客快物流大数据项目(六十二):主题及指标开发
Posted Lansonli
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了客快物流大数据项目(六十二):主题及指标开发相关的知识,希望对你有一定的参考价值。
目录
主题及指标开发
一、主题开发业务流程
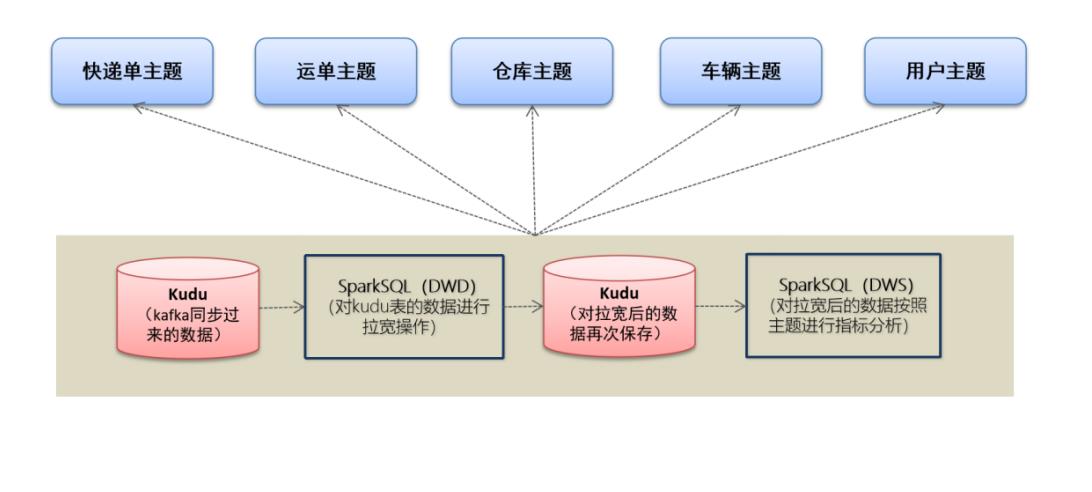
二、离线模块初始化
1、创建包结构
本次项目采用scala编程语言,因此创建scala目录
| 包名 | 说明 |
| cn.it.logistics.offline | 离线指标统计程序所在包 |
| cn.it.logistics.offline.dwd | 离线指标dwd层程序所在包 |
| cn.it.logistics.offline.dws | 离线指标dws层程序所在包 |
2、创建时间处理工具
实现步骤:
- 在公共模块的scala目录下的common程序包下创建DateHelper对象
- 实现获取当前日期
- 实现获取昨天日期
package cn.it.logistics.common
import java.text.SimpleDateFormat
import java.util.Date
/**
* 时间处理工具类
*/
object DateHelper
/**
* 返回昨天的时间
*/
def getyesterday(format:String)=
//当前时间减去一天(昨天时间)
new SimpleDateFormat(format).format(new Date(System.currentTimeMillis() - 1000 * 60 * 60 * 24))
/**
* 返回今天的时间
* @param format
*/
def gettoday(format:String) =
//获取指定格式的当前时间
new SimpleDateFormat(format).format(new Date)
3、定义主题宽表及指标结果表的表名
每个主题都需要拉宽操作将拉宽后的数据存储到kudu表中,同时指标计算的数据最终也需要落地到kudu表,因此提前将各个主题相关表名定义出来
实现步骤:
- 在公共模块的scala目录下的common程序包下创建OfflineTableDefine单例对象
- 定义各个主题相关的表名
参考代码:
package cn.it.logistics.common
/**
* 自定义离线计算结果表
*/
object OfflineTableDefine
//快递单明细表
val expressBillDetail = "tbl_express_bill_detail"
//快递单指标结果表
val expressBillSummary = "tbl_express_bill_summary"
//运单明细表
val wayBillDetail = "tbl_waybill_detail"
//运单指标结果表
val wayBillSummary = "tbl_waybill_summary"
//仓库明细表
val wareHouseDetail = "tbl_warehouse_detail"
//仓库指标结果表
val wareHouseSummary = "tbl_warehouse_summary"
//网点车辆明细表
val dotTransportToolDetail = "tbl_dot_transport_tool_detail"
//仓库车辆明细表
val warehouseTransportToolDetail = "tbl_warehouse_transport_tool_detail"
//网点车辆指标结果表
val ttDotSummary = "tbl_dot_transport_tool_summary"
//仓库车辆指标结果表
val ttWsSummary = "tbl_warehouse_transport_tool_summary"
//客户明细表数据
val customerDetail = "tbl_customer_detail"
//客户指标结果表数据
val customerSummery = "tbl_customer_summary"
4、物流字典码表数据类型定义枚举类
为了后续使用方便且易于维护,根据物流字典表的数据类型定义成枚举工具类,物流字典表的数据如下:
来自:tbl_codes表
| name | type |
| 注册渠道 | 1 |
| 揽件状态 | 2 |
| 派件状态 | 3 |
| 快递员状态 | 4 |
| 地址类型 | 5 |
| 网点状态 | 6 |
| 员工状态 | 7 |
| 是否保价 | 8 |
| 运输工具类型 | 9 |
| 运输工具状态 | 10 |
| 仓库类型 | 11 |
| 是否租赁 | 12 |
| 货架状态 | 13 |
| 回执单状态 | 14 |
| 出入库类型 | 15 |
| 客户类型 | 16 |
| 下单终端类型 | 17 |
| 下单渠道类型 | 18 |
实现步骤:
- 在公共模块的scala目录下的common程序包下创建CodeTypeMapping对象
- 根据物流字典表数据类型定义属性
实现过程:
- 在公共模块的scala目录下的common程序包下创建CodeTypeMapping对象
- 根据物流字典表数据类型定义属性
package cn.it.logistics.common
/**
* 定义物流字典编码类型映射工具类
*/
class CodeTypeMapping
//注册渠道
val RegisterChannel = 1
//揽件状态
val CollectStatus = 2
