强化学习 马尔科夫决策过程
Posted 好奇小圈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了强化学习 马尔科夫决策过程相关的知识,希望对你有一定的参考价值。
文章目录
一、Markov Decision Process(MDP)
1.简介
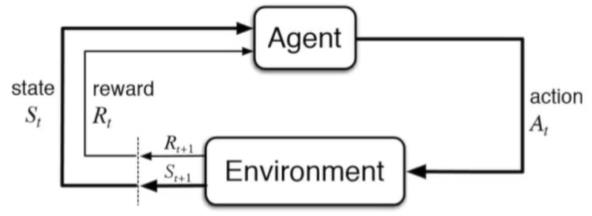
1.Markov Decision Process can model a lot of real-world problem. lt formally describes the framework of reinforcement learning
2.Under MDP, the environment is fully observable.
2.1Optimal control primarily deals with continuous MDPs.
2.2Partially observable problems can be converted into MDPs.
2、Markov 特性
1.历史状态ht=s1,s2,s3,……,st
2.状态st有且仅有:
p ( st+1 | st )=p ( st+1 | ht )
p ( st+1 | st , at )=p ( st+1 | ht , at )
3.“考虑到现在,未来是独立于过去的”
3、Markov 过程
马尔科夫链+奖励
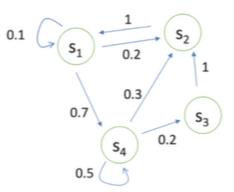
状态转移矩阵 P 表现为p ( st+1 = s’ | st = s )

4、Markov决策
马尔科夫链+奖励+行为


约定表达:
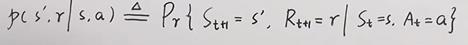
状态转移函数:

策略分为:确定性策略a=π(s)、随机性策略π(a|s)=PAt=a|St=s
回报:
既当前的奖励会影响到后续,但“时间是治愈伤痛的良药”,因此引入折扣。
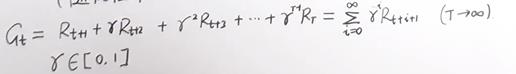
实际根据随机性策略可知,我们的选择分支很多,因此提出“价值函数”。
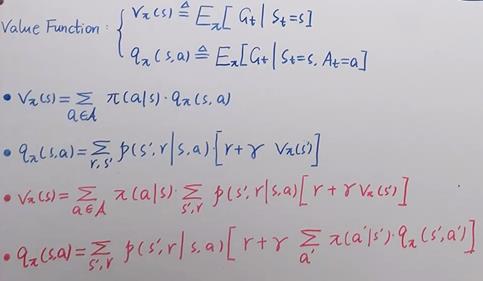
其中红色部分为贝尔曼期望(普通)方程。
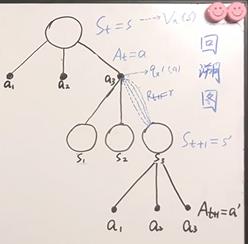
回溯图:
贝尔曼最优价值函数:
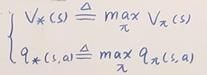
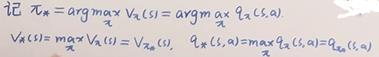
其中:
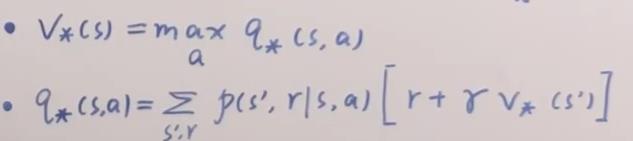
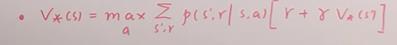
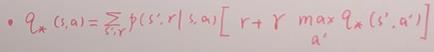
以上是关于强化学习 马尔科夫决策过程的主要内容,如果未能解决你的问题,请参考以下文章