FlinkFlink Streaming File Sink
Posted 九师兄
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了FlinkFlink Streaming File Sink相关的知识,希望对你有一定的参考价值。

1.概述
类似文章:【Flink】Flink StreamingFileSink
2.背景
Flink 支持将流数据以文件形式存储到外部系统,典型使用场景是将数据写入Hive表所在 HDFS存储路径,通过Hive 做查询分析。随着Flink文件写入被业务广泛使用,暴露出很多问题,因此需要了解 Flink Streaming File sink 的实现逻辑。
3.案例
从Kafka消费JSON数据,转换为 UserInfo 实体类数据流,最终以Parquet 格式写入Hive表对应的HDFS路径。使用 Flink 1.12.1,Hadoop 2.8.0, hive 2.3.8。
-----------------------------
- hive 建表语句
-----------------------------
create table userinfo(
userid int,
username string
) stored as parquet;
-----------------------------
- java 实体类
-----------------------------
public class UserInfo
private int userId;
private String userName;
public int getUserId()
return userId;
public void setUserId(int userId)
this.userId = userId;
public String getUserName()
return userName;
public void setUserName(String userName)
this.userName = userName;
@Override
public String toString()
return "UserInfo" +
"userId=" + userId +
", userName='" + userName + '\\'' +
'';
-----------------------------
- Flink 文件写入程序
-----------------------------
public class Kafka2Parquet
public static void main(String[] args) throws Exception
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Properties props = new Properties();
props.setProperty("bootstrap.servers", "localhost:9092");
props.setProperty("group.id", "test_001");
env.setParallelism(1);
env.enableCheckpointing(30000);
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3,2000));
env.setStateBackend(new FsStateBackend("hdfs://localhost:9000/user/todd/checkpoint"));
FlinkKafkaConsumer<String> dataStream = new FlinkKafkaConsumer("mqTest02", new SimpleStringSchema(), props);
dataStream.setStartFromLatest();
DataStream<UserInfo> userInfoDataStream = env.addSource(dataStream)
.map(value -> JsonUtils.parseJson(value, UserInfo.class));
// 1. 设置BulkFormat Builder 2.使用 CheckpointRollingPolicy
StreamingFileSink<UserInfo> parquetSink = StreamingFileSink
.forBulkFormat(new Path("hdfs://localhost:9000/user/hive/warehouse/userinfo"), ParquetAvroWriters.forReflectRecord(UserInfo.class))
.withRollingPolicy(OnCheckpointRollingPolicy.build())
.build();
userInfoDataStream.addSink(parquetSink);
env.execute();
-----------------------------
- 生成的parquet 文件名称及路径
-----------------------------
inprogress 临时文件
hdfs://localhost:9000/user/hive/warehouse/userinfo/2021-08-09--19/.part-0-0.inprogress.18296793-9fde-4376-b6fc-7c47512bd108
part 最终文件
hdfs://localhost:9000/user/hive/warehouse/userinfo/2021-08-09--19/part-0-0
4. 核心类
-
BulkWriter:用于不同格式的数据文件批量写入,主要实现类ParquetBulkWriter、AvroBulkWriter、OrcBulkWriter、SequenceFileWriter代表了数据写入的压缩格式。
-
RecoverableWriter: 具有失败恢复能力的外部文件系统写入器,主要实现类HadoopRecoverableWriter、S3RecoverableWriter、LocalRecoverableWriter,代表对不同类型文件系统的操作。
-
BulkPartWriter:InProgressFileWriter 实现类用来向inprogress文件写数据,持有BulkWriter。
-
OutputStreamBasedPartFileWriter:Part Writer 基类,使用 RecoverableFsDataOutputStream 写出数据。
-
RecoverableFsDataOutputStream:文件系统输出流,能够从文件系统的指定偏移量进行数据写入。
-
BucketAssigner:负责将数据划分到不同的Bucket,可以根据数据格式自定义Assigner。内部集成 SimpleVersionedSerializer,用来对BucketID 做序列化/反序列化操作。
