自动驾驶 Apollo 源码分析系列,系统监控篇:Monitor模块如何监控通信中 channel 的时延?
Posted frank909
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自动驾驶 Apollo 源码分析系列,系统监控篇:Monitor模块如何监控通信中 channel 的时延?相关的知识,希望对你有一定的参考价值。
上一篇文章分析了 Apollo 框架中 Monitor 模块如何监控硬件,这篇文章继续分析 Monitor 是如何监控软件的,数据通信中 channel 是本文主要分析对象。
1. 受监控的内容
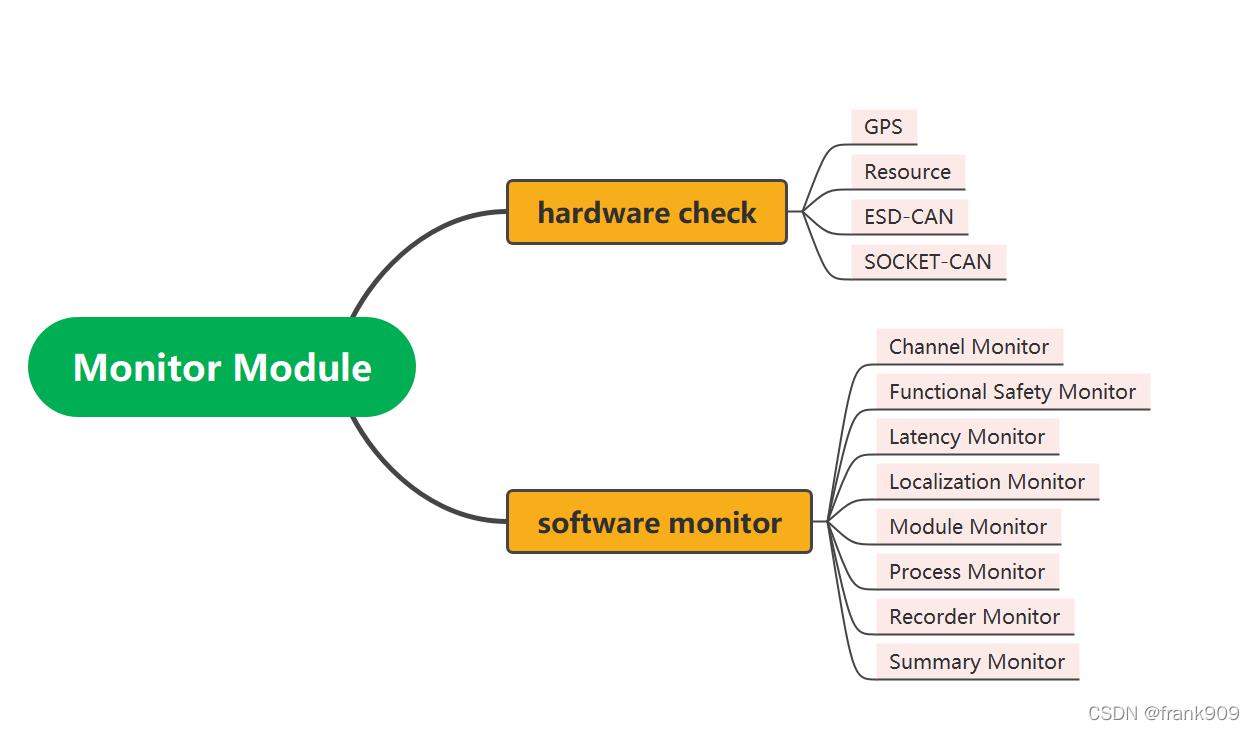
上图是之前的文章总结的,可以看到软件监控有 8 类对象:
- Channel Monitor 数据通信频道监控
- Functional Safety Monitor 功能安全监控
- Latency Monitor 时延监控
- Localization Monitor 定位监控
- Module Monitor 模块监控
- Process Monitor 监控
- Recorder Monitor 数据记录监控
- Summary Monitor 监控状态汇总
因为前面的文章已经分析了 Functional Safety Monitor 和 Summary Monitor,所以,这篇文章我们着重看看其他受监控的内容,本文分析 Channel 和 Latency 两个部分内容。
2. Apollo 如何监控数据通信状态?
Channel 是 CyberRT 中的通信渠道,它的监控是配合 LatencyMonitor 一起使用的。
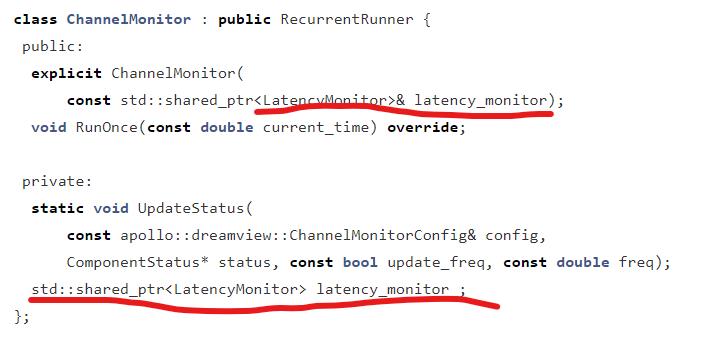
由于它没有复写 tick() 方法,所以,每次定时触发周期,RunOnce() 方法都会被执行。
相关的定时参数如下:
DEFINE_double(channel_monitor_interval, 5,
"Channel monitor checking interval in seconds.");
每 5 秒监测一次。
我有在思考,这些监测周期时间都很长,这是为什么?
也许只适合低速场景吧。

