SparkConf对象
val sparkConf: SparkConf = SparkUtils.autoSettingEnv(
SparkUtils.sparkConf(appName)
)
//TODO 2)创建SparkSession对象
val sparkSession: SparkSession = SparkUtils.getSparkSession(sparkConf)
sparkSession.sparkContext.setLogLevel(Configuration.LOG_OFF)
//处理数据
execute(sparkSession)
/**
* 数据处理
*
* @param sparkSession
*/
override def execute(sparkSession: SparkSession): Unit =
// 退出sc
sparkSession.stop
加载快递单宽表增量数据并缓存
加载快递单宽表的时候,需要指定日期条件,因为快递单主题最终需要Azkaban定时调度执行,每天执行一次增量数据,因此需要指定日期。
//TODO 3)读取快递单明细宽表的数据
val expressBillDetailDF: DataFrame = getKuduSource(sparkSession, OfflineTableDefine.expressBillDetail, Configuration.isFirstRunnable)指标计算
程序首次运行需要全量装载历史的快递单数据,离线计算程序每天计算昨天增量数据,因此需要将历史的数据进行按照天进行分组,然后根据某一天来进行统计当前日期下的快递单相关指标数据
//读取出来的明细宽表数据可能是增量的数据,也可能是全量的数据
//全量的数据是包含多个日期的数据,增量数据是前一天的数据
//需要计算的指标是以日为单位,每天的最大快递单数、最小快递单数、平均快递单数据
//因此需要对读取出来的快递单明细宽表数据按照日为单位进行分组,然后统计每日的指标数据
val expressBillDetailGroupByDayDF: DataFrame = expressBillDetailDF.select("day").groupBy("day").count().cache()
//导入隐式转换
import sparkSession.implicits._
//定义计算好的指标结果集合对象
val rows: ArrayBuffer[Row] = ArrayBuffer[Row]()
//循环遍历所有日期的数据
expressBillDetailGroupByDayDF.collect().foreach(row=>
//获取到需要处理的数据所在的日期
val day: String = row.getAs[String](0)
//根据日期查询该日期内的快递单明细数据,然后将查询到的结果进行指标计算(指定日期的指标)
val expressBillDetailByDayDF: DataFrame = expressBillDetailDF.where(col("day") === day).toDF().persist(StorageLevel.DISK_ONLY_2)
//TODO 4)对快递明细宽表的数据进行指标的计算
//总快递单数
val totalExpressBillCount: Long = expressBillDetailByDayDF.agg(count("express_number")).first().getLong(0)
//各类客户的快递单数
val customerTypeExpressBillTotalCountDF: DataFrame = expressBillDetailByDayDF.groupBy($"type").agg(count("express_number").as("express_number")).cache()
//各类客户最大快递单数
val maxTypeExpressBillTotalCount: Row = customerTypeExpressBillTotalCountDF.agg(max("express_number")).first()
//各类客户最小快递单数
val minTypeExpressBillTotalCount: Row = customerTypeExpressBillTotalCountDF.agg(min("express_number")).first()
//各类客户平均快递单数
val avgTypeExpressBillTotalCount: Row = customerTypeExpressBillTotalCountDF.agg(avg("express_number")).first()
//各网点的快递单数
val dotExpressBillTotalCountDF: DataFrame = expressBillDetailByDayDF.groupBy($"dot_id").agg(count("express_number").as("express_number")).cache()
//各网点最大快递单数
val maxDotExpressBillTotalCount: Row = dotExpressBillTotalCountDF.agg(max("express_number")).first()
//各网点最小快递单数
val minDotExpressBillTotalCount: Row = dotExpressBillTotalCountDF.agg(min("express_number")).first()
//各网点平均快递单数
val avgDotExpressBillTotalCount: Row = dotExpressBillTotalCountDF.agg(avg("express_number")).first()
//各渠道的快递单数
val channelExpressBillTotalCountDF: DataFrame = expressBillDetailByDayDF.groupBy($"order_channel_id").agg(count("express_number").as("express_number")).cache()
//各渠道最大快递单数
val maxChannelExpressBillTotalCount: Row = channelExpressBillTotalCountDF.agg(max("express_number")).first()
//各渠道最小快递单数
val minChannelExpressBillTotalCount: Row = channelExpressBillTotalCountDF.agg(min("express_number")).first()
//各渠道平均快递单数
val avgChannelExpressBillTotalCount: Row = channelExpressBillTotalCountDF.agg(avg("express_number")).first()
val terminalExpressBillTotalCountDF: DataFrame = expressBillDetailByDayDF.groupBy($"order_terminal_type").agg(count("express_number").as("express_number")).cache()
println(terminalExpressBillTotalCountDF)
//各终端最大快递单数
val maxTerminalExpressBillTotalCount: Row = terminalExpressBillTotalCountDF.agg(max("express_number")).first()
//各终端最小快递单数
val minTerminalExpressBillTotalCount: Row = terminalExpressBillTotalCountDF.agg(min("express_number")).first()
//各终端平均快递单数
