SparkSQL高并发:读取存储数据库
Posted 华为云开发者社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SparkSQL高并发:读取存储数据库相关的知识,希望对你有一定的参考价值。
摘要:实践解析如何利用SarkSQL高并发进行读取数据库和存储数据到数据库。
本文分享自华为云社区《SarkSQL高并发读取数据库和存储数据到数据库》,作者:Copy工程师 。
1. SparkSql 高并发读取数据库
SparkSql连接数据库读取数据给了三个API:
//Construct a DataFrame representing the database table accessible via JDBC URL url named table and connection properties.
Dataset<Row> jdbc(String url, String table, java.util.Properties properties)
//Construct a DataFrame representing the database table accessible via JDBC URL url named table using connection properties.
Dataset<Row> jdbc(String url, String table, String[] predicates, java.util.Properties connectionProperties)
//Construct a DataFrame representing the database table accessible via JDBC URL url named table.
Dataset<Row> jdbc(String url, String table, String columnName, long lowerBound, long upperBound, int numPartitions, java.util.Properties connectionProperties)三个API介绍:
- 单个分区,单个task执行,无并发
遇到数据量很大的表,抽取速度慢。
实例:
SparkSession sparkSession = SparkSession.builder().appName("SPARK_FENGDING_TASK1").master("local").config("spark.testing.memory", 471859200).getOrCreate();
// 配置连接属性
Properties dbProps = new Properties();
dbProps.put("user","user");
dbProps.put("password","pwd");
dbProps.put("driver","oracle.jdbc.driver.OracleDriver");
// 连接数据库 获取数据 要使用自己的数据库连接串
Dataset<Row> tableDf = sparkSession.read().jdbc("jdbc:oracle:thin:@IP:1521:DEMO", "TABLE_DEMO", dbProps);
// 返回1
tableDf.rdd().getPartitions();该API的并发数为1,单分区,不管你留给该任务节点多少资源,都只有一个task执行任务
2. 任意字段分区
该API是第二个API,根据设置的分层条件设置并发度:
def jdbc(
url: String,
table: String,
predicates: Array[String], #这个是分层的条件,一个数组
connectionProperties: Properties): DataFrame =
val parts: Array[Partition] = predicates.zipWithIndex.map case (part, i) =>
JDBCPartition(part, i) : Partition
jdbc(url, table, parts, connectionProperties)
实例:
// 设置分区条件 通过入库时间 把 10月和11月 的数据 分两个分区
String[] patitions = "rksj >= '1569859200' and rksj < '1572537600'","rksj >= '1572537600' and rksj < '1575129600'";
// 根据StudentId 分15个分区,就会有15个task抽取数据