a. BucketAssigner 子类 DateTimeBucketAssigner 根据数据的ProcessTime 生成 yyyy-MM-dd–HH 格式的 Bucket 名称。同时使用 SimpleVersionedStringSerializer 对Bucket 名称序列化。 -
Bucket:StreamingFileSink数据输出的目录,每一条处理的数据根据BucketAssigner被分配到某个Bucket。主要功能:
1. 维护一份 InProgressFile 文件,负责该文件的创建、数据写入、
提交写入。
2. 在 StreamingFileSink 执行Checkpoint时,负责构建 BucketState
进而进行该状态序列化 。
3. 在 StreamingFileSink Checkpoint 完成后,重命名 InProgressFile 文件,
4. 在 StreamingFileSink 从savepoint 启动时,从 BucketState
恢复 InProgressFile 相关信息。
-
BucketState: Bucket的状态信息。通过BucketState能够恢复Bucket inprogress 文件及当前写入偏移量,从而继续向该 inprogress文件中追加内容,同时能够恢复 Pending状态文件信息,从而继续执行后续重名逻辑。
-
Buckets:负责管理 StreamingFileSink 中所有活跃状态的 Bucket。包括数据所在Bucket 分配,Active Bucket 快照状态存储。
-
RollingPolicy:定义了buckt 生成新的in-progress文件、及将in-progress 文件变更为最终part文件的策略。 最常用的策略是CheckpointRollingPolicy,在每次Checkpoint完成时,根据in-progress文件生成part文件。
-
StreamingFileSinkHelper:StreamingFileSink 调用 StreamingFileSinkHelper 方法完成对Buckets数据的写入及状态存储。
-
StreamingFileSink:根据BucketsBuilder构造器创建Buckets,初始化时创建StreamingFileSinkHelper,在Sink、checkpoint 方法中调用 StreamingFileSinkHelper 接口。
5.数据写入
Flink写文件流程为,先将数据写入inprogress临时文件,在满足RollingPolicy时,将inprogress临时文件重命名为最终的part文件。
参考Flink1.12.1版本的代码,学习下 Flink 将数据写入文件的具体流程。
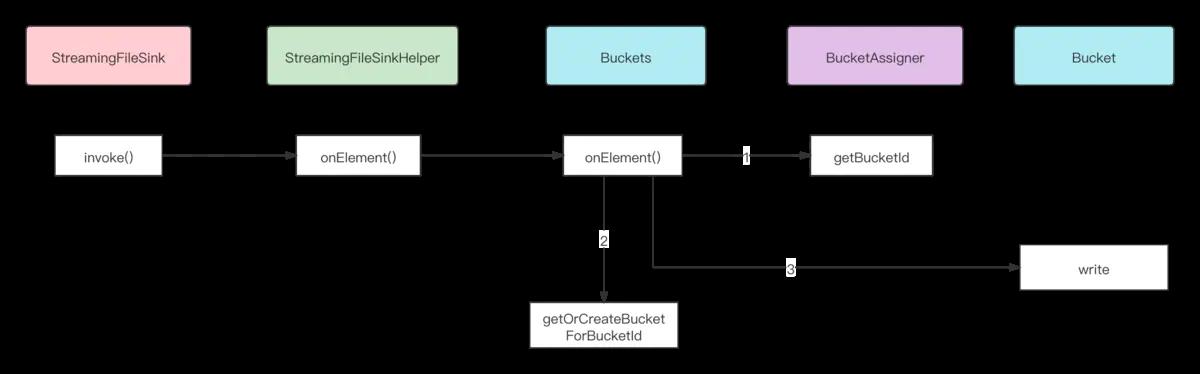
StreamingFileSink 执行 invoke() 方法处理数据,是通过调用 StreamingFileSinkHelper onElement()方法对 Buckets 进行操作。
functions.sink.filesystem.Buckets#onElement
public Bucket<IN, BucketID> onElement(
final IN value,
final long currentProcessingTime,
@Nullable final Long elementTimestamp,
final long currentWatermark)
throws Exception
// note: 获取当前数据所在的 BucketID, 即被被分桶后的子文件夹名称
final BucketID bucketId = bucketAssigner.getBucketId(value, bucketerContext);
// note: 从已缓存的集合中获取Bucket 或者 新建Bucket并缓存
final Bucket<IN, BucketID> bucket = getOrCreateBucketForBucketId(bucketId);
// note: 将数据写入具体 bucket
bucket.write(value, currentProcessingTime);
return bucket;
Buckets 处理数据时,需要根据定义的 BucketAssigner 获取数据所在的 Bucket 标识。上述案例使用了 DateTimeBucketAssigner 了解下它如何根据ProcessTime 获取 BucketID。
bucketassigners.DateTimeBucketAssigner#getBucketId
public String getBucketId(IN element, BucketAssigner.Context context)
if (dateTimeFormatter == null)
// note: 将Processing Time 转换为 yyyy-MM-dd--HH 格式
dateTimeFormatter = DateTimeFormatter.ofPattern(formatString).withZone(zoneId);
return dateTimeFormatter.format(Instant.ofEpochMilli(context.currentProcessingTime()));
根据 BucketID 从Buckets 中拿到有效的Bucket。
filesystem.Buckets#getOrCreateBucketForBucketId
private Bucket<IN, BucketID> getOrCreateBucketForBucketId(final BucketID bucketId)
throws IOException
Bucket<IN, BucketID> bucket = activeBuckets.get(bucketId);
if (bucket == null)
// note: 构建buckt所在完整路径,例如 hdfs://localhost:9000/user/hive/warehouse/userinfo/2020-08-08--14
final Path bucketPath = assembleBucketPath(bucketId);
// note: 创建 Bucket 并由activeBuckets缓存
bucket =
bucketFactory.getNewBucket(
subtaskIndex,
bucketId,
bucketPath,
maxPartCounter,
bucketWriter,
rollingPolicy,
fileLifeCycleListener,
outputFileConfig);
activeBuckets.put(bucketId, bucket);
notifyBucketCreate(bucket);
return bucket;