val avgTerminalExpressBillTotalCount: Row = terminalExpressBillTotalCountDF.agg(avg("express_number")).first()
println(avgTerminalExpressBillTotalCount)
//将每条记录写入到Row对象中
val rowInfo = Row(
day,
totalExpressBillCount, //总快递单数
if(maxTypeExpressBillTotalCount.isNullAt(0)) 0L else maxTypeExpressBillTotalCount.get(0).asInstanceOf[Number].longValue(),
if(minTypeExpressBillTotalCount.isNullAt(0)) 0L else minTypeExpressBillTotalCount.get(0).asInstanceOf[Number].longValue(),
if(avgTypeExpressBillTotalCount.isNullAt(0)) 0L else avgTypeExpressBillTotalCount.get(0).asInstanceOf[Number].longValue(),
if(maxDotExpressBillTotalCount.isNullAt(0)) 0L else maxDotExpressBillTotalCount.get(0).asInstanceOf[Number].longValue(),
if(minDotExpressBillTotalCount.isNullAt(0)) 0L else minDotExpressBillTotalCount.get(0).asInstanceOf[Number].longValue(),
if(avgDotExpressBillTotalCount.isNullAt(0)) 0L else avgDotExpressBillTotalCount.get(0).asInstanceOf[Number].longValue(),
if(maxChannelExpressBillTotalCount.isNullAt(0)) 0L else maxChannelExpressBillTotalCount.get(0).asInstanceOf[Number].longValue(),
if(minChannelExpressBillTotalCount.isNullAt(0)) 0L else minChannelExpressBillTotalCount.get(0).asInstanceOf[Number].longValue(),
if(avgChannelExpressBillTotalCount.isNullAt(0)) 0L else avgChannelExpressBillTotalCount.get(0).asInstanceOf[Number].longValue(),
if(maxTerminalExpressBillTotalCount.isNullAt(0)) 0L else maxTerminalExpressBillTotalCount.get(0).asInstanceOf[Number].longValue(),
if(minTerminalExpressBillTotalCount.isNullAt(0)) 0L else minTerminalExpressBillTotalCount.get(0).asInstanceOf[Number].longValue(),
if(avgTerminalExpressBillTotalCount.isNullAt(0)) 0L else avgTerminalExpressBillTotalCount.get(0).asInstanceOf[Number].longValue()
)
println(rowInfo)
//将计算好的结果数据写入到结果对象中
rows.append(rowInfo)
//释放资源
expressBillDetailByDayDF.unpersist()
customerTypeExpressBillTotalCountDF.unpersist()
dotExpressBillTotalCountDF.unpersist()
channelExpressBillTotalCountDF.unpersist()
terminalExpressBillTotalCountDF.unpersist()
)通过StructType构建指定Schema
//创建DataFrame:schema+rdd(数据)
//定义指标结果的schema信息
val schema: StructType = StructType(Array(
StructField("id", StringType, false, Metadata.empty),
StructField("totalExpressBillCount", LongType, false, Metadata.empty),
StructField("maxTypeExpressBillTotalCount", LongType, false, Metadata.empty),
StructField("minTypeExpressBillTotalCount", LongType, false, Metadata.empty),
StructField("avgTypeExpressBillTotalCount", LongType, false, Metadata.empty),
StructField("maxDotExpressBillTotalCount", LongType, false, Metadata.empty),
StructField("minDotExpressBillTotalCount", LongType, false, Metadata.empty),
StructField("avgDotExpressBillTotalCount", LongType, false, Metadata.empty),
StructField("maxChannelExpressBillTotalCount", LongType, false, Metadata.empty),
StructField("minChannelExpressBillTotalCount", LongType, false, Metadata.empty),
StructField("avgChannelExpressBillTotalCount", LongType, false, Metadata.empty),
StructField("maxTerminalExpressBillTotalCount", LongType, false, Metadata.empty),
StructField("minTerminalExpressBillTotalCount", LongType, false, Metadata.empty),
StructField("avgTerminalExpressBillTotalCount", LongType, false, Metadata.empty)
))持久化指标数据到kudu表
//将数据转换成rdd对象
val data: RDD[Row] = sparkSession.sparkContext.makeRDD(rows)
//根据表结构和数据创建DataFrame对象
val quotaDF: DataFrame = sparkSession.createDataFrame(data, schema)
//TODO 5)将计算好的指标数据写入到kudu数据库中
//将dataframe数据写入到kudu数据库
save(quotaDF, OfflineTableDefine.expressBillSummary)删除缓存数据
//TODO 6)删除缓存数据
以上是关于客快物流大数据项目(六十三):快递单主题的主要内容,如果未能解决你的问题,请参考以下文章