整个流程分为 3 个步骤:
- 从 HMI 中获取要被监控的 channel
- 通过 LatencyMonitor 去查询 channel 的频率
- 通过 update_freq 和 freq 更新 channel 的时延状态
所以,关键是获取 update_freq 和 freq 两个参数的赋值过程。

如果 LatencyMonitor 在自身查询到了相应 channel 的频率,则赋值给 freq,然后返回 true,否则返回 false。
有了这两个参数后,后面的逻辑判断就交给了 UpdateStatus()。

逻辑是什么呢?

- 通过 channel 的名字获取相应的 Reader 和最后一条 msg
- 判断是否有 Reader,如果没有提示这个channel 没有注册,并返回
- 通过 reader 判断时延,如果小于0或者大于则设置状态为 FATAL
- 通过判断 msg 相应的 field 内容是否有缺失,如果有则设置为状态为 ERROR
- 通过判断 freq 的值是否在合理的最小与最大范围内,如果不是则设置状态为 WARN
- 一切正常则判断为 OK
因为 SummaryMonitor 的评估提升状态时,不同的状态是为权重的,并且可以向下覆盖,比如FATAL 可以覆盖小于它的其它状态,ERROR 不能覆盖 FATAL 但能覆盖 WARN 和 OK 、UNKOWN。
到这里 Channel 如何被监控大的逻辑就弄清楚了,但还有 2 个小细节需要弄明白。
- channel 配套的 Reader 和最后一条 msg
- LatencyMonitor 工作流程
2.1 监控的 channel 和 reader
代码通过 GetReaderAndLatestMessage(const std::string& channel) 实现。

通过 MonitorManager 去创建不同的 Reader,然后开始观测,并获取这个 channel 最后一次信息,然后保存下来并返回。
通过整理可得,通过配置变量信息决定是否创建相应的 Reader。这些变量有:
i(channel == FLAGS_control_command_topic)
f (channel == FLAGS_localization_topic)
channel == FLAGS_perception_obstacle_topic)
(channel == FLAGS_prediction_topic)
(channel == FLAGS_planning_trajectory_topic)
(channel == FLAGS_conti_radar_topic)
(channel == FLAGS_relative_map_topic)
(channel == FLAGS_pointcloud_topic ||
channel == FLAGS_pointcloud_128_topic ||
channel == FLAGS_pointcloud_16_front_up_topic)
包含了感知数据、定位、预测、规划、控制 topic 相关。
3. 时延监控 LatencyMonitor 逻辑
前面内容有提到,ChannelMonitor 内部要借助 LatencyMonitor 提供的数据做一些判断,那么这个小节讨论的就是 LatencyMonitor 如何产生时延数据。