初次向Bucket写入数据,需要创建part的临时文件及用来向文件写数据的InProgressFileWriter对象,同时创建BulkWriter,用来进行数据写入。
- 创建临时文件:根据inprocess文件生成规则,在HadoopRecoverableFsDataOutputStream初始化时创建并返回针对该文件的DataOutputStream。
- 创建BulkWriter:当前案例中由ParquetWriterFactory工厂类创建ParquetBulkWriter,并传递临时文件对应的DataOutputStream。
sinkfilesystem.Bucket#write
void write(IN element, long currentTime) throws IOException
if (inProgressPart == null || rollingPolicy.shouldRollOnEvent(inProgressPart, element))
inProgressPart = rollPartFile(currentTime);
//note: BulkPartWriter使用 BulkWriter 写入数据。
inProgressPart.write(element, currentTime);
private InProgressFileWriter<IN, BucketID> rollPartFile(final long currentTime)
throws IOException
// note: 关闭part文件。
closePartFile();
final Path partFilePath = assembleNewPartPath();
// note: 创建InProgressFileWriter
return bucketWriter.openNewInProgressFile(bucketId, partFilePath, currentTime);
// 创建BulkPartWriter 使用BulkWriter进行数据写入,
OutputStreamBasedBucketWriter#openNewInProgressFile
public InProgressFileWriter<IN, BucketID> openNewInProgressFile(
final BucketID bucketID, final Path path, final long creationTime)
throws IOException
// note: 根据的inprocess文件路径,由recoverableWriter创建。
return openNew(bucketID, recoverableWriter.open(path), path, creationTime);
public InProgressFileWriter<IN, BucketID> openNew(
final BucketID bucketId,
final RecoverableFsDataOutputStream stream,
final Path path,
final long creationTime)
throws IOException
final BulkWriter<IN> writer = writerFactory.create(stream);
return new BulkPartWriter<>(bucketId, stream, writer, creationTime);
// 创建hdfs文件系统临时文件,针对该文件创建 RecoverableFsDataOutputStream
HadoopRecoverableWriter#open
public RecoverableFsDataOutputStream open(Path filePath) throws IOException
final org.apache.hadoop.fs.Path targetFile = HadoopFileSystem.toHadoopPath(filePath);
final org.apache.hadoop.fs.Path tempFile = generateStagingTempFilePath(fs, targetFile);
return new HadoopRecoverableFsDataOutputStream(fs, targetFile, tempFile);
HadoopRecoverableFsDataOutputStream(FileSystem fs, Path targetFile, Path tempFile)
throws IOException
// note: 确保hadoop 支持 truncate方法
ensureTruncateInitialized();
this.fs = checkNotNull(fs);
this.targetFile = checkNotNull(targetFile);
this.tempFile = checkNotNull(tempFile);
// 创建临时文件
this.out = fs.create(tempFile);
将数据以parquet格式写入临时文件,调用链路比较长中间涉及不少工厂类及代理类,最终调用的还是parquet框架本身的API。
filesystem.BulkPartWriter#write
public void write(IN element, long currentTime) throws IOException
writer.addElement(element);
markWrite(currentTime);
parquet.ParquetBulkWriter#addElement
public void addElement(T datum) throws IOException
// note: org.apache.parquet.hadoop.ParquetWriter
parquetWriter.write(datum);
6.checkpoint 过程
在生产环境中大多使用 OnCheckpointRollingPolicy 策略,即在执行Checkpoint时存储BucketState,提交已写入的数据记录已写入数据的偏移量,在CK完成后将 inprogress 文件重命名为最终 part 文件。
根据Checkpoint生命周期方法,了解执行过程。

- initializeState 创建StreamingFileSinkHelper,做一些初始化工作。如果从已有的状态快照启动,会对BucketStates进行恢复,稍后详细介绍快照恢复的逻辑,先看状态快照中存储了什么信息,及后续逻辑。
- snapshotState 状态快照存储。Buckets 的 snapshotState() 会保存序列化后的 BucketState 及当前子任务处理的最大part文件个数。
public void snapshotState(
final long checkpointId,
final ListState<byte[]> bucketStatesContainer,