//派件状态
val DispatchStatus = 3
//快递员状态
val CourierStatus = 4
//地址类型
val AddressType = 5
//网点状态
val DotStatus = 6
//员工状态
val StaffStatus = 7
//是否保价
val IsInsured = 8
//运输工具类型
val TransportType = 9
//运输工具状态
val TransportStatus = 10
//仓库类型
val WareHouseType = 11
//是否租赁
val IsRent = 12
//货架状态
val GoodsShelvesStatue = 13
//回执单状态
val ReceiptStatus = 14
//出入库类型
val WarehousingType = 15
//客户类型
val CustomType = 16
//下单终端类型
val OrderTerminalType = 17
//下单渠道类型
val OrderChannelType = 18
object CodeTypeMapping extends CodeTypeMapping
5、封装公共接口
根据分析:主题开发数据的来源都是来自于kudu数据库,将数据进行拉宽或者将计算好的指标最终需要写入到kudu表中,因此根据以上流程抽象出来公共接口
实现步骤:
- 在offline目录下创建OfflineApp单例对象
- 定义数据的读取方法:getKuduSource
- 定义数据的处理方法:execute
- 定义数据的存储方法:save
参考代码:
package cn.it.logistics.offline
import cn.it.logistics.common.Configuration, DateHelper, Tools
import org.apache.spark.sql.DataFrame, SaveMode, SparkSession
import org.apache.spark.sql.functions.col, date_format
/**
* 根据不同的主题开发定义抽象方法
* 1)数据读取
* 2)数据处理
* 3)数据保存
*/
trait OfflineApp
/**
* 读取kudu表的数据
* @param sparkSession
* @param tableName
* @param isLoadFullData
*/
def getKuduSource(sparkSession: SparkSession, tableName:String, isLoadFullData:Boolean = false)=
if (isLoadFullData)
//加载全部的数据
sparkSession.read.format(Configuration.SPARK_KUDU_FORMAT).options(
Map(
"kudu.master" -> Configuration.kuduRpcAddress,
"kudu.table" -> tableName,
"kudu.socketReadTimeoutMs"-> "60000")
).load().toDF()
else
//加载增量数据
sparkSession.read.format(Configuration.SPARK_KUDU_FORMAT).options(
Map(
"kudu.master" -> Configuration.kuduRpcAddress,
"kudu.table" -> tableName,
"kudu.socketReadTimeoutMs"-> "60000")
).load()
.where(date_format(col("cdt"), "yyyyMMdd") === DateHelper.getyesterday("yyyyMMdd")).toDF()
/**
* 数据处理
* @param sparkSession
*/
def execute(sparkSession: SparkSession)
/**
* 数据存储
* dwd及dws层的数据都是需要写入到kudu数据库中,写入逻辑相同
* @param dataFrame
* @param isAutoCreateTable
*/
def save(dataFrame:DataFrame, tableName:String, isAutoCreateTable:Boolean = true): Unit =
//允许自动创建表
if (isAutoCreateTable)
Tools.autoCreateKuduTable(tableName, dataFrame)
//将数据写入到kudu中
dataFrame.write.format(Configuration.SPARK_KUDU_FORMAT).options(Map(
"kudu.master" -> Configuration.kuduRpcAddress,
"kudu.table" -> tableName
)).mode(SaveMode.Append).save()

- 📢博客主页:https://lansonli.blog.csdn.net
- 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
- 📢本文由 Lansonli 原创,首发于 CSDN博客🙉
- 📢大数据系列文章会每天更新,停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨
以上是关于客快物流大数据项目(六十二):主题及指标开发的主要内容,如果未能解决你的问题,请参考以下文章