LatencyMonitor 也是周期性执行任务的模块,不过相比其它的 Monitor,它额外实现了 3 个方法:
GetFrequency()
PublishLatencyReport()
AggregateLatency()
我们至少能知道,它内部要聚合各种时延,然后会定期发布时延报告。并且有一个服务类的API供其它类进行频率查询。
DEFINE_double(latency_monitor_interval, 1.5,
"Latency report interval in seconds.");
DEFINE_double(latency_report_interval, 15.0,
"Latency report interval in seconds.");
DEFINE_int32(latency_reader_capacity, 30,
"The max message numbers in latency reader queue.");
监控时延的周期是每 1.5s 一次,时延报告发布周期是每15s一次,时延相关的reader队列容量是30。

LatencyMonitor 在每次触发 RunOnce() 方法时会创建一个 reader 用来监控 latency recording topic,它是由相应的 proto 文件定义。

我们先看 LatencyRecord 它里面有 3 条信息:
- 开始时间 begin_time
- 结束时间 end_time
- 信息的 id
LatencyRecordMap 信息丰富一些,它包含:
- 消息头 header
- 模块名字
- LatencyRecord 数组
LatencyMonitor 读取的是每个监测周期内每个 LatencyRecordMap 中所有 LatencyRecord 的耗时。
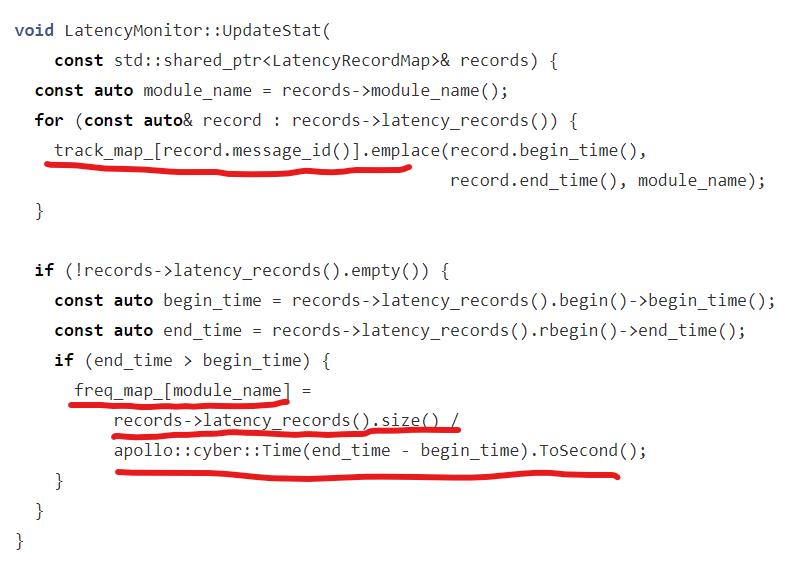
主要做了 2 件事。
- 保存每个 msg 的耗时信息到 track_map_
- 更新 freq_map 中模块的频率信息
我们重点关注第 2 个逻辑,也是前面内容分析到的 channelmonitor 会主动来查询 freqmap 中的值。
这个逻辑就是一个 LatencyRecordMap 中有一组 LatencyRecord,获取第一条记录中的开始时间,获取最后一条的结束时间。
如果结束时间大于开始时间,表明通信没有紊乱,频率值由下面公式计算:
freq = size/durantion
比如总共有 5 条记录,5 条记录总共耗时 10s。那么频率就是 5/10 = 0.5也就是1/2,代表什么呢?代表的是 1s 内只能传0.5 条信息。
3.1 定期发布时延报告
RunOnce 运行时会根据传入的 currenttime 和 flush_time_之差与定期报告的时长作比较,如果大于后者则需要对外发布时延信息。