final ListState<Long> partCounterStateContainer)
throws Exception
// note: 清理历史状态信息
bucketStatesContainer.clear();
partCounterStateContainer.clear();
// note: 将 BucketState 以二进制格式存储到 bucketStatesContainer
snapshotActiveBuckets(checkpointId, bucketStatesContainer);
// note: 存储当前任务处理的最大文件数
partCounterStateContainer.add(maxPartCounter);
private void snapshotActiveBuckets(
final long checkpointId, final ListState<byte[]> bucketStatesContainer)
throws Exception
for (Bucket<IN, BucketID> bucket : activeBuckets.values())
//note: 每个正在使用的Bucket会生成BucketState
final BucketState<BucketID> bucketState = bucket.onReceptionOfCheckpoint(checkpointId);
// note: 将BucketState 序列化后存储到 ListState
final byte[] serializedBucketState =
SimpleVersionedSerialization.writeVersionAndSerialize(
bucketStateSerializer, bucketState);
bucketStatesContainer.add(serializedBucketState);
BucketState<BucketID> onReceptionOfCheckpoint(long checkpointId) throws IOException
//note: 关闭 inProgressPart, 填充BucketState 使用的属性信息
prepareBucketForCheckpointing(checkpointId);
//note: ck 期间有数据写入。
if (inProgressPart != null)
inProgressFileRecoverable = inProgressPart.persist();
inProgressFileCreationTime = inProgressPart.getCreationTime();
this.inProgressFileRecoverablesPerCheckpoint.put(
checkpointId, inProgressFileRecoverable);
// note: 构建出BucketState
return new BucketState<>(
bucketId,
bucketPath,
inProgressFileCreationTime,
inProgressFileRecoverable,
pendingFileRecoverablesPerCheckpoint);
private void prepareBucketForCheckpointing(long checkpointId) throws IOException
if (inProgressPart != null && rollingPolicy.shouldRollOnCheckpoint(inProgressPart))
closePartFile();
// note: closePartFile()会将生成的 pendingFileRecoverable 写入pendingFileRecoverablesForCurrentCheckpoint
if (!pendingFileRecoverablesForCurrentCheckpoint.isEmpty())
pendingFileRecoverablesPerCheckpoint.put(
checkpointId, pendingFileRecoverablesForCurrentCheckpoint);
pendingFileRecoverablesForCurrentCheckpoint = new ArrayList<>();
closePartFile() 主要处理工作包含:
- 使用 BulkWriter 将数据 flush 到外部文件。
- 基于当前 inprogressPart 创建出PendingFileRecoverable对象,其中封装了 HadoopFsRecoverable 对包含了targetFile(part文件)、tempFile(inprogress文件)、offset(数据当前写入的偏移量)属性,是最重要的状态信息。在checkpoint完成后,会将tempFile命名为targetFile。
- 关闭inprogressPart,填充 pendingFileRecoverablesForCurrentCheckpoint信息,代表当前CK正在处理的 inprogressPart文件。
private InProgressFileWriter.PendingFileRecoverable closePartFile() throws IOException
InProgressFileWriter.PendingFileRecoverable pendingFileRecoverable = null;
if (inProgressPart != null)
//note: 和inProgressPart文件一一对应
pendingFileRecoverable = inProgressPart.closeForCommit();
//note: 存储到LIST
pendingFileRecoverablesForCurrentCheckpoint.add(pendingFileRecoverable);
inProgressPart = null;
return pendingFileRecoverable;
FlinkFlink SQL 开源UI平台 flink-streaming-platform-web
FlinkFlink AscendingTimestampExtractor - Timestamp monotony violated
FlinkFlink TaskManager 一直 User file cache uses directory
FlinkFlink 写入 kafka 报错 The server disconnected before a response was received
FlinkFlink SQL Cannot instantiate user function cannot assign instance LinkedMap FlinkKafkaConsum