Dataset<Row> tableDf3 = sparkSession.read().jdbc("jdbc:oracle:thin:@IP:1521:DEMO", "TABLE_DEMO",patitions,dbProps);
// 返回2
tableDf3.rdd().getPartitions();该API操作相对自由,就是设置分区条件麻烦一点。
3. 根据Long类型字段分区
该API是第三个API,根据设置的分区数并发抽取数据:
def jdbc(
url: String,
table: String,
columnName: String, # 根据该字段分区,需要为整形,比如id等
lowerBound: Long, # 分区的下界
upperBound: Long, # 分区的上界
numPartitions: Int, # 分区的个数
connectionProperties: Properties): DataFrame =
val partitioning = JDBCPartitioningInfo(columnName, lowerBound, upperBound, numPartitions)
val parts = JDBCRelation.columnPartition(partitioning)
jdbc(url, table, parts, connectionProperties)
实例:
// 根据StudentId 分15个分区,就会有15个task抽取数据
Dataset<Row> tableDf2 = sparkSession.read().jdbc("jdbc:oracle:thin:@IP:1521:DEMO", "TABLE_DEMO", "studentId",0,1500,15,dbProps);
// 返回10
tableDf2.rdd().getPartitions();该操作根据分区数设置并发度,缺点是只能用于Long类型字段。
2. 存储数据到数据库
存储数据库API给了Class DataFrameWriter<T>类,该类有存储到文本,Hive,数据库的API。这里只说数据库的API,提一句,如果保存到Text格式,只支持保存一列。。。就很难受。
实例:
有三种写法
// 第一张写法,指定format类型,使用save方法存储数据库
jdbcDF.write()
.format("jdbc")
.option("url", "jdbc:postgresql:dbserver")
.option("dbtable", "schema.tablename")
.option("user", "username")
.option("password", "password")
.save();
// 第二种写法 使用jdbc写入数据库
jdbcDF2.write()
.jdbc("jdbc:postgresql:dbserver", "schema.tablename", connectionProperties);
// 第三种写法,也是使用jdbc,只不过添加createTableColumnTypes,创建表的时候使用该属性字段创建表字段
jdbcDF.write()
.option("createTableColumnTypes", "name CHAR(64), comments VARCHAR(1024)")
.jdbc("jdbc:postgresql:dbserver", "schema.tablename", connectionProperties);当我们的表已经存在的时候,使用上面的语句就会报错表已存在,这是因为我们没有指定存储模式,默认是ErrorIfExists
保存模式:
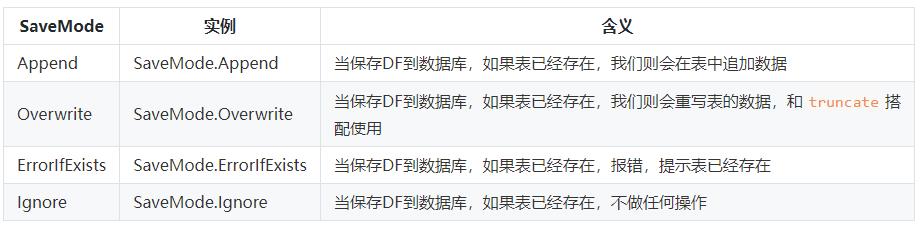
所以一般都是这样用:
tableDf3.write().mode(SaveMode.Append).jdbc("jdbc:oracle:thin:@IP:1521:DEMO", "TABLE_DEMO", connectionProperties);
对于connectionProperties还有很多其他选项:
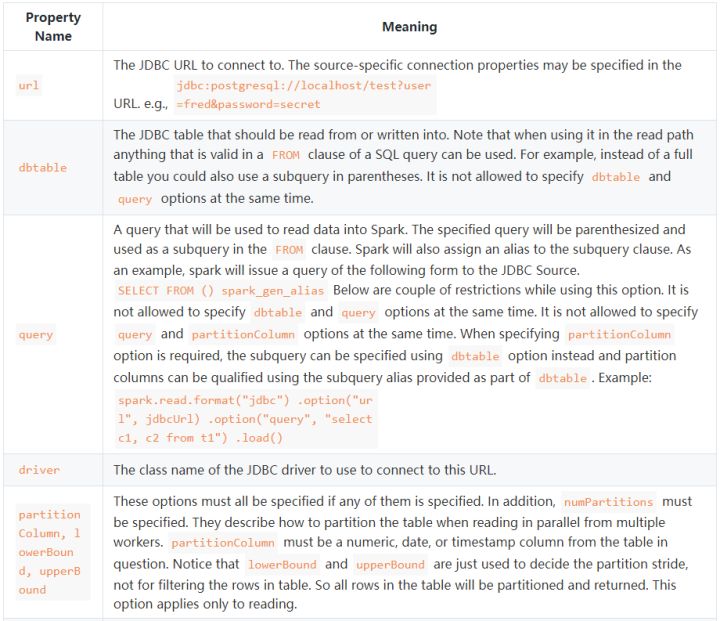
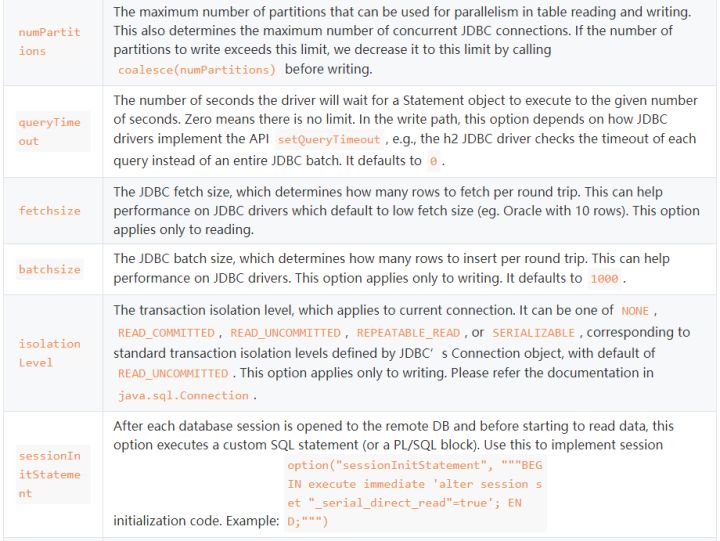
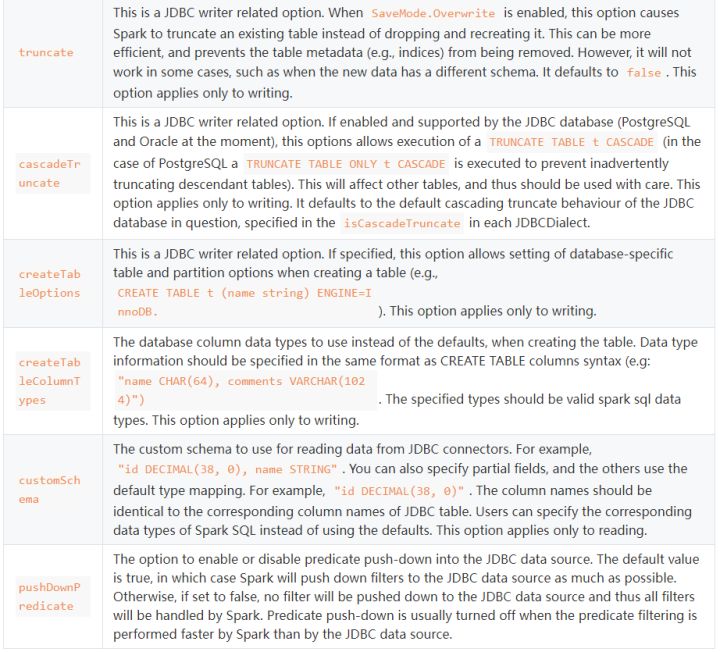
这里面的truncate就是说当使用SaveMode.Overwrite的时候,设置truncate为true,就会对表进行truncate语句清理表,不再是删除表在重建表的操作。
以上是关于SparkSQL高并发:读取存储数据库的主要内容,如果未能解决你的问题,请参考以下文章
Flink CookBook- JDBC Table Source并发详解