在发布时延报告前,先要内部聚合一下信息,然后通过创建的 LatencyReport writer 发送出去。
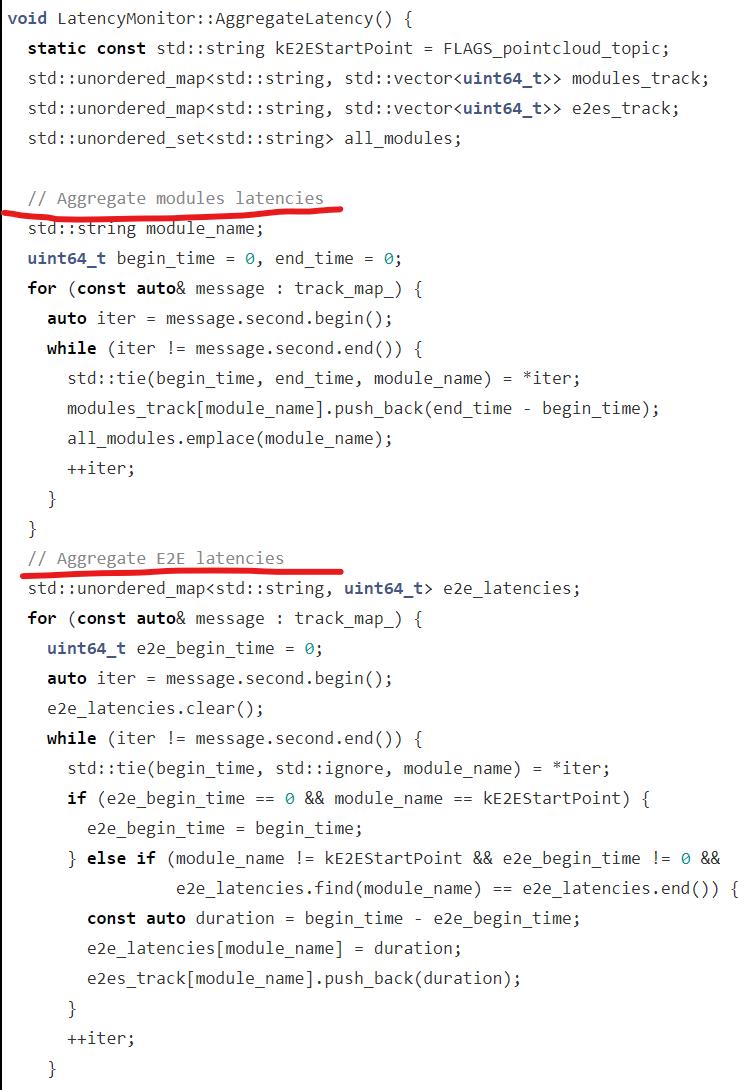
主要是聚合模块的时延和 E2E 的时延。
E2E 是什么呢?是从点云信息到各个模块输出的时间,也就是端到端时间。
这里有个重要的变量kE2EStartPoint 。
它是什么呢?其实是一条字符串,它被赋值为FLAGS_pointcloud_topic。也就是:

E2E Latency 的逻辑:
- 记录第一条点云数据的开始时间
- 依次记录那些不是点云数据的记录的开始时间,计算它们之间的差值,就成了这一个测试周期的 E2E 时延。

上面的注释指定了最终模块时延和端到端时延的格式,由 SetLatency() 方法实现。

代码比较简单,这里就不重复讲述了。
自此,LatencyMonitor 部分也讲完了。
4. 总结
- Channel 监控时主要是监控注册过的 channel,通过判断它的时延、内容、频率形成最终的状态报告。
- Latency 也是需要读取相关的 Topic,通过根据不同的 Topic 时间信息产生模块时延和端到端时延。
- Channel 和 Latency 的运行基于依靠于 CyberRT 的通信,所以,也必须保证 CyberRT 的 Channel 通信机制足够可靠,不然会产生误差。
以上是关于自动驾驶 Apollo 源码分析系列,系统监控篇:Monitor模块如何监控通信中 channel 的时延?的主要内容,如果未能解决你的问题,请参考以下文章
自动驾驶 Apollo 源码分析系列,系统监控篇:Monitor模块如何监控硬件
自动驾驶 Apollo 源码分析系列,系统监控篇:Monitor模块如何监控通信中 channel 的时延?
自动驾驶 Apollo 源码分析系列,系统监控篇:Monitor模块如何监控通信中 channel 的时延?
自动驾驶 Apollo 源码分析系列,系统监控篇:Monitor模块如何监控通信中 channel 的时延?